
转DM8的SQL性能优化思路浅谈系列(二)
干货攻略】达梦数据库DM8的SQL性能优化思路浅谈系列(二)
们在上一次的分享中已介绍SQL优化的重要性,预估执行计划生成及基础说明和达梦性能分析思路。今天我们接着来聊一下达梦数据库参数调整、跟踪存储过程中的慢SQL思路及辅助性能分析工具介绍和使用以及如何跟踪慢SQL。
达梦数据库DM.INI参数调整思路
达梦数据库的参数灵活性非常高,配置的好,它能达到一个整体很好的性能效果,而且跟产品深度融合,复用标准工艺参数,能很好的降本增效,这是我们每一个DBA都要重视的优化方向。
达梦优化参数分类
(1)相关文件路径设置参数(控制文件,备份文件,系统文件,临时文件等);(2)实例名(3)内存池以及缓存池(4)线程相关参数(5)查询INI优化类参数(这块跟我们产品特性有比较大关系);(6)检查点参数(7)IO优化参数(8)数据库设置类参数(9)兼容类参数(比如兼容Oracle等)(10)REDO相关参数(11)事务相关参数(12)监控参数(13)…
达梦数据库参数配置需要考虑的因素:(1)受机器硬件配置影响(CPU,内存根据需要设置);(2)受需要适配的产品影响(以产品和项目实际使用规模等情况为导向来设置,比如大型ERP产品,基础表比较多,字典缓冲区就要调整到合理值,避免设置过小,频繁被淘汰刷新,又例如看整个产品你的SQL分类,HASH类的SQL过多,则需要HJ_BUF_GLOBAL_SIZE ,HJ_BLK_SIZE合理设置,层次查询过多,则需要设置合理的CNNTB_OPT_FLAG;(3)受目标环境影响(生产环境,测试环境)(4)受适配源端数据库影响等;这里提供一种思路,大量的参数,需要一一去测试验证了解,这就需要非常了解产品的数据库DBA或数据库设计人员,在实践中一一去优化,形成适合自己产品的标准参数工艺。然后复用不断优化,才能深度的和产品融合,这才能真正用好数据库。达梦有700多个参数,每个参数的具体取值,需要根据产品特性来调整的。如下总结的 这些影响数据库性能的参数,其取值,需要根据实际产品特性具体调整,不能照搬。这里的取值只供参考:
|
参数名称 |
参数值 |
参数说明 |
|
MEMORY_POOL |
80 |
避免频繁向系统申请内存 |
|
BUFFER |
100 |
总内存的50%,根据机器实际内存调整 |
|
BUFFER_POOLS |
1 |
减少数据缓存区冲突 |
|
MAX_BUFFER |
100 |
最大buffer大小,一般调整至机器内存的55%左右,根据机器实际内存调整 |
|
MAX_SESSIONS |
100 |
最大会话数 |
|
MAX_SESSION_STATEMENT |
100 |
回话允许打开最大句柄数 |
|
ENABLE_MONITOR |
2 |
动态监控,上线系统设置为0 |
|
COMPATIBLE_MODE |
2 |
兼容Oracle参数 |
|
PARALLEL_THRD_NUM |
10 |
多线程任务 |
|
MAX_OS_MEMORY |
95 |
DM 服务器能使用的最大内存占操作系统物理内存与虚拟内存总和的百分比 |
|
MEMORY_TARGET |
0 |
共享内存池在扩充到此大小以上后,空闲时收缩回此指定大小,以 M 为单位 |
|
MEMORY_LEAK_CHECK |
0 |
所有内存池的泄漏检查 |
|
MEMORY_MAGIC_CHECK |
2 |
