迁移学习与ResNet
一、迁移学习
深度学习中,迁移学习可以让小样本学习得更好,省时,方便。eg:我们采用YOLOV5训练识别动物(假定是简单得二分类),那么我们可以使用作者基于coco数据集训练得所得权重文件weight1;在此基础上,训练我们的数据,即:使用我们的数据对weight1接着调整,直到weight1适应于我们的数据。
总所周知,VGG、ResNet都是经典、可靠的经典网络模型,很多新的DL网络模型都是将其作为BackBone,接着后续进行创新开发,得到新的网络模型。一般地,迁移学习有两种方案:
- (从头做起)使用原模型参数p,在新的网络中,p作为初始化用,反向传播的时候,更新所有参数。
- (站在巨人肩膀上)使用原模型参数p,在新的网络中,将原来模型参数进行冻结,反向传播只更新后半部模型参数。
(一般地,如果我们数据量大,冻结的层数越少;数据量小,冻结的层数越多。)
注:例如ResNet的FC是100分类,而我们使用其进行迁移学习的时候,可能是10分类,这时候FC需要我们进行修改。
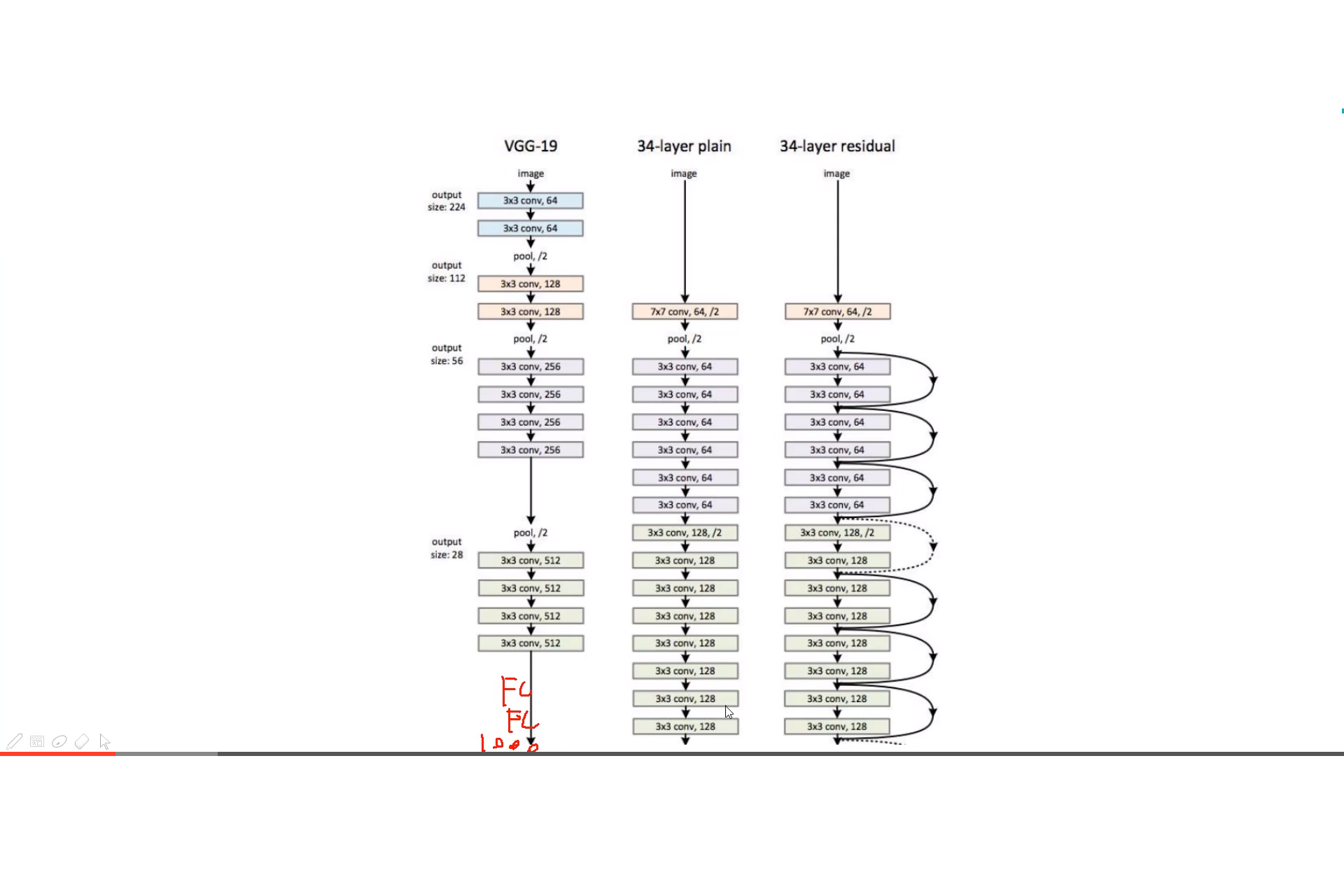
顺便科普:
参数量:
MobileNet: 6百万不到
YOLO5S: 7百万
VGG-16: 4000万
RestNet: 1.3亿
二、ResNet
2.1、restnet基本原理
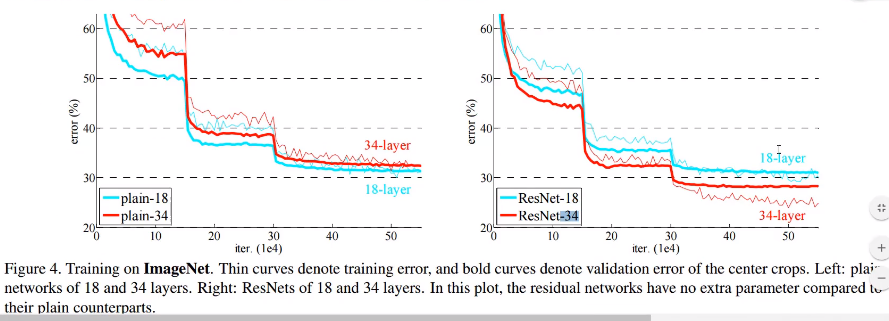
理论上,56层网络的拟合能力远远强于20层,如下图(老图),20层的网络反而loss比56的低,原因是:随着网络加深,容易过拟合。

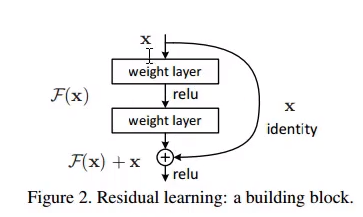
残差链接可以解决上述过拟合问题。例如:网络第n层输出为x,如下图,x现在走两条路,一条直接通过identity进行通过同等映射(直接copy下去);另一条经过两个权重层处理。对比上述两条路结果的loss,哪个小就在网络中保留哪一个(其实不是绝对保留,两条路都有权重系数的,可取原文看公式)。
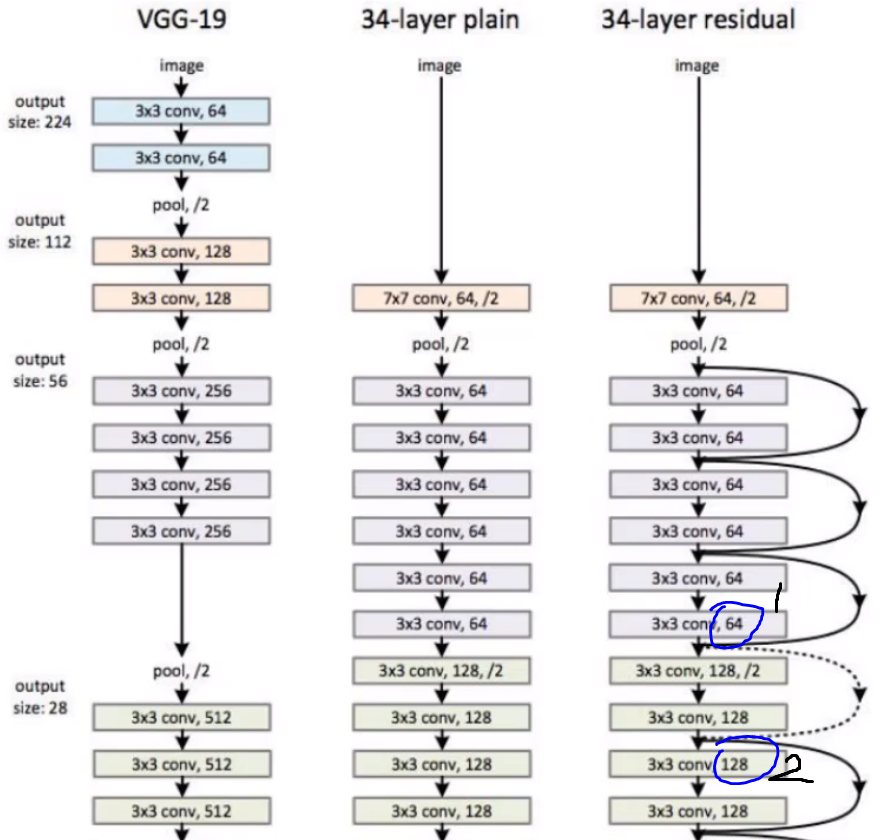
