



转 python3中SQLLIT编码与解码之Unicode与bytes 和 小工具 python2 (自动)转print 到python3
#########sample##########
sqlite3.OperationalError: Could not decode to UTF-8 column 'logtype' with text
将
with connection.cursor() as c:
c.execute("select id,name from district_info where p_id=0")
provinces = c.fetchall()
调整为
con = sqlite3.connect('./db.sqlite3')
# con.text_factory = bytes
con.text_factory = lambda x: str(x, 'gbk', 'ignore')
cur = con.cursor()
# with connection.cursor() as c:
c=cur.execute("select id,name from district_info where p_id=0")
provinces = c.fetchall()
return JsonResponse(provinces, safe=False)
############################
https://docs.python.org/3/library/sqlite3.html?highlight=conn%20text_factory%20str
https://docs.python.org/3/library/sqlite3.html?highlight=conn%20text_factory%20str
https://blog.csdn.net/chb4715/article/details/79104299 ( python3中编码与解码之Unicode与bytes)
https://www.cnblogs.com/lightwind/p/4499193.html (重要,python3中SQLLIT编码与解码之Unicode与bytes)
写这篇文章,起源于要写一个脚本批量把CSV文件(文件采用GBK或utf-8编码)写入到sqlite数据库里。
Python版本:2.7.9
sqlite3模块提供了con = sqlite3.connect("D:\\text_factory.db3") 这样的方法来创建数据库(当文件不存在时,新建库),数据库默认编码为UTF-8,支持使用特殊sql语句设置编码
PRAGMA encoding = "UTF-8";
PRAGMA encoding = "UTF-16";
PRAGMA encoding = "UTF-16le";
PRAGMA encoding = "UTF-16be";
但设置编码必须在main库之前,否则无法更改。 https://www.sqlite.org/pragma.html#pragma_encoding
认识text_factory属性,大家应该都是通过以下错误知晓的:
sqlite3.ProgrammingError: You must not use 8-bit bytestrings unless you use a text_factory that can interpret 8-bit bytestrings (like text_factory = str). It is highly recommended that you instead just switch your application to Unicode strings.
大意是推荐你把字符串入库之前转成unicode string,你要用bytestring字节型字符串(如ascii ,gbk,utf-8),需要加一条语句text_factory = str。
Python拥有两种字符串类型。标准字符串是单字节字符序列,允许包含二进制数据和嵌入的null字符。 Unicode 字符串是双字节字符序列,一个字符使用两个字节来保存,因此可以有最多65536种不同的unicode字符。尽管最新的Unicode标准支持最多100万个不同的字符,Python现在尚未支持这个最新的标准。
默认text_factory = unicode,原以为这unicode、str是函数指针,但貌似不是,是<type 'unicode'>和<type 'str'>
下面写了一段测试验证代码:

1 # -*- coding: utf-8 -*-
2 import sqlite3
3 '''
4 GBK UNIC UTF-8
5 B8A3 798F E7 A6 8F 福
6 D6DD 5DDE E5 B7 9E 州
7 '''
8
9 con = sqlite3.connect(":memory:")
10 # con = sqlite3.connect("D:\\text_factory1.db3")
11 # con.executescript('PRAGMA encoding = "UTF-16";')
12 cur = con.cursor()
13
14 a_text = "Fu Zhou"
15 gb_text = "\xB8\xA3\xD6\xDD"
16 utf8_text = "\xE7\xA6\x8F\xE5\xB7\x9E"