对所有内存池的校验 0 :不开启 |
|
FAST_POOL_PAGES |
3000 |
快速缓冲区页数 |
|
FAST_ROLL_PAGES |
1000 |
快速回滚缓冲区页数 |
|
RECYCLE_POOLS |
19 |
RECYCLE 缓冲区分区数 |
|
MULTI_PAGE_GET_NUM |
1 |
缓冲区最多一次读取的页面数 |
|
SORT_BUF_SIZE |
2 |
排序缓存区最大值,以 M 为单位 |
|
HJ_BUF_GLOBAL_SIZE |
500 |
HASH 连接操作符的数据总缓存大小>= HJ_BUF_SIZE ),系统级参数,以兆为单位。 |
|
HJ_BLK_SIZE |
1 |
HASH 连接操作符每次分配缓存( BLK )以兆为单位,必须小于 HJ_BUF_SIZE 。 |
|
DICT_BUF_SIZE |
5 |
字典缓冲区大小,以兆为单位 |
|
N_MEM_POOLS |
1 |
内存池的数量 |
|
LIKE_OPT_FLAG |
7 |
LIKE 查询的优化开关 |
|
VIEW_PULLUP_FLAG |
0 |
是否对视图进行上拉优化,把视图转换为其原始定义,消除视图 |
|
PARTIAL_JOIN_EVALUATION_FLAG |
1 |
是否对去除重复值操作的下层连接进行转换优化 |
|
USE_FK_REMOVE_TABLES_FLAG |
1 |
是否利用外键约束消除冗余表 |
|
SEL_ITEM_HTAB_FLAG |
0 |
当查询项中有相关子查询时,是否做 HTAB 优化。 |
|
CASE_WHEN_CVT_IFUN |
5 |
是否将 CASE WHEN THEN ELSE END 语句转换为 IFOPERATOR 函数 |
|
ORDER_BY_NULLS_FLAG |
0 |
ASC 升序排序时,控制 NULL 值返回的位置。 |
|
CNNTB_OPT_FLAG |
0 |
是否使用优化的层次查询执行机制 |
|
ADAPTIVE_NPLN_FLAG |
3 |
是否启用自适应计划机制,仅OPTIMIZER_MODE=1 时生效。 |
|
VIEW_FILTER_MERGING |
2 |
是否对视图条件进行合并优化以及如何优化 |
|
CKPT_INTERVAL |
300 |
指定检查点的时间间隔。 |
|
EXPR_N_LEVEL |
200 |
表达式最大嵌套层数 |
|
CACHE_POOL_SIZE |
20 |
SQL 缓冲池大小,以兆为单位 |
|
STAT_ALL |
0 |
在估算分区表行数时, 控制一些优化。 |
|
OPTIMIZER_AGGR_GROUPBY_ELIM |
1 |
当对派生视图进行分组查询,且分组项是派生视图分组项的子集时,是否考虑两层分组进行合并。 |
|
RLOG_PARALLEL_ENABLE |
0 |
是否启动并行日志 |
|
RLOG_APPEND_LOGIC |
0 |
是否启用在日志中记录逻辑操作的功能 |
|
UNDO_RETENTION |
90 |
事务提交后回滚页保持时间,单位为秒 |
跟踪存储过程中的慢SQL思路
当我们拿到一个慢存储过程,而且涉及比较复杂的逻辑时候,我们应该如何入手?(1)先要获取存储过程的传递参数,有时候可以找开发人员获取,进行调试,当开发人员给的参数执行可以调试的存储过程并不慢,那我们应该如何处理呢?
