SSD与vgg目标检测网络原理
目录:
一、SSD
二、基于SSD的极速人脸检测
三、VGG
一、SSD

SSD主干网络结构(SSD是一个多级分类网络)
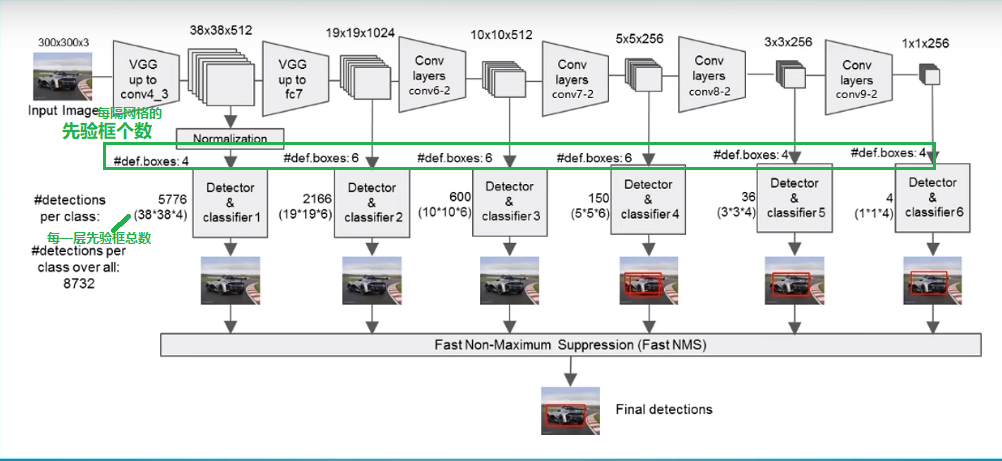
图1 ssd主干网络结构图
ssd中的vgg-19网络:
SSD采用的主干网络是VGG网络,关于VGG的介绍大家可以看我的另外一篇博客https://blog.csdn.net/weixin_44791964/article/details/102779878,这里的VGG网络相比普通的VGG网络有一定的修改,主要修改的地方就是:
- 1、将VGG16的FC6和FC7层转化为卷积层。
- 2、去掉所有的Dropout层和FC8层;
- 3、新增了Conv6、Conv7、Conv8、Conv9。
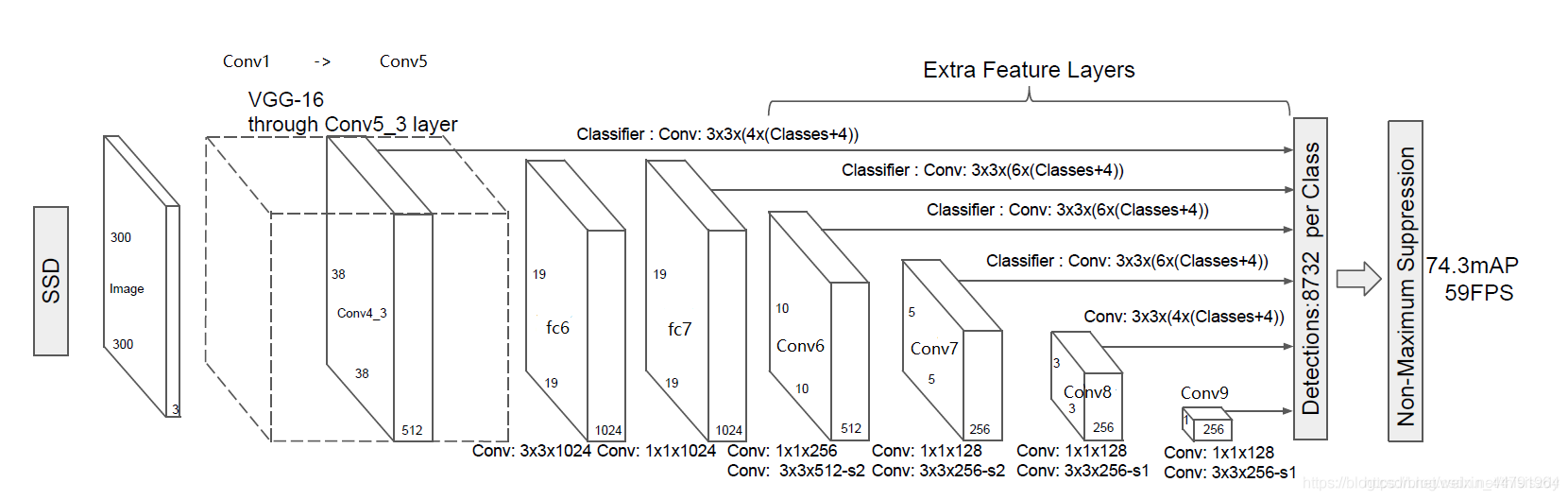
如图所示,输入的图片经过了改进的VGG网络(Conv1->fc7)和几个另加的卷积层(Conv6->Conv9),进行特征提取:
a、输入一张图片后,被resize到300x300的shape
b、conv1,经过两次[3,3]卷积网络,输出的特征层为64,输出为(300,300,64),再2X2最大池化,该最大池化步长为2,输出net为(150,150,64)。
c、conv2,经过两次[3,3]卷积网络,输出的特征层为128,输出net为(150,150,128),再2X2最大池化,该最大池化步长为2,输出net为(75,75,128)。
d、conv3,经过三次[3,3]卷积网络,输出的特征层为256,输出net为(75,75,256),再2X2最大池化,该最大池化步长为2,输出net为(38,38,256)。
e、conv4,经过三次[3,3]卷积网络,输出的特征层为512,输出net为(38,38,512),再2X2最大池化,该最大池化步长为2,输出net为(19,19,512)。
f、conv5,经过三次[3,3]卷积网络,输出的特征层为512,输出net为(19,19,512),再3X3最大池化,该最大池化步长为1,输出net为(19,19,512)。
g、利用卷积代替全连接层,进行了一次[3,3]卷积网络和一次[1,1]卷积网络,分别为fc6和fc7,输出的通道数为1024,因此输出的net为(19,19,1024)。
(从这里往前都是VGG的结构)
h、conv6,经过一次[1,1]卷积网络,调整通道数,一次步长为2的[3,3]卷积网络,输出的通道数为512,因此输出的net为(10,10,512)。
i、conv7,经过一次[1,1]卷积网络,调整通道数,一次步长为2的[3,3]卷积网络,输出的通道数为256,因此输出的net为(5,5,256)。
j、conv8,经过一次[1,1]卷积网络,调整通道数,一次padding为valid的[3,3]卷积网络,输出的通道数为256,因此输出的net为(3,3,256)。
k、conv9,经过一次[1,1]卷积网络,调整通道数,一次padding为valid的[3,3]卷积网络,输出的特征层为256,因此输出的net为(1,1,256)。
下面直接上代码(项目地址:https://github.com/bubbliiiing/ssd-pytorch):
文件vgg.py中(ssd算法对vgg-16的修改):
代码中,如下,有个参数ceil_mode,设置为false、true的区别见下图:
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]

1 import torch.nn as nn 2 from torchvision.models.utils import load_state_dict_from_url 3 4 5 ''' 6 该代码用于获得VGG主干特征提取网络的输出。 7 输入变量i代表的是输入图片的通道数,通常为3。 8 9 300, 300, 3 -> 300, 300, 64 -> 300, 300, 64 -> 150, 150, 64 -> 150, 150, 128 -> 150, 150, 128 -> 75, 75, 128 -> 10 75, 75, 256 -> 75, 75, 256 -> 75, 75, 256 -> 38, 38, 256 -> 38, 38, 512 -> 38, 38, 512 -> 38, 38, 512 -> 19, 19, 512 -> 11 19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 512 -> 19, 19, 1024 -> 19, 19, 1024 12 13 # SSD 中需要从VGG提取两个特征图(见SSD主干网络结构) 14 38, 38, 512的序号是22 15 19, 19, 1024的序号是34 16 ''' 17 ''' 18 卷积通道数量 19 ''' 20 base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M', 21 512, 512, 512] 22 23 def vgg(pretrained = False): 24 layers = [] 25 in_channels = 3 26 for v in base: 27 if v == 'M': 28 layers += [nn.MaxPool2d(kernel_size=2, stride=2)] 29 elif v == 'C': 30 layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)] 31 else: 32 conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) 33 layers += [conv2d, nn.ReLU(inplace=True)] 34 in_channels = v 35 # 19, 19, 512 -> 19, 19, 512 36 pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) 37 # 19, 19, 512 -> 19, 19, 1024 38 conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6) 39 # 19, 19, 1024 -> 19, 19, 1024 40 conv7 = nn.Conv2d(1024, 1024, kernel_size=1) 41 layers += [pool5, conv6, 42 nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)] 43 44 model = nn.ModuleList(layers) 45 if pretrained: 46 state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data") 47 state_dict = {k.replace('features.', '') : v for k, v in state_dict.items()} 48 model.load_state_dict(state_dict, strict = False) 49 return model 50 51 if __name__ == "__main__": 52 net = vgg() 53 for i, layer in enumerate(net): 54 print(i, layer)
文件ssd.py中:
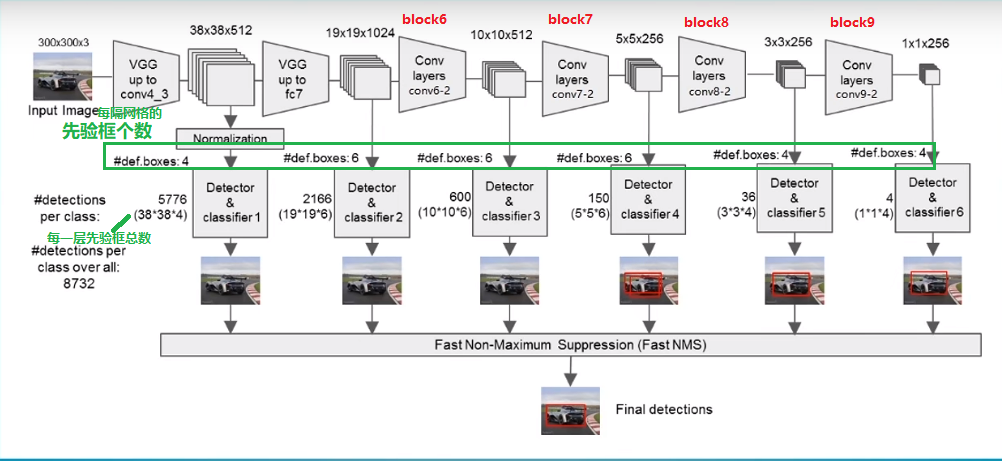
见图下ssd主干网络结构图,vgg中输出两个38*38*512和19*19*1024的特征图(图中的block6、7、8、9和代码中的注释的block一一对应):
1 def add_extras(in_channels, backbone_name): 2 layers = [] 3 if backbone_name == 'vgg': 4 # Block 6 5 # 19,19,1024 -> 19,19,256 -> 10,10,512 6 layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)] 7 layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)] 8 9 # Block 7 10 # 10,10,512 -> 10,10,128 -> 5,5,256 11 layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)] 12 layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)] 13 14 # Block 8 15 # 5,5,256 -> 5,5,128 -> 3,3,256 16 layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)] 17 layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)] 18 19 # Block 9 20 # 3,3,256 -> 3,3,128 -> 1,1,256 21 layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)] 22 layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)] 23 else: 24 layers += [InvertedResidual(in_channels, 512, stride=2, expand_ratio=0.2)] 25 layers += [InvertedResidual(512, 256, stride=2, expand_ratio=0.25)] 26 layers += [InvertedResidual(256, 256, stride=2, expand_ratio=0.5)] 27 layers += [InvertedResidual(256, 64, stride=2, expand_ratio=0.25)] 28 29 return nn.ModuleList(layers)
