

国产数据库obase
##sample 1 文章1 OceanBase 慢查询排查思路
https://open.oceanbase.com/blog/4030499840?_gl=1*1muepo8*_ga*MTg4MDgzMzI3Mi4xNzE1NDE3MjEw*_ga_T35KTM57DZ*MTcxNTg0MDQ3OS4xMi4xLjE3MTU4NDU2NTkuNjAuMC4w
本文汇总了项目实践中前辈的经验和笔者的理解,旨在帮助初学 OceanBase(以下简称 OB)的工程师,快速解决 SQL 执行缓慢等性能问题。当遇到性能问题时,很多工程师可能会感到无从下手,本文将根据关键日志提供多种分析方向,以加速问题排查。
作者:任仲禹
爱可生 DBA 团队成员,擅长故障分析和性能优化,文章相关技术问题,欢迎大家一起讨论。
背景
应用连接 OB 的生产架构,一般有两种:
- 应⽤ → OBProxy → OBServer
- 应⽤ → OBProxy-Sharding → OBServer
前者是大多数客户使⽤场景,后者是少数客户使⽤的单元化架构场景,后文将 OBProxy 和 OBProxy-Sharding 统称为 ODP(OceanBase Database Proxy)。
当我们发现某条语句耗时较长时,我们需要排查的点有:应⽤到 ODP 的⽹络时间、ODP 的执行时间、ODP 到 OBServer 的⽹络时间、OBServer 的执行时间。
从哪些信息入手?
要诊断哪部分时间消耗长,以及原因是什么,大多数情况会从如下几个组件获取信息。
ODP 组件
- obproxy_digest.log:审计⽇志,记录执⾏失败的 SQL 语句、执行时间大于参数
query_digest_time_threshold阈值(默认是 2ms)请求。 - obproxy_slow.log:慢 SQL 请求日志,记录执⾏时间大于参数
slow_query_time_threshold阈值(默认是 500ms)的请求。 - obproxy.log:ODP 总日志。
在 obproxy_digest.log 和 obproxy_slow.log 中,第 15、16、17、18 列(即 8353us,179us,0us,5785us)分别表示:ODP 处理总时间、ODP 预处理时间、ODP 获取连接时间、OBServer 执⾏时间。示例如下:
2023-05-04
16:46:03.513268,test_obproxy,,,,test:ob_mysql:sbtest,OB_MYSQL,sbtest1,sbtest1,COM_QUERY
,SELECT,failed,1064,select t1.*%2Ct2.* from sbtest1 t1%2Csbtest2 t2 where t1.id = t2.id
where id <10000,8353us,179us,0us,5785us,Y0-7FA25BB4A2E0,YB420ABA3FAC-0005FA2415BE0F81-
0-0,,,0,10.186.63.172:2881
- ODP 处理总时间的起点:ODP 接收到客户端请求的时间;
- ODP 处理总时间的终点:ODP 把所有的数据都写回给客户端;
- ODP 预处理时间:包含去
oceanbase.__all_virtual_proxy_schema查询 Leader 的时间; - ODP 获取连接时间:目前不做记录,看到的都是 0;
- OBServer 执行时间:起点是 ODP 发送请求给 OBServer,终点是收到 OBServer 返回第一条记录。
从上面的原理可以看出,后三项时间相加并不等于第一项时间,比如 ODP 处理总时间比较长,但是预处理时间和 OBServer 执行时间都很短,有可能时间消耗在 OBServer 将第一条记录返回给 ODPServer 和 ODPServer 把所有数据写回给客户端之间,这在结果集较大的 SQL 语句中⽐较常⻅。
OBserver 组件
- gv$audit_sql:该视图⽤于展示所有 OBServer 上每⼀次 SQL 请求的来源、执⾏状态等统计信息。
该视图是按照租户拆分的,除了系统租户,其他租户不能跨租户查询。⼀般常⽤的字段有:request_time,sql_id,plan_id,plan_type,trace_id,svr_ip,client_ip,user_client_ip,user_name,db_name,elapsed_time,queue_time,get_plan_time,execute_time,retry_cnt,table_scan,ret_code,query_sql……
# 大致的归类如下
标识信息:tenant_id,sql_id,trace_id,plan_id ,sid,transaction_hash,......
来自哪⾥:user_name,user_client_ip,client_ip(OBProxy) ,......
在哪执行:svr_ip,db_name,plan_type, ......
开始时间:request_time
执行耗时:elapsed_time,get_plan_time,execute_time ,......
等待耗时:total_wait_time_micro,queue_time,net_time,user_io_wait_time,......
数据扫描:table_scan(全表扫描),disk_reads,memstore_read_row_count,sstable_read_row_count ,......
并行执行:expected_worker_count,used_worker_count, qc_id,sqc_id,worker_id ,......
请求类型:request_type, ......
强弱读:consistency_level
数据量:affected_rows,return_rows,partition_cnt,......
返回码:ret_code
- observer.log:OBServer 运行的主要⽇志,这里面的信息非常全面,外部用户不易解读,很多情况下会根据
trace_id去搜索,例如通过 OCP 的 SQL 诊断功能获取到TraceID,再进⾏查询。
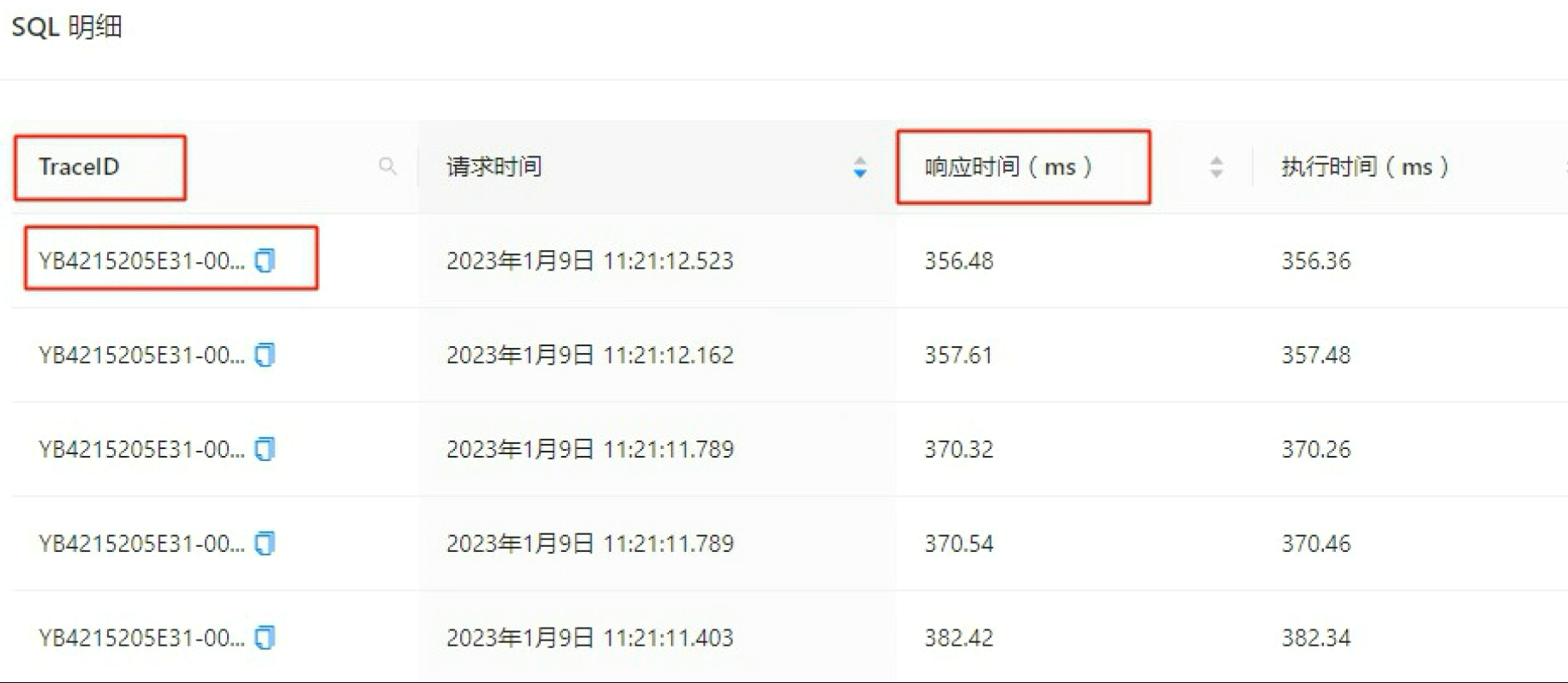
常见 OB 慢查询分析思路
1. ODP 给应用回写数据耗时长
当 SQL 的结果集很大,ODP 就需要较长时间将数据返回给应用,这时候会发现 OBServer 执行时间和 ODP 预处理时间相加,比 ODP 执行总时间要小,以下面的 obproxy.log 记录为例:
[2023-04-19 19:12:31.662602] WARN [PROXY.SM] update_cmd_stats (ob_mysql_sm.cpp:8633)
[5628][Y0-7F820F6C7960] [lt=38] [dc=0] Slow Query: ((client_ip={x.x.x.x:51555},
server_ip={x.x.x.x:2881}, obproxy_client_port={x.x.x.x:33584},
server_trace_id=YB420A97B009-0005F6EF28FSFS11-0-0, route_type=ROUTE_TYPE_LEADER,
user_name=depo, tenant_name=su, cluster_name=cmcluster, logic_database_name=,
logic_tenant_name=, ob_proxy_protocol=0, cs_id=1077902,
proxy_sessid=1513983664671181892, ss_id=611834, server_sessid=3221841415, sm_id=260155,
cmd_size_stats={client_request_bytes:87, server_request_bytes:122,
server_response_bytes:0, client_response_bytes:185002181}, cmd_time_stats=
{client_transaction_idle_time_us=0, client_request_read_time_us=11,
client_request_analyze_time_us=10, cluster_resource_create_time_us=0,
pl_lookup_time_us=4, pl_process_time_us=4, congestion_control_time_us=1,
congestion_process_time_us=0, do_observer_open_time_us=2, server_connect_time_us=0,
server_sync_session_variable_time_us=0, server_send_saved_login_time_us=0,
server_send_use_database_time_us=0, server_send_session_variable_time_us=0,
server_send_all_session_variable_time_us=0, server_send_last_insert_id_time_us=0,
server_send_start_trans_time_us=0, build_server_request_time_us=2,
plugin_compress_request_time_us=0, prepare_send_request_to_server_time_us=65,
server_request_write_time_us=20, server_process_request_time_us=337792,
server_response_read_time_us=2353609, plugin_decompress_response_time_us=1299449,
server_response_analyze_time_us=17505, ok_packet_trim_time_us=0,
client_response_write_time_us=1130104, request_total_time_us=5309727}, sql=SELECT x,x,x
FROM sbtest.sbtest1 where id =1)
client_response_bytes:185002181client_response_write_time_us=1130104
该示例中,ODP 回写给应用的数据为 185MB,耗时 1.1s,可以通过该信息观测下是否是 SQL 的结果集较大。
2. ODP 获取 location cache 慢
ODP 要把 SQL 路由到准确的 OBServer 上,只需要知道每个 Table 的 Partition 的 Leader 所在位置,获取位置的过程叫做 “get location cache”。通常这个过程很快,并且获取后会缓存在本地,少数情况下,这个时间消耗会慢,以下面为例:
[2023-05-07 00:01:04.506809] WARN [PROXY.SM] update_cmd_stats (ob_mysql_sm.cpp:8607)
[363][Y0-7F4521AA21A0] [lt=28] [dc=0] Slow Query: ((client_ip={x.x.x.x:36246},
server_ip={x.x.x.x:2881}, obproxy_client_port={21.2.1
92.29:40556}, server_trace_id=, route_type=ROUTE_TYPE_LEADER, user_name=mY14OyQ1tF,
tenant_name=bu06, cluster_name=cscluster2, logic_database_name=budb,
logic_tenant_name=odp-h170kfw30w7l, ob_proxy_protocol=2, cs_id=2993079,
proxy_sessid=1513983656080750373, ss_id=53737247, server_sessid=3223571471,
sm_id=44290320, cmd_size_stats={client_request_bytes:342, server_request_bytes:385,
server_response_bytes:66, client_response_bytes:66}, cmd_time_stats=
{client_transaction_idle_time_us=0, client_request_read_time_us=25,
client_request_analyze_time_us=25, cluster_resource_create_time_us=0,
pl_lookup_time_us=4998993, pl_process_time_us=126, congestion_control_time_us=2,
congestion_process_time_us=0, do_observer_open_time_us=5, server_connect_time_us=0,
server_sync_session_variable_time_us=0, server_send_saved_login_time_us=0,
server_send_use_database_time_us=0, server_send_session_variable_time_us=0,
server_send_all_session_variable_time_us=0, xxxxxxxx
pl_lookup_time_us=4998993
耗时 4s 明显有异常,获取到该日志后可以快速和 OB 研发缩小问题排查范围。
3. 表的路由选择
在 OceanBase 数据库中,有 Local 计划、Remote 计划和 Distributed 计划三种表路由。Local 计划、Remote 计划均为单分区的路由。ODP 的作⽤就是尽量消除 Remote 计划,将路由尽可能的变为 Local 计划。
如果表路由类型为 Remote 计划的 SQL 过多,则表示该 SQL 性能可能不是最优,通常的原因有 ODP 路由问题、无法计算表分区 ID、使用了全局索引、需要开启二次路由等等。
