

转 pt-query-digest 使用实例
##samlple 0
pt-query-digest 官方文档
pt-query-digest - Analyze MySQL queries from logs, processlist, and tcpdump.
SYNOPSIS
Usage
pt-query-digest [OPTIONS] [FILES] [DSN]
pt-query-digest analyzes MySQL queries from slow, general, and binary log files. It can also analyze queries
from SHOW PROCESSLIST and MySQL protocol data from tcpdump. By default, queries are grouped by fingerprint
and reported in descending order of query time (i.e. the slowest queries first). If no FILES are given, the tool reads
STDIN. The optional DSN is used for certain options like --since and --until.
Report the slowest queries from slow.log:
->pt-query-digest slow.log
Report the slowest queries from the processlist on host1:
pt-query-digest --processlist h=host1
->Capture MySQL protocol data with tcppdump, then report the slowest queries:
tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txt
pt-query-digest --type tcpdump mysql.tcp.txt
->Save query data from slow.log to host2 for later review and trend analysis:
pt-query-digest --review h=host2 --no-report slow.log
注意:
pt-query-digest 在采集本地慢查询日志到 远端管理数据库时候,有的时候出现消耗一个cpu 100%资源的情况
可能原因是跟这个虚拟机本地磁盘I/O 瓶颈有关,需要读本地slow.log
规避方法
run it with nice -n 19 and then its priority will be so low that everything else gets priority.
nice -n 19 使用见下文
http://blog.chinaunix.net/uid-9950859-id-98406.html
## sample 1
https://www.cnblogs.com/moss_tan_jun/p/8025517.html
感谢moss_tan_jun
-》如何通过慢查询日志找出有问题的SQL
查询次数多且每次查询时间较长的sql
通常为pt-query-digest分析的前个查询
IO大的SQL(数据库的瓶颈之一是IO)
注意pt-query-digest分析结果中 Rows examine项
未命中索引的SQL
注意pt-query-digest分析结果中 Rows examine很大 但是Rows Sent很小
-》通过explain分析SQL
->索引优化
如何选择合适的列建立索引
###sample 2
https://aws.amazon.com/cn/blogs/china/pt-query-digest-rds-mysql-slow-searchnew/
感谢闫静
实际案例
这里描述一个实际的案例,在 RDS MySQL 碰到性能问题时,我们如何通过 pt-query-digest 工具来分析性能,找到其中的问题所在。
发现问题
某一天突然发现 RDS MySQL CPU 利用率高达100%,平时正常运行几乎都在40%以下,怀疑 MySQL 数据库之前运行了一些问题 SQL 语句导致了 CPU 资源的飙升。
分析问题
这里我们首先来获取13:00-14:00这一个小时范围内的 RDS MySQL slow log ,然后再使用我们前面部署的 pt-query-digest 工具来分析一下,看是否可以发现一些端倪。
[root@ip-172-31-36-44 ~]# mysql -h mysql. xxxxxxxxxxxx.rds.cn-northwest-1.amazonaws.com.cn -u root -p -P13306 -D mysql -s -r -e "SELECT CONCAT( '# Time: ', DATE_FORMAT(start_time, '%y%m%d %H%i%s'), '\n', '# User@Host: ', user_host, '\n', '# Query_time: ', TIME_TO_SEC(query_time), ' Lock_time: ', TIME_TO_SEC(lock_time), ' Rows_sent: ', rows_sent, ' Rows_examined: ', rows_examined, '\n', sql_text, ';' ) FROM mysql.slow_log where DATE_FORMAT(start_time, '%Y%m%d %H:%i:%s') between '20190328 13:00:00' and '20190328 14:00:00' " > /tmp/slow.log.1314.log
Enter password:
[root@ip-172-31-36-44 ~]#
[root@ip-172-31-36-44 ~]#
[root@ip-172-31-36-44 ~]# pt-query-digest --report /tmp/slow.log.1314.log> /tmp/report.1314.log
[root@ip-172-31-36-44 ~]#
[root@ip-172-31-36-44 ~]# cat /tmp/report.1314.log
# 220ms user time, 30ms system time, 27.48M rss, 221.73M vsz
# Current date: Thu Mar 28 06:03:53 2019
# Hostname: ip-172-31-36-44.cn-northwest-1.compute.internal
# Files: /tmp/slow.log.1314.log
# Overall: 255 total, 4 unique, 0 QPS, 0x concurrency ____________________
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 9360s 5s 62s 37s 49s 8s 35s
# Lock time 0 0 0 0 0 0 0
# Rows sent 3.12k 0 266 12.52 0 54.70 0
# Rows examine 1.85G 1.88M 12.99M 7.45M 9.30M 1.35M 6.94M
# Query size 2.42M 78 114.10k 9.72k 79.83k 28.60k 212.52
# Time 46.29M 185.87k 185.87k 185.87k 185.87k 0 185.87k
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== ============================== =============== ===== ======= =====
