
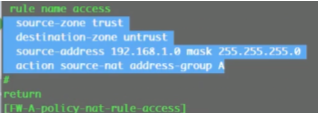
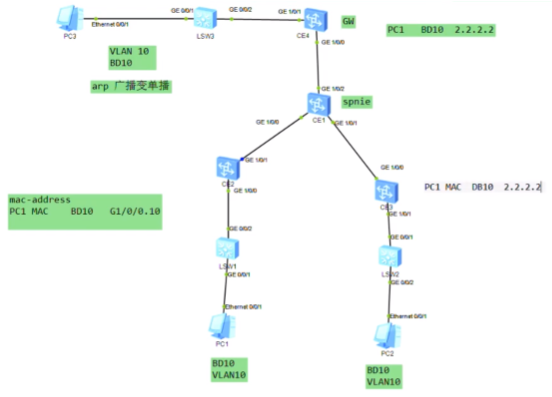
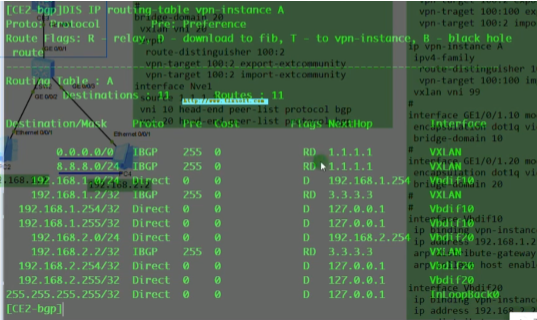
Hcie rs 学习笔记 誉天 阮维 vxlan章节
视频1
Vxlan 实验需要用到ce系列sw镜像文件(ce12800+6800用的都是这个镜像,但vxlan实验只能用12800)+ensp版本1.3c00spc100
开一台12800需要1g内存

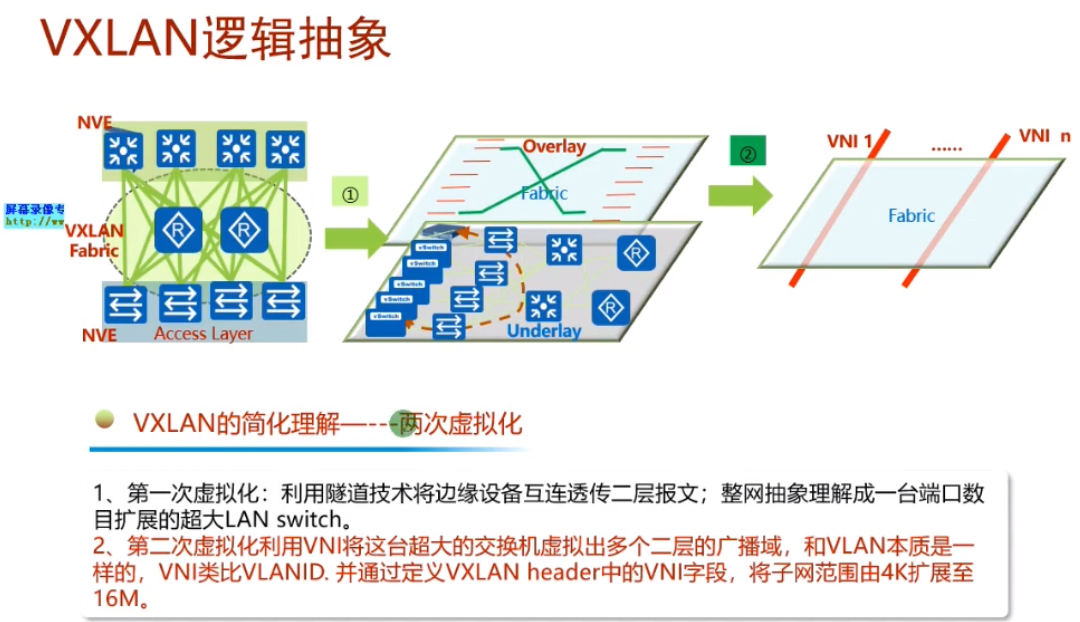
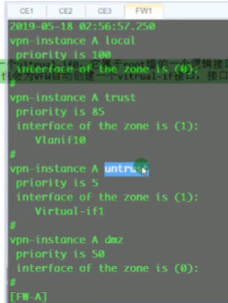
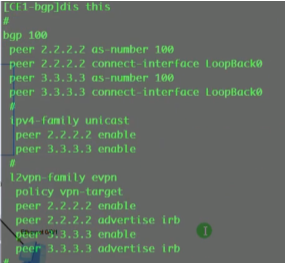
vxlan最早是vmware+cisco研究出来的隧道技术,主要用于服务器虚拟化的场景下实现二层互访的一种隧道技术。目前已经作为标准化的隧道技术,是数据中心里首选的大二层技术。vxlan本质就是隧道.
Mpls vpn是把三层网络在三层私有网络的基础上进行扩展-即三层vpn

而vxlan是通过三层网络将2个相同的网段连接在一起,形成大二层,左右互访就不是跨网段。
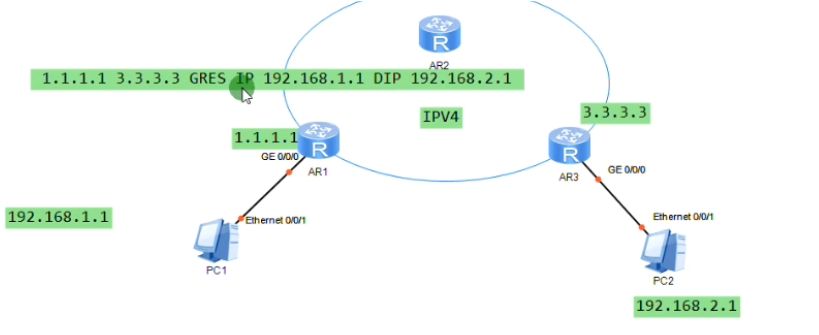
lsp的自动生成,是依靠ldp协议来控制的-控制平面。而vxlan和gre隧道一样,是没有控制平面的。gre隧道是人为创建的,直接在源地址和目标地址之间建立隧道,不需要跑协议。vxlan是没有控制平面的人为手动配置的大二层隧道技术。
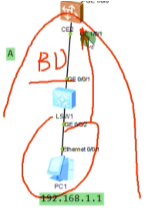
底层ip网络为underlay网络,vxlan所构建的大二层网络为overlay网络。在一个underlay上,可以创建多个隔离的广播域(如1.1和2.2)
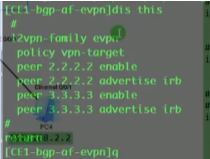
vpls的缺点不适合dc场景中使用,啥呢?evpn呢check
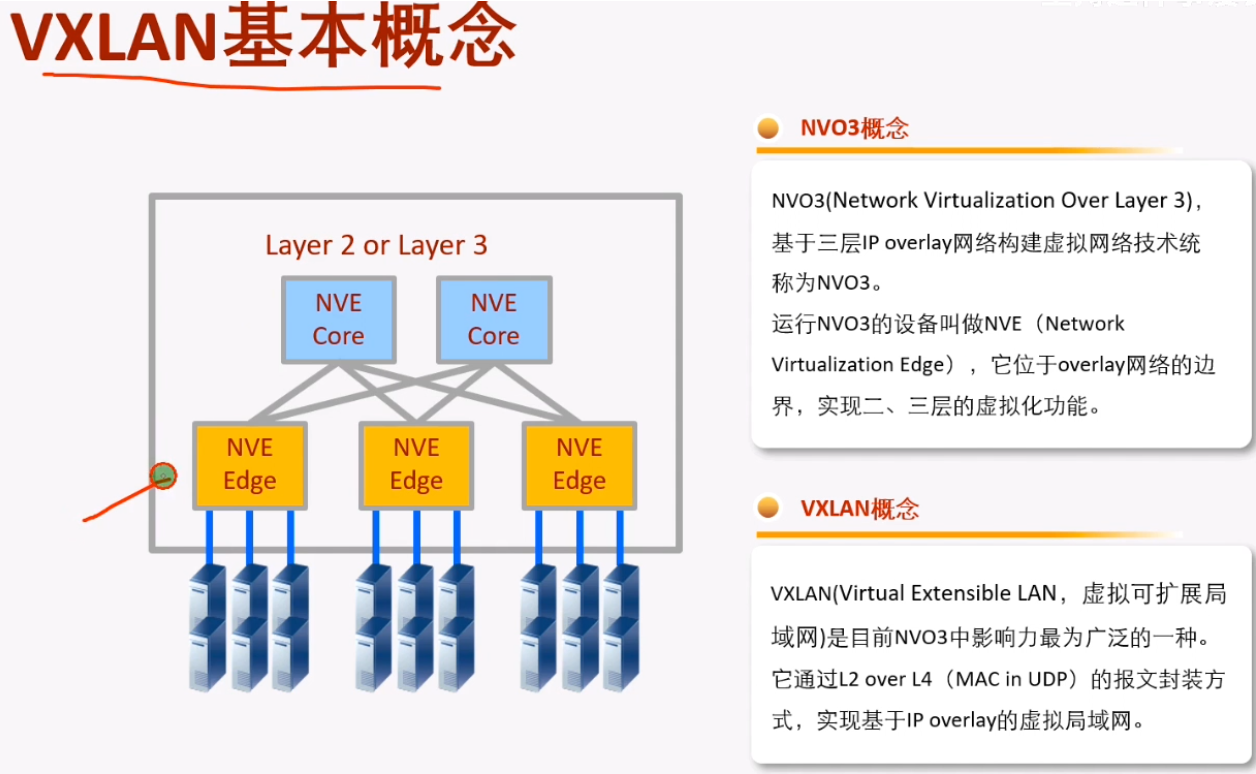
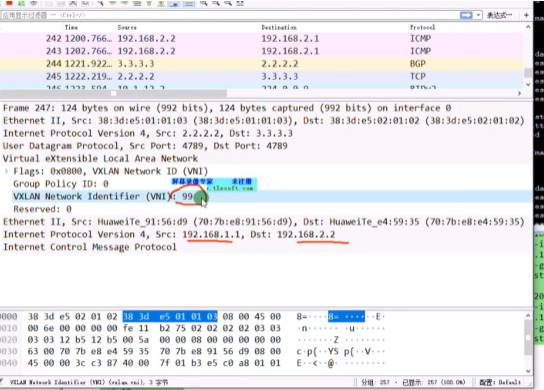
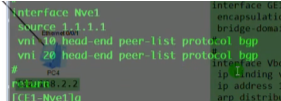
运行vxlan的设备成为nve设备(忽略nvo3)。以太网数据帧进入到vxlan网络中,接入的设备就叫做nve-对vxlan报文进行封装和解封装的设备.
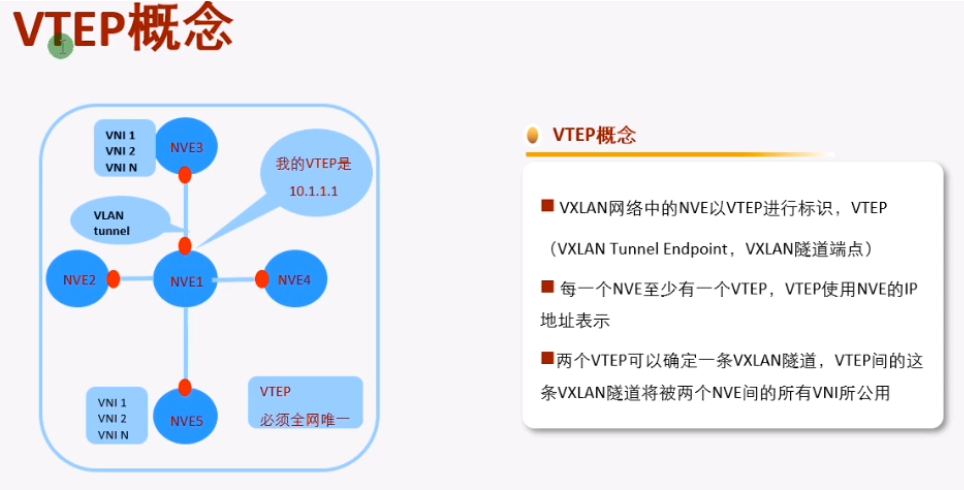
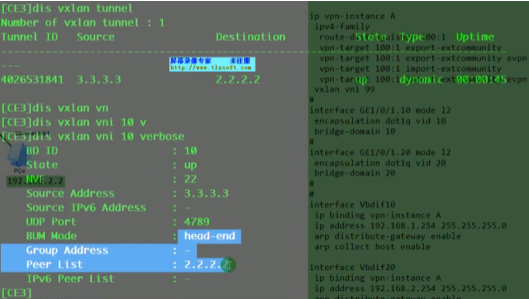
在vxlan的网络中,如何标识nve设备-通过vtep,每一个nve至少有一个vtep,vtep使用nve的ip地址来标识。so在vxlan网络中,vtep地址不能一样

ex:运行ospf协议的路由器需要r-id来标识,而r-id使用loop来标识


两端的vtep地址如上,则这条vxlan隧道就是在1.1和2.2之间去封装的。Ex: vxlan报文就被封装到这两个vtep地址之间,要求这两个地址路由可达。在gre隧道时,指定源为1.1.宿为2.2,也要求1.1能ping通2.2,否则gre隧道不能起来。So vtep即是设备的标识符,又同时用于vxlan隧道的建立,要保证其全网唯一且可达。
上面vtep概念图中,nve1就会使用vtep地址和其他设备建立vxlan隧道,所以在规划时要保证vtep地址的全网唯一且可达。

vni,类似于vlan id,1个vni代表了1个租户/大二层网络 。vni是在vxlan网络中,来标识不同的广播域的。大二层-本质就是大,但仍是二层网络。世界上任意一个角落的主机都可以放到一个广播域中,so大

vlan和vni的类比

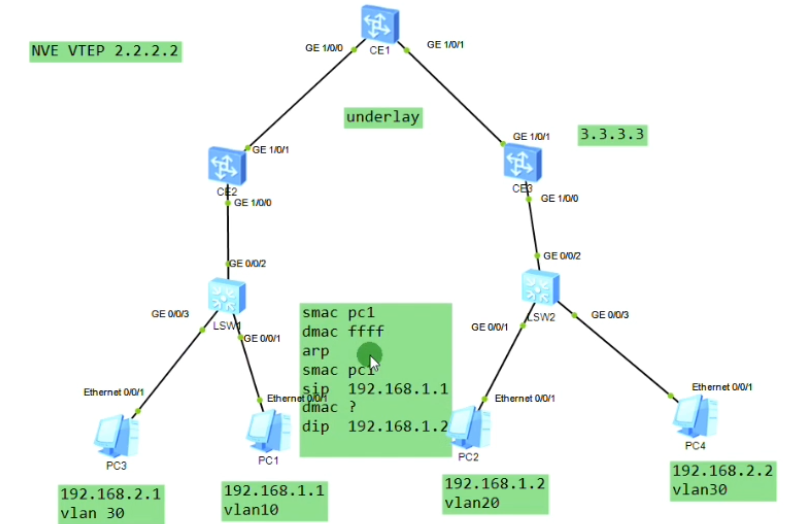
主机在发包时,如果目标地址和源地址在同一个网段,就不会发送给网关,check那会发给谁?