17 unicode_text= u"\u798F\u5DDE"
18
19 print 'Part 1: con.text_factory=str'
20 con.text_factory = str
21 print type(con.text_factory)
22 cur.execute("CREATE TABLE table1 (city);")
23 cur.execute("INSERT INTO table1 (city) VALUES (?);",(a_text,))
24 cur.execute("INSERT INTO table1 (city) VALUES (?);",(gb_text,))
25 cur.execute("INSERT INTO table1 (city) VALUES (?);",(utf8_text,))
26 cur.execute("INSERT INTO table1 (city) VALUES (?);",(unicode_text,))
27 cur.execute("select city from table1")
28 res = cur.fetchall()
29 print "-- result: %s"%(res)
30
31 print 'Part 2: con.text_factory=unicode'
32 con.text_factory = unicode
33 print type(con.text_factory)
34 cur.execute("CREATE TABLE table2 (city);")
35 cur.execute("INSERT INTO table2 (city) VALUES (?);",(a_text,))
36 # cur.execute("INSERT INTO table2 (city) VALUES (?);",(gb_text,))
37 # cur.execute("INSERT INTO table2 (city) VALUES (?);",(utf8_text,))
38 cur.execute("INSERT INTO table2 (city) VALUES (?);",(unicode_text,))
39 cur.execute("select city from table2")
40 res = cur.fetchall()
41 print "-- result: %s"%(res)
42
43 print 'Part 3: OptimizedUnicode'
44 con.text_factory = str
45 cur.execute("CREATE TABLE table3 (city);")
46 cur.execute("INSERT INTO table3 (city) VALUES (?);",(a_text,))
47 #cur.execute("INSERT INTO table3 (city) VALUES (?);",(gb_text,))
48 cur.execute("INSERT INTO table3 (city) VALUES (?);",(utf8_text,))
49 cur.execute("INSERT INTO table3 (city) VALUES (?);",(unicode_text,))
50 con.text_factory = sqlite3.OptimizedUnicode
51 print type(con.text_factory)
52 cur.execute("select city from table3")
53 res = cur.fetchall()
54 print "-- result: %s"%(res)
55
56 print 'Part 4: custom fuction'
57 con.text_factory = lambda x: unicode(x, "gbk", "ignore")
58 print type(con.text_factory)
59 cur.execute("CREATE TABLE table4 (city);")
60 cur.execute("INSERT INTO table4 (city) VALUES (?);",(a_text,))
61 cur.execute("INSERT INTO table4 (city) VALUES (?);",(gb_text,))
62 cur.execute("INSERT INTO table4 (city) VALUES (?);",(utf8_text,))
63 cur.execute("INSERT INTO table4 (city) VALUES (?);",(unicode_text,))
64 cur.execute("select city from table4")
65 res = cur.fetchall()
66 print "-- result: %s"%(res)
打印结果:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