# 1 0x582C46632FB388ABE5D178303... 7913.0000 84.5% 216 36.6343 1.57 SELECT MLModel?_ecgw_a_pred
# 2 0x0E39F3F13EDA325B4E53D0244... 971.0000 10.4% 25 38.8400 2.04 INSERT slph_adjust_his
# 3 0x3FC5160B3B25069FA843DC222... 466.0000 5.0% 12 38.8333 1.53 SELECT MLModel?_jd_pred unit_info MLModel?_jd_pred
# MISC 0xMISC 10.0000 0.1% 2 5.0000 0.0 <1 ITEMS>
# Query 1: 0 QPS, 0x concurrency, ID 0x582C46632FB388ABE5D178303E079908 at byte 420282
# This item is included in the report because it matches --limit.
# Scores: V/M = 1.57
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 84 216
# Exec time 84 7913s 20s 57s 37s 49s 8s 35s
# Lock time 0 0 0 0 0 0 0 0
# Rows sent 0 0 0 0 0 0 0 0
# Rows examine 79 1.48G 7.01M 7.02M 7.02M 6.94M 0 6.94M
# Query size 1 47.02k 222 223 222.89 212.52 0 212.52
# Time 84 39.21M 185.87k 185.87k 185.87k 185.87k 0 185.87k
# String:
# Hosts 172.31.39.23 (120/55%), 172.31.46.35 (36/16%)... 3 more
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS LIKE 'MLModel6_ecgw_a_pred'\G
# SHOW CREATE TABLE `MLModel6_ecgw_a_pred`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT * FROM MLModel6_ecgw_a_pred
where unitname = 395 and forecast48hr >= now()
and forecast48hr < NOW() + INTERVAL 1 HOUR
order by predTime desc
limit 1\G
# Query 2: 0 QPS, 0x concurrency, ID 0x0E39F3F13EDA325B4E53D0244F2E9A23 at byte 210412
..............
..............
..............
从上面我们可以看到排在第一位的 SQL 语句在本次分析中总的时间占比高达84%,且单次调用耗时在36秒。接下来我们看看 SQL 语句的情况:
mysql> SELECT * FROM MLModel6_ecgw_a_pred
-> where unitname = 395 and forecast48hr >= now()
-> and forecast48hr < NOW() + INTERVAL 1 HOUR
-> order by predTime desc
-> limit 1
-> ;
Empty set (39.59 sec)
mysql> explain SELECT * FROM MLModel6_ecgw_a_pred
-> where unitname = 395 and forecast48hr >= now()
-> and forecast48hr < NOW() + INTERVAL 1 HOUR
-> order by predTime desc
-> limit 1;
+----+-------------+----------------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | MLModel6_ecgw_a_pred | NULL | index | idx_un | idx_un1 | 15 | NULL | 325 | 0.03 | Using where; Backward index scan |
