

Elastic 8.4.1 java Api 使用过程问题及解决方案
这玩意儿原生的dsl语法确实非常反人类,然后参考别的组的同事的代码时,发现了个牛B的玩意
easy-es:傻瓜级ElasticSearch搜索引擎ORM框架 https://www.easy-es.cn/ 一定要去看啊
1、怎么把业务数据存入es
连接ES

@Service @Slf4j public class ElasticConnectUtil { @Value("${elastic.host}") private String elasticHost; @Value("${elastic.port}") private Integer elasticPort; private ElasticsearchClient client = null; public ElasticsearchClient getClient(){ // ElasticsearchClient client = null ; if(null != client){ return client; } try{ RestClient restClient = RestClient.builder(new HttpHost(elasticHost,elasticPort)).build(); ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper()); client = new ElasticsearchClient(transport); }catch (Exception e){ log.error("连接elastic失败:",e); throw new BaseException("连接elastic失败:",e); } return client; } }
保存数据到es
public void saveData(String index,String id,String data){ Reader reader = new StringReader(data); IndexRequest<JsonData> indexRequest = IndexRequest.of(a -> a.index(index).id(id).withJson(reader)); IndexResponse response = null; try { response = elasticConnectUtil.getClient().index(indexRequest); }catch (Exception e){ String errMsg = "新增数据失败:索引:"+index+",id:"+id+",数据:"+data; log.error(errMsg,e); throw new BaseException(errMsg,e); } log.info("新增数据成功:索引:"+index+",id:"+id+",数据:"+data+",返回结果:"+response.toString()); }
2、select t.* from ord_send_info t where t.is_valid=1 and (t.corp_id in () or t.corp_id in () ); 原来需要这样查询数据的地方,改到es里,提高响应速度,特别是大数据量的时候,千万及亿级时
报错:"error": "no handler found for uri [/customer/doc/1?pretty=&pretty=true] and method [POST]"
解决:好像是语法问题,下图是官网上的的
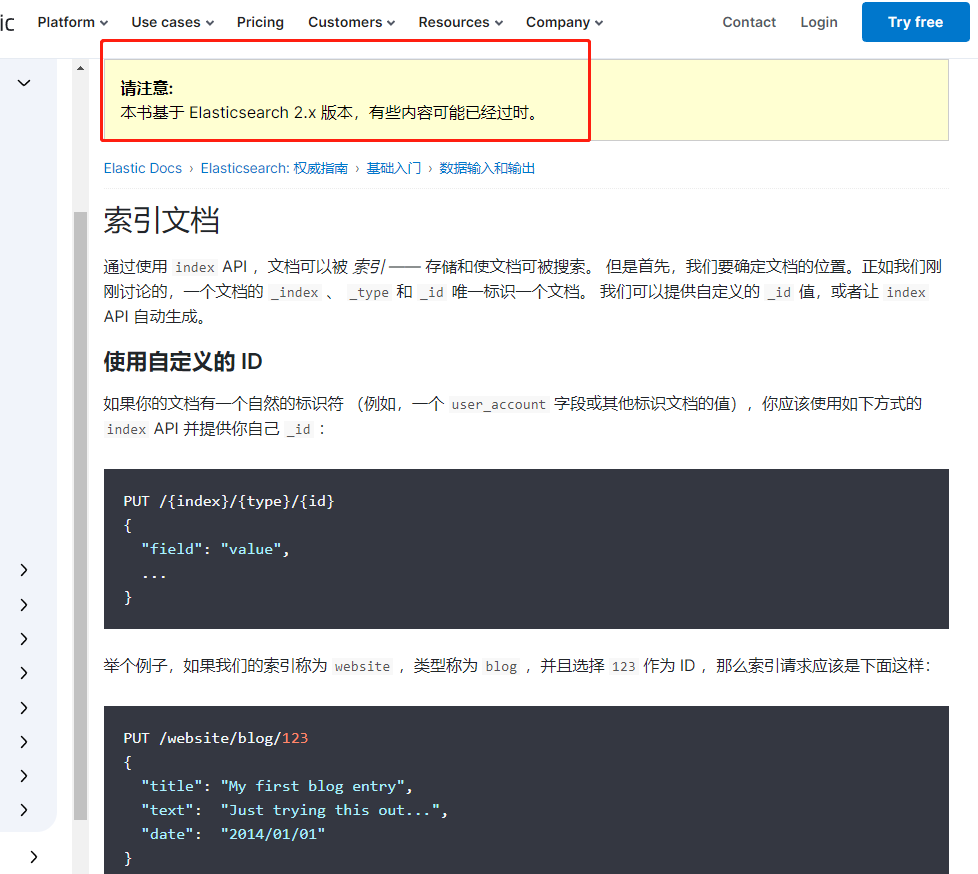