Part 1: con.text_factory=str<type 'type'>-- result: [('Fu Zhou',), ('\xb8\xa3\xd6\xdd',), ('\xe7\xa6\x8f\xe5\xb7\x9e',), ('\xe7\xa6\x8f\xe5\xb7\x9e',)]Part 2: con.text_factory=unicode<type 'type'>-- result: [(u'Fu Zhou',), (u'\u798f\u5dde',)]Part 3: OptimizedUnicode<type 'type'>-- result: [('Fu Zhou',), (u'\u798f\u5dde',), (u'\u798f\u5dde',)]Part 4: custom fuction<type 'function'>-- result: [(u'Fu Zhou',), (u'\u798f\u5dde',), (u'\u7ec2\u5fd3\u7a9e',), (u'\u7ec2\u5fd3\u7a9e',)] |
Part 1:unicode被转换成了utf-8,utf-8和GBK被透传,写入数据库,GBK字符串被取出显示时,需要用类似'gbk chars'.decode("cp936").encode("utf_8")的语句进行解析print
Part 2:默认设置,注释的掉都会产生以上的经典错误,输入范围被限定在unicode对象或纯ascii码
Part 3:自动优化,ascii为str对象,非ascii转为unicode对象
Part 4:GBK被正确转换,utf-8和unicode在存入数据库时,都被转为了默认编码utf-8存储,既'\xe7\xa6\x8f\xe5\xb7\x9e',
In[16]: unicode('\xe7\xa6\x8f\xe5\xb7\x9e','gbk')
Out[16]: u'\u7ec2\u5fd3\u7a9e'
就得到了以上结果。
接着,用软件查看数据库里是如何存放的。
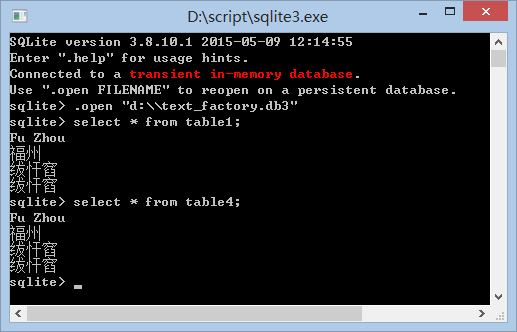
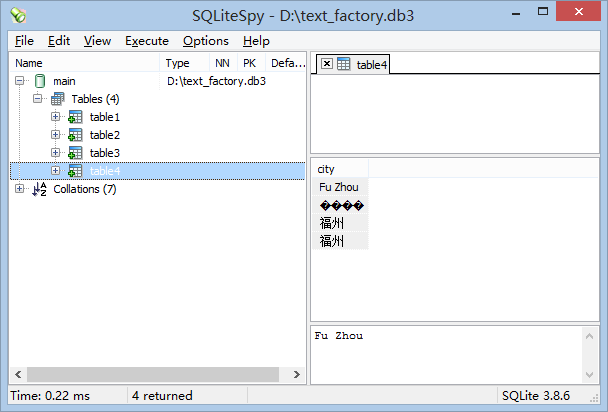
分别用官方的sqlite3.exe和SqliteSpy查看,sqlite3.exe因为用命令行界面,命令行用的是GBK显示;SqliteSpy则是用UTF显示,所以GBK显示乱码。这就再次印证了GBK被允许存放入数据库的时候,存放的是raw数据,并不会强制转为数据库的默认编码utf-8保存。
Connection.text_factory使用此属性来控制我们可以从TEXT类型得到什么对象(我:这也印证写入数据库的时候,需要自己编码,不能依靠这个)。默认情况下,这个属性被设置为Unicode,sqlite3模块将会为TEXT返回Unicode对象。若你想返回bytestring对象,可以将它设置为str。
因为效率的原因,还有一个只针对非ASCII数据,返回Unicode对象,其它数据则全部返回bytestring对象的方法。要激活它,将此属性设置为sqlite3.OptimizedUnicode。
你也可以将它设置为任意的其它callabel,接收一个bytestirng类型的参数,并返回结果对象。《摘自http://www.360doc.com/content/11/1102/10/4910_161017252.shtml》
以上一段话是官方文档的中文版关于text_factory描述的节选。
综上,我谈谈我的看法*和使用建议:
1)sqlite3模块执行insert时,写入的是raw数据,写入前会根据text_factory属性进行类型判断,默认判断写入的是否为unicode对象;
2)使用fetchall()从数据库读出时,会根据text_factory属性进行转化。
3)输入字符串是GBK编码的bytestring,decode转为unicode写入;或加text_factory=str直接写入,读出时仍为GBK,前提需要数据库编码为utf-8,注意用sqlitespy查看是乱码。
4)输入字符串是Utf-8编码的bytestring,可以设置text_factory=str直接写入直接读出,sqlitespy查看正常显示。
5)如果不是什么高性能场景,入库前转成unicode,性能开销也很小,测试数据找不到了,像我这样话一整天研究这一行代码,不如让机器每次多跑零点几秒。。
*(因为没有查看sqlite3模块的源代码,所以只是猜测)
另外,附上数据库设置为UTF-16编码时,产生的结果,更乱,不推荐。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
Part 1: con.text_factory=str<type 'type'>-- result: [('Fu Zhou',), ('\xc2\xb8\xc2\xa3\xef\xbf\xbd\xef\xbf\xbd',), ('\xe7\xa6\x8f\xe5\xb7\x9e',), ('\xe7\xa6\x8f\xe5\xb7\x9e',)]Part 2: con.text_factory=unicode<type 'type'>-- result: [(u'Fu Zhou',), (u'\u798f\u5dde',)]Part 3: OptimizedUnicode<type 'type'>-- result: [('Fu Zhou',), (u'\u798f\u5dde',), (u'\u798f\u5dde',)]Part 4: custom fuction<type 'function'>-- result: [(u'Fu Zhou',), (u'\u8d42\u62e2\u951f\u65a4\u62f7',), (u'\u7ec2\u5fd3\u7a9e',), (u'\u7ec2\u5fd3\u7a9e',)] |