通过 gv$sql_audit 的 PLAN_TYPE 字段可以判断 SQL 的执行计划类型:
- 1:Local
- 2:Remote
- 3:Distributed
4. OBServer 写入限速
当 memstore 已使⽤的内存达到 writing_throttling_trigger_percentage 时(默认 100),触发写入限速。当该配置项的值为 100 时,表示关闭写入限速机制。在触发写入限速后,剩余 memstore 内存必须保证在writing_throttling_maximum_duration(默认 1h)内不会分配完,也就是写入速度上限为 memstore * (1- writing_throttling_trigger_percentage) / writing_throttling_maximum_duration。
通过监控 gv$memstore 可以知道 memstore 使用的百分比。当发生了写入限速,observer.log 中会看到如下记录:
[2023-04-10 10:52:09.076066] INFO [COMMON] ob_fifo_arena.cpp:301 [68425][1739]
[YB420A830ADF-00058B41370AAF4F] [lt=85] [dc=0] report write throttle
info(cur_mem_hold=162644623360, throttle_info_={decay_factor_:"0.000000005732",
alloc_duration_:2400000000, trigger_percentage_:70, memstore_threshold_:231928233960,
period_throttled_count_:140, period_throttled_time_:137915965,
total_throttled_count_:23584, total_throttled_time_:27901629728})
关键字:report,write,throttle,info
还有⼀种场景就是发现 QPS 异常下降时(尤其是包含⼤量写⼊,可以通过查询系统表的⽅式确认是否是由于写⼊限速导致。
select * from v$session_event where EVENT='memstore memory page alloc wait' \G;
*************************** 94. row ***************************
CON_ID: 1
SVR_IP: x.x.x.x
SVR_PORT: 22882
SID: 3221487713
EVENT: memstore memory page alloc wait
TOTAL_WAITS: 182673
TOTAL_TIMEOUTS: 0
TIME_WAITED: 1004.4099
AVERAGE_WAIT: 0.005498403704981032
MAX_WAIT: 12.3022
TIME_WAITED_MICRO: 10044099
CPU: NULL
EVENT_ID: 11015
WAIT_CLASS_ID: 109
WAIT_CLASS#: 9
WAIT_CLASS: SYSTEM_IO
关键字:memstore,memory,page,alloc,wait
5. 访问执行计划
访问计划也是影响 SQL 耗时的⼀个因素,没有命中 plan cache、访问计划发生了预期外的变化都会造成 SQL 执行变慢。
没有命中 plan cache 可以在 gv$sql_audit 中看到 IS_HIT_PLAN=0。
要查看 SQL 具体的执行计划有两种⽅式:一是执行 explain extended <query_sql>,但这只能看到当前环境下,该语句的执行计划,可能并不是现场缓慢 SQL 的执行计划,需要查看缓慢 SQL 正在使用的访问计划,需要首先记录下 gv$sql_audit 中的四个值:SVR_IP,SVR_PORT,TENANT_ID,PLAN_ID。并在 gv$plan_cache_plan_explain中进行查询:
select SVR_IP, SVR_PORT, TENANT_ID, PLAN_ID from gv$sql_audit where query_sql ...
select * from gv$plan_cache_plan_explain where ip=<SVR_IP> and port=<SVR_PORT> and
tenant_id=<TENANT_ID> and plan_id=<PLAN_ID>
6. OBServer 锁等待
OceanBase 选择 MVCC 来实现事务并发性和一致性,支持读写不互斥。因此事务间的锁等待一般发生在写请求上(lock_for_write),极少情况下也会发生在读请求(lock_for_shared)。
当发生了锁等待,SQL执⾏耗时也会变长,通常的表现是:在 gv$sql_audit 中看到 elapsed_time 较大,execute_time 较小,retry_cnt 较大(>0),伴随 observer.log 可以观察到如下日志:
[2023-03-29 12:00:26.310172] WARN [STORAGE.TRANS] on_wlock_retry
(ob_memtable_context.cpp:393) [135700][2338][Y1312AC1C4140-0005EFC759EADC21] [lt=10]
[dc=0] lock_for_write conflict(*this=alloc_type=0 ctx_descriptor=700817166
trans_start_time=1680062426310071 min_table_version=1679627152331552
max_table_version=1679627152331552 is_safe_read=false has_read_relocated_row=false
read_snapshot=1680062426310007 start_version=-1 trans_version=9223372036854775807
commit_version=0 stmt_start_time=1680062426310074 abs_expired_time=1680062436209982
stmt_timeout=9899908 abs_lock_wait_timeout=1680062436209982 row_purge_version=0
lock_wait_start_ts=0 trx_lock_timeout=-1 end_code=0 is_readonly=false ref=2 pkey=
{tid:1116004302242691, partition_id:0, part_cnt:0} trans_id={hash:4021727895899886621,
inc:669379877, addr:"172.28.65.64:4882", t:1680062426310046} data_relocated=0
relocate_cnt=0 truncate_cnt=0 trans_mem_total_size=0 callback_alloc_count=0
callback_free_count=0 callback_mem_used=0 checksum_log_ts=0,
key=table_id=1116004302242691 rowkey_object=[{"BIGINT":2024021}] ,
conflict_ctx="alloc_type=0 ctx_descriptor=700817301 trans_start_time=1680062426309892
xx
- 关键字:lock_for_write,conflict
7. SQL 语句有问题
一般 SQL 语句查询慢排除上述问题后,大部分跟自身有关,例如 SQL 语句没有走到索引、写法有问题等。这种情况就需要:
- 通过
gv$sql_audit表或 ODP 日志拿到具体的 SQL 文本。
# 查询以某个租户⼀段范围内执⾏耗时的SQL语句进⾏排序
SELECT usec_to_time(request_time) as request_time,
sql_id, plan_id, plan_type, trace_id,
svr_ip, client_ip, user_client_ip, user_name, db_name elapsed_time, queue_time,
get_plan_time, execute_time, retry_cnt, table_scan,
ret_code,
query_sql
FROM gv$sql_audit
WHERE tenant_id=1001
AND request_time BETWEEN time_to_usec('2023_05_12 13:00:00')
AND time_to_usec('2023_05_13 13:10:00') AND is_executor_rpc = 0
ORDER BY elapsed_time DESC limit 10;
2. 拿到 SQL 文本后,再通过 Explain 查询计划进⾏分析(例如对下文语句进⾏ Explain 分析,比如 name 中只有表名不包含索引列的话,则该 SQL 语句可能使用的主键或全表扫描)。
obclient [sbtest]> explain select * from sbtest1 where k like '%111181823%' \G
*************************** 1. row ***************************
Query Plan: ========================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
----------------------------------------
|0 |TABLE SCAN|sbtest1|283098 |333648|
========================================
Outputs & filters:
-------------------------------------
0 - output([sbtest1.id], [sbtest1.k], [sbtest1.c], [sbtest1.pad]),
filter([(T_OP_LIKE, cast(sbtest1.k, VARCHAR(1048576)), '%111181823%', '\\')]),
access([sbtest1.k], [sbtest1.id], [sbtest1.c], [sbtest1.pad]), partitions(p0)
1 row in set (0.004 sec)
3. 排查 SQL 成本和执行计划中访问顺序是否有问题,就不具体展开了。
以上就是导致 OB 慢查询常见的原因及分析思路,希望对读者有所帮助。
##sample 2
OceanBase 4.1.0 clog 目录探究
https://open.oceanbase.com/blog/5203648257
于OceanBase 4.x 版本如何统计租户每日 clog 日志生成量的背景下,探究以及如何查看租户 clog 的使用情况。
作者:姜宇爱可生 DBA 团队成员,擅长数据库故障排查和处理。对技术抱有热忱,实践是检验真理的唯一标准~本文来源:原创投稿爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
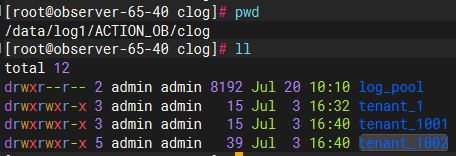
我们知道 clog 目录是存放 OceanBase 数据库记录修改操作的物理日志目录。目录具体的物理存放位置为 /data/log1/clustername/clog。比如,集群 ACTION_OB 的 clog 目录如下图所示:
OceanBase 4.1.0 版本采用了租户级别的日志流,将物理的变更记录聚合成了组织良好的若干日志流:一个系统日志流和多个用户日志流。系统的所有物理变更信息被记录在这些日志流中,故障恢复、日志归档、备库同步等均使用一套物理变更信息。在一个租户内,一个日志流允许有多个副本,多个副本之间基于 Paxos 协议同步数据。
OceanBase 4.1.0 版本 clog 目录下不再是 OBServer 的 clog 文件,而是新增了一层目录:log_pool 和 tenant_id 两类目录。下面我们分别介绍一下这两类目录的作用。
log_pool 目录
OceanBase 会为每一个 OBServer 节点初始化一个日志预分配池,即为该 OBServer 节点的日志盘总容量 LOG_DISK_CAPACITY,clog 文件默认 64M 一个,log_pool 会根据 log_disk_capacity/64M 预分配所有的 clog 日志文件;它受到集群配置项 log_disk_size 和 log_disk_percentage 共同影响。
- 如果
log_disk_size的值为 0,且log_disk_percentage的值不为 0,则系统以log_disk_percentage配置项设置的值分配日志盘空间。 - 如果
log_disk_size的值不为 0,则无论log_disk_percentage的值是否为 0,系统均以log_disk_size配置项设置的值分配日志盘空间。 - 如果
log_disk_size和log_disk_percentage的值均为 0,则系统会根据日志和数据是否共用同一磁盘来自动计算 Redo 日志占用其所在磁盘总空间的百分比:
log_disk_size 和 log_disk_percentage 默认为 0,如果没有特殊配置的情况下,OBServer 的日志盘总容量使用根据上述第三种情况决定。本地测试环境 OceanBase 日志盘没有划分磁盘,和 OceanBase 数据盘 data 目录共用一个磁盘。所以 OceanBase 日志盘占用其所在磁盘总空间的百分比为 30%,即 30G。
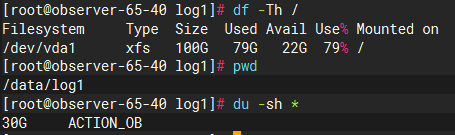
我们可以通过系统表 __all_virtual_server 来查看具体使用情况。其中 log_disk_capacity 即为当前 OBServer 节点的日志盘总容量,大约为 30G 左右。