正确的语法是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | POST /website/_doc{ "title":"My first blog entry", "text":"Just trying this out..."}get /website/_doc/dWIsVIMBqVRaOii8I0Q-get /_searchPUT /test2/_doc/1{"name":"李华", "age":18 }PUT /customer/_doc/1{ "name":"John Doe"}GET /customer/_doc/1post /customer/_update/1{ "doc":{"name":"John Doe-update"}} |
如下图:官网中,中文的文档都是基于2.x版本的,,
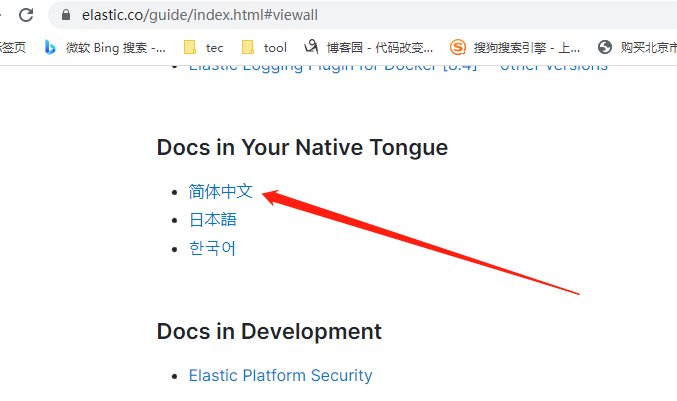
官网关于8.4的语法示例:
自己弄个浏览器翻译插件翻一下
动态映射|弹性搜索指南 [8.4] |弹性的 (elastic.co)
显式映射|弹性搜索指南 [8.4] |弹性的 (elastic.co)
springboot项目中使用 es,官方文档参考: 安装|弹性搜索 Java API 客户端 [8.4] |弹性的 (elastic.co)
测试过程中发现一个问题啊
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | @Testpublic void saveDataTest(){ String id = "eWJ7XoMBqVRaOii8nkQn"; String index = "products"; Product p = new Product(); p.setName("社保啊公积金"); p.setPrice(BigDecimal.valueOf(0.00006)); operations.saveData(index,id, JSONUtil.toJsonStr(p)); try { Thread.sleep(1000L); } catch (InterruptedException e) { e.printStackTrace(); } operations.search(index);} |
以上仅是个单元测试啊,现象是保存数据之后立刻就去查询,是查询不到刚保存成功的那个结果的,但是如果保存成功之后延迟一秒再查询,就是能查到最新结果的,
这个问题不知道是不是跟ES的配置有关。
问题2:对象中有Long类型的id,转成json存到es后值比原来小1,转成string后再存值就不会变化
问题3:往同一个index存10w条数据时,当存了1000多条时,报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | 2022-10-09 18:04:30.775 ERROR 19956 --- [l-1600-thread-1] o.a.h.i.n.c.InternalHttpAsyncClient : I/O reactor terminated abnormallyorg.apache.http.nio.reactor.IOReactorException: Failure opening selector at org.apache.http.impl.nio.reactor.AbstractIOReactor.<init>(AbstractIOReactor.java:103) ~[httpcore-nio-4.4.12.jar:4.4.12] at org.apache.http.impl.nio.reactor.BaseIOReactor.<init>(BaseIOReactor.java:85) ~[httpcore-nio-4.4.12.jar:4.4.12] at org.