(2)有些存储过程,可能特定的传参才会导致他的缓慢,这个时候,可以获取到存储过程的传参,通过专业SQL分析工具或使用达梦客户端工具进行调试,并分析缓慢的原因。
(3)存储过程一般都是统计运算类的,一般情况下是可以反复调用的,这个时候,我们一定要确定好,不能盲目执行,避免造成数据错乱,当确定可以调试后,我们就用达梦的客户端调试工具进行调试,我们可以适当在存储过程中打print输出时间,调用完成后,看下在哪一段执行过慢,这样有针对性的优化。
(4)对于有些不能调试的存储过程,我们如何处理呢?这里我在跟踪SQL慢方式中,我们先手动改好,把改写好的存储过程,更新到仿真测试环境,把可能影响性能的SQL都改写成动态嵌套SQL_INFO中,这样就可以在日志表中获取慢SQL了。
性能辅助分析工具
达梦丰富的性能优化辅助工具,能帮助DBA更好的定位问题,给我们日常SQL分析带来了很大的帮助,在预估执行计划不准情况下,我们可以利用性能辅助工具,来处理,举个例子,比如我们存储过程的性能问题,则可以通过ET来看大概性能分布情况,这样就更有效的知道什么操作符造成的。为什么要看实时执行计划?其主要原因还是,预估执行计划可能并不准确。
使用如下工具默认都要检查如下三个参数,否则无法使用:参数1,2默认开启:–内存参数DM.INI直接修改,需要重启动生效,默认一般已经开启。
SP_SET_PARA_VALUE(1,‘ENABLE_MONITOR’,1);SP_SET_PARA_VALUE(1,‘MONITOR_TIME’,1);
参数3会话级别开启:---会话参数,建议遇到问题,当前会话开启即可,不建议参数级别开启;MONITOR_SQL_EXEC为会话级动态参数,可以设置只针对当前会话开启:
SF_SET_SESSION_PARA_VALUE(‘MONITOR_SQL_EXEC’,1);
3.1达梦ET工具使用
在使用ET工具前检查ENABLE_MONITOR,MONITOR_TIME是否开启,默认配置都是开启状态,我们再检查下MONITOR_SQL_EXEC,如果没有开启,在直接在要执行SQL的会话窗口先执行:
SF_SET_SESSION_PARA_VALUE(‘MONITOR_SQL_EXEC’,1);3.1.1 执行了此参数之后,执行我们要跟踪的SQL,点击执行号,就可以弹出分析了;
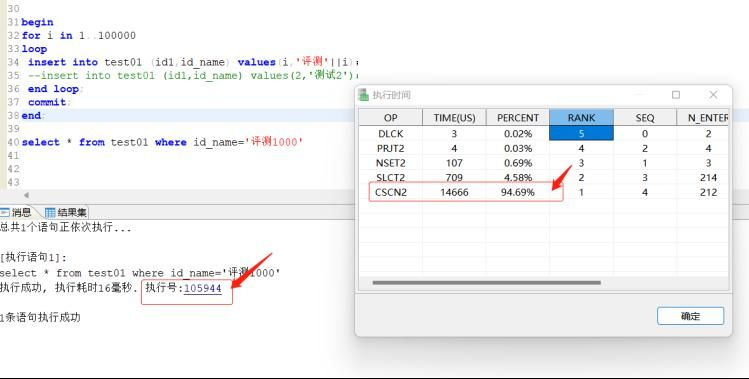
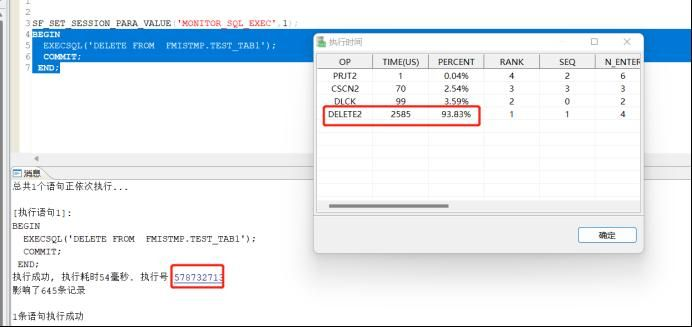
3.1.2 ET工具还可以分析存储过程,当存储过程执行比较慢的时候,我们调用后,也可以点击执行号,看他的执行占用备份比,我们通常是看PERCENT百分比,这个通常能代表,哪一个操作符耗时比较长。
用例:
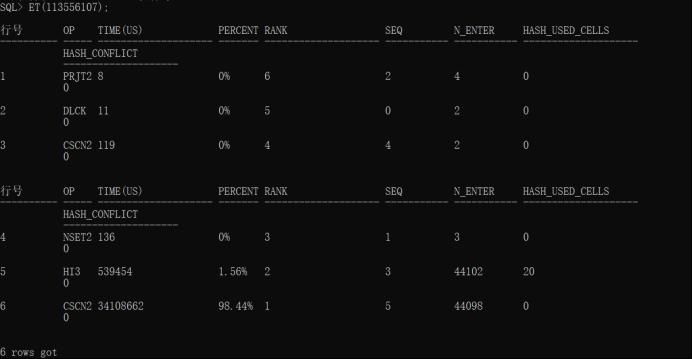
3.1.3在DISQL中也可以使用
操作方法:ET(执行号);
3.2、v$cachepln中如何获取历史执行计划v$cachepln保存了历史的SQL缓存计划,平常我们在跟踪问题的时候,也可以分析它的历史缓存计划是否是最优,把历史计划生成出来,此功能对标Oracle的V$SQL_PLAN_STATISTICS_ALL只是获取方式有所差异,今天演示下达梦的获取方法:步骤1:我们先查询下v$cachepln,获得我前面执行SQL产生的缓存计划的CACHE_ITEM我们以此测试SQL语句为例,先执行:
select a.dxid from TEST_TAB1 a,TEST_TAB2 bwhere a.dxid=b.dxid;
再查询
SELECT * FROM v$cachepln WHERE SQLSTR LIKE ‘%TEST_TAB1%’;–140357593086048步骤2:再通过调用生成执历史执行计划语句,主要通过步骤1获取得CACHE_ITEM,以及DUMP_FILE指定服务器目录生成历史缓存执行计划信息;
alter session set events ‘immediate trace name plndump level 140357593086048, dump_file ‘’/home/dmdba/140357593086048.log’‘’;步骤3:登录服务器在/home/dmdba/140357593086048.log 找到此文件,即可获取历史缓存执行计划信息;
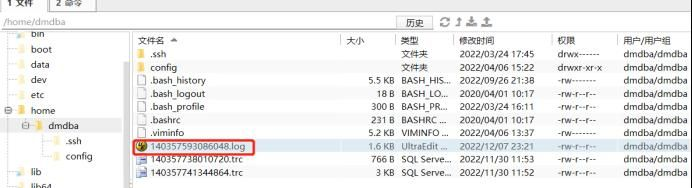
打开140357593086048.log文件
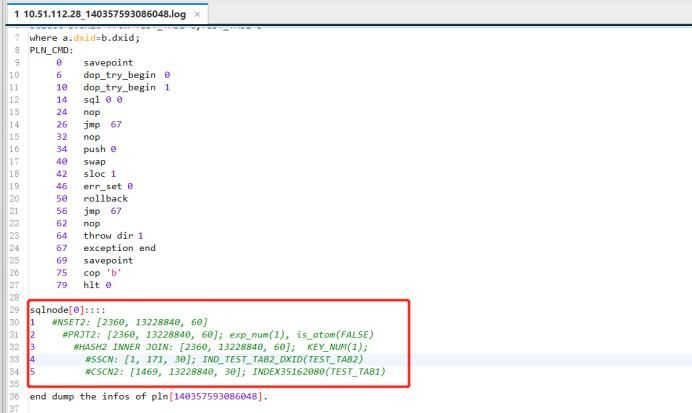
如上就是v$cachepln如何获取历史的缓存执行计划,这个可以结合分析当前SQL语句性能问题,判定缓存计划是否有问题,如果历史的执行计划错误的,我们还可以通过SP_CLEAR_PLAN_CACHE(cache_item)来清理;如果要全部清理,也可以直接使用call SP_CLEAR_PLAN_CACHE();3.3、实际执行计划和统计信息的跟踪
set autotrace <OFF(默认值) | NL | INDEX | ON|TRACE> ;参数详解:
(1)当SET AUTOTRACE OFF 停止 AUTOTRACE 功能,常规执行语句;(2)当SET AUTOTRACE NL 时,开启 AUTOTRACE 功能,不执行语句,如果执行计划中有嵌套循环操作,那么打印 NL 操作符的内容;(3)当 SET AUTOTRACE INDEX(或者 ON)时,开启 AUTOTRACE 功能,不执行语句,如果有表扫描,那么打印执行计划中表扫描的方式、表名和索引。(4)当 SET AUTOTRACE TRACE 时,开启 AUTOTRACE 功能,执行语句,打印执行计划。
此功能与服务器 EXPLAIN 语句的区别在于,EXPLAIN 只生成执行计划,并不会真正执行SQL 语句,因此产生的执行计划有可能不准。而 TRACE 获得的执行计划,是服务器实际执行的计划 —来自《DM8_DIsql使用手册.pdf》说明手册。
预估执行计划:我们看结果集,实际SQL,关联就20条记录,但是结果集显示是:2619310,这个是明显不准确的,这样的前提下,执行性能也是不高的;
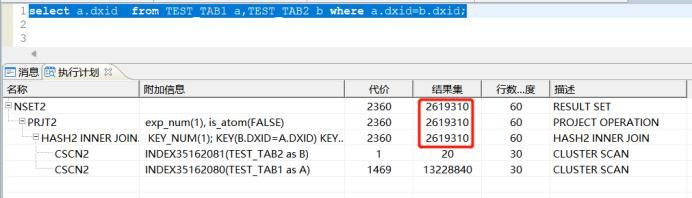
如上预估执行计划不准的情况下,我们需要的是服务器实际的执行计划,所以需要如下
设置SET AUTOTRACE TRACE来获取。
实操如下:当登录DISQL后