但是残差链接可能有个问题,如下图,34-层的残差网络中,有个虚线残差连接,我们注意到1->2过程中,特征图的channel由64->128,通过正常卷积层是这样,那残差连接是怎么解决的呢?答案是:通过1×1卷积进行升维度。
以下是两个常规网络,一个34层,一个18层,左图中可以看到,34层网络由于过拟合,效果反而不如18层网络;有图中我们给两者都加上残差连接后,34层网络才变得更好。
2.2 基于resnet的迁移学习
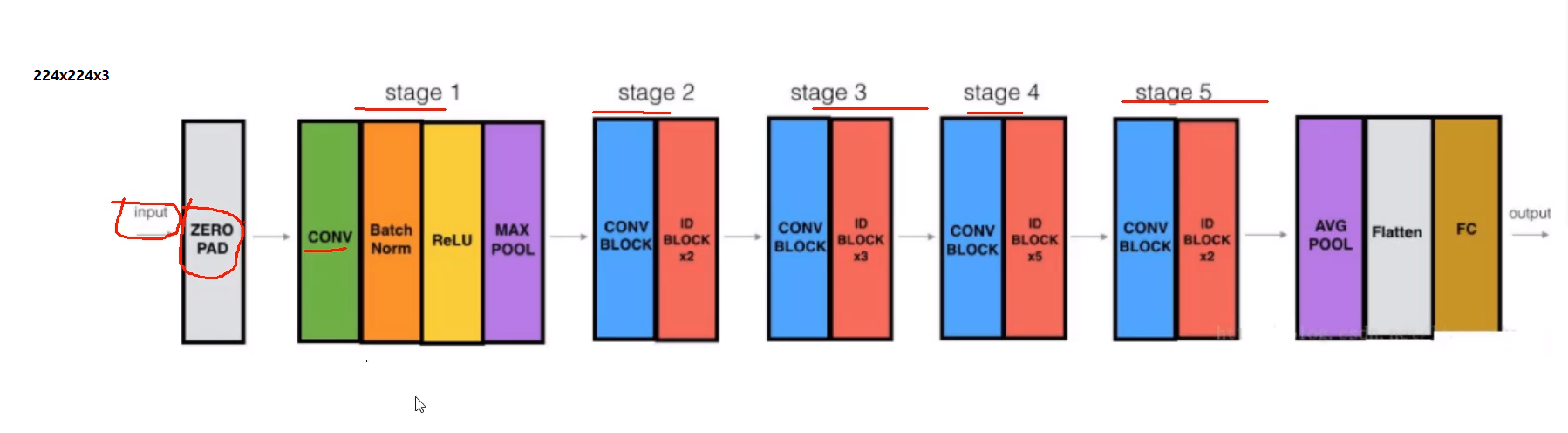
这里为了说明问题,选择层数比较小,stage1、2、3、4、5,5个模块(迁移学习会采用官方预训练模型,但是官方是1000分类,咱们是10分类,所以咱们需要修改下图的AVG POOL-Flatten-FC的size,其余前面模块直接复制官方参数,并冻结),请注意蓝色conv block模块、ID block 模块,下文简称c模块、i模块。
i模块:对应上图 34-layer residual中的 实线模块。
c模块:对应......虚线模块。
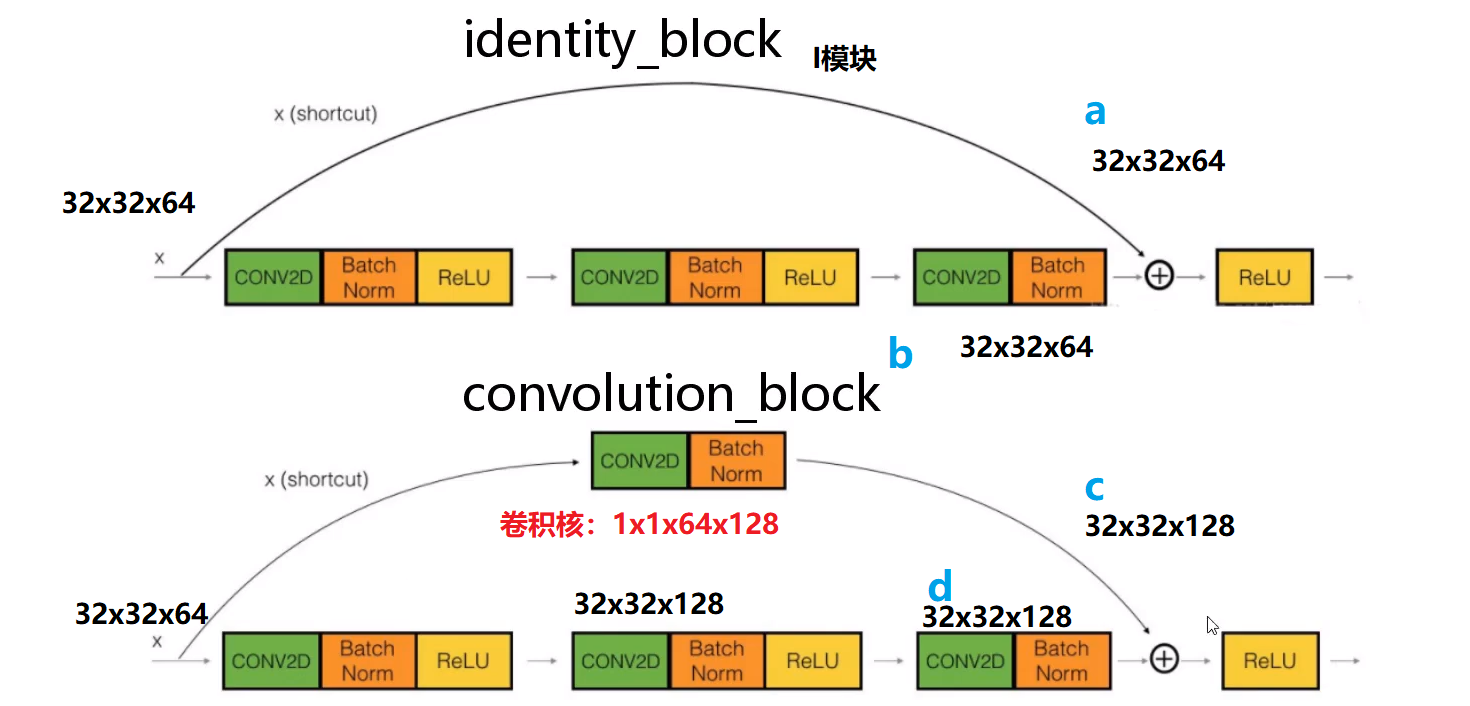
