决策树算法
算法思想
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
总结来说:
决策树模型核心是下面几部分:
- 结点和有向边组成
- 结点有内部结点和叶结点俩种类型
- 内部结点表示一个特征,叶节点表示一个类
一、ID3算法
“信息熵”是度量样本集合不确定度(纯度)的最常用的指标。
在我们的ID3算法中,我们采取信息增益这个量来作为纯度的度量。我们选取使得信息增益最大的特征进行分裂!
信息熵是代表随机变量的复杂度(不确定度),条件熵代表在某一个条件下,随机变量的复杂度(不确定度)。而我们的信息增益恰好是:信息熵-条件熵。
•当前样本集合 D 中第 k 类样本所占的比例为 pk ,则 D 的信息熵定义为
•离散属性 a 有 V 个可能的取值 {a1,a2,…,aV};样本集合中,属性 a 上取值为 av 的样本集合,记为 Dv。
•用属性 a 对样本集 D 进行划分所获得的“信息增益”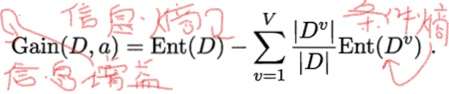
•信息增益表示得知属性 a 的信息而使得样本集合不确定度减少的程度
在决策树算法中,我们的关键就是每次选择一个特征,特征有多个,那么到底按照什么标准来选择哪一个特征。
这个问题就可以用信息增益来度量。如果选择一个特征后,信息增益最大(信息不确定性减少的程度最大),那么我们就选取这个特征。
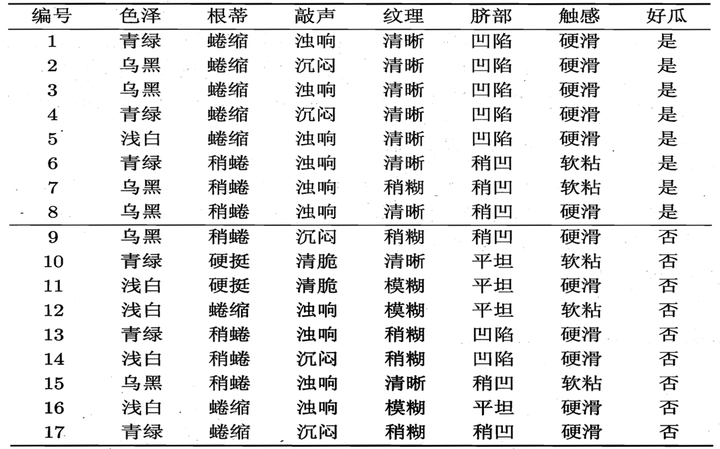
选择指标就是在所有的特征中,选择信息增益最大的特征。那么如何计算呢?看下面例子:
正例(好瓜)占 8/17,反例占 9/17 ,根结点的信息熵为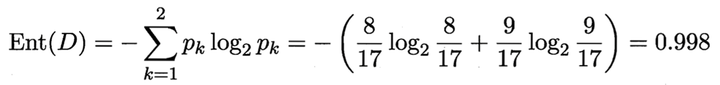
计算当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益
色泽有3个可能的取值:{青绿,乌黑,浅白}
D1(色泽=青绿) = {1, 4, 6, 10, 13, 17},正例 3/6,反例 3/6
D2(色泽=乌黑) = {2, 3, 7, 8, 9, 15},正例 4/6,反例 2/6
D3(色泽=浅白) = {5, 11, 12, 14, 16},正例 1/5,反例 4/5
3 个分支结点的信息熵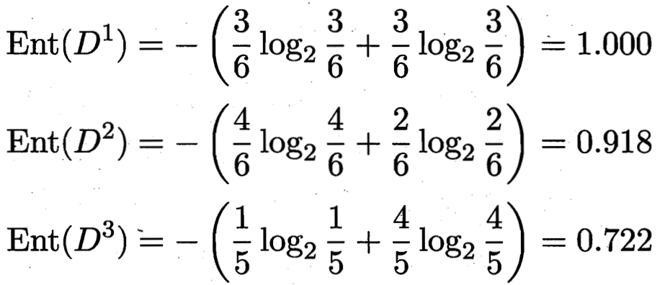
那么我们可以知道属性色泽的信息增益是:
同理,我们可以求出其它属性的信息增益,分别如下:
于是我们找到了信息增益最大的属性纹理,它的Gain(D,纹理) = 0.381最大。
于是我们选择的划分属性为“纹理”
如下: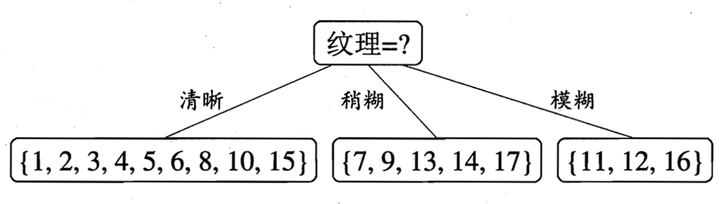