那 log_disk_assigened 日志盘分配 和 log_disk_in_use 日志盘使用 又代表了什么意思呢?我们继续向下看。
tenant_id 目录
租户在一个 OBServer 的表现为一个 unit 资源单元,v4 新增 unit_config 属性 LOG_DISK_SIZE(注意和系统参数 log_disk_size 区分),为创建的租户初始化 log_disk_size 大小的 clog 目录空间。具体存放位置就是上边说的 /data/log1/clustername/clog/tenant_id 目录了。根据不同租户的 tenant_id 创建不同租户所属的日志目录。
需要注意的是这部分空间并不是一开始就分配到租户的所属目录下的,而是预占,在租户未使用 clog 文件时,会保留在 log_pool 中,表现为 all_virtual_server 表的 log_disk_assigned 字段。当租户需要写入新的 clog 文件时,OceanBase 才会将 log_pool 中的 clog 文件分配到所属的租户目录下,表现为 all_virtual_server 表的 log_disk_in_use 字段。
我们可以通过视图 gv$ob_units 查看具体 OBServer 节点的 unit 配置情况:
- log_disk_size:表示某一租户 unit 资源单元的日志磁盘可用的最大容量。
- log_disk_in_use:表示某一租户 unit 资源单元的日志磁盘使用容量。
可以看到下图中,all_virtual_server 的 log_disk_assinged 列对应 gv$ob_units 的 log_disk_size 列值之和,即 OBServer 节点的日志盘是根据租户的unit规格配置来预分配每个租户的日志盘容量的。all_virtual_server 的 log_disk_in_use 列对应 gv$ob_units 的 log_disk_in_use 列值之和,即当租户需要申请新的 clog 文件时,log_pool 才会将 clog 文件分配到租户的日志目录下。
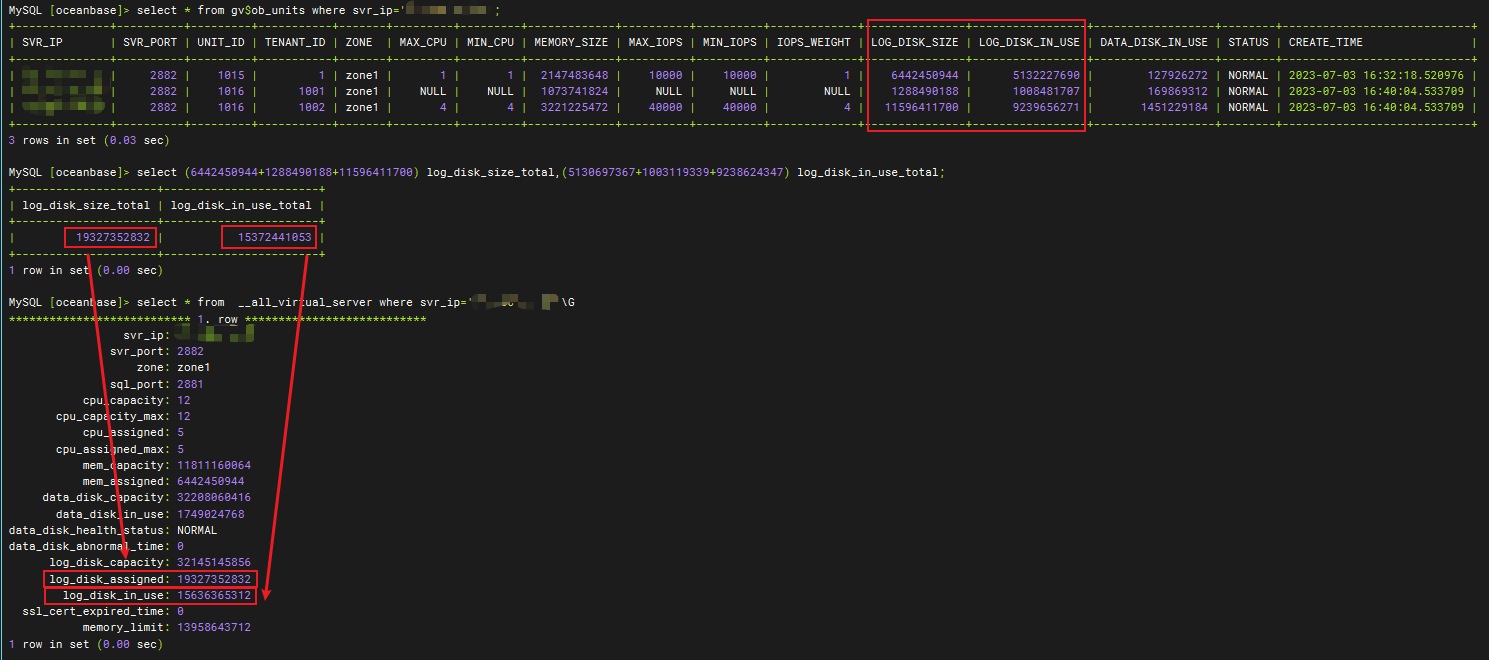
我们也可以通过磁盘目录使用来观察到 log_pool+tenant_id 的目录之和大约是 30G 左右,即 LOG_DISK_CAPACITY=30G;而 tenant_id 目录大小与 gv$ob_units 的 log_disk_in_use 对应;