pc上添加静态路由
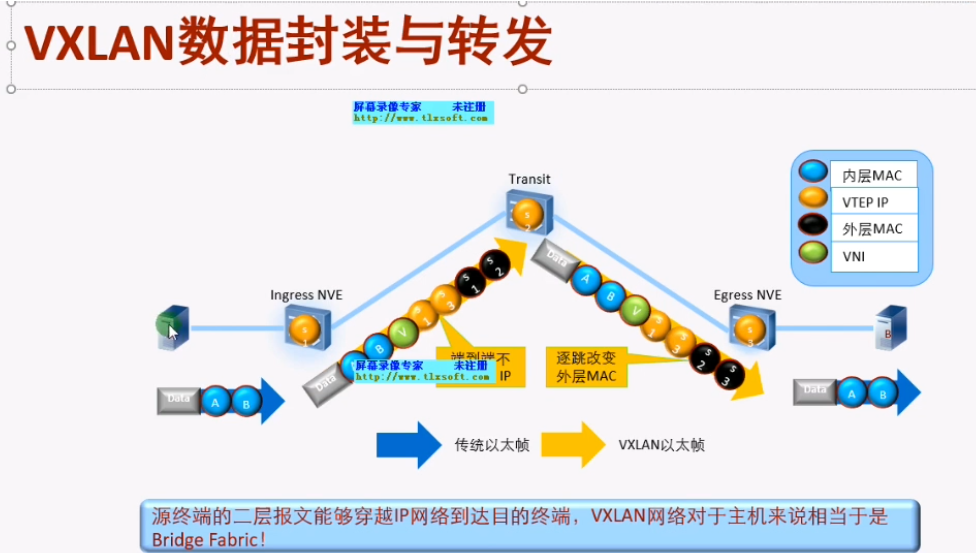
主机A和B的地址在同一个网段,中间是一个三层的网络
黄色1和3分别为源和宿端的vtep地址。数据帧封装完成后,就相当于将二层的数据帧封装到三层的报文中。
通过外层的ip地址查询三层路由,对端接收到后在进行解封装还原为原始的数据帧
传统的三层vpn,如gre,三层vpn,里面传递的就是纯粹的ip包,没有mac地址(数据帧到达pe就被解封装了,露出ip部分了),就是跨网段来访问。上述大二层就是把数据帧整个封装进去。用户感知两端的pc在同一个子网-该技术应用于云计算和虚拟化场景,要求vm不能跨网段部署

原来的技术下,需要互访的vm只能部署在如左侧同一台服务器下/同一个二层网络,但是有大二层技术之后,就提升了扩展性。同时vm迁移后,业务不中断(vxlan在虚拟化数据中心和云计算数据中心内的极大优势)

Ipsec vpn 传输模式,只会封装ip之上的tcp和udp
7层vpn-应用层vpn,不会封装udp,只会封装应用层
pppoe(check文档)不能算是隧道技术,不能实现端到端的通信。是以太网封装ppp,是一种远程广域网接入技术,但其不足以帮你构建vpn
--------------------------------------------------------------------------------
2023-05-04 12:35
Video2
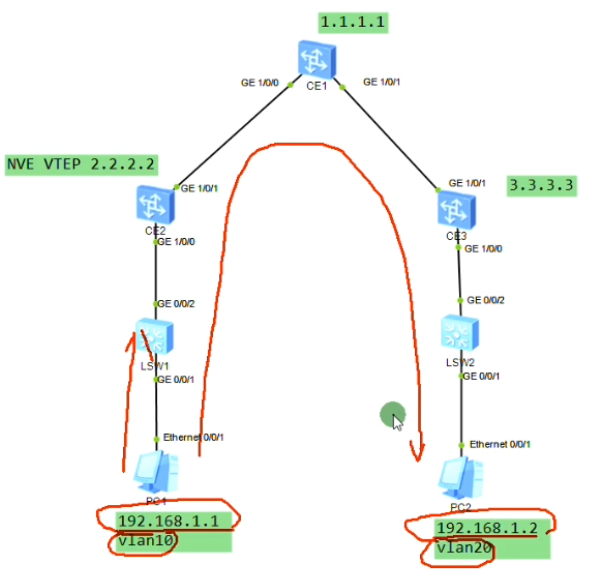
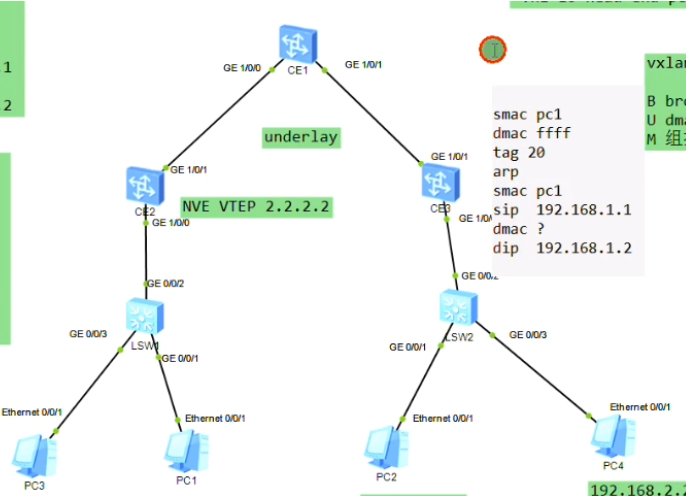
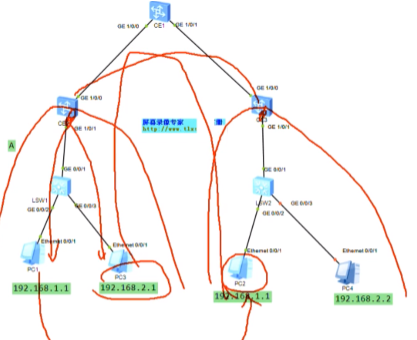
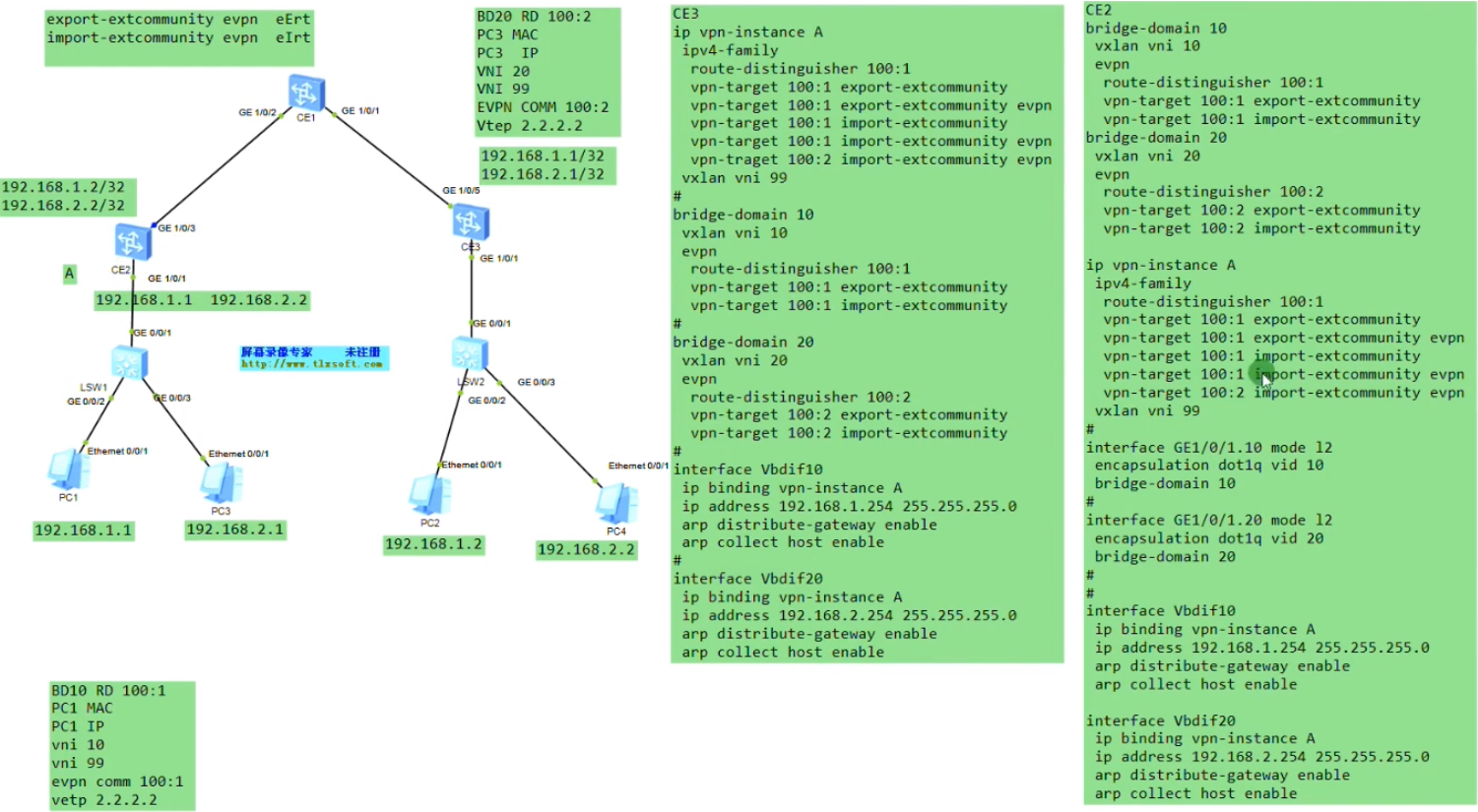
假设上图两台pc为vm或物理机,中间为三层网络,vtep通过环回口来设置。
站在vxlan的角度看整个网络,只要求主机地址在同一个网段即可,主机属于哪个vlan无所谓,都能够实现二层的通信。即,vlan id在vxlan的网络中失去了原有的隔离意义。
现在园区网也会用到vxlan,骨干网络为vxlan网络后,园区的主机在任何地方接入,只要地址在同一个段内,就能实现二层互访。华三的敏捷园区网解决方案用的就是vxlan技术,实现了在整个园区网随意地点的二层接入,只要接入的是同一个vxlan网络,且网段能通,就能实现同二层互访,也可以实现跨二层互访-这个叫业务随行。华为也有业务随行解决方案,但是不是基于vxlan的。
Sw1的下联口配access,上联口配置为trunk
以下为配置underlay网络
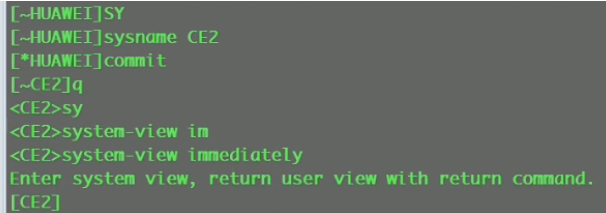
~为ce系列特有提示符,代表未提交,需要commit才能生效。也可加immediately,就无~,可立即生效 //等同ne40
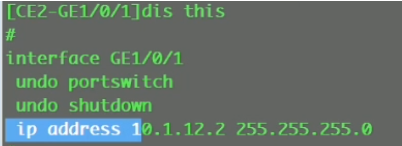
将Ce 系列sw的接口直接当路由器接口(三层接口)来使用
G1/0/0 ip add 10.1.12.1 24
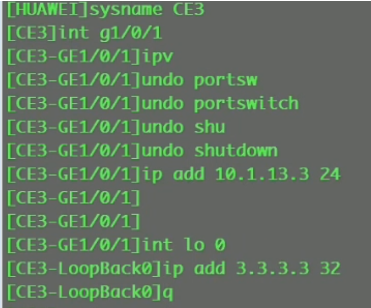
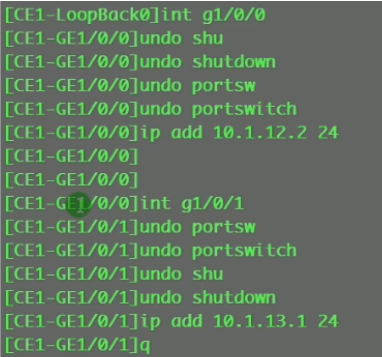
三台sw上配置rip
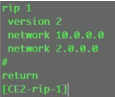
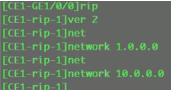
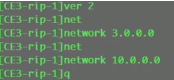
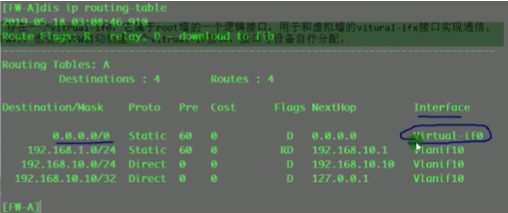
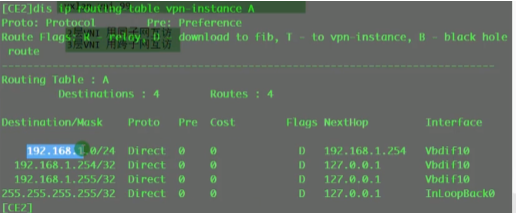
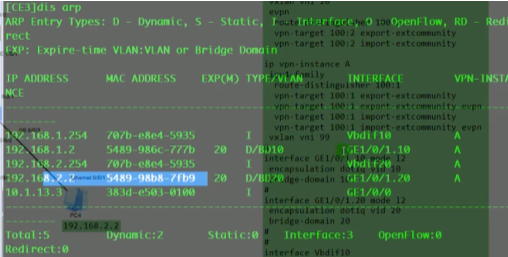
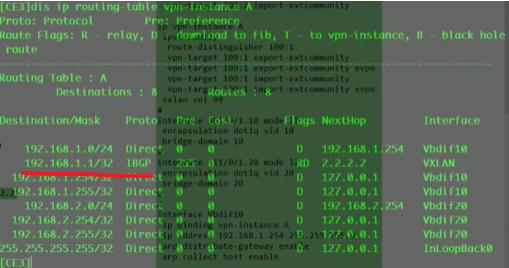
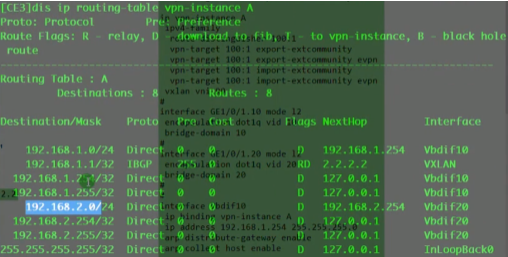
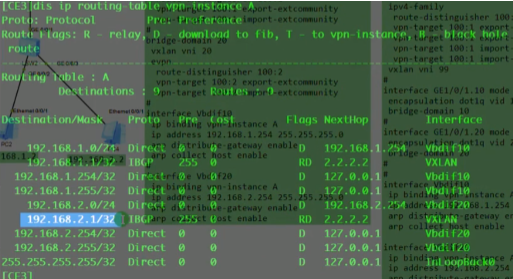
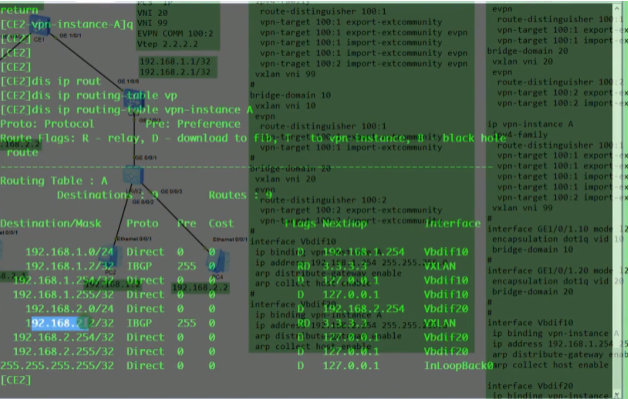
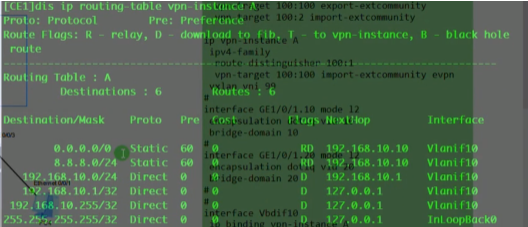
看路由表,能学到路由,保证vtep的地址全网可达。
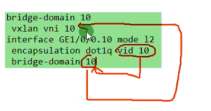
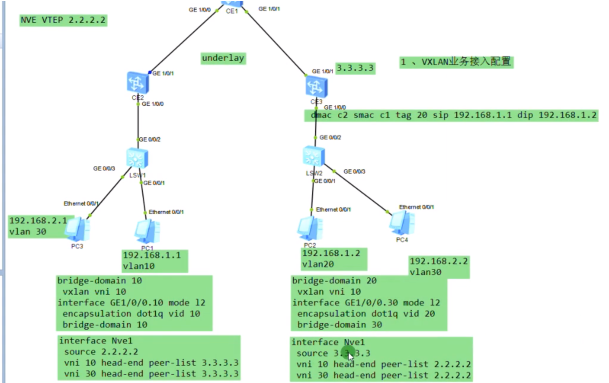
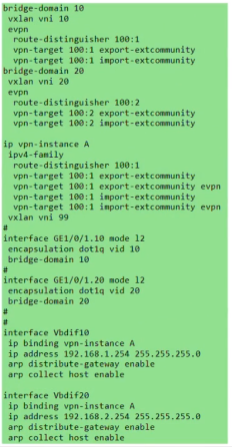
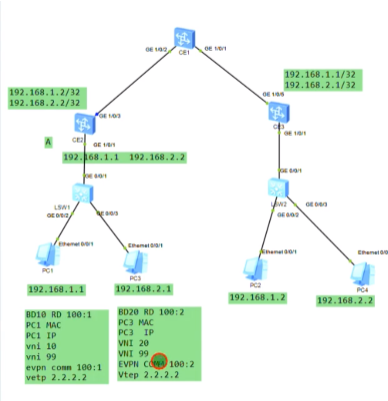
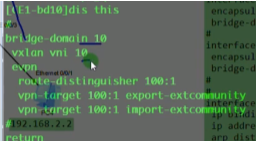
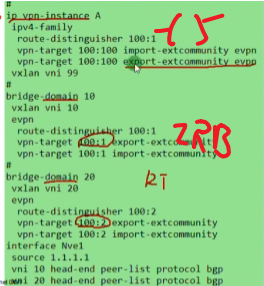
以下为vxlan业务接入配置,创建bd域。用于在nve本地区分不同的大二层网络,仅本地有效。ex创建bd 10,效果类似于vpn实例,每一个bd域只能关联一个vni。10只是一个名称,实际起作用的是vni,代表将这个bd域绑定到这个大二层网络中-vni10。在一台nve上不同的bd域要关联不同的vni。