于是,我们可以得到了三个子结点,对于这三个子节点,我们可以递归的使用刚刚找信息增益最大的方法进行选择特征属性,
比如:D1(纹理=清晰) = {1, 2, 3, 4, 5, 6, 8, 10, 15},第一个分支结点可用属性集合{色泽、根蒂、敲声、脐部、触感},基于 D1各属性的信息增益,分别求的如下:
于是我们可以选择特征属性为根蒂,脐部,触感三个特征属性中任选一个(因为他们三个相等并最大),其它俩个子结点同理,然后得到新一层的结点,再递归的由信息增益进行构建树即可
我们最终的决策树如下: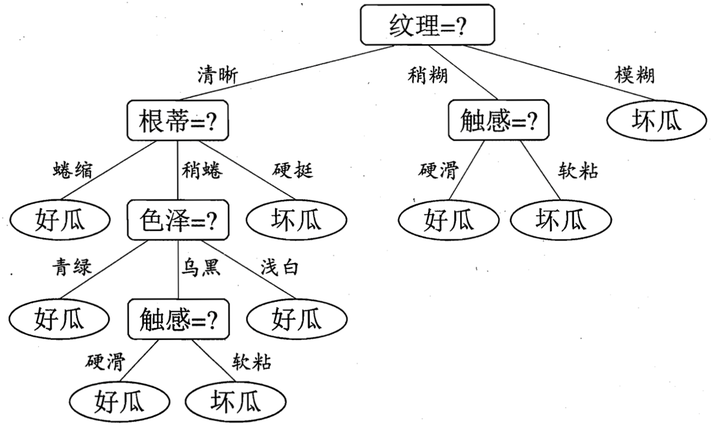
啊,那到这里为止,我们已经知道了构建树的算法,上面也说了有了树,我们直接遍历决策树就能得到我们预测样例的类别。那么是不是大功告成了呢?
结果是:不是的
我们从上面求解信息增益的公式中,其实可以看出,信息增益准则其实是对可取值数目较多的属性有所偏好!
现在假如我们把数据集中的“编号”也作为一个候选划分属性。我们可以算出“编号”的信息增益是0.998
因为每一个样本的编号都是不同的(由于编号独特唯一,条件熵为0了,每一个结点中只有一类,纯度非常高啊),也就是说,来了一个预测样本,你只要告诉我编号,其它特征就没有用了,这样生成的决策树显然不具有泛化能力。
于是我们就引入了信息增益率来选择最优划分属性!
二、C4.5算法
首先我们来看信息增益率的公式:

由上图我们可以看出,信息增益率=信息增益/IV(a),说明信息增益率是信息增益除了一个属性a的固有值得来的。
我们来看IV(a)的公式:
属性a的固有值:
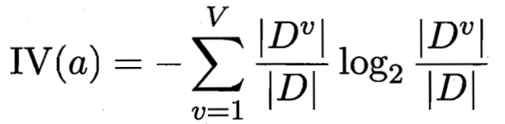
IV(触感) = 0.874 ( V = 2 )
IV(色泽) = 1.580 ( V = 3 )
IV(编号) = 4.088 ( V = 17
由上面的计算例子,可以看出IV(a)其实能够反映出,当选取该属性,分成的V类别数越大,IV(a)就越大,如果仅仅只用信息增益来选择属性的话,那么我们偏向于选择分成子节点类别大的那个特征。
但是在前面分析了,并不是很好,所以我们需要除以一个属性的固定值,这个值要求随着分成的类别数越大而越小。于是让它做了分母。这样可以避免信息增益的缺点。
那么信息增益率就是完美无瑕的吗?
当然不是,有了这个分母之后,我们可以看到增益率准则其实对可取类别数目较少的特征有所偏好!毕竟分母越小,整体越大。
于是C4.5算法不直接选择增益率最大的候选划分属性,候选划分属性中找出信息增益高于平均水平的属性(这样保证了大部分好的的特征),再从中选择增益率最高的(又保证了不会出现编号特征这种极端的情况)
三、CART算法
CART是一课二叉树
当CART是分类树时,采用GINI值作为节点分裂的依据;当CART是回归树时,采用样本的最小方差作为节点分裂的依据;

分类树?回归树?