如下图所示:I模块(同等银色)在a、b汇合处相加,由于特征图尺寸一致,可以直接相加;再看C模块,在d处,特征图大小变为32×32×128,而原来特征图为
32×32×64,他们channel维度不同,原本是不能直接相加,但是在跳远连接(shortup过程)有个1×1卷积,它可以升高维度,处理后特征图变为32×32×128,这时候c
、d两处的特征图就可以相加了(这里加法其实是带权重的加法)。
效果怎样自己看吧,下图左边是迁移学习的效果,右边是自己重新训练的效果。
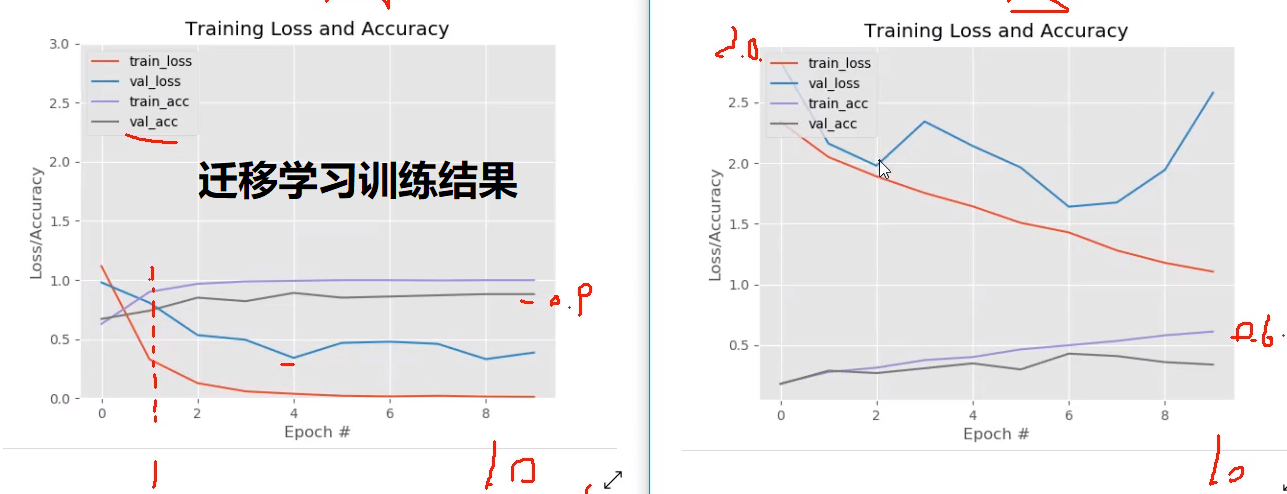
结论:迁移学习,使用官方权重进行预训练,模型收敛快!一般不建议冻住!
Reference:
[1] https://arxiv.org/pdf/1512.03385.pdf 《Deep Residual Learning for Image Recognition》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号