上图为创建bd域后,为该bd域分配一个vni(模拟器要使用100以下的,否则模拟失败)
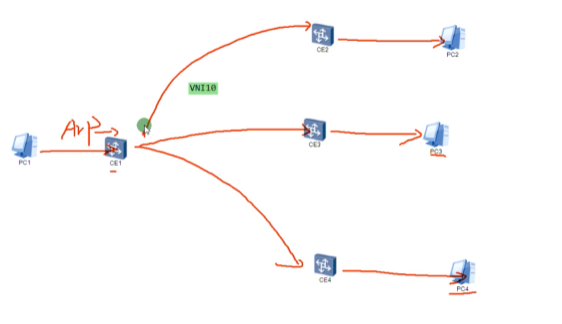
现在想pc1发送的数据和ce2的vni10 关联起来-即,希望pc1属于vni10
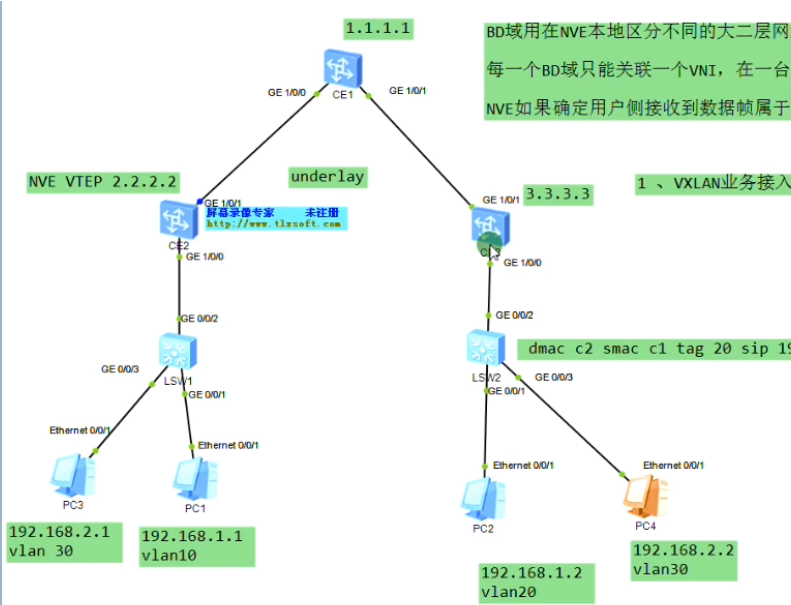
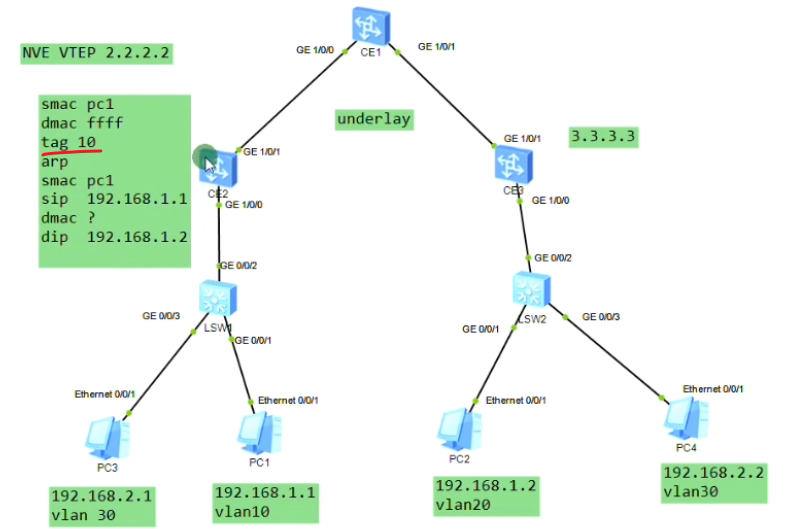
nve如何确定从用户侧接收到的数据帧属于本地的哪个bd域,即属于哪个vni的大二层网络。可以通过在sw1上打的vlan tag来关联bd域,bd域又关联了vni,实现了全部的关联
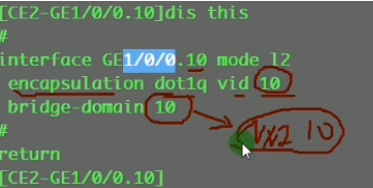
配置二层子接口(单臂路由时配置的是三层子接口)。 从这个物理接口接收到tag为10的数据帧,那这个数据帧就属于本地的bd域10,就绑定到vni10里。即说明这个数据帧就属于vni10这个大二层的数据帧。子接口做vxlan的接入,是根据vlan tag来作为报文的特征来关联bd域,从而关联到这个bd域所属的大二层网络中。这里的配置也说明确实没有控制平面,需要手动配置。
关联性如上
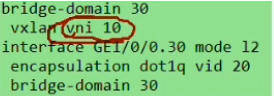
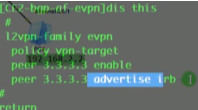
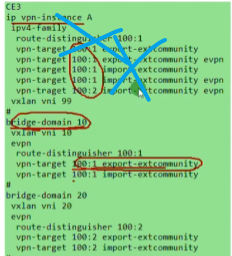
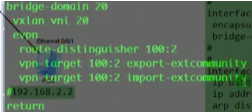
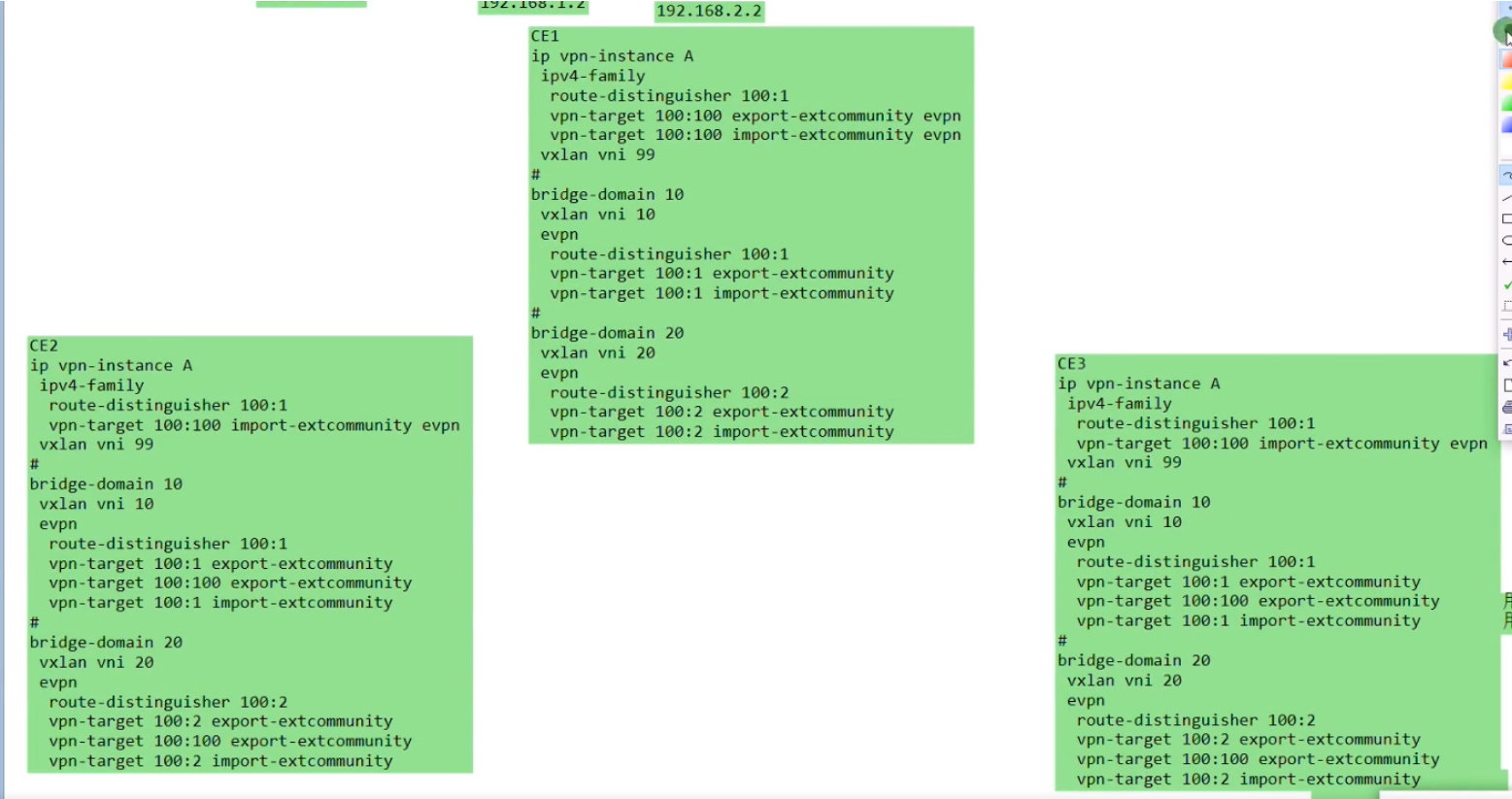
Ce3配置,说明vni才是本质。具有相同vni的数据帧才是在同一个大二层网络里,能实现二层互访。vni有点像rt,一样才能互引路由。
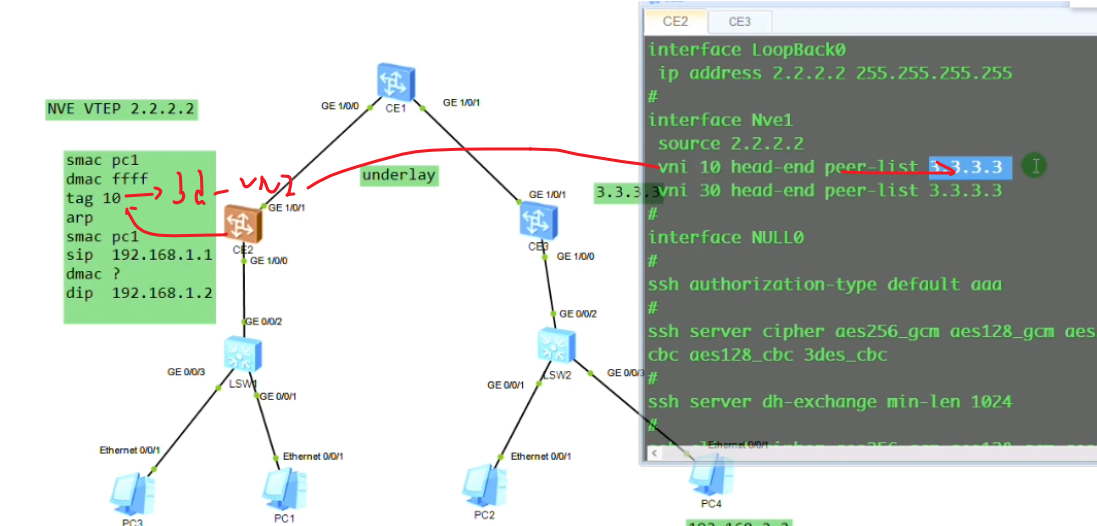
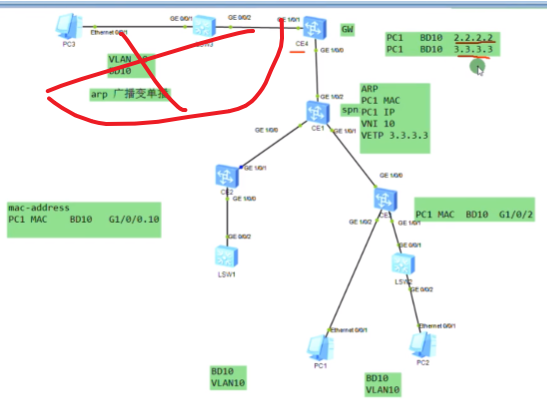
接下来配置vxlan隧道