##################
https://blog.csdn.net/xkxjy/article/details/8179479
环境:python3.2 sqllite3
代码如下:
import sqlite3 as sql
conn = sql.connect(r'c:\setupinfidb.db', detect_types=sql.PARSE_COLNAMES)
c = conn.cursor()
c.execute('select * from setuplog')
for row in c:
print(row)
运行以上代码时,提示:
Traceback (most recent call last):
File "sqlitetest.py", line x, in <module>
c.execute('select * from setuplog')
sqlite3.OperationalError: Could not decode to UTF-8 column 'logtype' with text '\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd'
这个意思是说column ‘logtype’ 不能通过UTF-8 decode,就是logtype不是用utf8编码的
一般情况下这个情况出现在text类型的数据上面
这个可以通过设置 conn.text_factory 解决
如 conn.text_factory = bytes
把text类型当bytes来解释,就不会出错了
不过,这样也不太好,如果知道是什么编码就好了,例子代码是gbk编码的
这里可以这样设置:
conn.text_factory = lambda x : str(x, 'gbk', 'ignore')
指示以gbk来解码而不是默认的utf8
---------------------
作者:xkxjy
来源:CSDN
原文:https://blog.csdn.net/xkxjy/article/details/8179479
版权声明:本文为博主原创文章,转载请附上博文链接!
#####################
python3中编码与解码之Unicode与bytes
今天玩Python爬虫,下载一个网页,然后把所有内容写入一个txt文件中,出现错误;
TypeError: write() argument must be str, not bytes
AttributeError: 'URLError' object has no attribute 'code'
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' inposition 5747: illegal multibyte sequence
一看就是编码问题,不懂,度娘上面这方面讲得不多,感觉没说清楚,自己研究了一晚上,摸出了一点门道。
从头说起,由于各国语言文字不同,起初要在计算机中表示,就有了各种各样的编码(例如中文的gb2312)。但是这样就出现了兼容性的问题,所以就有了Unicode,也就是所谓的万国码,python3中字符串类型str就是以Unicode编码格式编码,所以我们在Python3 中看到多种语言文字的字符串而不会出现乱码。
编码是一种用一种特定的方式对抽象字符(Unicode)转换为二进制形式(bytes)进行表示,也就是python3中的encode。解码就是对用特定方式表示的二进制数据用特定的方式转化为Unicode,也就是decode。
下图就是编码的核心:
一、字符的编码:
Python对于bites类型的数据用带‘b‘前缀的单引号活双引号表示。
下面关于字符编码解码的代码很好的解释了上面的流程图:
s='你好'
print(s)#输出结果:你好
print(type(s))#输出结果:<class 'str'>
s=s.encode('UTF-8')
print(s)#输出结果:b'\xe4\xbd\xa0\xe5\xa5\xbd'
print(type(s))#输出结果:<class 'bytes'>
s=s.decode('UTF-8')
print(s)#输出结果:你好
print(type(s))#输出结果:<class 'str'>
多说一句,如果你对str类型字符进行decode会报错,同理,对bytes类型进行encode也会报错。
二、文件编码
在python 3 中字符是以Unicode的形式存储的,当然这里所说的存储是指存储在计算机内存当中,如果是存储在硬盘里,Python 3的字符是以bytes形式存储,也就是说如果要将字符写入硬盘,就必须对字符进行encode。对上面这段话再解释一下,如果要将str写入文件,如果以‘w’模式写入,则要求写入的内容必须是str类型;如果以‘wb’形式写入,则要求写入的内容必须是bytes类型。文章开头出现的集中错误,就是因为写入模式与写入内容的数据类型不匹配造成的。
s1 = '你好'
#如果是以‘w’的方式写入,写入前一定要进行encoding,否则会报错
with open('F:\\1.txt','w',encoding='utf-8') as f1:
f1.write(s1)
s2 = s1.encode("utf-8")#转换为bytes的形式
#这时候写入方式一定要是‘wb’,且一定不能加encoding参数