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor.execute(AbstractMultiworkerIOReactor.java:321) ~[httpcore-nio-4.4.12.jar:4.4.12] at org.apache.http.impl.nio.conn.PoolingNHttpClientConnectionManager.execute(PoolingNHttpClientConnectionManager.java:221) ~[httpasyncclient-4.1.4.jar:4.1.4] at org.apache.http.impl.nio.client.CloseableHttpAsyncClientBase$1.run(CloseableHttpAsyncClientBase.java:64) ~[httpasyncclient-4.1.4.jar:4.1.4] at java.lang.Thread.run(Thread.java:748) [na:1.8.0_201]Caused by: java.io.IOException: Unable to establish loopback connection at sun.nio.ch.PipeImpl$Initializer.run(PipeImpl.java:94) ~[na:1.8.0_201] at sun.nio.ch.PipeImpl$Initializer.run(PipeImpl.java:61) ~[na:1.8.0_201] at java.security.AccessController.doPrivileged(Native Method) ~[na:1.8.0_201] at sun.nio.ch.PipeImpl.<init>(PipeImpl.java:171) ~[na:1.8.0_201] at sun.nio.ch.SelectorProviderImpl.openPipe(SelectorProviderImpl.java:50) ~[na:1.8.0_201] at java.nio.channels.Pipe.open(Pipe.java:155) ~[na:1.8.0_201] at sun.nio.ch.WindowsSelectorImpl.<init>(WindowsSelectorImpl.java:127) ~[na:1.8.0_201] at sun.nio.ch.WindowsSelectorProvider.openSelector(WindowsSelectorProvider.java:44) ~[na:1.8.0_201] at java.nio.channels.Selector.open(Selector.java:227) ~[na:1.8.0_201] at org.apache.http.impl.nio.reactor.AbstractIOReactor.<init>(AbstractIOReactor.java:101) ~[httpcore-nio-4.4.12.jar:4.4.12] ... 5 common frames omittedCaused by: java.net.SocketException: No buffer space available (maximum connections reached?): connect at sun.nio.ch.Net.connect0(Native Method) ~[na:1.8.0_201] at sun.nio.ch.Net.connect(Net.java:454) ~[na:1.8.0_201] at sun.nio.ch.Net.connect(Net.java:446) ~[na:1.8.0_201] at sun.nio.ch.SocketChannelImpl.connect(SocketChannelImpl.java:648) ~[na:1.8.0_201] at java.nio.channels.SocketChannel.open(SocketChannel.java:189) ~[na:1.8.0_201] at sun.nio.ch.PipeImpl$Initializer$LoopbackConnector.run(PipeImpl.java:127) ~[na:1.8.0_201] at sun.nio.ch.PipeImpl$Initializer.run(PipeImpl.java:76) ~[na:1.8.0_201] ... 14 common frames omittedy |