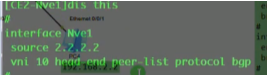
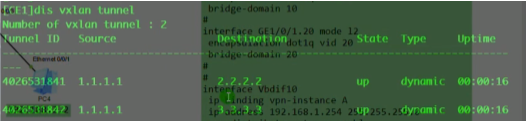
创建nve接口,指定隧道的源地址为自己的vtep地址。针对vni 10 来创建一条隧道。3.3.3.3为目标nve的vtep地址
模拟器的物理接口默认是down的,需要手动un shutdown(真机是默认开启的),两端就可以ping通了
从上图vni的配置(vni 30为后续新增的pc3和4之间的大二层网络),也可以看出不同的vni可以共享一条隧道
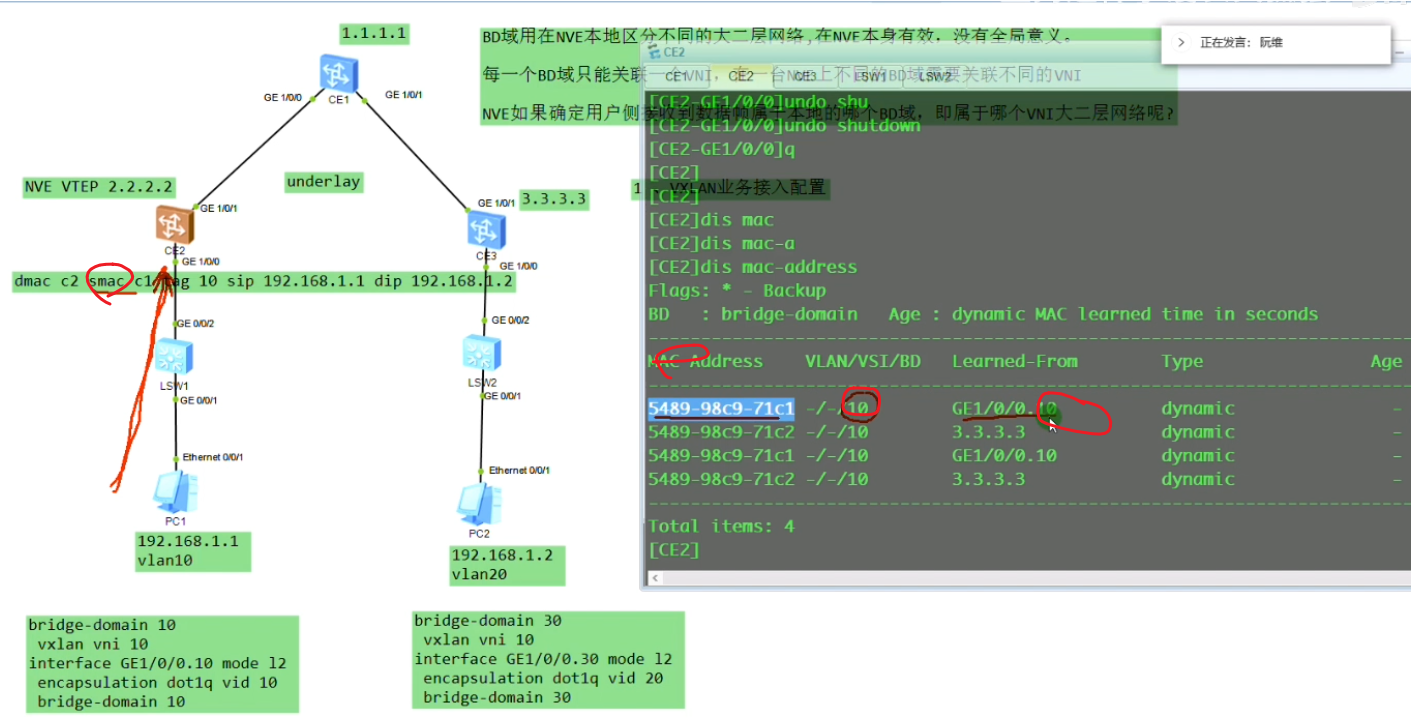
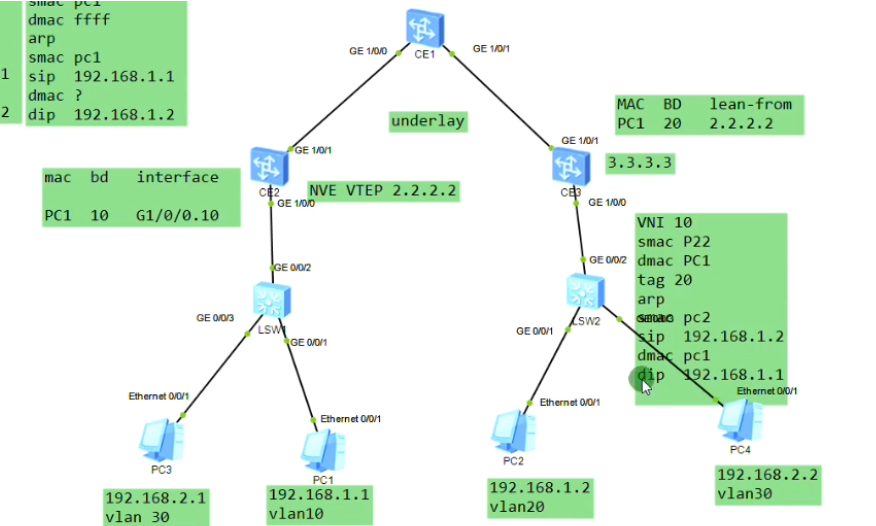
Pc1发出的数据帧,到达sw1,打上vlan 10的tag,然后到达ce2,由于vlan tag=10,其关联的bd域是10。so在上图mac地址表中关联的bd域就是10,其不关心vlan10。So 其认为在bd域10下,g1/0/0.10这个子接口下学到了pc1的mac地址-这就是用户侧的mac地址学习行为。从用户侧接收到数据帧之后,会根据数据帧的vlan tag关联bd域,并为这个bd域创建对应的mac地址表项。包含mac+bd域+子接口。然后将报文进行vxlan的封装,
右侧的bd应该为20
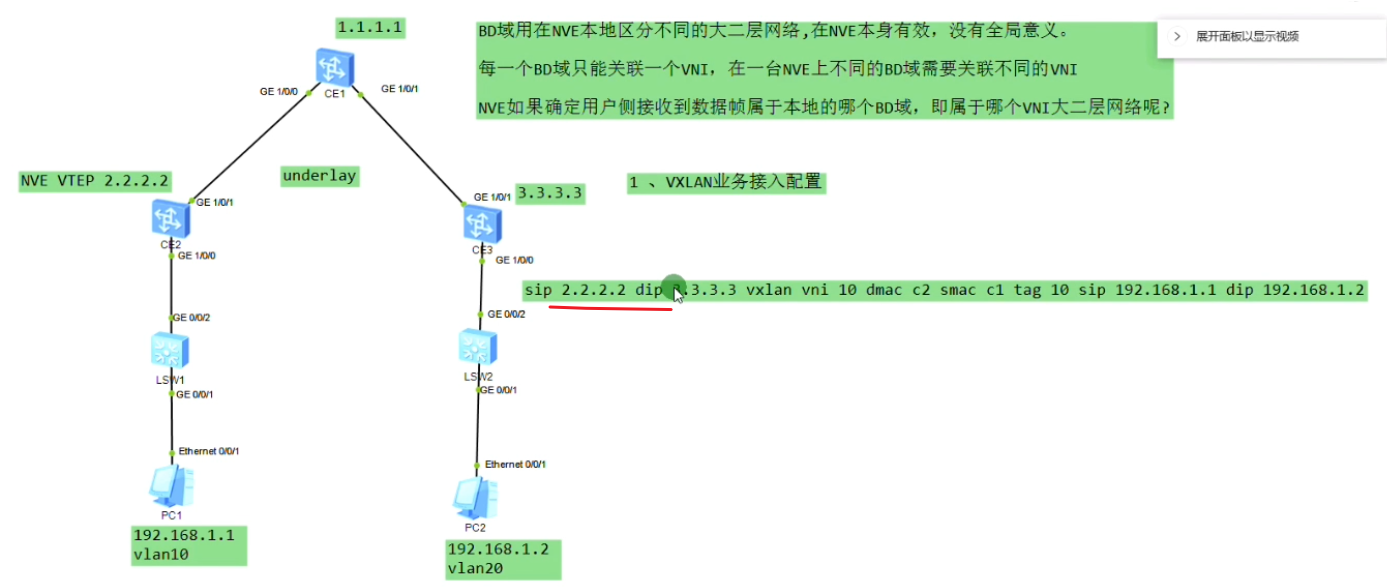
vxlan封装,上图ce2上子接口需要把vlan tag 10剥离-即ce2发出的数据帧是不带vlan tag的。
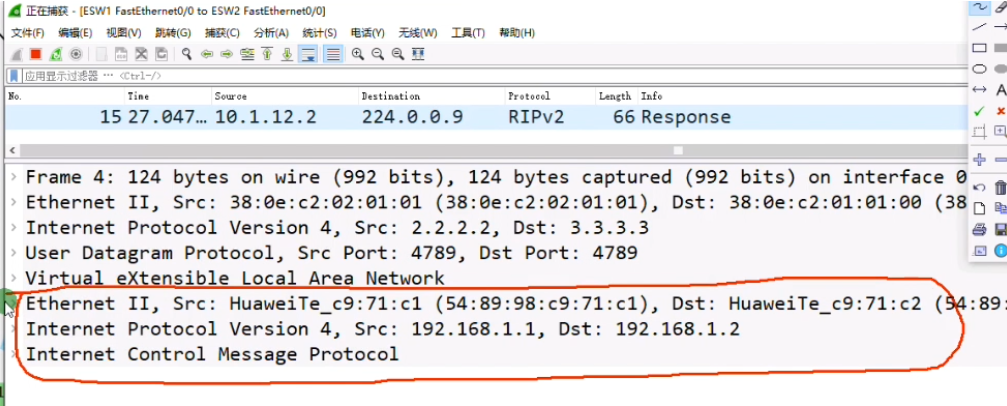
Ce2的g1/0/1抓包