+----+-------------+----------------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.02 sec)
mysql> show index from MLModel6_ecgw_a_pred;
+----------------------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+----------------------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| MLModel6_ecgw_a_pred | 0 | PRIMARY | 1 | id | A | 6899295 | NULL | NULL | | BTREE | | | YES | NULL |
| MLModel6_ecgw_a_pred | 1 | idx_un | 1 | forecast48hr | A | 60106 | NULL | NULL | YES | BTREE | | | YES | NULL |
| MLModel6_ecgw_a_pred | 1 | idx_un | 2 | UNITNAME | A | 352164 | NULL | NULL | YES | BTREE | | | YES | NULL |
| MLModel6_ecgw_a_pred | 1 | idx_un1 | 1 | predTime | A | 112492 | NULL | NULL | YES | BTREE | | | YES | NULL |
| MLModel6_ecgw_a_pred | 1 | idx_un1 | 2 | UNITNAME | A | 162489 | NULL | NULL | YES | BTREE | | | YES | NULL |
+----------------------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
5 rows in set (0.10 sec)
mysql>
从上面我们不难看出,此 SQL 语句使用了错误的索引 idx_un1 ,实际上使用 idx_un 索引选择性会更好,执行效率会更高。
解决问题
强制此 SQL 语句使用正确的索引,不到1秒就执行完毕:
mysql> SELECT * FROM MLModel6_ecgw_a_pred force index(idx_un)
-> where unitname = 395 and forecast48hr >= now()
-> and forecast48hr < NOW() + INTERVAL 1 HOUR
-> order by predTime desc
-> limit 1
-> ;
Empty set (0.03 sec)
mysql>
后续就是具体的优化工作,至于是优化索引设置,还是去调整SQL语句,可以根据实际情况来进行即可。
总结
pt-query-digest 是一个针对 MySQL slow log 进行分析的工具,可以获得更友好、易读、更人性化的 SQL 性能汇总及分析报告;
RDS MySQL 由于是托管的数据库,我们可以使用 awscli RDS API 或者以 MySQL sql 脚本来分别将 FILE 和 TABLE 形式的慢查询日志获取到本地,然后再使用 pt-query-digest 进行分析;
Percona Toolkit 是业界比较知名的 MySQL 工具集,里面包含多种可以提升效率的管理工具,除了 pt-query-digest 使用较多之外,还有 pt-online-schema-change 、 pt-mysql-summary 、 pt-summary 等工具被广泛使用,推荐有兴趣的同学可以尝试使用;
###samlple 3
https://blog.csdn.net/anzhen0429/article/details/77828927
感谢anzhen0429
案例背景:
线上某台mysql生产库服务器,CPU负载告警,使用率持续接近100%,丝毫没有回落的意思!
1. 性能表象的数据采集
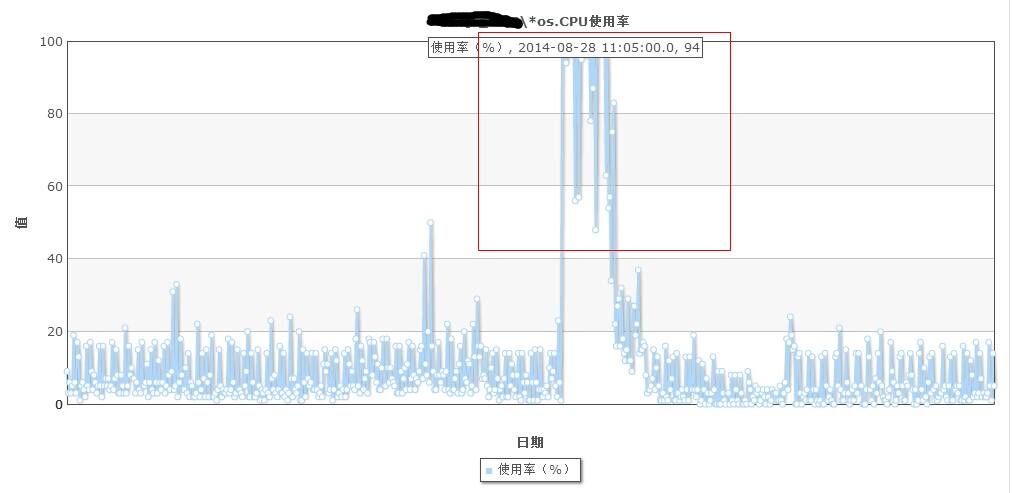
登陆DB服务器 : 、mysql进程的CPU占用率765.9%(8核),CPU基本上消耗殆尽!