SQL> ALTER SESSION SET ‘MONITOR_SQL_EXEC’=1;DMSQL 过程已成功完成已用时间: 174.805(毫秒). 执行号:106510701.SQL> set autotrace TRACE;SQL> select a.dxid from TEST_TAB1 a,TEST_TAB2 b where a.dxid=b.dxid;已用时间: 66.393(毫秒). 执行号:112458304.SQL> select a.dxid from TEST_TAB1 a,TEST_TAB2 b where a.dxid=b.dxid;行号 DXID1 114871462 2795284553 2796592384 2800970105 2835713386 2804392067 2854476848 2906221859 28543597710 28543597411 272522356…20 rows got1 #NSET2: [2360, 2619310->0, 60]2 #PRJT2: [2360, 2619310->0, 60]; exp_num(1), is_atom(FALSE)3 #HASH2 INNER JOIN: [2360, 2619310->0, 60]; KEY_NUM(1);4 #CSCN2: [1, 20, 30]; INDEX35162081(TEST_TAB2)5 #CSCN2: [1469, 13228840->11668240, 30]; INDEX35162080(TEST_TAB1)
说明:如上案例是服务器真实的执行计划。由于测试需要,制造SQL统计信息异常,预估执行计划可能是不准确的,但是实际set autotrace TRACE 后就是其真实服务器的执行计划,使用set autotrace TRACE后,我们可以看到带箭头的[2360, 2619310->0, 60][实际计划代价,结果,显示长度],而预估执行计划应该是这样显示[2360, 2619310, 60],和实际计划对比相差太远;预估计划结果2619310,实际是0,这就明显不对了,根据经验看,是未收集统计信息导致,收集后计划后,记录数就准确了。

跟踪慢SQL的常用方式
4.1、慢SQL实时抓取
达梦数据库开启参数后,SQL实时执行就可以抓取了,通过简单SQL就可以抓取。通常在运行过程中,遇到用户反馈系统比较慢的时候,我们都可以先用此SQL查询下,如果加压大量SQL长时间未处理,而且都是重复的,则有2个可能性:第1种可能性,这个是频繁SQL,但是遇到了某个慢SQL导致数据库整体事务处理能下降了;第2种可能性,就是本身此SQL就有问题,这样给我们快速响应数据库带来了问题。
Select'sP_close_session('||sess_id||');' ,datediff(ss, last_recv_time, sysdate) ss ,cast(sf_get_session_sql(sess_id) as varchar) sql,*fromv$sessionswherestate='ACTIVE'order bylast_send_time;