但是报文中没有tag。因为Ce2子接口的封装是dot1q这种类型,收到拥有tag 的报文,在执行vxlan封装之前会把tag剥离,再打上vni。子接口关联物理口,最后通过物理口将数据帧发送出去。在vxlan的网络中,vlan tag就没有意义了,会剥离掉再打上vni-在vxlan的网络就使用vxlan的标识(在我的领域按我的规矩来)。
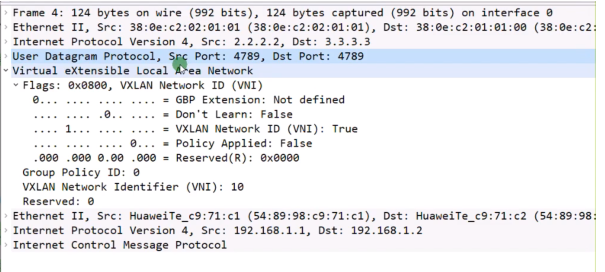
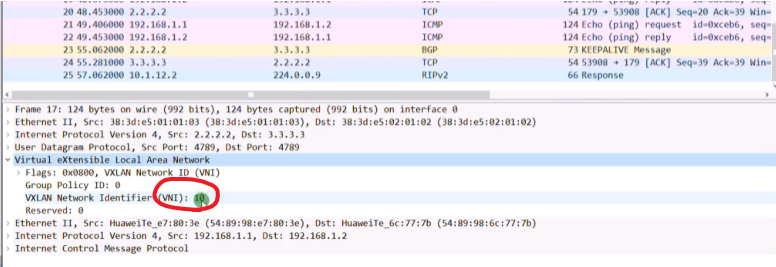
打udp的封装目的是为了实现负载分担
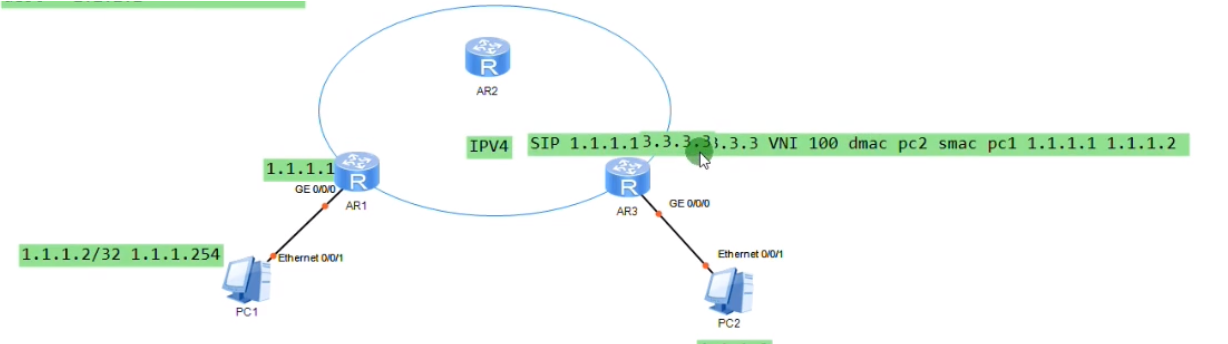
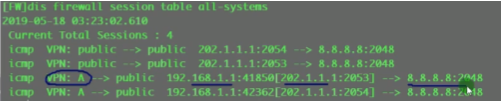
dc场景中接入设备常常这样连。1.1到达3.3是负载分担的-基于流(cost相同,igp都能实现等价负载分担)。而流是通过5元组来区分的(+protocol。没port的事,port来标识上层为vxlan封装)。如果给vxlan报文添加一个udp,就能更好的借用现在设备的负载分担算法,在多条等价的路径上去转发报文,充分利用dc的带宽。因dc通常会采用双路冗余,就可以根据5元组来实现负载分担(本质在于匹配流量)。借助流的五元组,更好的在dc场景实现负载分担的效果。华为设备上Dport4789,代表上层是vxlan报文。报文格式中最外层的2.2和3.3就是vtep地址。
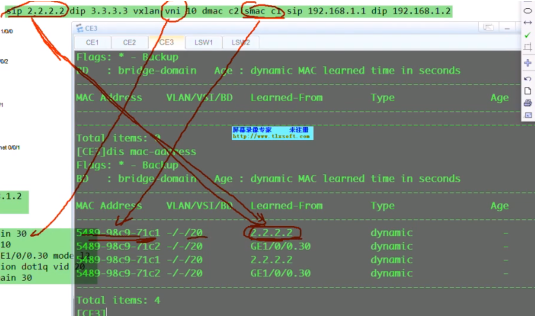
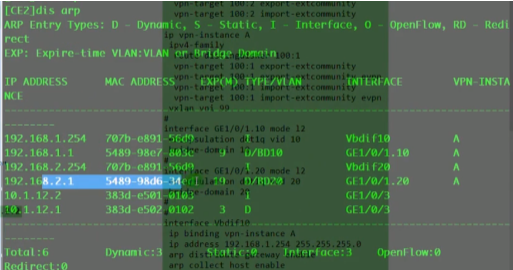
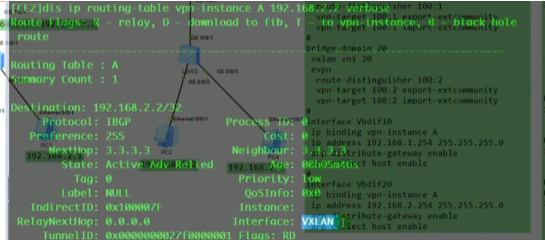
ce3提取数据帧的源ip(对端vtep地址)和源mac(真正的源),记录到local的mac表中。代表pc1是从2.2这个vtep来接入网络的。因为未来回包的时候,要回给2.2,so这里学一下mac。本质就是在数据帧到达vtep后,vtep将对端vtep地址(隧道端点)和源mac地址做一个关联,然后根据vni10,属于我本地的bd域20。bd域关联了子接口,子接口又关联了物理口,就可以从物理口把数据帧发送出去,这个子接口关联的vlan20。so在ce3发出数据帧时会重新打上vlan tag 20,lsw2接收到后就会根据目标mac地址查询mac地址表,如果没有相应的mac地址,则泛洪到所有属于vlan20 的端口上
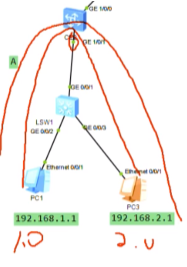
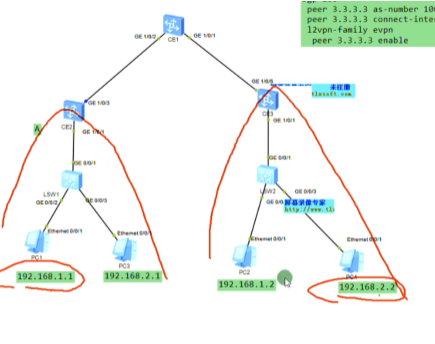
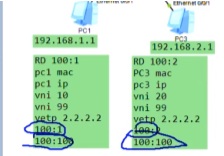
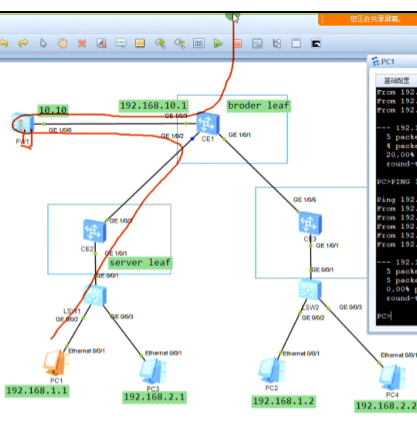
新的需求,增加两台pc3,4。
这里面没有设置网关,网关有多种,集中式网关和分布式网关。今天只是同子网互访搞定
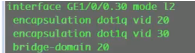
一个子接口可以绑定多个vlan id,组网更灵活
vni是虚拟隔离的,如图,网络变成了两个大二层vni10和20,但其底层使用的是同一个ip网络-1.1,2.2,3.3组成的是underl网络(就是vtep组成的可达的网络)。在这个网络之上存在两个隔离的大二层网络,相当于两个广播域。从用户角度来说,就是在不同的网络里-网络虚拟化:共用网络物理资源但逻辑上是隔离的。本质是通过vxlan隧道来实现网络虚拟化的功能,卖的时候为了显示高大上,就称为vxlan网络功能虚拟化。大:体现在只要三层网络可达的地方,vxlan隧道都可以建立。同时只需要边缘设备支持vxlan即可,中间设备不需要支持,只需要支持ip就行。So nve-数据进来的时候,就好像进入了虚拟网络里,所以称为网络虚拟化边缘设备。
不同的vni,可以理解为不同租户申请的vm(或者同一个租户的不同部门,后期可以通过网关实现3层互通),租户之间的网络是隔离的。用户就不用关心vm在数据中心的哪个位置了,不管在哪,都是在同一个局域网内-网络功能虚拟化。
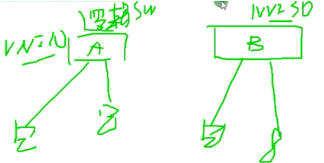
每一个vni都可以看成一个独立的sw,在云计算中该sw被称为逻辑交换机-利用vxlan做出来的,能够实现二层互访的网络。用户感知到的网络结构就是上图。dc就是使用物理硬件虚拟出来设备来实现你的功能需求。
vxlan本质就是隧道,实现了网络虚拟化。讲到这里,只是实现了相同vni的互通,后续还要通过网关,实现不同vni的互通。
从业务角度来说,可以实现虚拟化网络的生成,也能实现网络的隔离,并将网络资源卖给用户。vni取值1-1600万,so公有云就是使用vxlan来实现用户网络隔离的。用户vm隔离和互访在公有云中都可以做。
上述lab是在pc已互相知道对方的mac的单播行为,如果不知道对方的mac,就需要广播方式发送arp请求,但要发给谁?如果有多个vni隧道,就需要全网泛洪-因为vtep不知道目标主机在哪个vtep上。及广播报文如何来进行转发。pc如何在vxlan网络中实现arp解析的
配置总结如上
解释了为何出现云计算和sdn,因为在公有云中这种业务非常多,如果都是手动配置,效率太低。最严重的问题是vm从一个dc迁移到另一个dc,需要隧道重写,原有隧道要拆除-靠人来运维这个网络是不能实现的。私有云规模小,可以通过手动去做vxlan隧道。但大型私有云和公有云场景,为了维护vxlan隧道,避免vm跨dc迁移的影响,就需要用到sdn解决方案。是一款控制器软件,需要和云平台做对接,云平台知道vm从哪迁移到哪了,然后根据lldp协议(类比cdp,LLDP提供了一种标准的链路层发现方式,可以将本端设备的主要能力、管理地址、设备标识、接口标识等信息封装到LLDP报文中传递给邻居设备)发现这个vm新上线的物理交换机是哪一台。lldp协议的信息会通过网管网络交给控制器,控制器再动态的把相应配置下发到新的设备上,并将老设备的配置自动删除。sdn的思想:业务的灵活配置和删除,来实现业务的快速切换。人工做是不可能的,因为在公有云里,每天可能需要上千台vm要做迁移。
所以需要sdn,用软件来实现动态的部署,并不是转控分离的sdn,而是业务型sdn-sdn第二代,第一代为转控分离的sdn,基本已经发展不起来了。目前各大厂商推的是业务型sdn,针对云计算数据中心里的云业务。SDN-软件定义网络,减少管理员的工作量,让网络自动运维起来。但是和各种云平台的对接开发不好做,如 op、fc,华为目前只能和华为自己对接,能和开源的云平台对接,但是不能和厂家的云平台对接。当前华为的sdn项目没有实际应用起来,很多都是跑着测试的。
bug:配置维护麻烦。如果云平台做了误操作,云平台的配置跟控制器的配置不同步了,会各种报错。最后需要登录到控制端的底层和云平台的底层去删数据库,把数据库里的错误日志记录删掉。还有云平台和控制器之间的网络断开了,现在云平台的后端数据库已经ok了,但是这个数据库的信息没有同步到控制器上,业务就通不了。
华为卖东西有两种方式:基于产品;2基于项目:你有什么问题,我来解决你的特定问题。
------------------------------------------------------------------------------
2023-05-05 16:20
视频3
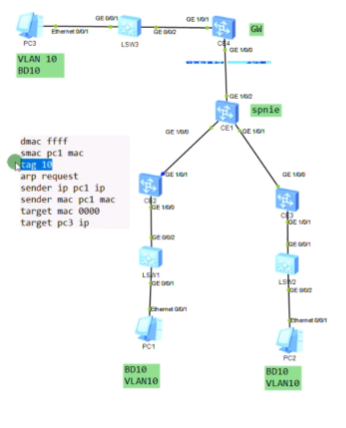
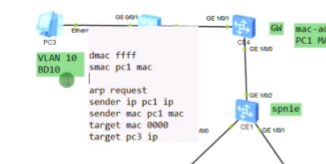
Pc1要和pc2通信,首先要发送arp广播,封装如上图
报文到达lsw1之后,会打上vlan tag10,交给ce2
Ce2接收到之后,判断是广播帧,且vlan tag为10,配置已关联到bd 10,就会继续检查隧道配置-nve,检查vni10所关联的peer-list都是谁,如果vni10存在多个peer-list(同一网段的主机是可以从任意一台ce sw上接入的)。ce就会将这个报文进行vxlan封装,并进行头端复制,dip为每一个peer的地址。就相当于将这个arp广播泛洪到vni 10的所有端点路由器上,类似于广播泛洪。
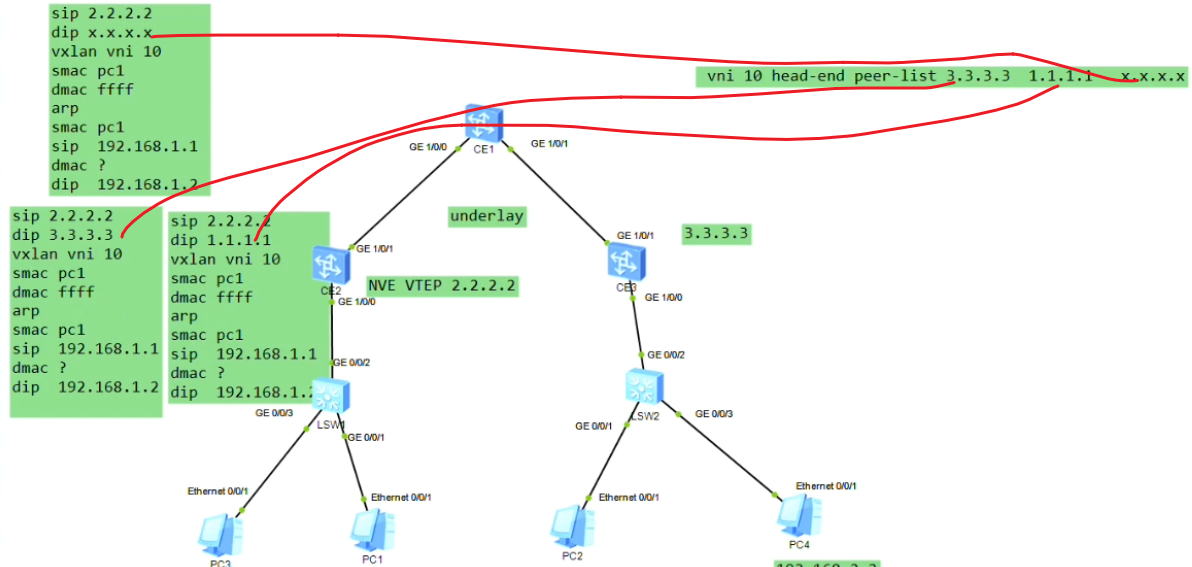
vxlan报文的头端复制行为。vtep会向整个ip网络,根据peer-list中指定的地址,向每个地址分别复制一份发送给对端的主机上。把arp广播泛洪到整个vni10的peer-list上。
即vxlan如何转发bum报文,此例就是在vni 10上peer lists列表中的所有地址进行泛洪,和其他的vni没有关系。

指的都是针对数据帧的行为。相当于在一个传统网络里,把一个bum帧泛洪到该vlan的所有接口上。
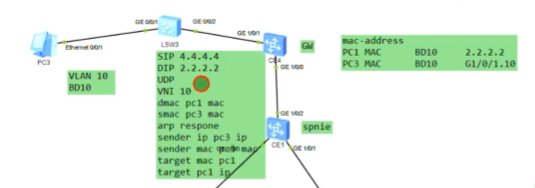
通过vxlan隧道到达ce3,解封装vxlan,并封装vlan tag 20,pc2就可以接收到该广播。
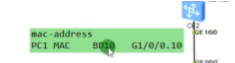
Pc1在发送arp请求时,ce2会学习pc1的mac和对应bd域的关系和子接口的关系,形成mac地址记录。