目录空间使用的问题明白后,当我在看 OCP 的集群租户信息时发现,日志盘目录下为什么会多了一个 tenant_1001 的目录呢,这个租户我没有创建过呀,为什么会多了一个租户呢?
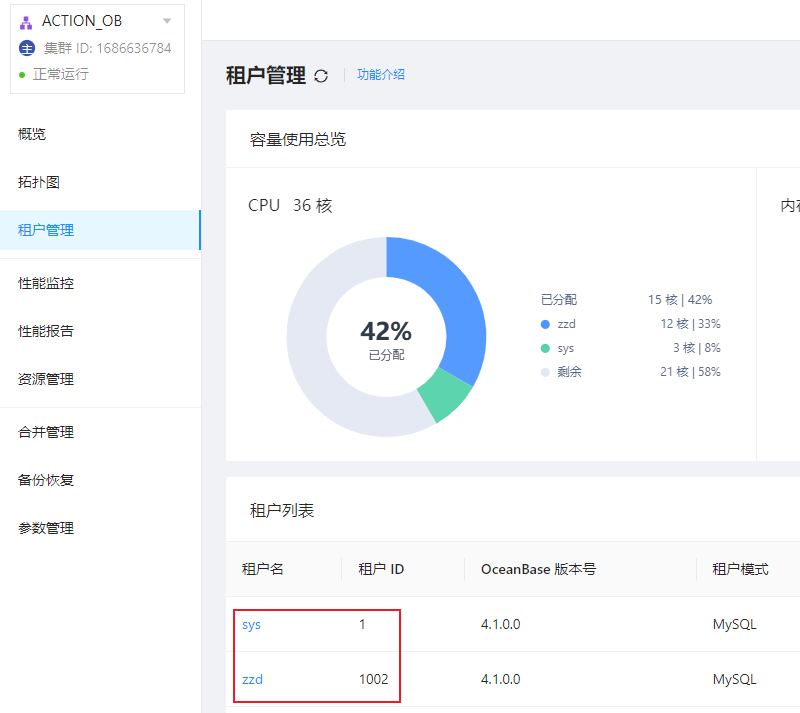
其实 tenant_1001 是 1002 租户的 Meta 租户,从 4.0.0 版本开始,引入了 Meta 租户概念。Meta 租户是 OceanBase 数据库内部自管理的租户,每创建一个用户租户系统就会自动创建一个对应的 Meta 租户,其生命周期与用户租户保持一致。Meta 租户用于存储和管理用户租户的集群私有数据,这部分数据不需要进行跨库物理同步以及物理备份恢复,这些数据包括:配置项、位置信息、副本信息、日志流状态、备份恢复相关信息、合并信息等。Meta 租户不能直接登录。我们可以通过 DBA_OB_TENANTS 视图查看具体的租户信息:
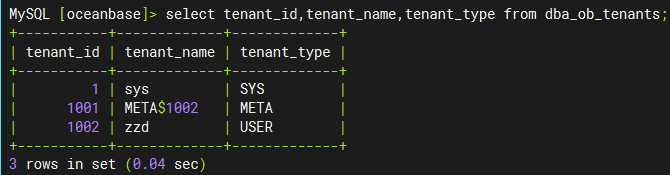
下图中,我们看到tenant_id目录下并不是具体的clog文件,而是又有一层数字id目录,数字id目录下的log目录才是具体存放clog文件的地方,那这些数字id有代表的是什么意思呢,我们继续向下看。

3、日志流目录
OcenaBase 4.x 版本引入了日志流 和分片的概念。每个分区都有其对应的数据存储对象,称之为分片(Tablet),它具备存储数据的能力,支持在机器之间迁移(transfer),是数据均衡的最小单位。日志流是由 OceanBase 数据库自动创建和管理的实体,它代表了一批数据的集合,包括若干 Tablet 和有序的 Redo 日志流。它通过 Paxos 协议实现了多副本日志同步,保证副本间数据的一致性,实现了数据的高可用。
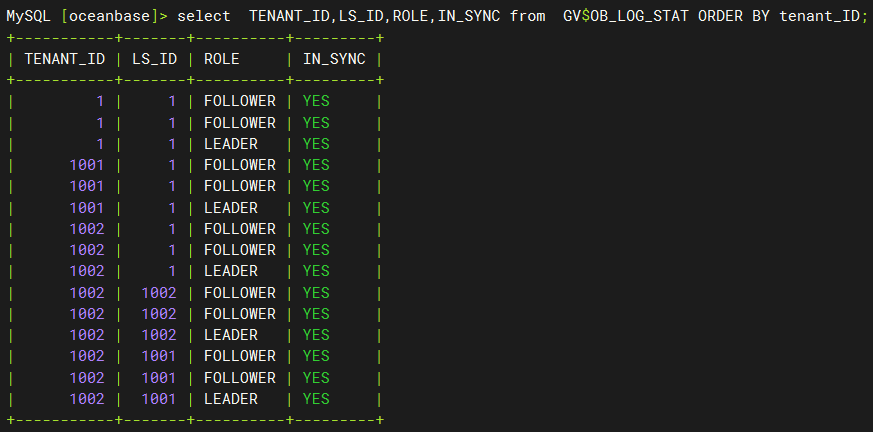
上图中的数字 id 其实就是对应了这里的日志流 id,即 LS_ID。我们可以通过 gv$ob_log_stat 查看租户的日志流 ID。通过下图我们可以看到 tenant_id=1 的租户对应的日志流 id 为 1;tenant_id=1001 的租户对应的日志流 id 为 1;tenant_id=1002 的租户对应的日志流 id 为 1、1001、1002 与上图目录结构一致。
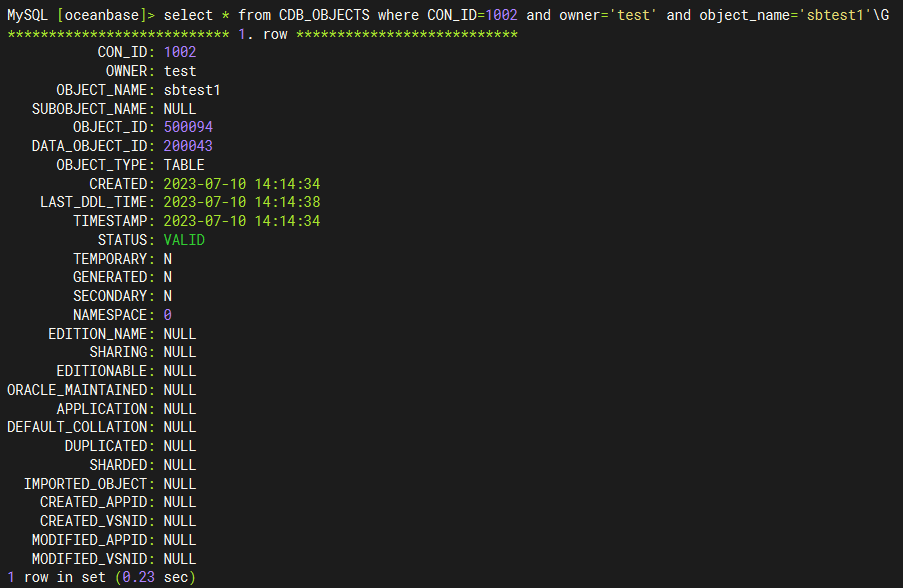
我们也可以通过视图 CDB_OBJECTS 和 CDB_OB_TABLET_TO_LS 查看表分区对应的分片、分片与日志流的映射关系,以及日志流副本的位置信息。比如我们想看 tenant_id=1002 租户的 test 库的 sbtest1 表所在的日志流信息:
- 通过
CDB_OBJECTS我们可以查询对指定表对应的分片 ID:tablet_id(DATA_OBJECT_ID)
- 通过
CDB_OB_TABLET_TO_LS我们可以查询到指定分片的日志流 ID:LS_ID。