分类树的作用是通过一个对象的特征来预测该对象所属的类别,而回归树的目的是根据一个对象的信息预测该对象的属性,并以数值表示。
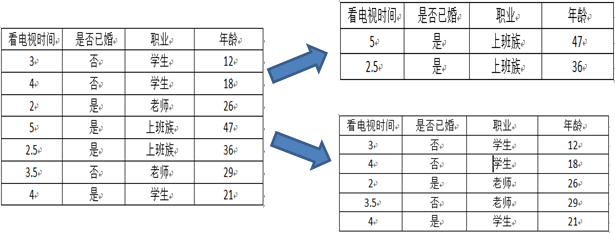
CART既能是分类树,又能是决策树,如上表所示,如果我们想预测一个人是否已婚,那么构建的CART将是分类树;如果想预测一个人的年龄,那么构建的将是回归树。
假设我们构建了两棵决策树分别预测用户是否已婚和实际的年龄,如图1和图2所示:

图1 预测婚姻情况决策树 图2 预测年龄的决策树
图1表示一棵分类树,其叶子节点的输出结果为一个实际的类别,在这个例子里是婚姻的情况(已婚或者未婚),选择叶子节点中数量占比最大的类别作为输出的类别;
图2是一棵回归树,预测用户的实际年龄,是一个具体的输出值。怎样得到这个输出值?一般情况下选择使用中值、平均值或者众数进行表示,图2使用节点年龄数据的平均值作为输出值。
CART如何选择分裂的属性?
如果是分类树,CART采用GINI值衡量节点纯度;如果是回归树,采用样本方差衡量节点纯度。节点越不纯,节点分类或者预测的效果就越差。
GINI值的计算公式:
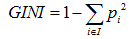
节点越不纯,GINI值越大。以二分类为例,如果节点的所有数据只有一个类别,则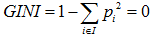 ,如果两类数量相同,则
,如果两类数量相同,则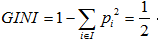 。
。
回归方差计算公式:
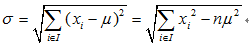
方差越大,表示该节点的数据越分散,预测的效果就越差。如果一个节点的所有数据都相同,那么方差就为0,此时可以很肯定得认为该节点的输出值;如果节点的数据相差很大,那么输出的值有很大的可能与实际值相差较大。
因此,无论是分类树还是回归树,CART都要选择使子节点的GINI值或者回归方差最小的属性作为分裂的方案。即最小化(分类树):
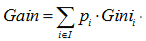
或者(回归树):

CART如何分裂成一棵二叉树?
节点的分裂分为两种情况,连续型的数据和离散型的数据。
CART对连续型属性的处理与C4.5差不多,通过最小化分裂后的GINI值或者样本方差寻找最优分割点,将节点一分为二,在这里不再叙述,详细请看C4.5。
对于离散型属性,理论上有多少个离散值就应该分裂成多少个节点。但CART是一棵二叉树,每一次分裂只会产生两个节点,怎么办呢?很简单,只要将其中一个离散值独立作为一个节点,其他的离散值生成另外一个节点即可。这种分裂方案有多少个离散值就有多少种划分的方法,举一个简单的例子:如果某离散属性一个有三个离散值X,Y,Z,则该属性的分裂方法有{X}、{Y,Z},{Y}、{X,Z},{Z}、{X,Y},分别计算每种划分方法的基尼值或者样本方差确定最优的方法。
以属性“职业”为例,一共有三个离散值,“学生”、“老师”、“上班族”。该属性有三种划分的方案,分别为{“学生”}、{“老师”、“上班族”},{“老师”}、{“学生”、“上班族”},{“上班族”}、{“学生”、“老师”},分别计算三种划分方案的子节点GINI值或者样本方差,选择最优的划分方法,如下图所示:
第一种划分方法:{“学生”}、{“老师”、“上班族”}
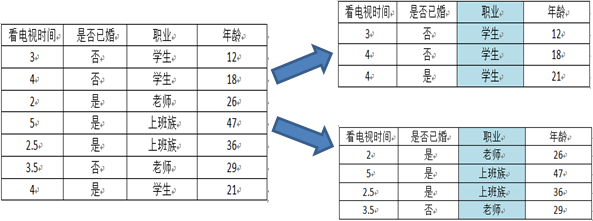
预测是否已婚(分类):
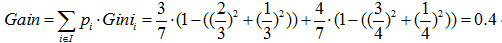
预测年龄(回归):

第二种划分方法:{“老师”}、{“学生”、“上班族”}
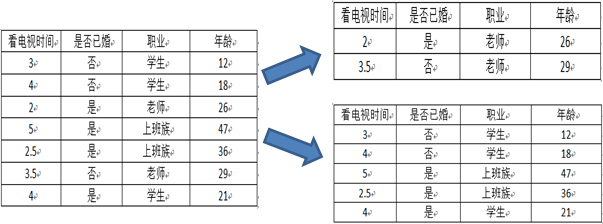
预测是否已婚(分类):
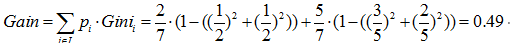
预测年龄(回归):
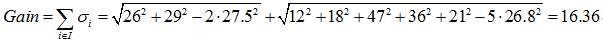
第三种划分方法:{“上班族”}、{“学生”、“老师”}
预测是否已婚(分类):
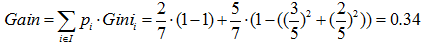
预测年龄(回归):
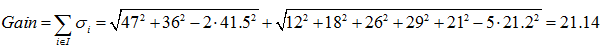
综上,如果想预测是否已婚,则选择{“上班族”}、{“学生”、“老师”}的划分方法,如果想预测年龄,则选择{“老师”}、{“学生”、“上班族”}的划分方法。
如何剪枝?