说明:拼接了结束会话的sP_close_session,可以快速导出结束异常会话,如果时间无法获取则要v$dm_ini检查下ENABLE_MONITOR是否开启(1:打开;0:关闭),否则时间获取不到,就无法统计时间了;
4.2、SQL_INFO跟踪性能语句
通常存储过程慢SQL并不好抓取,在不是很好抓取的时候,我们可以采用性能分析工具里说的达梦DEBUG工具,但是有些无法调试的,我们怎么办呢?这个时候,我们可以改写待跟踪的存储过程,在把要跟踪的SQL嵌套到SQL_INFO中,这样有性能的SQL就可以写入日志表SQL_LOG了;实践中,改写存储过程需要有一定数据库开发能力的小伙伴来处理,我这里提供的是一种跟踪的性能方式;
--创建性能跟踪表--DROP TABLE SQL_LOG;CREATE TABLE SQL_LOG(GID VARCHAR2(100), --GUID"USER_NAME" VARCHAR2(32) , --当前用户"START_TIME" TIMESTAMP(0), --SQL开始执行时间"END_TIME" TIMESTAMP(0) , --SQL执行结束时间"SQL_TEXT" VARCHAR2(4000),--SQL执行语句"ROW_COUNT" NUMBER(15) , --记录数"LOG_TYPE" VARCHAR2(20) , --完成是SUCCESSFUL,报错是FAILED"SESSION_ID" NUMBER(38, 0) , --会话ID"LOG_DETAIL" VARCHAR2(2000), --错误信息"INT_STACK" VARCHAR2(4000), ----堆栈信息"SQL_TIMES" NUMBER(10, 2) --记录SQL执行时间);CREATE INDEX IND_SQL_LOG_SQLTEXT ON SQL_LOG(SQL_TEXT);/--创建跟踪过程CREATE OR REPLACE PROCEDURE SQL_INFO("I_SQLSTART" IN VARCHAR2(32000))AS--说明:跟踪存储过程中某些慢SQL,跟踪大于0.1的SQL,根据场景可以改写V_ROWCOUNT INT;V_TIME DATE; --定义时间V_ERRMSG VARCHAR2(5000); --获取异常记录V_SQLTEXT VARCHAR2(32767); --获取传递的记录V_SQLTEXT_INS VARCHAR2(9000); --SQL记录V_CURTIME NUMBER(20,2); --开始时间V_USETIME NUMBER(20,2); --使用时间V_SESSION NUMBER(30); --SID记录V_INT_STACK VARCHAR2(4000);BEGINV_TIME:=SYSDATE;V_CURTIME:=DBMS_UTILITY.GET_TIME;V_SQLTEXT:=TRIM(I_SQLSTART);WHILE INSTR(V_SQLTEXT,' ')>0 LOOPV_SQLTEXT:=REPLACE(V_SQLTEXT,' ',' ');END LOOP;--执行主体EXECUTEIMMEDIATEEXECUTE IMMEDIATE