clog 磁盘使用控制
租户可使用的 clog 磁盘容量是有限度的,当租户 unit 的 clog 日志容量使用比例(log_disk_in_use/log_disk_size*100%)达到指定阈值(log_disk_utilization_threshold,默认为 80%,不可修改)后,不会再向 log_pool 申请 clog 文件,而是直接复用最老的 clog 文件。
可以看到下图中租户的 clog 磁盘使用率也符合预期值。

clog 的使用量统计
在知道了 clog 目录结构之后,我们就可以通过计算租户目录下 clog 文件的生成量来统计租户每小时、每天的日志生成量,可以用于预估 OceanBase 备份盘的使用量。
#统计租户 clog 的生成量
--每小时
find $clog_dir/tenant_$tenant_id/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ':' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$3" | "$1" | "$1*64/1024 "G"}'
--每天
find tenant_1001/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ' ' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$3" | "$1" | "$1*64/1024 "G"}'
# 统计租户 data 数据大小
select tenant_id,svr_ip,sum(required_size/1024/1024/1024) from CDB_OB_TABLET_REPLICAS group by tenant_id,svr_ip,svr_port;
#!/usr/bin/bash
clog_dir=/data/log1/ACTION_OB/clog
echo "-- 检查时间:`date "+%Y-%m-%d %H:%M:%S"` --"
echo "+++++++++++++++++++++++++++++++++++++++++++++++++++"
echo "log_pool剩余clog文件数量: `ls -l $clog_dir/log_pool/|grep -v meta|wc -l`"
echo "log_pool剩余空间: $(echo "scale=2;`ls -l $clog_dir/log_pool/|grep -v meta|wc -l` * 64 / 1024 "|bc) G"
for tenant_id in `ls $clog_dir|grep "tenant_*"|awk -F '_' '{print $2}'`
do
echo "+++++++++++++++++++++++++++++++++++++++++++++++++++"
echo "$tenant_id 租户当前clog文件数量: `find $clog_dir/tenant_$tenant_id/* -regex '.*/[0-9]+' -type f |wc -l`"
echo "$tenant_id 租户当前clog文件总大小: $(echo "scale=2;`find $clog_dir/tenant_$tenant_id/* -regex '.*/[0-9]+' -type f |wc -l` * 64 / 1024 "|bc) G"
echo -e "$tenant_id 租户clog按照天统计:(YYYY-mm-dd|file_num|count_size)\n`find $clog_dir/tenant_$tenant_id/ -type f -regex '.*/[0-9]+' -exec stat --format="%y" {} \; |cut -d ' ' -f 1|sort|uniq -c|awk -F ' ' '{print $2" | "$1" | "$1*64/1024 "G"}'`"
done
脚本执行结果如下图所示:

######sample 3
https://open.oceanbase.com/blog/1100238?_gl=1*88apwm*_ga*MjA4MjA4NTk4Ny4xNzE3MDUzMTA2*_ga_T35KTM57DZ*MTcxNzA1Nzg5MS4yLjEuMTcxNzA1OTA4Ny4yMy4wLjA.
在企业数据库里有一种需求是读写分离,本文介绍 OB 的读写分离方案的部署和测试过程,希望可以减少分布式数据库选型时不必要的基本功能测试。读写分离听起来简单,实际内部设计还是有很多巧妙之处,刚学习完 OBCP 的 朋友们不妨也看看。
本文测试内容如下,有相应截图:
- OCP 的安装部署
- OB 集群部署
- OB 只读副本部署及其只读访问测试
- OB 只读副本和全功能副本的在线转换
- OB 单副本备集群部署及其只读访问测试
机器准备
硬件资源
机器全部使用公有云 ECS,配置是 32c128G2T。
[root@observer00:/root/t-oceanbase-antman]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
<...>
[root@observer00:/root/t-oceanbase-antman]# free -g
total used free shared buff/cache available
Mem: 125 1 104 0 19 118
Swap: 0 0 0
[root@observer00:/root/t-oceanbase-antman]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 50G 42G 5.1G 90% /
devtmpfs 63G 0 63G 0% /dev
tmpfs 63G 0 63G 0% /dev/shm
tmpfs 63G 820K 63G 1% /run
tmpfs 63G 0 63G 0% /sys/fs/cgroup
/dev/mapper/ob_vg-ocp_home 296G 2.0G 279G 1% /home
/dev/mapper/ob_vg-docker_home 493G 73M 467G 1% /docker
/dev/mapper/ob_vg-ob_data 2.2T 85M 2.1T 1% /data/1
/dev/mapper/ob_vg-ob_log 504G 73M 479G 1% /data/log1
[root@observer00:/root/t-oceanbase-antman]#
机器初始化
机器初始化是很重要的一步,使用 OceanBase 提供的软件包t-oceanbase-antman-1.3.6-1917679.alios7.x86_64.rpm 可以做一些自动化初始工作。
这部分不再重复描述。详情请参考 https://mp.weixin.qq.com/s/Q-4ksIRFWYa4xbl4Yccw1g 以前的初始化步骤。
OCP 部署
ocp 的部署可以先参考 OceanBase 2.x 试用版安装体验——OCP 2.3 。
镜像文件准备
一共三个 docker 镜像文件,分别是 OBProxy、OCP、OceanBase。
[root@observer00:/root/t-oceanbase-antman]# ls -lrth *.gz -rw-r--r-- 1 126593 users 404M Jan 3 22:18 obproxy173.tar.gz -rw-r--r-- 1 root root 688M Jan 17 14:02 ocp-all-in-one-2.5.0-x86.tar.gz -rw-r--r-- 1 root root 1.4G Jan 17 14:09 OB2273_x86_20201214.tar.gz [root@observer00:/root/t-oceanbase-antman]#
加载镜像文件
[root@observer00:/root/t-oceanbase-antman]# for img in `ls *.gz`;do echo $img; docker load -i $img; done OB2273_x86_20201214.tar.gz <...> Loaded image: reg.docker.alibaba-inc.com/antman/ob-docker:OB2273_x86_20201214 obproxy173.tar.gz <...> Loaded image: reg.docker.alibaba-inc.com/antman/obproxy:OBP173_20200603_1923 ocp-all-in-one-2.5.0-x86.tar.gz <...> Loaded image: reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one:2.5.0-1918031
查看镜像文件。不同版本的镜像文件在版本号上会有一点区别。注意看 tag 标签。镜像文件命名并不重要。实际版本以 tag 为准。
[root@observer00:/root/t-oceanbase-antman]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one 2.5.0-1918031 2e635ca841b8 2 weeks ago 1.55GB reg.docker.alibaba-inc.com/antman/ob-docker OB2273_x86_20201214 4da7b6c59465 5 weeks ago 2.89GB reg.docker.alibaba-inc.com/antman/obproxy OBP173_20200603_1923 781b6520e237 7 months ago 1.15GB [root@observer00:/root/t-oceanbase-antman]#
OCP部署配置文件 obcluster.conf
下面直接给出关键的几个配置.
第一次跑的时候在 /root/t-antman-oceanbase/ 下没有这个目录。执行脚本初始化一个
[root@observer00:/root/t-oceanbase-antman]#sh init_obcluster_conf.sh [root@observer00:/root/t-oceanbase-antman]# vim obcluster.conf ## obcluster.conf ## SINGLE_OCP_MODE=TRUE ################################ 根据环境必须修改 / MUST CHANGE ACCORDING ENVIRONMENT ################################ ############ 填写机器IP和root/admin密码 / Edit Machine IP and Password Of root/admin ############ ZONE1_RS_IP=172.23.152.220 OBSERVER01_ROOTPASS=******* OBSERVER01_ADMINPASS=****** SSH_PORT=22 ############ 根据服务器CPU、内存设置容器资源编排 / Allocate Container Resources According To Server ############ OB_docker_cpus=20 OB_docker_memory=92G OCP_docker_cpus=6 OCP_docker_memory=16G OBProxy_docker_cpus=2 OBProxy_docker_memory=6G ############ 填写OCP各组件容器的版本信息 / Edit Docker Image, Repo And Tag of OCP Components ############ # OB docker docker_image_package=OB2273_x86_20201214.tar.gz OB_image_REPO=reg.docker.alibaba-inc.com/antman/ob-docker OB_image_TAG=OB2273_x86_20201214 # OCP docker ocp_docker_image_package=ocp-all-in-one-2.5.0-x86.tar.gz OCP_image_REPO=reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one OCP_image_TAG=2.5.0-1918031 # OBPROXY docker obproxy_docker_image_package=obproxy173.tar.gz obproxy_image_REPO=reg.docker.alibaba-inc.com/antman/obproxy obproxy_image_TAG=OBP173_20200603_1923
自动化安装
OCP的部署命令非常简单。只要机器环境没有问题,安装部署就是一个命令,自动过。
[root@observer00:/root/t-oceanbase-antman]# ./install.sh -i 1-
run install.sh with DEBUG=FALSE, INSTALL_STEPS=1 2 3 4 5 6 7 8 CLEAR_STEPS= CONFIG_FILE=/root/t-oceanbase-antman/obcluster.conf
[2021-01-23 15:51:01.148954] INFO [start antman API service]
LB_MODE=none
[2021-01-23 15:51:01.534776] INFO [step1: making ssh authorization, logfile: /root/t-oceanbase-antman/logs/ssh_auth.log]
[2021-01-23 15:51:04.782001] INFO [step1: ssh authorization done]
[2021-01-23 15:51:04.792041] INFO [step2: no action is required when LB_MODE=none]
[2021-01-23 15:51:04.795448] INFO [step3: check whether OBSERVER port 2881,2882 are in use or not on 172.23.152.220]
[2021-01-23 15:51:09.462947] INFO [step3: OBSERVER port 2881,2882, 2022 are idle on 172.23.152.220]
[2021-01-23 15:51:09.466502] INFO [step3: installing ob cluster, logfile: /root/t-oceanbase-antman/logs/install_ob.log]
[2021-01-23 15:51:35.760209] INFO [start container: docker run -d -it --name META_OB_ZONE_1 --net=host -e OBCLUSTER_NAME=obcluster -e DEV_NAME=eth0 -e ROOTSERVICE_LIST="172.23.152.220:2882:2881" -e DATAFILE_DISK_PERCENTAGE=90 -e CLUSTER_ID=100000 -e ZONE_NAME=META_OB_ZONE_1 -e OCP_VIP=172.23.152.220 -e OCP_VPORT=8080 -e METADB_CLUSTER_NAME=obcluster -e app.password_root=ro0T@20#Ra -e app.password_admin=ro0T@20#Ra -e OPTSTR="cpu_count=20,memory_limit=89G,__min_full_resource_pool_memory=1073741824,_ob_enable_prepared_statement=false,memory_limit_percentage=90" --cpu-period 100000 --cpu-quota 2000000 --cpuset-cpus 0-19 --memory 92G -v /home/admin/oceanbase:/home/admin/oceanbase -v /data/log1:/data/log1 -v /data/1:/data/1 -v /backup:/backup --restart on-failure:5 reg.docker.alibaba-inc.com/antman/ob-docker:OB2273_x86_20201214]
0dbbc671f4cbf3792067e64eade064a397f46cacabd65af63de699826c4d940c
[2021-01-23 15:51:35.971611] INFO [installing OB docker and starting OB server on 172.23.152.220, pid: 19062, log: /root/t-oceanbase-antman/logs/install_OB_docker.log and /home/admin/logs/ob-server/ inside docker]
[2021-01-23 15:51:39.090756] INFO [install_OB_docker.sh finished and reg.docker.alibaba-inc.com/antman/ob-docker:OB2273_x86_20201214 started on 172.23.152.220]
[2021-01-23 15:51:39.094245] INFO [waiting on observer ready on 172.23.152.220]
[2021-01-23 15:54:39.103957] INFO [waiting on observer ready on 172.23.152.220 for 3 Minitues]
[2021-01-23 15:55:39.114452] INFO [waiting on observer ready on 172.23.152.220 for 4 Minitues]
[2021-01-23 15:55:39.504591] INFO [observer on 172.23.152.220 is ready]
[2021-01-23 15:55:39.514450] INFO [observer installation on all hosts done]
[2021-01-23 15:55:39.521402] INFO [Now, start bootstrap on 172.23.152.220: alter system bootstrap REGION "OCP_META_REGION" ZONE "META_OB_ZONE_1" SERVER "172.23.152.220:2882"]
[2021-01-23 15:56:59.700068] INFO [bootstrap done, observer now ready]
[2021-01-23 15:56:59.710201] INFO [major_freeze start]
[2021-01-23 15:57:59.759744] INFO [major_freeze done]
[2021-01-23 15:57:59.763844] INFO [step3: installation of ob cluster done]
[2021-01-23 15:57:59.767362] INFO [step4: initializing ocp metadb, logfile: /root/t-oceanbase-antman/logs/init_metadb.log]
[2021-01-23 15:58:04.640267] INFO [step4: initialization of ocp metadb done]
[2021-01-23 15:58:04.643938] INFO [step5: check whether OCP port 8080 is in use or not on 172.23.152.220]
[2021-01-23 15:58:06.202247] INFO [step5: OCP port 8080 is idle on 172.23.152.220]
[2021-01-23 15:58:06.206098] INFO [step5: installing temporary ocp, logfile: /root/t-oceanbase-antman/logs/install_tmp_ocp.log]
[2021-01-23 15:58:26.476181] INFO [ob server is ready on host 172.23.152.220]
[2021-01-23 15:58:26.625129] INFO [init metadb: docker run --net host --workdir=/home/admin/ocp-init/src/ocp-init --entrypoint=python reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one:2.5.0-1918031 create_metadb.py 172.23.152.220 2881 root@ocp_meta X21FRlH9{@ ocp root@ocp_monitor ^I4SH6HsU@ ocp_monitor]
create_metadb.py:356: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
data = yaml.load(file)
<...>
[root@observer00:/root/t-oceanbase-antman]#
[root@observer00:/root/t-oceanbase-antman]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5333a8797e7b reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one:2.5.0-1918031 "/usr/bin/supervisor…" 7 minutes ago Up 7 minutes ocp
60bd06244095 reg.docker.alibaba-inc.com/antman/obproxy:OBP173_20200603_1923 "sh start_obproxy.sh" 8 minutes ago Up 8 minutes obproxy
0dbbc671f4cb reg.docker.alibaba-inc.com/antman/ob-docker:OB2273_x86_20201214 "/usr/bin/supervisor…" 20 minutes ago Up 20 minutes META_OB_ZONE_1
[root@observer00:/root/t-oceanbase-antman]#
如果安装报错了,就把报错的步骤 回滚掉 -c 。
OB 集群部署
部署规划
目标:
- 部署一个 1-1-1 的 OB 集群。
- 部署一个只读副本。
- 部署一个单副本备集群。
主机名IPREGIONIDCZone备注observer01172.23.152.221RG1IDC1ZONE_1OB 主副本observer02172.30.118.66RG1IDC2ZONE_2OB 备副本observer03172.30.118.67RG2IDC3ZONE_3OB 备副本observer04172.26.154.55RG2IDC22ZONE_4OB 只读副本observer05172.26.154.54RG3IDC4ZONE_1OB 备集群单副本
注意:这里的 REGION 和 IDC 信息都是特别设计的,后面可以看到效果。
做到后面发现这里的 IDC22 应该命名为 IDC33 更贴切一些。不过不好调整了。在实际生产环境里,IDC22 跟 IDC3 通常是同一个物理机房或者同一个城市,属于同一个 REGION。
机器资源池录入
- 新增机型

- 新增凭据


- 新增机房

- 添加主机

重复添加所有主机后,OCP 管理的机器资源如下:

部署 OB 集群
注意,选机器的时候,ZONE、IDC、IP 都要跟规划一致。

- 可选:指定一些 OB 集群参数。

这些参数是常用的,性能测试时会有用。不是必须的。有关参数介绍请参考:OB 开发测试建议 (中)

提交后生成安装任务。
OceanBase 集群的自动化安装任务相比手动安装是更严谨一些,这符合企业级数据库运维平台的基本要求。子任务切分很细,并且有很多环境检查准备等工作。OCP 提供了图形化的进度浏览。多个节点能同时安装。

OceanBase 集群的安装时间绝大部分都是这一步任务的时间。这一步是为了测试主机上 IO 的综合能力,然后生成一个文件 `/home/admin/oceanbase/etc/io_resource.conf 。
[admin@observer01:/home/admin]# ps -ef|grep ob_admin admin 7002 6963 99 17:47 ? 00:08:40 /home/admin/oceanbase/bin/ob_admin io_bench -c /home/admin/oceanbase/etc -d /data/1/obdemo admin 10848 5779 0 17:49 pts/0 00:00:00 grep --color=auto ob_admin [admin@observer01:/home/admin]#
部署 OBProxy 集群
给业务部署一个 OBProxy,用于业务读写。由于测试环境我没有 VIP,所以这里集群的 IP 填写了第一个后端 OBProxy 的 IP。

创建 OB 租户
新建 OB 的 ORALCE 租户
OCP 可以创建租户,选择兼容 MySQL 或者 ORACLE。这个细节就不重复了。

初始化 ORACLE 租户数据
这里用 BenchmarkSQL 工具初始化 TPCC 场景数据。
vim props.ob db=oceanbase driver=com.alipay.oceanbase.obproxy.mysql.jdbc.Driver conn=jdbc:oceanbase://172.30.118.66:2883/tpcc?useAffectedRows=true&emulateUnsupportedPstmts=false&characterEncoding=utf8&enableQueryTimeouts=false&useLocalSessionState=false&useLocalTransactionState=false&rewriteBatchedStatements=true&allowMultiQueries=true&socketTimeout=600000 user=tpcc@oboracle01#obdemo password=123456 warehouses=100 loadWorkers=10
OB 只读副本部署
新增一个 ZONE
在集群 obdemo的管理界面里点击“新增 Zone”,选一个机器,用于只读副本。