with open('F:\\2.txt','wb') as f2:
f2.write(s2)
有的人会问,我在系统里面用文本编辑器打开以bytes形式写入的2.txt文件,发现里面显示的是‘你好’,而不是‘b'\xe4\xbd\xa0\xe5\xa5\xbd'’,因为文本文档打开2.txt时,又会对它进行decode,然后才给你看到。
三、网页的编码
网页编码和文件编码方法差不多,如下urlopen下载下来的网页read()且用decoding(‘utf-8’)解码,那就必须以‘w’的方式写入文件。如果只是read()而不用encoding(‘utf-8’)进行编码,一定要以‘wb’方式写入:
以‘w’方式写入时:
response= url_open('http://blog.csdn.net/gs_zhaoyang/article/details/13768925 ' ,timeout=5 )
#此处以UTF-8方式进行解码,解码后的数据以unicode的方式存储在html中
html = response.read().decode('UTF-8')
print(type(html))#输出结果:<class 'str'>
#这时写入方式一定要加encoding,以encoding
# 即UTF-8的方式对二进制数据进行编码才能写入
with open('F:\DownloadAppData\html.txt',"w" , encoding='UTF-8') as f:
f.write(html)
以‘wb’方式写入:
response= url_open('http://blog.csdn.net/gs_zhaoyang/article/details/13768925 ' ,timeout=5 )
html = response.read()#此处不需要进行解码,下载下来
print(type(html))#输出结果:<class 'bytes'>
with open('F:\DownloadAppData\html.txt',"wb" ) as f:
f.write(html)
如果要在Python3中,对urlopen下来的网页进行字符搜索,肯定也要进行decode,例如使用lxml.etree就必须进行decode。
---------------------
作者:奥辰_
来源:CSDN
原文:https://blog.csdn.net/chb4715/article/details/79104299
版权声明:本文为博主原创文章,转载请附上博文链接!
###################
http://www.runoob.com/python/python-func-str.html (重要,Python str() 函数)
https://www.cnblogs.com/sesshoumaru/p/6070713.html (Python str() 函数))
http://www.runoob.com/python3/python3-string-encode.html (Python3 encode()方法)
class str(object='') class
str(object=b'', encoding='utf-8', errors='strict')
Return a string version of object. If object is not provided, returns the empty string. Otherwise, the behavior of str()depends on whether encoding or errors is given, as follows.
If neither encoding nor errors is given, str(object) returns object.__str__(), which is the “informal” or nicely printable string representation of object. For string objects, this is the string itself. If object does not have a __str__() method, then str() falls back to returning repr(object).
If at least one of encoding or errors is given, object should be a bytes-like object (e.g. bytes or bytearray). In this case, if object is a bytes (or bytearray) object, then str(bytes, encoding, errors) is equivalent to bytes.decode(encoding, errors). Otherwise, the bytes object underlying the buffer object is obtained before calling bytes.decode(). See Binary Sequence Types — bytes, bytearray, memoryview and Buffer Protocol for information on buffer objects.