arp报文发送到达对端nve后,对端也会进行mac地址的学习,根据报文中携带的vni,查询本地配置,匹配本地配置的bd域。即ce sw本身就会对vxlan相关数据进行学习和记录。对端vtep通过这个记录,就知道通告这个vtep可以到达目标主机
Pc2回复arp应答
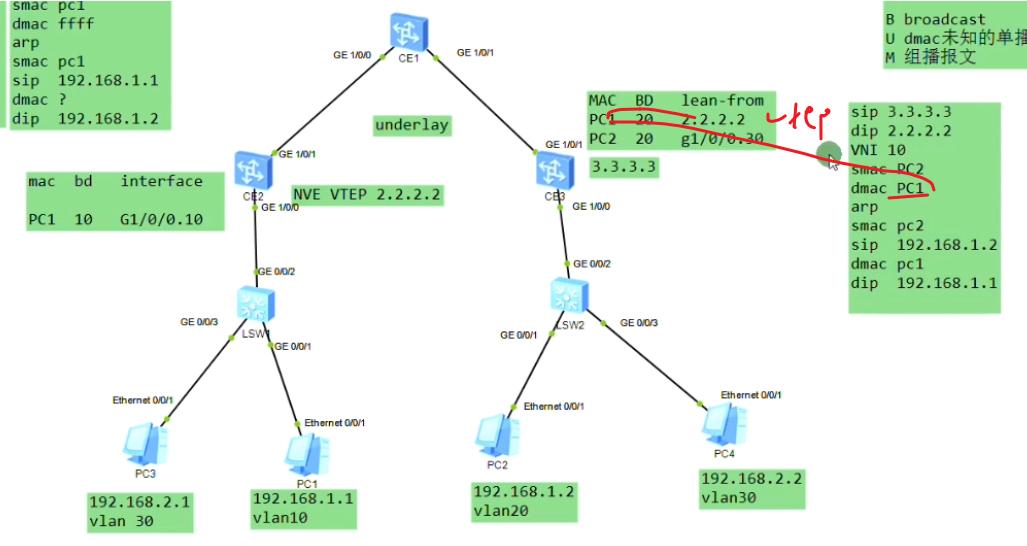
报文到达ce3,学习pc2的mac,本地的bd域和子接口。把vlan tag拆掉,压入vni10。因这个数据帧的dmac是pc1,而ce3的mac地址表中有对应的表项,是从2.2.2.2学到的。就封装ce2的ip作为dip,在封装2层mac,单播发送给ce2
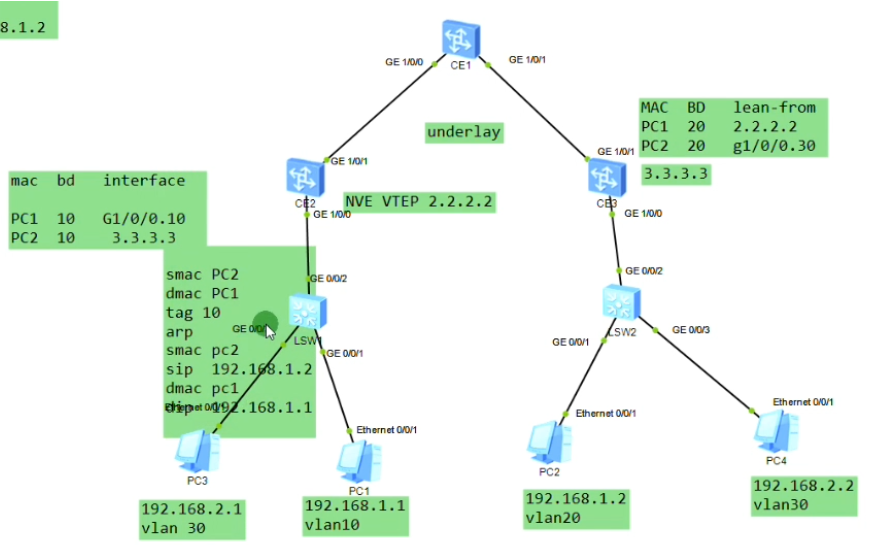
Ce2接收到,会进行源mac地址学习。先根据vni 10关联本地的bd域10,从3.3.3.3学到,解封装重新打上这段的vlan tag 10,至此已经完成了arp解析。后续pc1和pc2之间的报文就不需要头端复制了-除非ce上的mac地址被老化或失效。
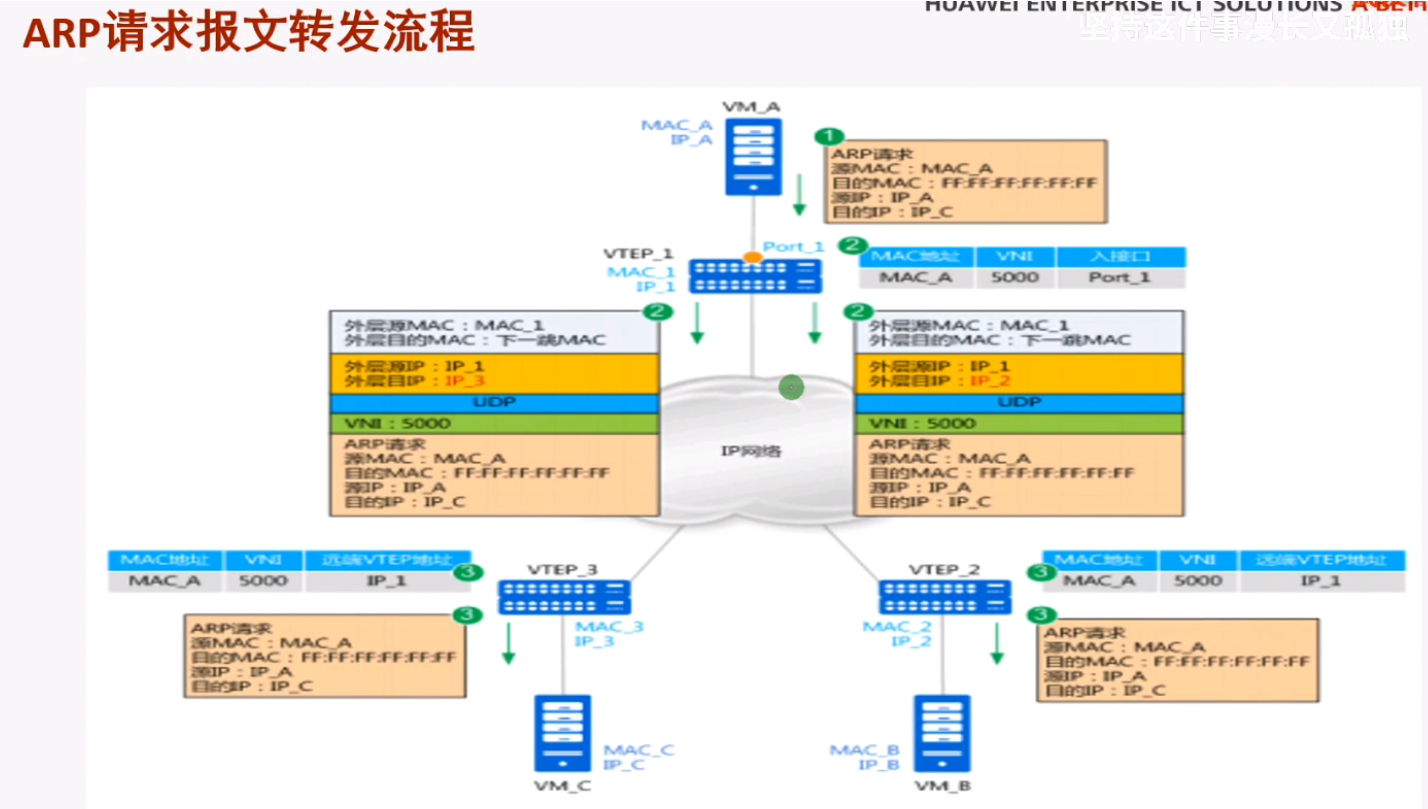
vtep处将arp广播进行头端复制,分别发送给vtep2和vtep3(因为都存在vni 10的peer)
测试不通,配置无问题的话,就将nve下的vni删除重新配置。现象为配置保存后重启就不行了。在尝试把nve接口全部删掉

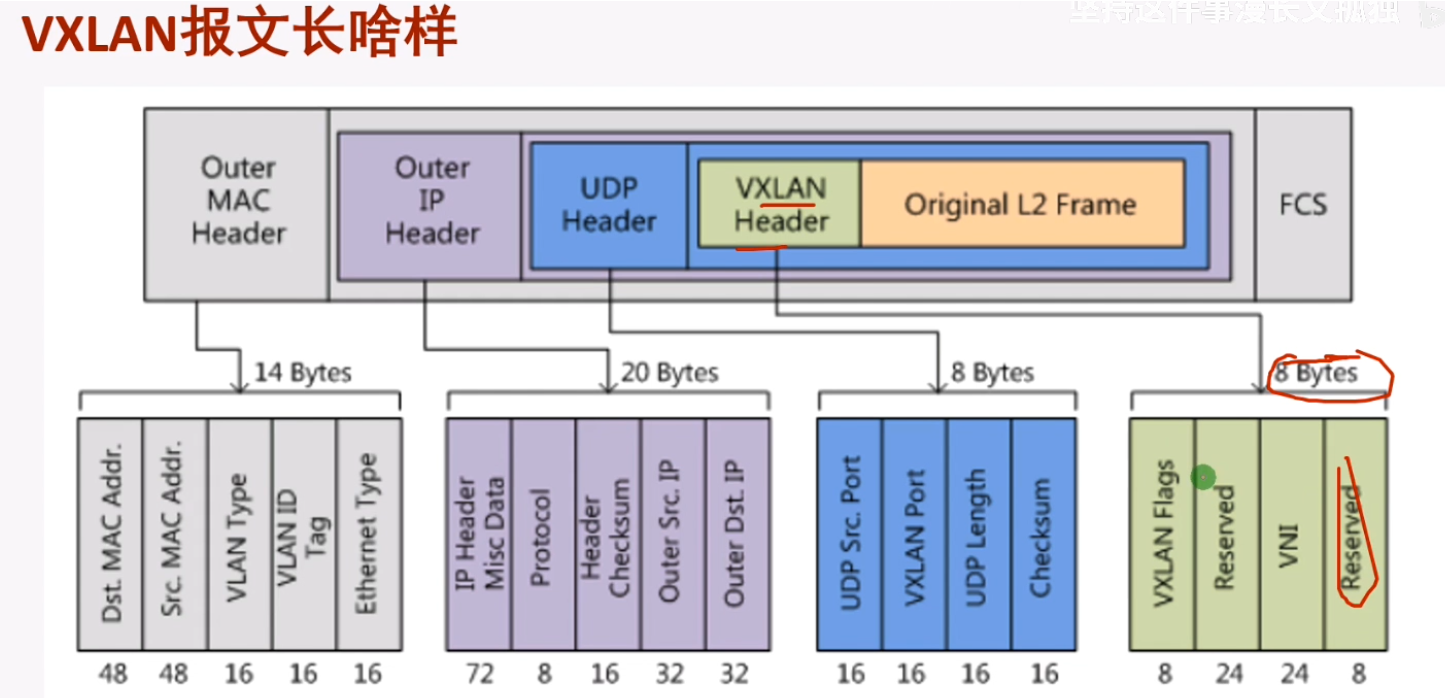
第一行的R:reserved。I:必须置一。vni:24b-1600万,这个数量级对公有云来说很难用完,即便后期用完了,可以使用reserved位进行扩充。而vlan只支持4096个。
Udp header:d port=vxlan port 4789华为。S port是通过内层数据帧的帧头信息,通过哈希计算得到。
sip和dip就是vtep的地址(上图字段前后顺序写反了)
子接口封装
vxlan和evpn都是大二层技术
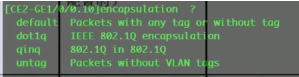
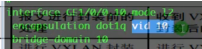
Vid10明确了指定vlan。
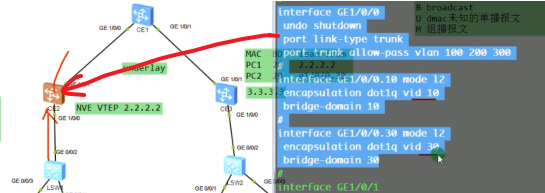
同一个物理接口,可以传统二层和大二层网络在一起跑。就这样配,然后ce的子接口上没有定义的vlan就走传统二层网络。此配置说明在这台sw上传统的vlan业务和vxlan业务能同时混合接入。vxlan和vlan的网络可以互访
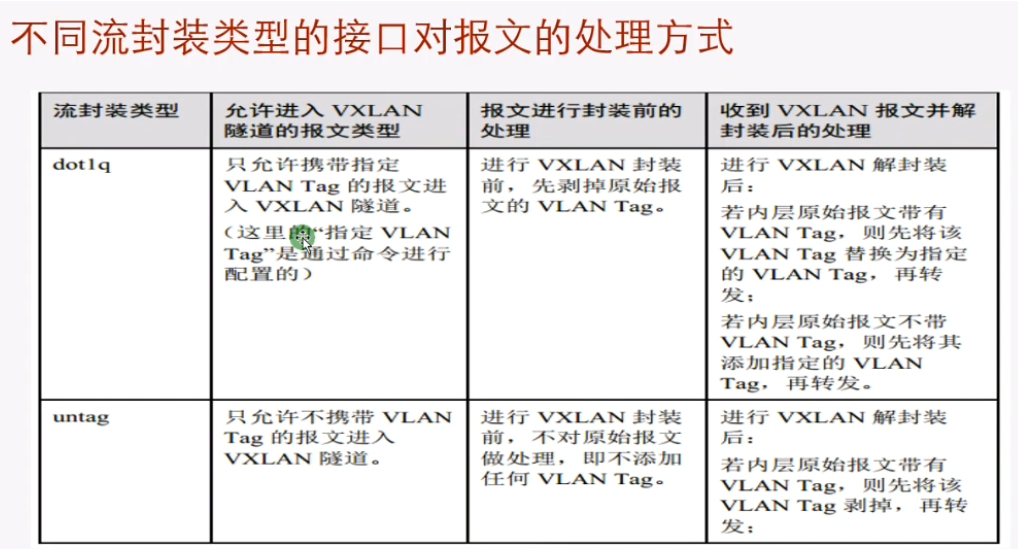
Dot1q,右侧,接收到有vlan tag的数据帧时,会根据vni查询本地的bd域,找到这个bd域绑定的vid是多少,将这个vid替换成vlan tag向本地发送(即,我不在乎你原始在哪个vlan,到本地我会给你换本地vni对应的vlan tag。只要保证主机在同一个网段,不管他们在哪个vlan,我把你们放到同一个vni内,都能通)。Vlan tag在vxlan的网络里没有任何意义。
逻辑:vni绑定的bd域,bd域关联的子接口,子接口封装的接口类型所关联的vid
端口默认的pv id为1,trunk口默认的pv id也是1,untag情况,就是access和trunk接口的pvid都是1,那上到ce侧就是untag的数据帧
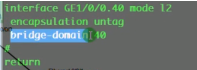
在这个物理接口上,收到只要是untag的数据帧,都属于bd40(只允许不带vlan tag的数据帧进入到vxlan隧道),进行vxlan的封装。来和出去的时候都不带tag
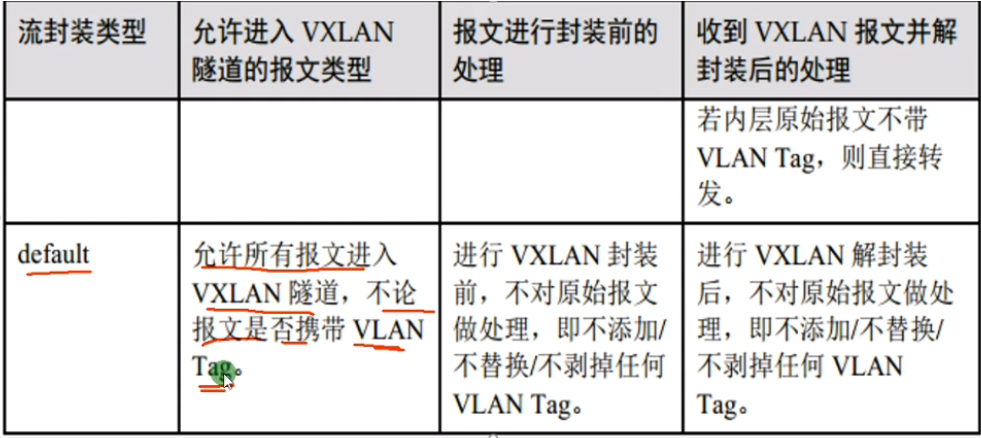
有没有vlan tag的都进入vxlan隧道,,把二层数据帧整个打包到vxlan报文中-原汁原味。解封装亦此
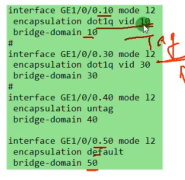
上图的配置,当vlan tag 10的数据帧到达接口后,会有冲突,设备无法判断属于bd10还是bd50,即想要使用default类型的子接口,需要独占一个物理接口,如下配置
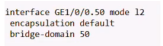
一个物理接口下有一个子接口是default类型的话,就不能有其他类型的子接口。这个物理接口上上来的所有数据帧都属于bd50。所有vlan都被其抢走了。
还有一种qinq子接口封装模式,用的少,看产品手册
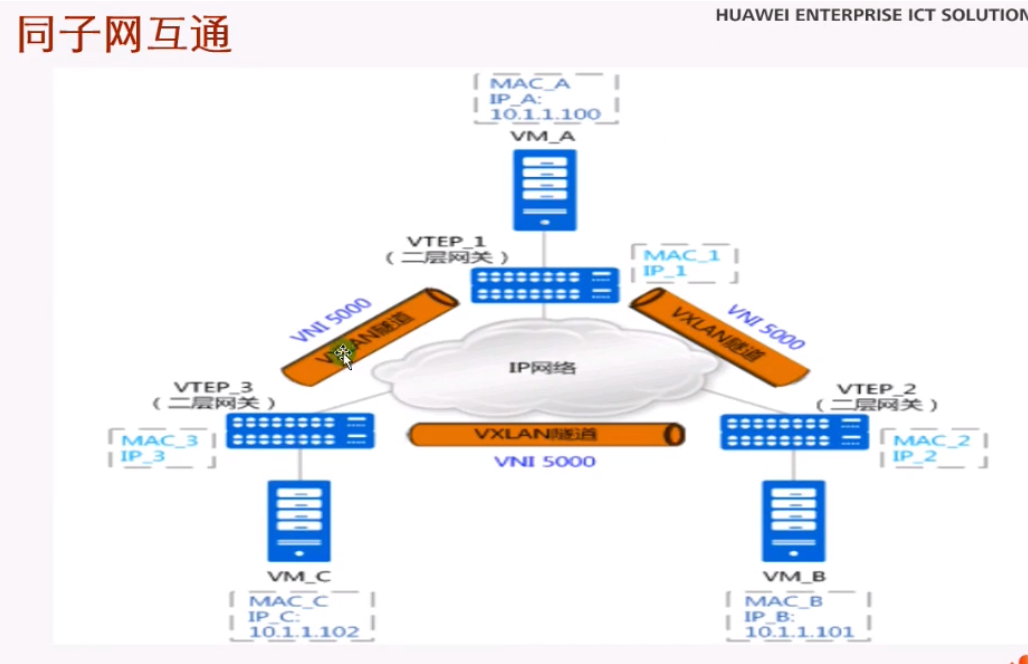
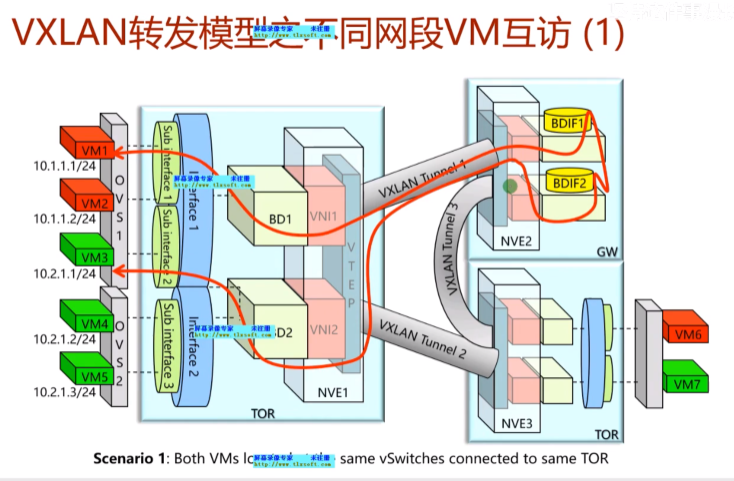
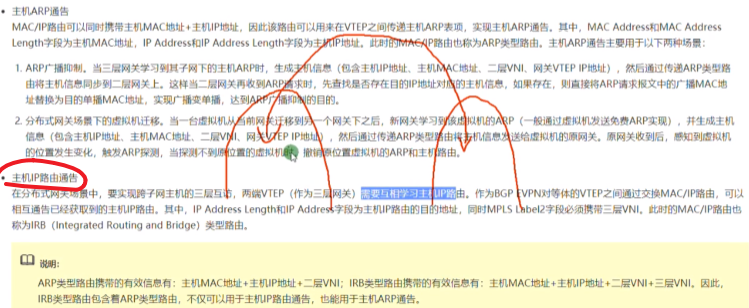
跨子网在vxlan网络中的实现
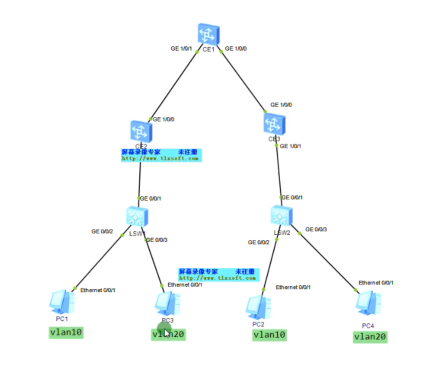
同一个vlan,可以通过vxlan互访;而不同vlan,就需要部署网关了
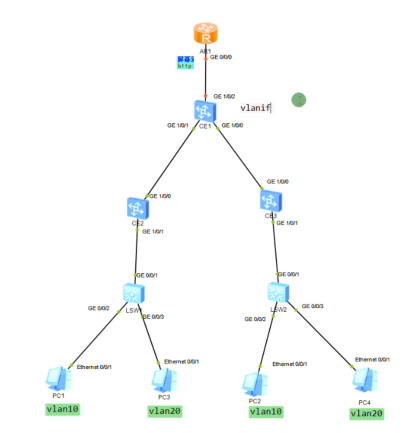
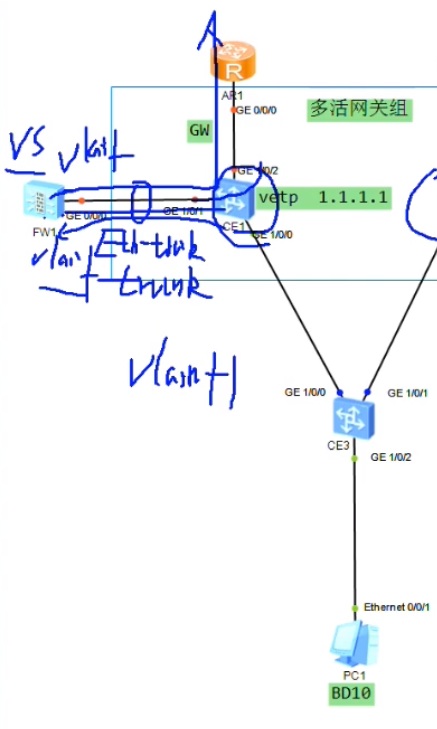
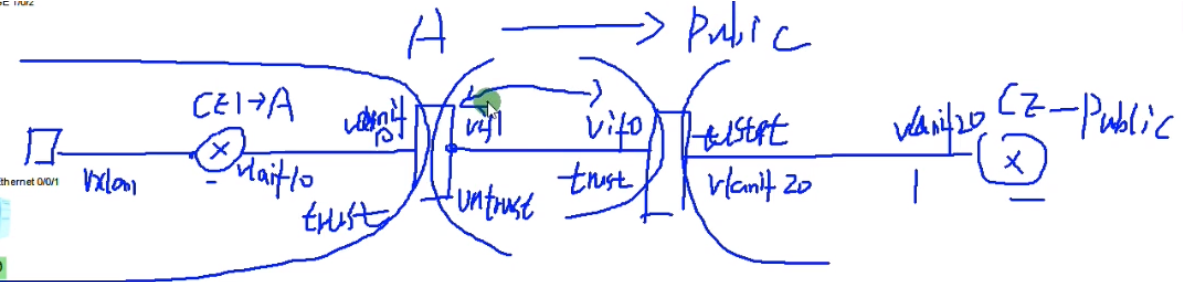
可以在网络中部署一台R-做成单臂路由,然后把sw1的上联口配置为trunk,用子接口,通过单臂路由的形式来实现跨vni的三层互访。但是在dc场景中采用这种单臂路由来实现vxlan网络的互访有点繁琐,就可以借鉴三层sw的特点,只是在ce1上做成vxlan的网关来实现三层的互访,就相当于创建vlanif来实现三层的互访-就不需要路由器来做单臂路由了。
lab步骤:1.同子网通,2.跨子网通。
接入交换机配置vlan 10,20 ,上联trunk
Undo infor center enable
Ce sw 物理if需要配置undo portswitch。ce间全网跑rip,version2,network
集中式网关使用ensp500的版本,但是这个新版本能够支持evpn,但是这俩bug还是多,很多做完了不通。不行就把12800设备删了,重新取一台出来。不行就把镜像删了,导入500的。总结做集中式网关用500的,而做evpn时用新的12800的
此为500的镜像
后期还有多租户的场景:现在是一个租户:一个公司的4台电脑,那另外公司的电脑来了如何隔离?
在dc的云网一体化解决方案中,所有的配置都可以由controlle自动下发,这里是手动去配置静态vxlan的网络。未来的趋势就是:underlay和overlay网络配置都是0配置,设备上电插上网线,配置会自动下发
敏捷控制器分园区版和数据中心版