由上图可知,我们分别取:
- conv4_3的第三次卷积的特征;
- fc7卷积的特征;
- conv6的第二次卷积的特征(block6);
- conv7的第二次卷积的特征(block7);
- conv8的第二次卷积的特征(block8);
- conv9的第二次卷积的特征(block9)。
共六个特征层进行下一步的处理。为了和普通特征层区分,我们称之为有效特征层,来获取预测结果。
对获取到的每一个有效特征层,我们都需要对其做两个操作,分别是:
- 一次卷积得到channel维度为:num_anchors x 4的featureMap(用于回归预测候选框的 x y w h)
- 一次卷积得到channel维度为:num_anchors x num_classes的featureMap(用于分类预测候选框的置信度)
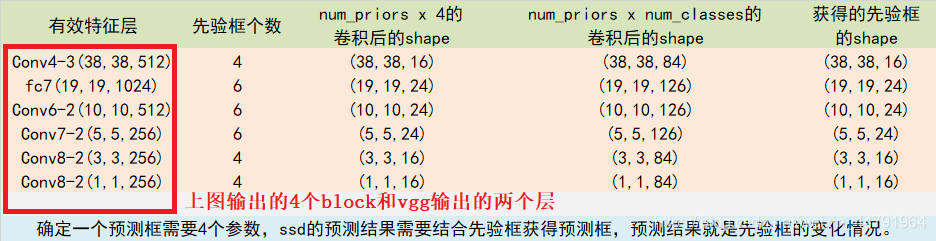
而num_anchors指的是该特征层每一个特征点所拥有的先验框数量。上述提到的六个特征层,每个特征层的每个特征点对应的先验框数量分别为4、6、6、6、4、4。上述操作分别对应的对象为:
num_anchors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。所以有:(4、6、6、6、4、4)*4 = (16、24、24、24、16、16)
num_anchors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测对应的种类。(4、6、6、6、4、4)*21 = (84、126、126、126、84、84)
所有的特征层对应的预测结果的shape如下:
1 class SSD300(nn.Module): 2 def __init__(self, num_classes, backbone_name, pretrained = False): 3 super(SSD300, self).__init__() 4 self.num_classes = num_classes 5 if backbone_name == "vgg": 6 self.vgg = add_vgg(pretrained) 7 self.extras = add_extras(1024, backbone_name) 8 self.L2Norm = L2Norm(512, 20) 9 mbox = [4, 6, 6, 6, 4, 4] 10 11 loc_layers = [] 12 conf_layers = [] 13 backbone_source = [21, -2] 14 #---------------------------------------------------# 15 # 在add_vgg获得的特征层里 16 # 第21层和-2层可以用来进行回归预测和分类预测。 17 # 分别是conv4-3(38,38,512)和conv7(19,19,1024)的输出 18 #---------------------------------------------------# 19 for k, v in enumerate(backbone_source): 20 loc_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)] 21 conf_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)] 22 #-------------------------------------------------------------# 23 # 在add_extras获得的特征层里 24 # 第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测。 25 # shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256) 26 #-------------------------------------------------------------# 27 for k, v in enumerate(self.extras[1::2], 2): 28 loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)] 29 conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)] 30 else: 31 self.mobilenet = mobilenet_v2(pretrained).features 32 self.extras = add_extras(1280, backbone_name) 33 self.L2Norm = L2Norm(96, 20) 34 mbox = [6, 6, 6, 6, 6, 6] 35 36 loc_layers = [] 