说明:
1. str函数功能时将对象转换成其字符串表现形式,如果不传入参数,将返回空字符串。
>>> str()
''
>>> str(None)
'None'
>>> str('abc')
'abc'
>>> str(123)
'123'
2. 当转换二进制流时,可以传入参数encoding,表示读取字节数组所使用的编码格式;参数errors,表示读取二进制的错误级别。(这两个参数和open方法中的同名参数有相同取值和类似的含义,详见Python内置函数(47)——open)。
>>> file = open('test.txt','rb') # 打开文件
>>> fileBytes = file.read() # 读取二进制流
>>> fileBytes
b'\xe6\x88\x91\xe6\x98\xaf\xe7\xac\xac1\xe8\xa1\x8c\xe6\x96\x87\xe6\x9c\xac\xef\xbc\x8c\xe6\x88\x91\xe5\xb0\x86\xe8\xa2\xab\xe6\x98\xbe\xe7\xa4\xba\xe5\x9c\xa8\xe5\xb1\x8f\xe5\xb9\x95\r\n\xe6\x88\x91\xe6\x98\xaf\xe7\xac\xac2\xe8\xa1\x8c\xe6\x96\x87\xe6\x9c\xac\xef\xbc\x8c\xe6\x88\x91\xe5\xb0\x86\xe8\xa2\xab\xe6\x98\xbe\xe7\xa4\xba\xe5\x9c\xa8\xe5\xb1\x8f\xe5\xb9\x95\r\n\xe6\x88\x91\xe6\x98\xaf\xe7\xac\xac3\xe8\xa1\x8c\xe6\x96\x87\xe6\x9c\xac\xef\xbc\x8cr\xe6\x88\x91\xe5\xb0\x86\xe8\xa2\xab\xe6\x98\xbe\xe7\xa4\xba\xe5\x9c\xa8\xe5\xb1\x8f\xe5\xb9\x95'
>>> str(fileBytes) # 默认将二进制流转换成字符串表现形式
"b'\\xe6\\x88\\x91\\xe6\\x98\\xaf\\xe7\\xac\\xac1\\xe8\\xa1\\x8c\\xe6\\x96\\x87\\xe6\\x9c\\xac\\xef\\xbc\\x8c\\xe6\\x88\\x91\\xe5\\xb0\\x86\\xe8\\xa2\\xab\\xe6\\x98\\xbe\\xe7\\xa4\\xba\\xe5\\x9c\\xa8\\xe5\\xb1\\x8f\\xe5\\xb9\\x95\\r\\n\\xe6\\x88\\x91\\xe6\\x98\\xaf\\xe7\\xac\\xac2\\xe8\\xa1\\x8c\\xe6\\x96\\x87\\xe6\\x9c\\xac\\xef\\xbc\\x8c\\xe6\\x88\\x91\\xe5\\xb0\\x86\\xe8\\xa2\\xab\\xe6\\x98\\xbe\\xe7\\xa4\\xba\\xe5\\x9c\\xa8\\xe5\\xb1\\x8f\\xe5\\xb9\\x95\\r\\n\\xe6\\x88\\x91\\xe6\\x98\\xaf\\xe7\\xac\\xac3\\xe8\\xa1\\x8c\\xe6\\x96\\x87\\xe6\\x9c\\xac\\xef\\xbc\\x8cr\\xe6\\x88\\x91\\xe5\\xb0\\x86\\xe8\\xa2\\xab\\xe6\\x98\\xbe\\xe7\\xa4\\xba\\xe5\\x9c\\xa8\\xe5\\xb1\\x8f\\xe5\\xb9\\x95'"
>>> str(fileBytes,'utf-8') # 传入encoding参数,函数将以此编码读取二进制流的内容
'我是第1行文本,我将被显示在屏幕\r\n我是第2行文本,我将被显示在屏幕\r\n我是第3行文本,r我将被显示在屏幕'
>>> str(fileBytes,'gbk') # 当传入encoding不能解码时,会报错(即errors参数默认为strict)
Traceback (most recent call last):
File "<pyshell#46>", line 1, in <module>
str(fileBytes,'gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 8: illegal multibyte sequence
>>> str(fileBytes,'gbk','ignore') # 'ignore' 忽略级别,字符编码有错,忽略掉.
'鎴戞槸绗1琛屾枃鏈锛屾垜灏嗚鏄剧ず鍦ㄥ睆骞\r\n鎴戞槸绗2琛屾枃鏈锛屾垜灏嗚鏄剧ず鍦ㄥ睆骞\r\n鎴戞槸绗3琛屾枃鏈锛宺鎴戝皢琚鏄剧ず鍦ㄥ睆骞'
>>> str(fileBytes,'gbk','replace') # 'replace' 替换级别,字符编码有错的,替换成?.
'鎴戞槸绗�1琛屾枃鏈�锛屾垜灏嗚��鏄剧ず鍦ㄥ睆骞�\r\n鎴戞槸绗�2琛屾枃鏈�锛屾垜灏嗚��鏄剧ず鍦ㄥ睆骞�\r\n鎴戞槸绗�3琛屾枃鏈�锛宺鎴戝皢琚�鏄剧ず鍦ㄥ睆骞�'