华为现在有3大控制器:1.AC-SDN 数据中心控制器(dc);2.AC-campus敏捷控制器(做园区网的接入认证的);3.wan-sdn,做广域网的。
以上三种都是软件,都是叫ac,但是后缀不同
集中式网关的配置
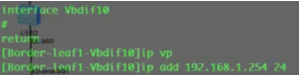
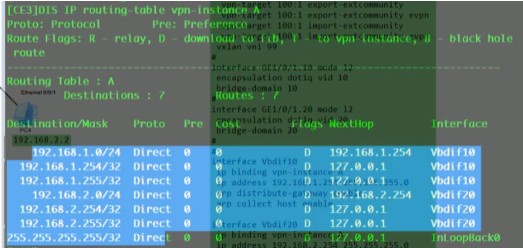
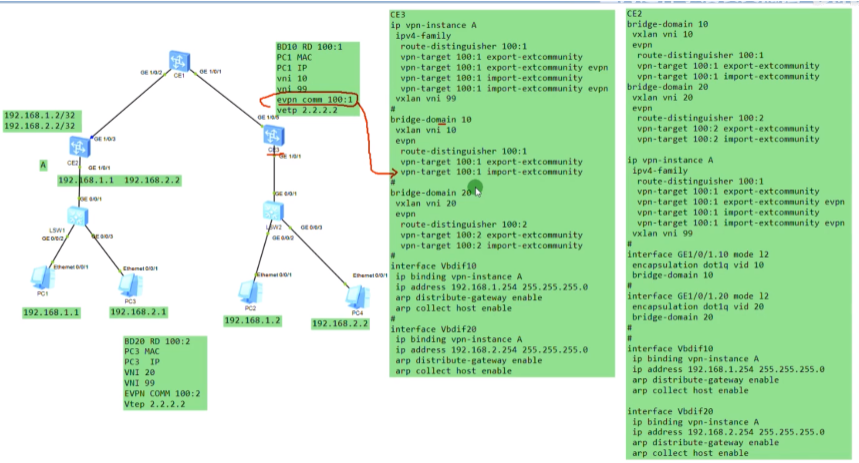
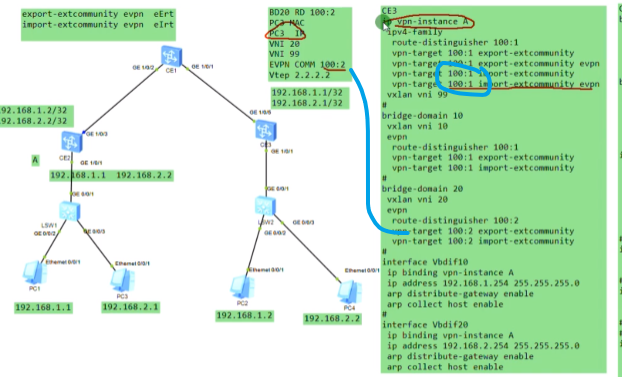
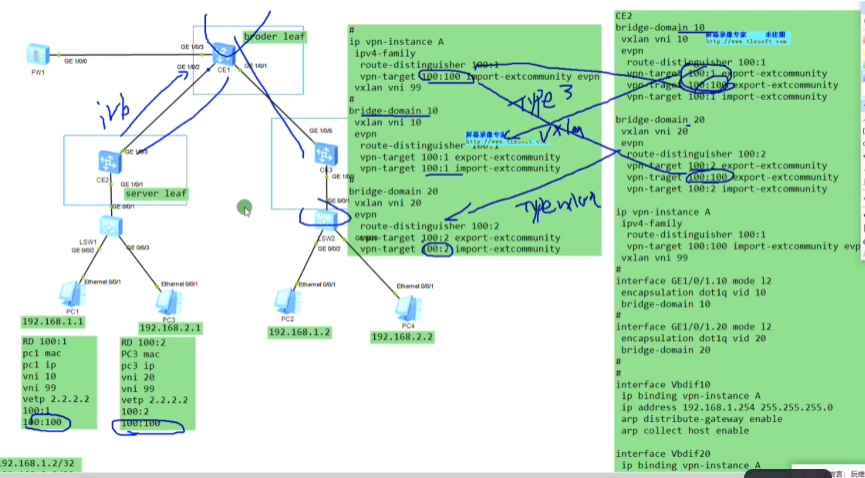
在ce1上创建bd域10和20,分别绑定vni 10和20,创建vbdif接口,其取值和vxlan的取值范围一致-1600万。每一个bd域要求对应一个vbd if接口。相当于在传统网络中vlan 10,对应了vlan if10这个接口,而在vxlan网络中,bd10对应一个vbd if10(将sw当成三层)
在配置vbdif10 和20的ip地址。如果隧道起来,这两个接口对于这台sw就是直连路由。但因为pc1和pc3要和网关通信,就相当于ce1和2之间要建立一条vxlan的隧道(vni10和vni20的),如果是实际的应用那后期的配置量就增大了,vm的迁移,这种手动去维护就不现实了。
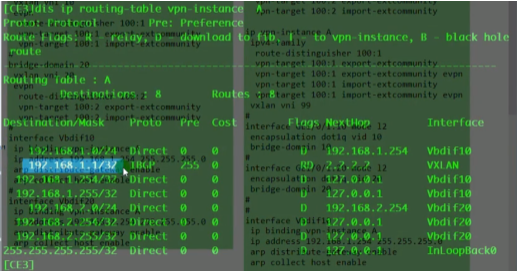
此时pc1 ping网关,数据帧就封装在2.2-1.1的隧道中。然后网关就会学习下面vm的mac,
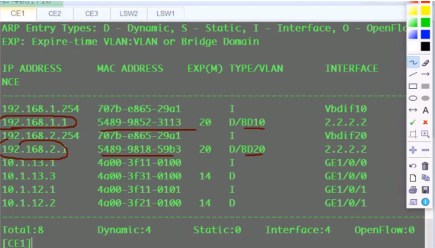
在网关的arp表中,存在对应bd下vm的mac地址
以上称为vxlan网络的集中式网关,所有vni之间的三层互通,都是通过ce1来做路由,ce1上的每一个vbd if接口都当成直连路由看待。