新增一个只读副本
在租户里新增一个副本,类型选择“只读副本”。

OB 单副本备集群部署
新建备集群
在集群 obdemo 的集群管理界面,点击“新建备集群”。


新建备集群的任务里面也会有 IO 测试,bootstrap 操作。搭建备集群并不是增加一个备副本,而是搭建一个独立的 OB 集群。

新增 OBProxy
新增一个 OBProxy 访问只读副本。
目前 OCP 还不支持创建 2 个 OBProxy 集群关联到一个 OB 集群。所以这个 OBProxy 暂时只能手动创建。
OBProxy 启动的时候指定 obconfig_url 。

需要取这个值中的 IP 和端口部分,替换下面参数中的 IP和端口。
[admin@observer04:/opt/taobao/install/obproxy]# cd /opt/taobao/install/obproxy && bin/obproxy -p2883 -cobdemo -o "obproxy_config_server_url=http://172.23.152.220:8080/services?Action=GetObProxyConfig&User_ID=alibaba-inc&uid=ocpmaster,proxy_idc_name=IDC22" bin/obproxy -p2883 -cobdemo -o obproxy_config_server_url=http://172.23.152.220:8080/services?Action=GetObProxyConfig&User_ID=alibaba-inc&uid=ocpmaster,proxy_idc_name=IDC22 listen port: 2883 cluster_name: obdemo optstr: obproxy_config_server_url=http://172.23.152.220:8080/services?Action=GetObProxyConfig&User_ID=alibaba-inc&uid=ocpmaster,proxy_idc_name=IDC22 [admin@observer04:/opt/taobao/install/obproxy]# ps -ef|grep obproxy admin 6761 1 30 19:31 ? 00:00:01 bin/obproxy -p2883 -cobdemo -o obproxy_config_server_url=http://172.23.152.220:8080/services?Action=GetObProxyConfig&User_ID=alibaba-inc&uid=ocpmaster,proxy_idc_name=IDC22 admin 7192 31451 0 19:31 pts/0 00:00:00 grep --color=auto obproxy [admin@observer04:/opt/taobao/install/obproxy]#
注意:备副本的 OBPROXY 我在启动的时候特地指定了 proxy_idc_name=IDC22这个参数。当通过这个 OBPROXY 发起弱一致性读时,会按下面顺序路由:
- 同一个 IDC 下的备副本所在的 OBSERVER 节点。
- 同一个 REGION 下的其他 IDC 下的备副本所在的 OBSERVER 节点。
- 其他 REGION 下的备副本所在的 OBSERVER 节点
集群拓扑
- 主集群视角的拓扑

- 备集群视角的拓扑

也可以在集群里通过 SQL 确认:
select t1.name resource_pool_name, t3.unit_id, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb, t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,t4.tenant_id, t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order BY t1.tenant_id ,t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id
;
SELECT * FROM __all_zone WHERE name IN ('region','idc');


测试验证
确认集群租户资源分布
这个不是必须的。只是顺道展示一下 OCP 新增的功能。也方便大家对只读副本的理解。

确认表(分区)的位置
以表bmsql_item为例。这是个单表。

运行下面 SQL 查询这个表分区的位置
SELECT t.tenant_id, a.tenant_name, d.database_name, t.table_name, tg.tablegroup_name , t.part_num , t2.partition_id, t2.ZONE, t2.svr_ip, t2.ROLE, t2.data_size
, a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality
FROM oceanbase.__all_tenant AS a
JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id )
JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id)
JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1,2) )
LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id)
WHERE a.tenant_id IN (1001 ) AND t.table_type IN (3) AND d.database_name LIKE '%TPCC%'
AND t.table_name IN ('BMSQL_ITEM')
;

从图中看表bmsql_item的主副本在 221 上,其他节点都是备副本。
确认 SQL 路由节点的方法
OceanBase 里所有的 SQL 都会在sys租户的内部视图gv$sql_audit里记录。这个对排查问题非常方便。
下面语句是根据 SQL 文本查询执行信息
SELECT /*+ read_consistency(weak) ob_querytimeout(100000000) */ substr(usec_to_time(request_time),1,19) request_time_, s.svr_ip, s.client_Ip, s.sid, s.plan_type, s.query_sql, s.affected_rows, s.return_rows, s.ret_code FROM gv$sql_audit s WHERE s.tenant_id=1001 AND user_name LIKE '%TPCC%'AND query_sql LIKE '%TEST_RO%' ORDER BY request_time DESC LIMIT 10;

其中
client_ip是 SQL 在 OceanBase 集群视角的客户端 IP。如果客户端是通过 OBPROXY 访问 OB,那么这个地址通常就是 OBPROXY 的地址。svr_ip是 SQL 被路由到 OceanBase 集群的节点 IP。通常是 SQL 访问分区的主副本 IP,不过有时候也不是。这个跟 OBPROXY 路由策略有关。这个以后可以独立成篇去介绍。plan_type是 SQL 的执行类型。1:表示在该节点(指svr_ip)本机执行;2:表示是发送到其他节点远程执行。发送到哪个节点这里看不到(通常是指发送到分区主副本节点);3 表示是这个 SQL 是个分布式执行计划,会涉及到多个分区。有可能这些分区还跨节点了。
所以,上图的解释是这个 SQL 从 55 这个 IP 路由到 55 这个节点。由于访问的表的主副本不在这个节点,所以又再次路由到其他节点(实际是主副本所在节点,即 221 )。
业务读写验证
前面的 TPCC 场景的数据初始化使用的就是第一个 OBProxy 集群,包含读写操作。
首先我们看有一个实时读写的单表 SQL 会被路由到哪个节点。测试 SQL 类似
select /*+ test_rw */ count(*) cnt from bmsql_item\G
注意:/*+ */ 是 SQL 的注释语法,也是 HINT 语法。 test_rw不是标准的 SQL HINT,所以会被 SQL 引擎忽略。写在这里只是为了标记这个 SQL,方面后面从 SQL 审计视图里定位到这个 SQL。
为了简化情况,让下面的测试案例可以复现。请严格按照测试方法做。每次执行 SQL 时都重新连接。不要复用老的连接。
开始测试,通过 observer02 上的 OBPROXY 连接集群看看。然后换 observer01 上的 OBPROXY 连接集群看看。
[root@observer00:/root]# obclient -hobserver02 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "select /*+ test_rw_10 */ count(*) cnt from bmsql_item\G " obclient: [Warning] Using a password on the command line interface can be insecure. *************************** 1. row *************************** CNT: 100000 [root@observer00:/root]# obclient -hobserver01 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "select /*+ test_rw_10 */ count(*) cnt from bmsql_item\G " obclient: [Warning] Using a password on the command line interface can be insecure. *************************** 1. row *************************** CNT: 100000
看 SQL 审计结果

所以,无论从哪个 OBPROXY 链接 OB 集群,通常单表 SQL 最后都会被路由到该表主副本所在的节点。这种路由规则叫强一致性读。
本项验证的目的已经达到。下面演示弱一致性读的路由规则。弱一致性读只允许就近读取备副本。需要指定 HINT (read_consistency(weak) 或者在会话级别设置。
obclient -hobserver01 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_41 */ count(*) cnt from bmsql_item\G" obclient -hobserver01 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_41 */ count(*) cnt from bmsql_item\G" obclient -hobserver02 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_41 */ count(*) cnt from bmsql_item\G" obclient -hobserver02 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_41 */ count(*) cnt from bmsql_item\G"

观察 SQL 路由信息

注意: SQL 审计视图按时间顺序是从下往上看。
多测试可以看出,如果选择备副本所在节点的 OBPROXY 连接 OB 集群,它就随机转发给备副本的 OBSERVER 节点了,然后 SQL 也是本地执行(plan_type=1)。如果选择主副本所在节点的 OBPROXY 连接 OB 集群,它就随机转发给所有的 的 OBSERVER 节点。
除了用 SQL HINT 外,还有个办法就是通过 SESSION 变量来设置弱一致性读。
[root@observer00:/root]# obclient -hobserver01 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_rw_14 */ count(*) cnt from bmsql_item\G" obclient: [Warning] Using a password on the command line interface can be insecure. *************************** 1. row *************************** CNT: 100000 [root@observer00:/root]# obclient -hobserver02 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_rw_14 */ count(*) cnt from bmsql_item\G" obclient: [Warning] Using a password on the command line interface can be insecure. *************************** 1. row *************************** CNT: 100000 [root@observer00:/root]#

弱一致性读通常用于少量的读写分离场景。对于大量的读写分离需求,或者为了绝对不影响主副本的读写,那推荐使用只读副本。
只读副本访问验证
只读副本主要用于读写分离场景。对于一些业务上能接受些许延时的查询,可以访问“只读副本”减轻主副本的压力。只读副本的访问也必须使用弱一致性读。
下面就验证只读副本的访问是否真的会路由到只读副本的节点。为了便于理解,我加了一些强一致性读进行对比。
obclient -h172.23.152.221 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "select /*+ test_ro_28 */ count(*) cnt from bmsql_item\G" obclient -h172.23.152.221 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_28 */ count(*) cnt from bmsql_item\G" obclient -h172.26.154.55 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "select /*+ test_ro_28 */ count(*) cnt from bmsql_item\G" obclient -h172.26.154.55 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_28 */ count(*) cnt from bmsql_item\G"