问题3原因:连接一次es就创建了一个ElasticsearchClient对象,创建的多了短时间未释放掉,就把资源占满了,
问题4:报错 co.elastic.clients.elasticsearch._types.ElasticsearchException: [es/search] failed: [search_phase_execution_exception] all shards failed
问题4原因:查询语法及类型不对导致,参考:身份证|弹性搜索指南 [8.4] |弹性的 (elastic.co) 这个例子里查的string类型的数据,实际需求查的是Long类型的数据,
错误代码:
1 2 3 4 5 6 7 8 9 10 11 | get /_search{ "query":{ "bool": { "should":[ {"match":{"ord_send_info.corpId":[1,2,3]}}, {"match":{"ord_send_info.chgCorpId":[1,2,3]}} ] } }} |
正确代码如下:
get /ord_send_info/_search
{
"query":{
"bool": {
"should":[
{"match":{"corpId":2}},
{"match":{"corpId":2}},
{"match":{"corpId":2}},
{"match":{"chgCorpId":2}},
{"match":{"chgCorpId":2}},
{"match":{"chgCorpId":2}}
]
}
}
}
依照错误代码写的java查询代码就报了上述错误,按照正确的代码重写java代码就可以了
代码参考如下:
public void search(String index,List<Integer> corpIdList){
List<Query> queryList = new ArrayList<>();
for(int i:corpIdList){
Query qCorpId = Query.of(q -> q.match(m->m.field("corpId").query(i)));
Query qChgCorpId = Query.of(q -> q.match(m -> m.field("chgCorpId").query(i)));
Query qInsSuppId = Query.of(q -> q.match(m -> m.field("insSuppId").query(i)));
Query qAccuSuppId = Query.of(q -> q.match(m -> m.field("accuSuppId").query(i)));
queryList.add(qCorpId);
queryList.add(qChgCorpId);
queryList.add(qInsSuppId);
queryList.add(qAccuSuppId);
}
Long startTime = System.currentTimeMillis();
SearchRequest searchRequest = SearchRequest.of(s -> s.index(index).query(q -> q.bool(b -> b.should(queryList))));
SearchResponse<OrdSendInfoEs> searchResponse = null;
try {
searchResponse = elasticConnectUtil.getClient().search(searchRequest,OrdSendInfoEs.class);
} catch (IOException e) {
log.error("批量查询异常",e);
}
log.info("耗时:"+(System.currentTimeMillis() - startTime));