CART采用CCP(代价复杂度)剪枝方法。代价复杂度选择节点表面误差率增益值最小的非叶子节点,删除该非叶子节点的左右子节点,若有多个非叶子节点的表面误差率增益值相同小,则选择非叶子节点中子节点数最多的非叶子节点进行剪枝。
可描述如下:
令决策树的非叶子节点为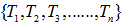 。
。
a)计算所有非叶子节点的表面误差率增益值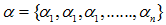
b)选择表面误差率增益值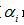 最小的非叶子节点
最小的非叶子节点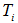 (若多个非叶子节点具有相同小的表面误差率增益值,选择节点数最多的非叶子节点)。
(若多个非叶子节点具有相同小的表面误差率增益值,选择节点数最多的非叶子节点)。
c)对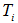 进行剪枝
进行剪枝
表面误差率增益值的计算公式:
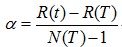
其中:
 表示叶子节点的误差代价,
表示叶子节点的误差代价,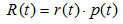 ,
,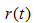 为节点的错误率,
为节点的错误率, 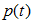 为节点数据量的占比;
为节点数据量的占比;
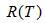 表示子树的误差代价,
表示子树的误差代价,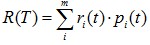 ,
, 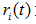 为子节点i的错误率,
为子节点i的错误率,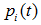 表示节点i的数据节点占比;
表示节点i的数据节点占比;
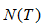 表示子树节点个数。
表示子树节点个数。
算例:
下图是其中一颗子树,设决策树的总数据量为40。
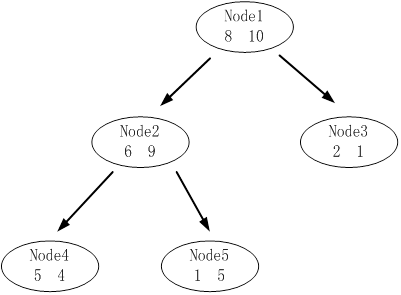
该子树的表面误差率增益值可以计算如下:
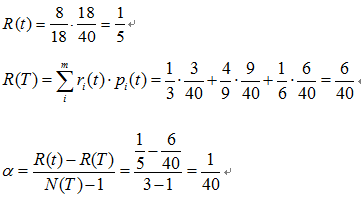
求出该子树的表面错误覆盖率为 ,只要求出其他子树的表面误差率增益值就可以对决策树进行剪枝。
流程图:
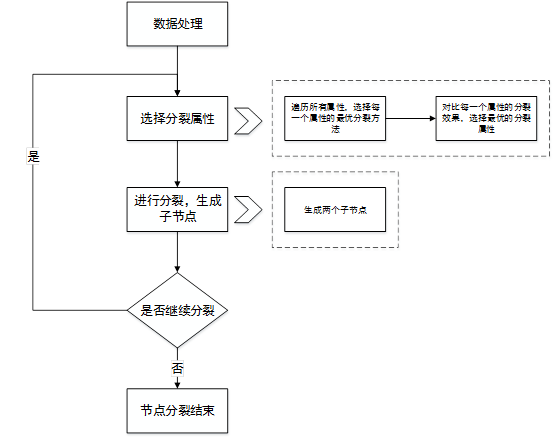
总结:
(1)CART是一棵二叉树,每一次分裂会产生两个子节点,对于连续性的数据,直接采用与C4.5相似的处理方法,对于离散型数据,选择最优的两种离散值组合方法。
(2)CART既能是分类数,又能是二叉树。如果是分类树,将选择能够最小化分裂后节点GINI值的分裂属性;如果是回归树,选择能够最小化两个节点样本方差的分裂属性。
(3)CART跟C4.5一样,需要进行剪枝,采用CCP(代价复杂度的剪枝方法)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号