37 conf_layers = [] 38 backbone_source = [13, -1] 39 for k, v in enumerate(backbone_source): 40 loc_layers += [nn.Conv2d(self.mobilenet[v].out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)] 41 conf_layers += [nn.Conv2d(self.mobilenet[v].out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)] 42 for k, v in enumerate(self.extras, 2): 43 loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)] 44 conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)] 45 46 self.loc = nn.ModuleList(loc_layers) 47 self.conf = nn.ModuleList(conf_layers) 48 self.backbone_name = backbone_name 49 50 def forward(self, x): 51 #---------------------------# 52 # x是300,300,3 53 #---------------------------# 54 sources = list() 55 loc = list() 56 conf = list() 57 58 #---------------------------# 59 # 获得conv4_3的内容 60 # shape为38,38,512 61 #---------------------------# 62 if self.backbone_name == "vgg": 63 for k in range(23): 64 x = self.vgg[k](x) 65 else: 66 for k in range(14): 67 x = self.mobilenet[k](x) 68 #---------------------------# 69 # conv4_3的内容 70 # 需要进行L2标准化 71 #---------------------------# 72 s = self.L2Norm(x) 73 sources.append(s) 74 75 #---------------------------# 76 # 获得conv7的内容 77 # shape为19,19,1024 78 #---------------------------# 79 if self.backbone_name == "vgg": 80 for k in range(23, len(self.vgg)): 81 x = self.vgg[k](x) 82 else: 83 for k in range(14, len(self.mobilenet)): 84 x = self.mobilenet[k](x) 85 86 sources.append(x) 87 #-------------------------------------------------------------# 88 # 在add_extras获得的特征层里 89 # 第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测。 90 # shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256) 91 #-------------------------------------------------------------# 92 for k, v in enumerate(self.extras): 93 x = F.relu(v(x), inplace=True) 94 if self.backbone_name == "vgg": 95 if k % 2 == 1: 96 sources.append(x) 97 else: 98 sources.append(x) 99 100 #-------------------------------------------------------------# 101 # 为获得的6个有效特征层添加回归预测和分类预测 102 #-------------------------------------------------------------# 103 for (x, l, c) in zip(sources, self.loc, self.conf): 104 loc.append(l(x).permute(0, 2, 3, 1).contiguous()) 105 conf.append(c(x).permute(0, 2, 3, 1).contiguous()) 106 107 #-------------------------------------------------------------# 108 # 进行reshape方便堆叠 109 #-------------------------------------------------------------# 110 loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1) 111 conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1) 112 #-------------------------------------------------------------# 113 # loc会reshape到batch_size, num_anchors, 4 114 # conf会reshap到batch_size, num_anchors, self.num_classes 115 #-------------------------------------------------------------# 116 output = ( 117 loc.view(loc.size(0), -1, 4), 118 conf.view(conf.size(0), -1, self.num_classes), 119 ) 120 return output
得到不同尺度每个网格中先验框的位置、置信度之后,后续训练和前向传播部署(YOLO的目标函数是将框的位置和置信度写在一个目标函数中,SSD也是),我就不多BB了,和yolo系列差不多。

然后就是超参数有哪些????
VGG :
如下图:以VGG-16为例子,特点是全是3*3卷积,参数相对少。然后maxpool后面必然会对featureMap的channel维度进行升维。因为maxpool会导致特征图信息丢失,所以后面接一个升维。

如下左图,VGG-34比VGG-18训练、测试效果都差(没有给全),不是过拟合导致,而是层数加深,网络学偏了。ResNet的加入后,有明显的改观。

- conv:特提特征,3*3提取得比5*5细粒度更细
- relu:增加网络非线性
- maxpool:降采样
反向传播:
就一个链式求导+梯度下降。
参考:https://blog.csdn.net/weixin_38347387/article/details/82936585
对于反向传播,真的不难。例如,对于某一次迭代,得到最终的loss,此时,已知中间网络任何一层输入、输出,包括每一层具体参数。对于第i层的权重参数wi,我们是可以求得loss对它的偏导f’,于是参数更新公式为:w = w – n*f’,其中n为学习率。
(思考:对于Focal loss,分类的错误的样本,loss大,而分类正确的loss值,loss小。Loss大,则一阶导数大,导致网络权重增量大,网络收敛更快。)
参考:https://blog.csdn.net/weixin_44791964/article/details/104981486
余思琪人脸检测:https://mp.weixin.qq.com/s?__biz=MzIyMDY2MTUyNg==&mid=2247483818&idx=1&sn=12e14dfd5154b35f14575d876785da76&chksm=97c9d3d3a0be5ac5a4e5cb05b23dd90bb73d57c2b3be6a70a139d8c28391a6185ec6297b6da0&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzIzNTU5MzA1OQ==&mid=2247483937&idx=1&sn=df27185114ca8c4d5db55a65b26aed69&chksm=e8e58e2ddf92073b162e75c1525b85dbad2551893889d8a5d9dde29baf58a16e91fd5c263e64&mpshare=1&scene=21&srcid=&sharer_sharetime=1583410558996&sharer_shareid=8457d4b9d590baced734dd1ede727998&exportkey=AYPFSxpVXLxn1WLk54RH1VQ=&pass_ticket=FoKnbqhyZbDrumsm%20Z7QDd8kcPLIpaufOB8LggwGl71QJQygeG0J45UJB52tqXSg#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzIyMDY2MTUyNg%3D%3D&chksm=97c9d060a0be5976d73484081239c3b5acd346fdd32acdfe47ab9a5407e05470e8c050f628c8&idx=1&mid=2247483929&scene=21&sn=d453f0ebfa06289cade4d37a824519b6#wechat_redirect

 浙公网安备 33010602011771号
浙公网安备 33010602011771号