log.info("查询到总数:"+searchResponse.hits().total().value());
}
select t.* from ord_send_info t where t.is_valid=1 and (t.corp_id in () or t.corp_id in () );
这里就解决了最初的问题,解决原来在数据库查询慢的问题
问题5:最大返回1w条
问题5解决:分页查询 TODO
问题6:
执行以下查询时报错:easy-es的写法
LambdaEsQueryWrapper<OrdSendInfoEs> wrapper = new LambdaEsQueryWrapper<>(); wrapper.index(index); wrapper.size(0); wrapper.groupBy(OrdSendInfoEs::getCardNo).max(OrdSendInfoEs::getId); List<OrdSendInfoEs> list = ordSendInfoEsMapper.selectList(wrapper); log.info(JSONUtil.toJsonStr(list)); return list;
报错信息:
Text fields are not optimised for operations that require per-document field data like aggregations and sorting,
问题6解决方案:
put /ord_send_info/_mapping { "properties":{ "cardNo":{ "type":"text", "fielddata":true }, "id":{ "type":"text", "fielddata":true } } }
问题7:历史数据初始化进es后,如下图,有些字段会自动多出一个带 “.keyword” 的字段,相比于原有的字段,支持可聚合。

问题7解释:
区别是:
当一个字段需要用于全文搜索(会被分词), 比如产品名称、产品描述信息, 就应该使用text类型.
当一个字段需要按照精确值进行过滤、排序、聚合等操作时, 就应该使用keyword类型.
所以如果没有设置mapping,es会自动给一些字段把text、和keyword都设置上,实际使用时应该根据需要同一个字段仅设置一个类型,当然有需要也可以设置成多个
默认的text类型的mapping是这样的:
1 2 3 4 5 6 7 8 9 | "cardType": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } |
接收es返回结果的对象里依然只有cartType这个字段,没有cartType.keyword这个字段,如果你修改cartType的值,cartType.keyword会自动的跟着更新,
但是如果你搜索的时候针对cartType想使用排序、或者聚合那在传字段名称的时候就只能传 cartType.keyword ,否则就会报错,所以真实使用es时,还是要自定义好mapping ,根据实际业务需要设置String类型的字段应该是text类型还是应该是keyword类型。
再创建index的同时,定义好mapping给每个字段设置好对应的类型,是不会出现cardType.keyword这种情况的,效果如下图:

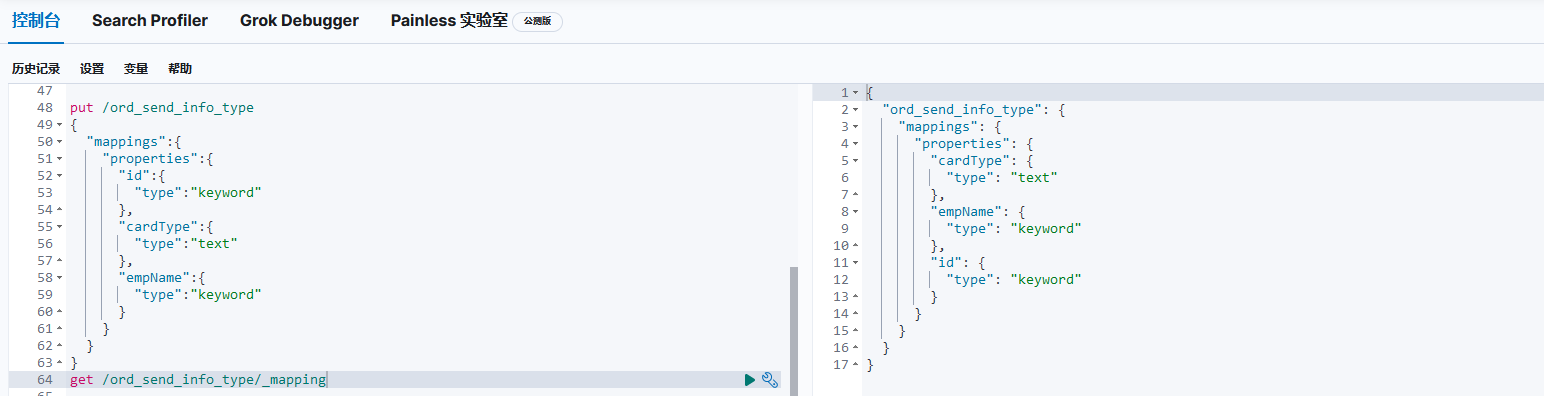

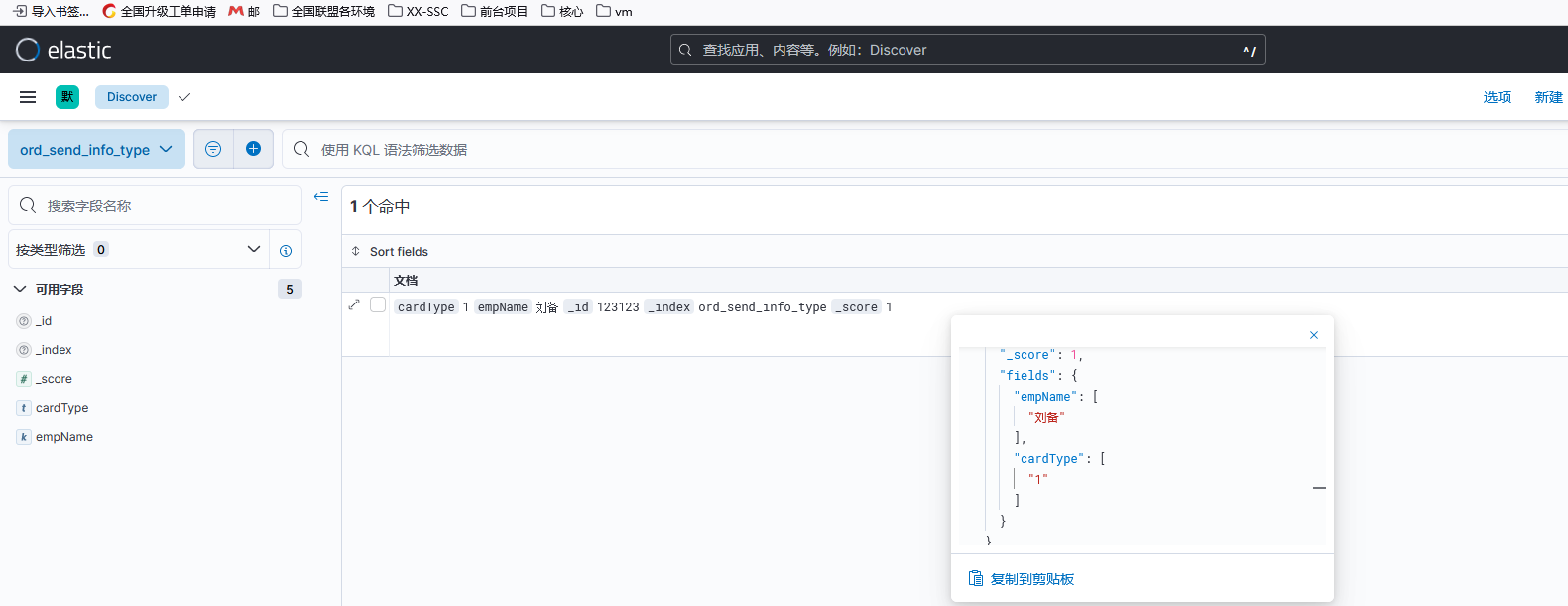

同时如果你想根据某个字段搜索数据时,代码里必须要写死这个字段的名称。
为避免在java代码里出现es里的字段名称,还需要封装一个工具,获取属性名称的统一方法,比如getCardTypeName,返回cardName 这个字段名称
解决方案:在类上加 @FieldNameConstants


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律