爬虫学习二(数据解析)
Re解析(正则表达式):
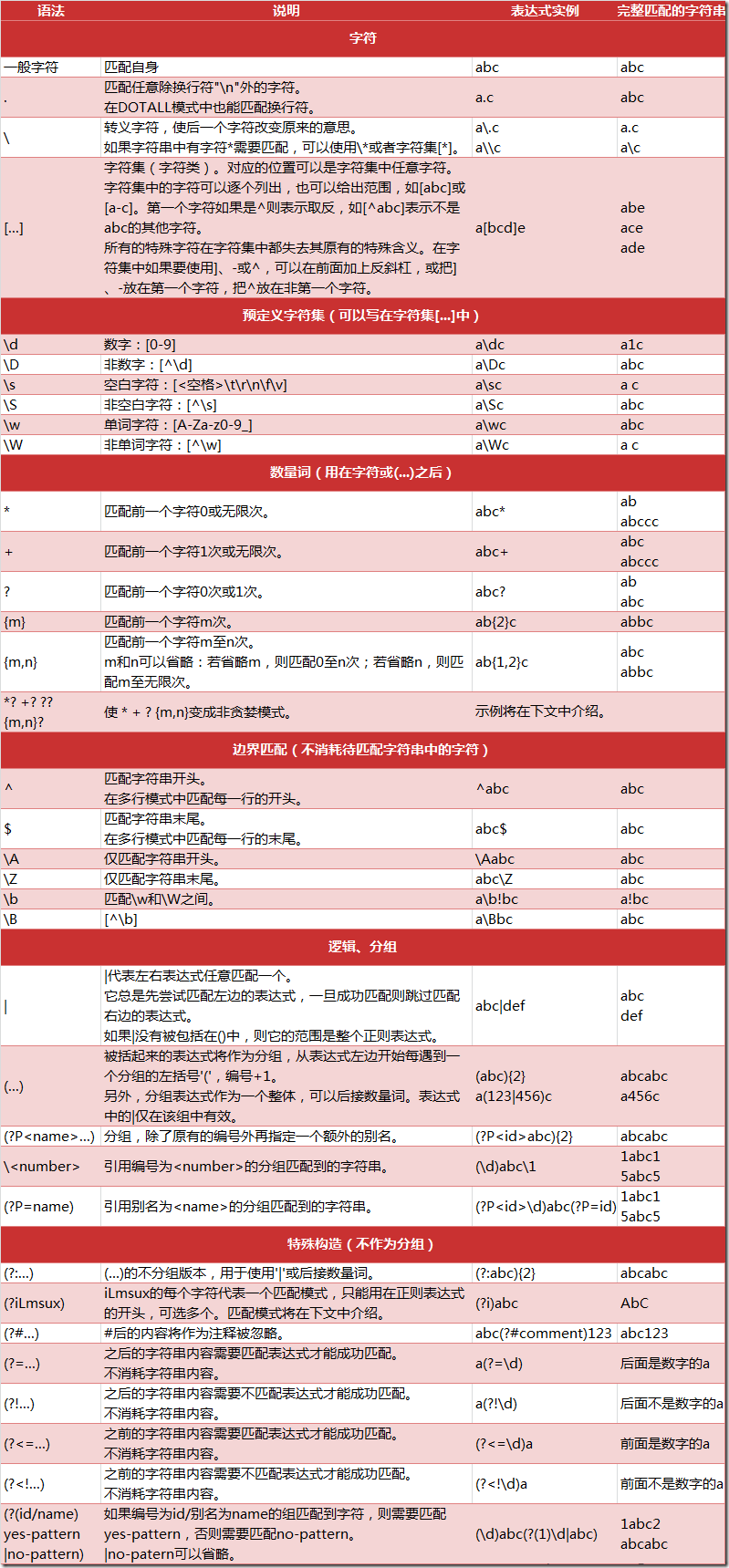
- 常用元字符
re模块:
- re.findall(正则表达式,原始字符串)
- 匹配字符串中所有符合正则的内容,返回列表
import re s=re.findall(r"\d",'12erfc456gffg7') print(s) ['1', '2', '4', '5', '6', '7']
- 匹配字符串中所有符合正则的内容,返回列表
- re.finditer(正则表达式,原始字符串或网页源代码(response))
- 匹配字符串中所以内容,返回迭代器,可以使用for循环访问其中内容,从迭代器中提取内容需要 .group()
-
import re s=re.finditer(r"\d",'12erfc456gffg7') for i in s: print(i.group()) 1 2 4 5 6 7
- re.search(正则表达式,原始字符串)
- 匹配字符串中匹配内容,返回match对象,需要用.group()提取内容,检索到一个结果就返回
- 全文匹配
import re s=re.search(r"\d",'12erfc456gffg7') print(s.group()) 1
- re.match(正则表达式,原始字符串)
- 匹配字符串中匹配内容,返回match对象,需要用.group()提取内容,检索到一个结果就返回
- 从头匹配,开始没有响应数据就匹配失败
-
import re s=re.match(r"\d",'12erfc456gffg7') print(s.group()) 1 import re s=re.match(r"\d",'rfc456gffg7') print(s.group()) Traceback (most recent call last): File "E:/爬虫/p0.py", line 4, in <module> print(s.group()) AttributeError: 'NoneType' object has no attribute 'group'
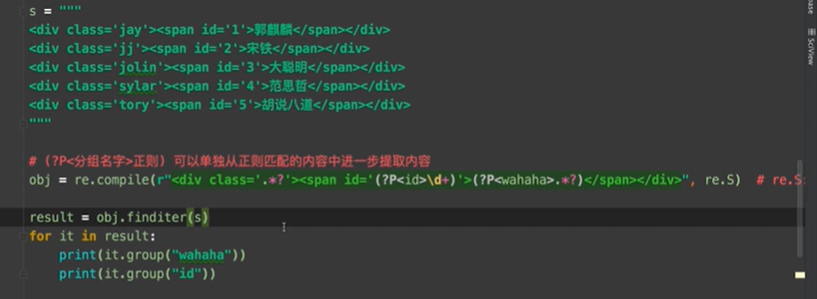
- re.compile(正则表达式,re.S)
- 预加载正则表达式:在程序最开始就定义正则表达式,方便后面的使用,re.S的作用是让.能匹配换行符
- (?P<字段名>正则表达式)可以进一步匹配内容并存入字段
- .*?可以过滤前后表达式之间的部分,通常是多行中不同的部分,(?P<字段名>.*?)可以将需要的数据存入设置的字段名的列表中,这时使用group(字段名)可以提取字段内容
-
import re obj=re.compile(r'\d+') s=obj.findall('rfc456gffg7') print(s) ['456', '7'] -
- requests.get(网页源代码,verify=False)
- 请求网页源代码
- response.encoding='编码类型'可以设置字符集的编码方式防止乱码
- response.encoding='utf-8'
实战:
- 爬取豆瓣电影top250的电影名字、年份、评分、评论人数
-
#-*- codingn:utf-8 -*- #获取网页源代码 request() #获取响应字段 正则表达式 re import re import requests import csv f = open("data.csv", mode='w', encoding='utf-8') csvwriter = csv.writer(f) url=[] for i in range(0,100,25): url.append('https://movie.douban.com/top250?start=%d'%i) headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"} for i in url: resp=requests.get(i,headers=headers) resp.encoding='utf-8' #print(resp.text) obj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?' r'<p class="">.*?<br>(?P<year>.*?) .*?<span ' r'class="rating_num" property="v:average">(?P<score>.*?)</span>.*?' r'<span>(?P<comment>.*?)人评价</span>',re.S) list=obj.finditer(resp.text) for i in list: print(i.group('name')) print(i.group('score')) print(i.group('year').strip()) print(i.group('comment')) dic=i.groupdict() dic['year']=dic['year'].strip() csvwriter.writerow(dic.values()) f.close() print("over")