注意: SQL 审计视图按时间顺序是从下往上看。
从上图可以看出,发往只读副本所在节点的 OBPROXY(这个 OBPROXY 启动时指定了特别的 IDC 参数,见前面说明)的弱一致性读,会路由到同一个 IDC 下的 OBSERVER 节点(也是本机节点,测试环境受限就这么巧),而不是随机到其他备副本节点。这就是只读副本的目的。
同时也看出,发往只读副本所在节点的 OBPROXY 的强一致性读,还是会被路由到主副本所在的节点。这个就是 OB 的只读副本跟其他分布式数据库主从读写分离方案最大的不同。OB 绝对不会出现错误的写了只读副本(双写)。
然而 OB 更特殊的优势还在只读副本故障时的情形。
只读副本故障后验证
通常模拟故障就是直接登录节点 杀掉 OBSERVER 进程。最近 OCP 增加了停止节点的功能,这里就顺便演示一下。(以前有客户吐槽 OB 不能停机,现在可以了 😆)

同样的,停 OBSERVER 节点也会生成一个任务,并且拆分为很多原子任务。这个过程会比我直接 KILL 节点要长很多。这是因为 OCP 选择了一种严谨的稳妥的步骤。

确认节点状态

select a.zone,concat(a.svr_ip ,':',a.svr_port) observer, usec_to_time(b.last_offline_time) last_offline_time, usec_to_time(b.start_service_time) start_service_time, b.status, b.with_rootserver from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port) order by a.ZONE, a.svr_ip ;

再跑弱一致性验证
obclient -h172.23.152.221 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "select /*+ test_ro_29 */ count(*) cnt from bmsql_item\G" obclient -h172.23.152.221 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_29 */ count(*) cnt from bmsql_item\G" obclient -h172.26.154.55 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "select /*+ test_ro_29 */ count(*) cnt from bmsql_item\G" obclient -h172.26.154.55 -utpcc@oboracle01#obdemo -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_29 */ count(*) cnt from bmsql_item\G"

从图中可以看出,当只读副本不可访问时,原弱一致性读的 SQL 会被路由到同一个 REGION(RG2)的其他 IDC(IDC3) OBSERVER 节点。
也就是说即使只读副本故障了,那些只读查询业务也不会受影响(OBPROXY 会迅速把路由切换到其他候选的备副本所在 OBSERVER 节点)。这点也是 OB 跟其他分布式数据库中间件读写分离最大的不同。尽管后者也可以通过高可用 agent 去判断只读实例故障然后更改各个备实例的读写权重。读写权重那个设置是全局层面的,无法按业务切分。
只读副本跟全功能备副本之间的在线转换
OceanBase 更特别的地方就是只读副本跟全功能副本可以在线转换。

上图是编辑Zone3 的全功能副本,改为只读副本。也可以改 Zone4 的只读副本为全功能副本。基本上 1 分钟就生效。
任务图如下:

最终结果如下:

只读副本和全功能副本的在线转换这个能力,通常用于 OceanBase 集群在线跨机房跨城市搬迁。支付宝每年双11 大促前后常做这种在线搬迁。
备集群的访问
OB 现在也支持主备集群架构(DATAGUARD)。备集群的使用详情以后再介绍,这里只展示一下备集群的访问。
首先备集群的访问跟主集群一样,只是集群名字后面多了一个 :2

上图: obdemo:1是主集群,obdemo:2是备集群。
备集群访问方式:
obclient -h172.26.154.55 -utpcc@oboracle01#obdemo:2 -P2883 -p123456 -s -e "set session ob_read_consistency=weak; select /*+ test_ro_30 */ count(*) cnt from bmsql_item\G" obclient -h172.26.154.55 -utpcc@oboracle01#obdemo:2 -P2883 -p123456 -s -e "select /*+ test_ro_30 */ count(*) cnt from bmsql_item\G"

注意:备集群只能读不能写,并且这个读必须是弱一致性读。
通常主集群的任意一个 OBPROXY 也可以访问备集群。
下面是上面 SQL 在备集群的 SQL 审计视图里的路由信息。

总结
综上所述,OB 的读写分离有三种方案:
- 三副本或者五副本架构下,个别 SQL 通过弱一致性读 HINT 或者会话设置,就近只读备副本。
- 三副本或五副本架构下,额外增加一个或多个只读副本,为只读副本配置单独的 OBPROXY ,只读业务走这个 OBPROXY 专门访问只读副本。
- 为 OB 集群搭建一个备集群,可以是单副本或者三副本。只读业务专门访问备集群。
至于要选择哪种方案呢,还是要看“读写分离”的目的。想在什么范围内隔离只读查询对读写业务的影响,决定了选择哪种方案更合适。
OB 读写分离方案的优势有两点:
- 无论什么状况都不用担心误写了“备副本或只读副本”,因为它不支持写,写操作会被路由到主副本。(当然备集群那个例外,不能跨集群路由)。
- 无论什么时候都不用担心“备副本或只读副本”故障了,因为 OBPROXY会就近路由到其他备副本。(当然单副本备集群不能,如果要防范这个风险,就搭建三副本备集群就行,自身有高可用)。
用惯了 ORACLE 的 ADG 或者 MySQL 的主从读写分离的,可能会觉得 OB 的读写分离方案复杂。这个就需要转变观念了。读写分离方案严格的说要考虑各种异常情况,OB 把这些异常都做到内部去了,但对用户使用是极其方便的,对运维的工作也是很友好的。当企业的数据库机器规模成百上千后,企业级的自动化运维平台应该长什么样呢?命令行下脚本运维肯定是不行,自动化任务失败率过高时也是不行。
小提示:仅仅通过 OCP 完成只读副本和备集群搭建还不算真正掌握这个能力,其背后具体的操作步骤(尤其是 SQL)才是关键,感兴趣的朋友,可以在任务列表里下载这些任务的日志进行详细研究。 HAVE FUN 😆!
更多文章请搜索个人公众号:OceanBase技术闲谈
#######ocenbase 在线问答
Q1:集群参数只需要设置一次,是对集群管理的所有zone 的OBSERVER 生效?
Q2租户参数只需要设置一次,是对集群管理的租户的OBSERVER 生效?
Q3:obproxy参数调整 为何要登陆每个obproxy 才能生效?
Q1: 是的,集群级配置项的修改会影响整个集群,无论是在哪个 Zone 中的 OBServer。
Q2: 是的,租户级配置项的修改会影响到该租户在集群内所在的 OBServer。
Q3: 因为OBProxy 参数调整需要登录每个 OBProxy 才能生效,因为 OBProxy 的配置是基于每个实例的。每个 OBProxy 实例都有自己的配置,修改某个 OBProxy 的参数只会影响该实例,不会自动同步到其他 OBProxy 实例。因此,为了确保所有 OBProxy 实例的参数都得到更新,需要依次登录到每个 OBProxy 实例进行参数调整。
也可以参考下配置项和系统变量。OceanBase分布式数据库-海量数据 笔笔算数
q1: show proxysession 用于查询 OBProxy 当前的连接数和连接状态的命令,需要监控或诊断 OBProxy 的连接状态等等
q2: show processlist 用于查询当前租户的会话数量及会话 ID,
包括用户、主机、数据库、状态等信息,需要查看当前数据库的活跃会话、检查是否有长时间运行的查询或事务、或者分析数据库的负载情况等等
q3:SHOW FULL PROCESSLIST 需要更详细地了解每个会话的具体操作,参考: [SHOW-OceanBase 数据库-OceanBase文档中心-分布式数据库使用文档]
(OceanBase分布式数据库-海量数据 笔笔算数)
4q1:OCP_MONITOR 用户可能是用于监控和管理 OceanBase 数据库的用户 可以参考这个文档
4q2:通过 obproxy连接数据库提供了更多的管理和优化功能,生产环境和需要复杂路由的场景应该会较合适。
而直接连接数据库则适用于简单配置或特定需求的场景。可以根据实际的业务需求和环境配置选择合适的连接方式。
q>\?如何用一条SQL 语句 查看业务租户内部所有leader副本的位置
select * from oceanbase.DBA_OB_TABLE_LOCATIONS where ROLE='LEADER' and table_name='xxx';
在普通租户下,可以通过查询 oceanbase.dba_ob_table_locations 获得各个租户中所有表的各分区位置信息。
select database_name, table_name, table_id, table_type, zone, svr_ip, role from oceanbase.dba_ob_table_locations where table_name = ‘t1’;
在系统租户下,可以通过查询 oceanbase.cdb_ob_table_locations 获得各个租户中所有表的各分区位置信息。
select database_name, table_name, table_id, table_type, zone, svr_ip, role from oceanbase.cdb_ob_table_locations where table_name = ‘t1’;
q:oceanbase 点查和范围查询