2. 问题全面诊断:
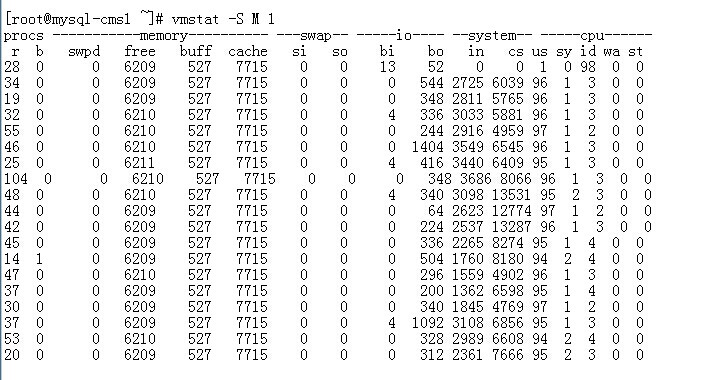
结论:
内存,磁盘都不是问题,中断请求数还算可以接受,CPU出现性能瓶颈,有大量任务等待CPU时间片;
基本上可以断定是单纯的CPU问题,且是由于mysql进程引发;
根据CPU负载模型,可以断定出问题的地方:(用户态的CPU使用率是瓶颈)
1. mysql进行大量的内存操作,逻辑读;例如:缺失关键索引
2. 大量的CPU运算任务;例如:2表的笛卡尔积
3. MySQL层性能采集
此处可以考虑使用慢日志,由于磁盘不是瓶颈,不会带来太大的额外负载;
这里我采用tcpdump和pt-query-digest来抓问题SQL;
监控:
tcpdump -i eth0 -s 65535 -x -nn -q -tttt port 3306 -c 200000 > 1.dmp &
分析:
pt-query-digest --type tcpdump 1.dmp --limit 10 > report.log
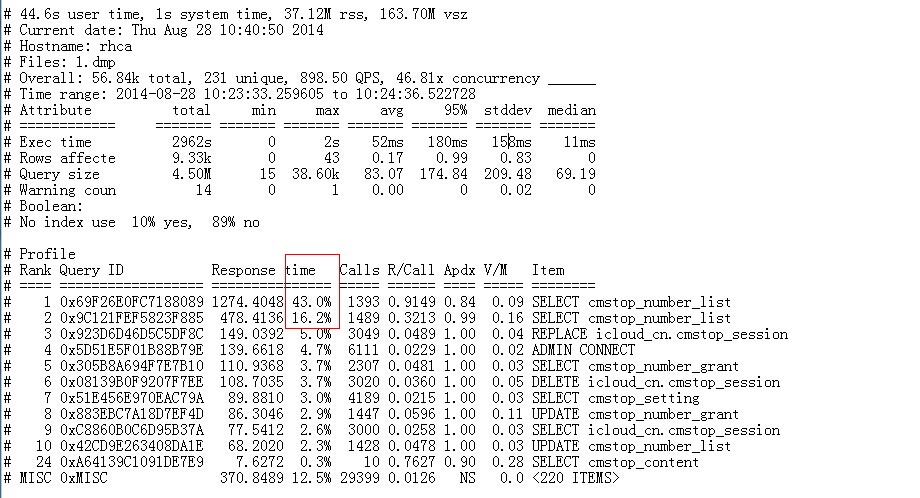
基本上搞定TOP2SQL,问题就能得到缓解;
这2语句的执行时间基本是在1S的样子,且消耗了大量CPU时间:
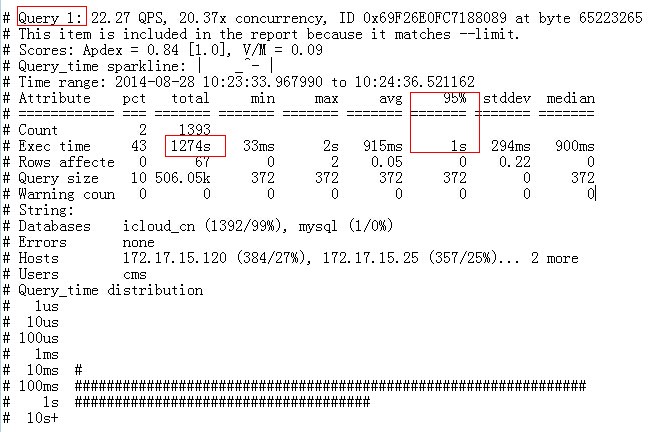
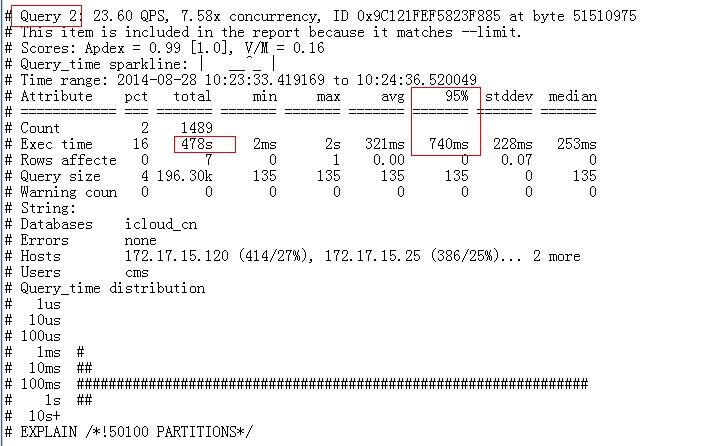
SQL优化:
TOP 1 SQL

同一个表访问了N次,且是select *,想必大家都知道怎么优化了吧!(吐槽一下!)