Xpath解析
- XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。
- 使用时需导入,from lxml import etree,tree=etree.parse('html(即网页)'),tree.path(Xpath解析式),返回列表
- 取节点内容可\text()拿文本,例如book\name\a\text(),取book标签里的name标签里的a标签里的内容
- 注意xpath索引从1开始
- 可通过网页抓包工具的elements选中需要的内容右键copy它的xpath
- 利用etree.HTML(网页源代码)将代码转为html
-
a.html: <html lang='en'>: <head>: <meta charset="utf-8" /> </head> <body>: <ul>: <li><a href="hhhhhhhhh">百度</a></li> <li><a href="xxxxxxxxx">谷歌</a></li> </ul> </body> </html> from lxml import etree tree=etree.parse('a.html') 提取‘百度’、‘谷歌’: result=tree.xpath('\html\body\ul\li\a\text()') 提取’百度‘: result=tree.xpath('\html\body\ul\li[1]\a\text()') 提取href为’hhhhhhhhhh'的数据: result=tree.xpath('\html\body\ul\li[1]\a[@href='hhhhhhhh']\text()) 获取全部a标签的href属性值: result=tree.xpath('\html\body\ul\li[1]\a\@href) 获取li列表并遍历: li_list=tree.xpath('\html\body\ul\li') for li in li_list: print(i) #节点 li.xpath("./a/text()") #在li_list中继续查找文字,相对查找加./,./表示当前节点,返回['百度'],['谷歌'] li.xpath("./a/@href") #获取a标签中href的值(获取属性值),返回['hhhhhhhhh'],['百度'],['xxxxxxxxx'],['谷歌'] -

-

- bookstore/*/nick/text()表示bookstore节点下任意节点的nick的内容,*表示任意节点

- 实例:
-
#-*- codingn:utf-8 -*- #获取网页源代码 request() #xpath提取 import requests from lxml import etree url = "https://www.nowcoder.com/interview/ai/index" response = requests.get(url= url) response.encoding='utf-8' wb_data = response.text html = etree.HTML(wb_data) companys = html.xpath('//html/body/div/div[3]/div/div[3]/div[2]/div/div') name=[] job=[] attention=[] for company in companys: name.append(company.xpath('.//div[1]/div[2]/text()')) job.append(company.xpath('.//div[2]/span[1]/b/text()')) attention.append(company.xpath('.//div[2]/span[2]/b/text()')) interviews=zip(name,job,attention) for i in interviews: print(i) - 注意!!!!
- 如果在网页源代码里面没有响应的内容就不能通过网络抓包工具copy字段的xpath进行提取,否则会返回空列表
-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具