HDFS的读写流程
一、简介
HDFS(Hadoop Distributed File System)是GFS的开源实现。
1.优点:
能够运行在廉价机器上,硬件出错常态,需要具备高容错性
流式数据访问,而不是随机读写
面向大规模数据集,能够进行批处理、能够横向扩展
简单一致性模型,假定文件是一次写入、多次读取
2.缺点:
不支持低延迟数据访问
不适合大量小文件存储(因为每条元数据占用空间是一定的)
不支持并发写入,一个文件只能有一个写入者
不支持文件随机修改,仅支持追加写入
3.数据单位:
block :文件上传前需要分块,这个块就是block,一般为128MB,可以修改。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的
一个单位。
packet :packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
chunk :chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte
的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值 约为128 : 1。(即64*1024 / 512)
二、HDFS读流程
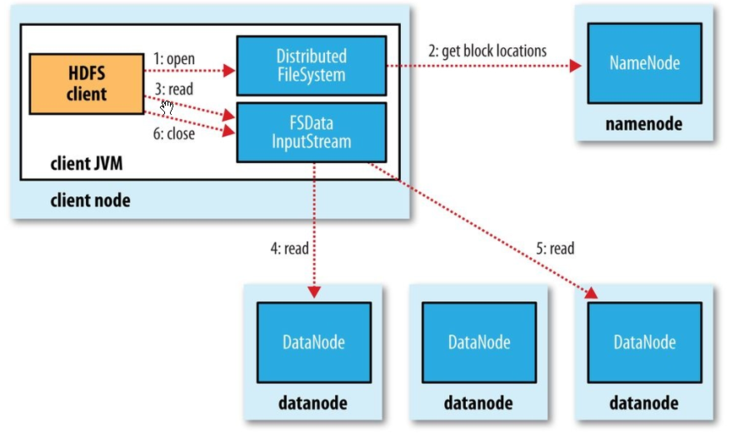
读详细步骤:
1、client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
2、就近挑选一台datanode服务器,请求建立输入流 。
3、DataNode向输入流中中写数据,以packet为单位来校验。
4、关闭输入流
三、HDFS写流程
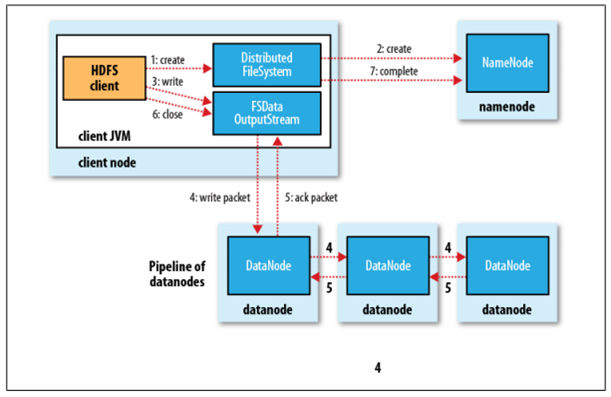
写详细步骤:
1、客户端向NameNode发出写文件请求。
2、检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,
由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录)
3、client端按128MB的块切分文件。
4、client将NameNode返回的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和多个DataNode构成pipeline管道。
client向第一个DataNode写入一个packet,这个packet便会在pipeline里传给第二个、第三个…DataNode。
在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点将ack发送给client。
5、写完数据,关闭输输出流.
6、发送完成信号给NameNode。
更通俗易懂的图:

四、机架感知(副本节点的选择)
- 第一个副本在client所处的节点上。如果客户端在集群外,随机选一个
- 第二个副本和第一个副本位于相同机架,随机节点。
- 第三个副本位于不同机架,随机节点
五、DFSOutputStream内部原理
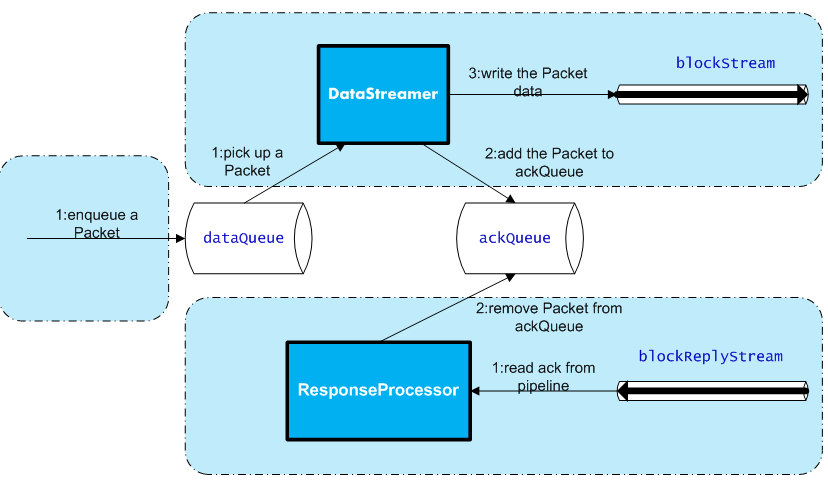
1、创建Packet
Client写数据时,会将字节流数据缓存到内部的缓冲区中,当长度满足一个Chunk大小(512B)时,便会创建一个Packet对象,然后向该Packet对象中写Chunk
的Checksum校验和数据,以及实际数据块Chunk Data,校验和数据是基于实际数据块计算得到的。每次满足一个Chunk大小时,都会向Packet中写上述数据内容,
直到达到一个Packet对象大小(64K),就会将该Packet对象放入到dataQueue队列中,等待DataStreamer线程取出并发送到DataNode节点。
2、发送Packet
DataStreamer线程从dataQueue队列中取出Packet对象,放到ackQueue队列中,然后向DataNode节点发送这个Packet对象所对应的数据
3、接收ack
发送一个Packet数据包以后,会有一个用来接收ack的ResponseProcessor线程,如果收到成功的ack,则表示一个Packet发送成功,ResponseProcessor线程会将
ackQueue队列中对应的Packet删除,在发送过程中,如果发生错误,所有未完成的Packet都会从ackQueue队列中移除掉,然后重新创建一个新的Pipeline,排除掉出错的
那些DataNode节点,接着DataStreamer线程继续从dataQueue队列中发送Packet。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号