V_SQLTEXT;V_ROWCOUNT:=SQL%ROWCOUNT;V_USETIME:=(DBMS_UTILITY.GET_TIME-V_CURTIME)/100;--这里调整多少秒的记录写入到SQL_LOG日志表中,这个可以嵌套到性能表里IF V_USETIME>=0.1 THENV_SQLTEXT_INS:=TRIM(SUBSTRB(V_SQLTEXT,1,4000));--达梦单列VARCHAR2可以存储9000以上,如果SQL够长,我们可以改大些V_SESSION:=SESSID;--会话SIDV_INT_STACK:=DBMS_UTILITY.FORMAT_CALL_STACK;INSERT INTO SQL_LOG(GID,USER_NAME,START_TIME,END_TIME,SQL_TEXT,ROW_COUNT,LOG_TYPE,SESSION_ID,INT_STACK,SQL_TIMES)VALUES (GUID(),USER,V_TIME,SYSDATE,V_SQLTEXT_INS,V_ROWCOUNT,'SUCCESSFUL',V_SESSION,V_INT_STACK,V_USETIME);END IF;EXCEPTION--如果SQL中执行异常,也会写SQL_LOG中,方便我们分析错误语句WHEN OTHERS THENROLLBACK;V_ERRMSG:=SQLERRM(SQLCODE);V_INT_STACK:=DBMS_UTILITY.FORMAT_CALL_STACK;V_SQLTEXT_INS:=TRIM(SUBSTRB(I_SQLSTART,1,4000));--达梦VARCHAR2可以存储9000以上,如果SQL够长,我们可以改大些V_USETIME:=(DBMS_UTILITY.GET_TIME-V_CURTIME)/100;INSERT INTO SQL_LOG(GID,USER_NAME,START_TIME,END_TIME,SQL_TEXT,LOG_TYPE,SESSION_ID,LOG_DETAIL,INT_STACK,SQL_TIMES)VALUES (GUID(),USER,V_TIME,SYSDATE,V_SQLTEXT_INS,'FAILED',V_SESSION,V_ERRMSG,V_INT_STACK,V_USETIME);COMMIT;RAISE;END SQL_INFO;
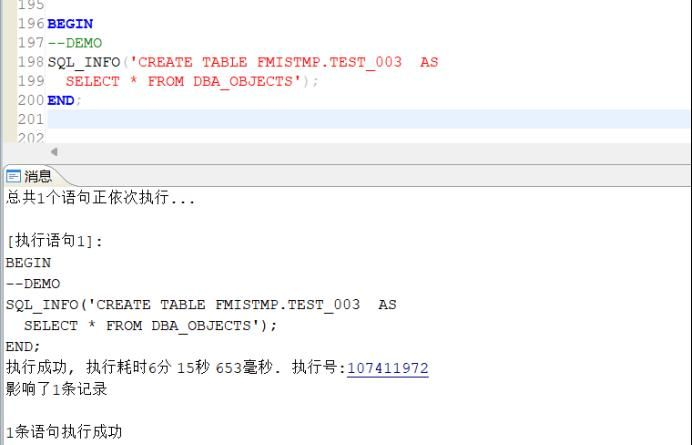
样例演示:–查看跟踪到执行这个DEMO语句的时间:
BEGIN–DEMOSQL_INFO(‘CREATE TABLE FMISTMP.TEST_003 ASSELECT * FROM DBA_OBJECTS’);END;
SELECT * FROM SQL_LOG WHERE SQL_TEXT LIKE ‘CREATE TABLE FMISTMP.TEST_003%’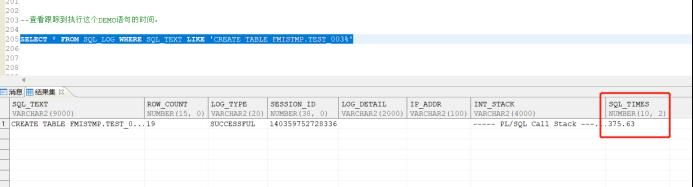
以上只是举例一个简单的创建备份表进行演示,实际上存储过程中很多动态拼接语句,都是可以放到SQL_INFO中,然后在执行过程中就可以跟踪到他的SQL是那一句慢了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号