TOP 2 SQL

该语句基本上是全表扫描,优化的余地不多;select * 是一个,建一个复合索引,使用索引扫描替换全表扫描
###sanple如何分析pt-qurey_digest结果,如下分析
分析思路如下:
1.取问题发生前10分钟(4:58 - 5.11)的数据如下,该条sql 执行次数只有26次。
Response/call 代表着次数
说明:首段profile 是按照百分比排序找到从高到低的sql,quer2 执行了26次
# 6.5s user time, 70ms system time, 64.22M rss, 259.25M vsz
# Current date: Sat Mar 6 11:38:50 2021
# Hostname: paaa05
# Files: binlog.003291.txt
# Overall: 33.63k total, 27 unique, 5.76 QPS, 0.01x concurrency __________
# Time range: 2021-03-01 03:34:33 to 05:11:53
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ============================= ============= ===== ====== ===== ====
# 1 0x8D589AFA4DFAEEED85FFF5AA... 26.0000 50.0% 16628 0.0016 0.98 BEGIN
# 2 0x3D27CE44D0BFF17BCB10E25E... 26.0000 50.0% 26 1.0000 0.00 INSERT SELECT tt_tran_log_tmp tt_tran_LOG_?
# MISC 0xMISC 0.0000 0.0% 16973 0.0000 0.0 <21 ITEMS>
说明:后面一段是详细的sql 执行过程,显示的是query 2执行的详细记录吗,并发度为0.03
# Query 2: 0.03 QPS, 0.03x concurrency, ID 0x3D27CE44D0BFF17BCB10E25E166D57AA at byte 95843495
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: 2021-03-01 04:59:02 to 05:11:32
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 0 26
# Exec time 50 26s 1s 1s 1s 1s 0 1s
# Query size 0 14.62k 576 576 576 576 0 576
# error code 0 0 0 0 0 0 0 0
2.分析问题发生时间段的sql (2021-03-01 05:10:54 to 05:16:53)
说明:Quere2 执行了 5957次,
# 2.6s user time, 50ms system time, 64.23M rss, 259.25M vsz
# Current date: Sat Mar 6 15:43:32 2021
# Hostname: paaa05
# Files: binlog.003291_1.txt
# Overall: 13.65k total, 27 unique, 2.22 QPS, 4.13x concurrency __________
# Time range: 2021-03-01 03:34:33 to 05:16:53
Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== ============================= ================ ===== ======= =====
# 1 0x8D589AFA4DFAEEED85FFF5AA... 12675.0000 50.0% 6786 1.8678 16... BEGIN
# 2 0x16BE5B4E5C503E3DEE8A2CEC... 11345.0000 44.7% 5957 1.9045 16... INSERT tt_tran_log_?
# 3 0x4AD01374BE977D49E3B1AF25... 730.0000 2.9% 72 10.1389 16... DELETE aaaa_rsm_mem_ms
# MISC 0xMISC 604.0000 2.4% 835 0.7234 0.0 <20 ITEMS>
说明:Quer2 并发度是36,qps 是17,那么很明显问题出在该条sql 并发度过高导致的。
# Query 2: 16.59 QPS, 31.60x concurrency, ID 0x16BE5B4E5C503E3DEE8A2CECA18B25B3 at byte 14548719
# This item is included in the report because it matches --limit.
# Scores: V/M = 162.79
# Time range: 2021-03-01 05:10:54 to 05:16:53
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 43 5957
# Exec time 44 11345s 0 203s 2s 0 18s 0
# Query size 14 3.44M 577 664 605.99 592.07 6.04 592.07
# error code 0 0 0 0 0 0 0 0
# String:
# Databases aaaamondb
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `aaaamondb` LIKE 'tt_tran_log_20210301'\G
# SHOW CREATE TABLE `aaaamondb`.`tt_tran_log_20210301`\G
insert into tt_tran_log_20210301 (TERMINALNO, TRANSDATE, SERVICEID, CHANNELID, SYSTEMID, ESCSTATUS, CONSUMERFLOWNO, PROVIDERFLOWNO, BUSINESSFLOWNO, BUSINESSRESPCODE, BUSINESSRESPMSG, BUSINESSSTATUS, TRANSSTAMP1, TRANSSTAMP2, TRANSSTAMP3, TRANSSTAMP4, TRANSSTAMP, FLOWLOCATION, ESCFLOWNO) values ('G