对同一个租户的4台vm,通过vxlan技术来实现网络虚拟化。传统的硬件网络结构,完全通过虚拟化来实现,用户不在关心硬件设备-本来设备也不是用户的。底层可以是某个场景的云底层架构,然后在这个底层物理架构的基础上,为某个租户提供网络虚拟化的功能。用户就不需要在购买r和sw,dc卖给用户的就是两条直连路由和两个vni,你卖给用户的只是逻辑资源。
vm上的虚拟网卡只能叫nfv-用软件来实现硬件网卡的功能;虚拟防火墙也叫nfv-用x86的vm来实现了华为的硬件防火墙的安全能力
有其他租户的话,路由的隔离?
通过在ce上创建vpn,然后将vbd if接口绑定到相应的vpn实例中,实现了路由表的隔离(租户的路由表和underlay网络的路由表也隔离了)。可以将一个公司的多个子网都绑定到同一个vpn 实例中。本质就是为每一个租户分配一个vpn实例,来实现租户间路由的隔离。
在云里实现底层资源的共享,但逻辑资源没有隔离。二层是通过vni隔离的,三层是通过vpn ins隔离的。当前的私有云和公有云都是这样部署的
如果vxlan和传统vlan里的主机互访
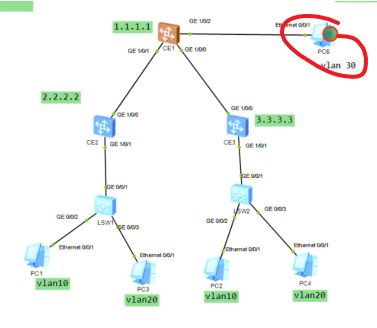
Ce1的g1/0/2接口,配置default vlan 30,然后配置vlan if 30 ,配ip地址,并绑定进vpn 实例中。然后vxlan和vlan网络就可以互访
现在租户的内网在vpn ins已通,要求上外网(用户的vm上互联网)
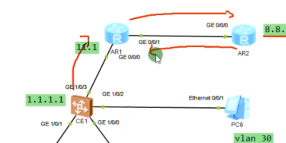
dc要存在一个对外的路由器出口,r1是dc的出口路由器,r2为外网的一台r。在这三台三层设备上分别配置默认路由指向nh设备,然后做nat来上外网。
真正的dc场景中,一般都是要经过防火墙出去的,lab里是在ce1上使用acl来匹配相应的流量访问互联网,其他流量不让访问互联网
在ce1 配置vpn ins下的默认路由,下一跳指向AR1互联的if(解决报文是在vpn ins中,但是没有公网8.8路由的问题)

不加关键字public,这条静态路由就无效。加public的意义就是,下一跳地址去public路由表里去查找,因为public路由表有对应的静态路由,就迭代出接口。
做了一个vpn路由的泄露,把缺省的报文都发送给public路由表的10.1.11.10。报文到达ar1,通过nat就出去了
Display nat session all查看nat的转换信息,如果有转换信息,就说明报文成功从r1泄露出去了
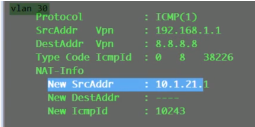
已成功泄露
在r1上需要配置静态路由,到达192.168.1.0网段,nh为ce1,但是此时还是不通,因为ce1接收到回的报文(dip已经经过nat为私网地址了),是查public路由表,因为匹配了默认路由,就又发送回给r1,就需要再将这条路由泄露回vpn ins路由表,dip配置源主机地址即可。同子网和跨子网互通,都是在vxlan隧道之间的概念,所以ce1就没有到达pc1的路由(跨网段就是直连路由,因为int vbd if已经属于vpn ins了,会自动去这个实例里去找路由条目)


在ce1的公网路由表中,就会存在出接口为vbd if的静态路由,然后r就会查vpn ins中的路由表
以上就是dc中的私网地址访问公网的思路
也可以在租户和租户之间的vrf中进行路由泄露
如何彻底做到租户间路由的隔离吗,还有租户内网路由是否冲突的。
真正的公有云和私有云里是有防火墙的,通过网关ce1将报文引到防火墙上(旁挂部署),在防火墙上通过虚墙来隔离,再绕回到公墙,所有租户的nat在防火墙做,这就不存在冲突了,且租户之间的报文也通过防火墙来互通。网关上在每个vpn ins上写缺省路由nh到防火墙
以上为数据中心各种解决方案
ssvpn:公有云里的外网用户要通过sslvpn连到dc中的vm,如何部署ssl网关
dc就是云计算场景下的硬件vxlan网络
------------------------------------------------------------
2023-05-09 8:40
Video 4
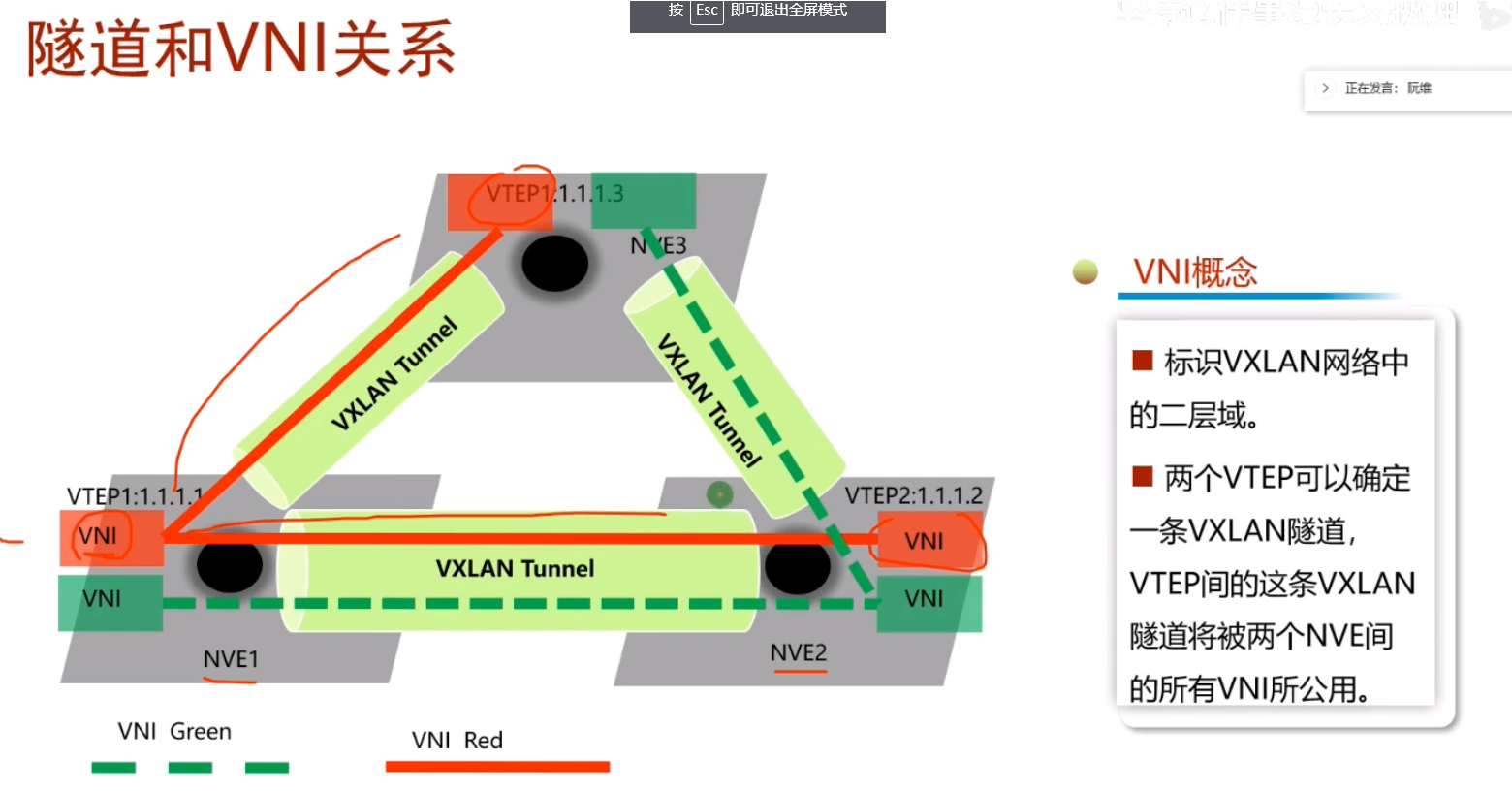
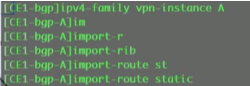
从以上lab 看vxlan隧道和vni的关系:vm在nve上接入,只要给vm分配相同的vni,在nve上就要针对相应的vni手动建立隧道就能通。上图有问题,看下面的图,文字看上面的
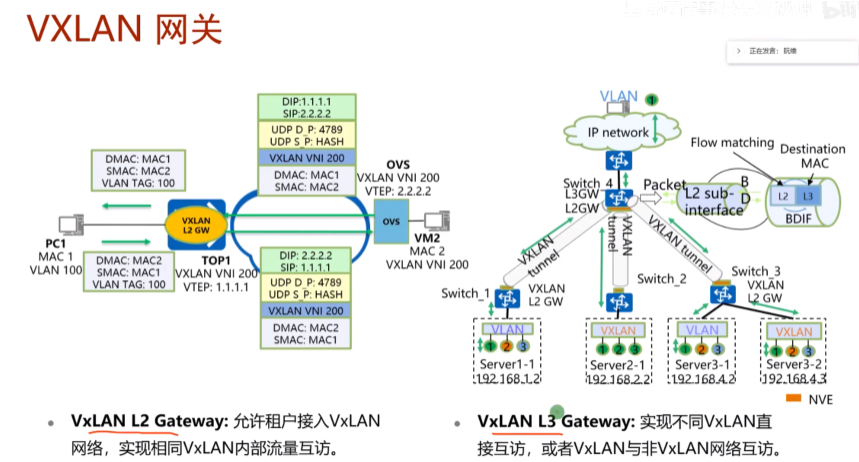
vxlan网关分为vxlan的二层和三层网关。对报文进行vxlan封装和解封装的设备称为vxlan的二层网关;vxlan的三层网关,就是实现传统意义上路由功能的网关了。视频3的lab中,sw4起到三层网关+二层网关的作用,而下面的4台sw,就是二层网关,起到vxlan的封装和解封装
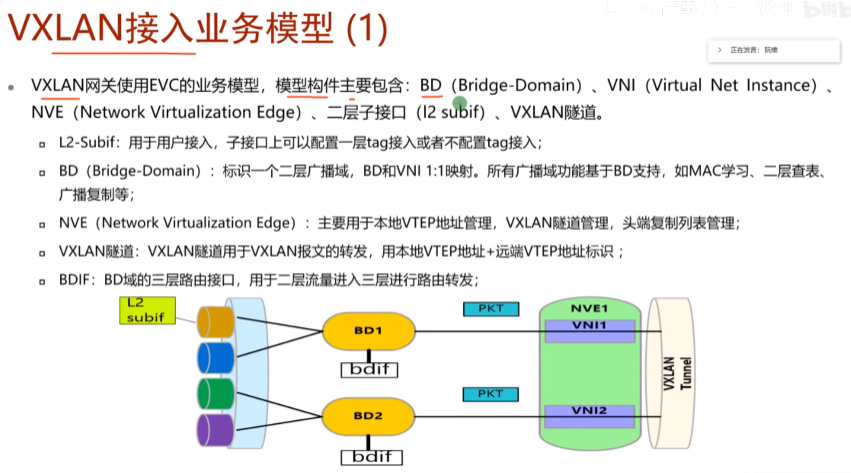
bd域:桥接域,sw本地有效的概念。vni才是真正标识主机在不在同一个大二层网络中。
vni一个大二层网络的标识符,其和bd域在一台sw上是1:1的关系
nve:执行vxlan报文封装和解封装的设备
vxlan的网络中间设备只需要支持ip转发,vxlan的封装和解封装是集中在边缘设备上完成的,三层网关同理,也同属于vxlan网络的边缘设备-因为流量要达到网关去别的子网,所以称为nve:网络虚拟化边缘设备
业务接入模型1,根据报文携带的tag和子接口的封装类型来决定报文属于哪个bd域
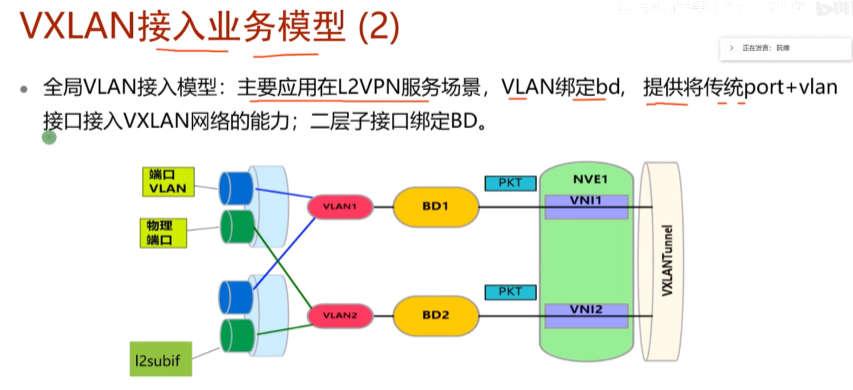
业务接入模型2-全局vlan接入,ex:vlan 2 binding bd 10,进行vxlan业务的接入。凡是属于vlan2的接口都可以绑定到bd域中,就不需要子接口来做,如下(ne40里不支持)

这台sw上所有加入到vlan10的物理接口都关联到bd域10,但是此条命令有以下限制条件:

不能配置vlanif-就不能充当网关,只能做业务接入。所以在dc的场景中,很少使用这种方法进行vxlan的业务接入,都是用的子接口的。
arp广播报文抑制,为了实现arp广播,vtep设备要进行头端复制,会把所有的arp广播复制到该vni所有端点的nve上(以单播形式发送),那在dc中arp报文通过vxlan隧道发送给所有端点,会对dc的设备性能产生影响,如下
Ce1要进行多次的vxlan封装,1个arp广播变成了3个单播的vxlan报文。dc场景中的vm有上万台,而arp也是常见的报文。那在dc里,这种为了支持arp泛洪的头端复制行为,会对dc的整体性能产生影响。成千上万台发送arp,导致nve进行大量arp报文的封装和头端复制,中间的设备也需要大量转发这些bum报文经头端复制产生的单播报文。优化方法如下:
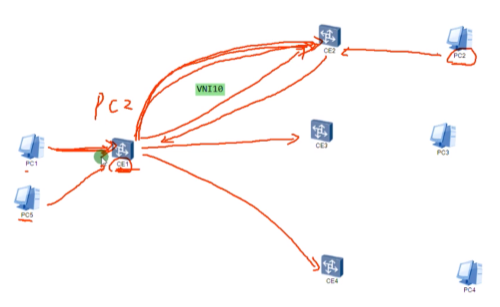
环境:新增一台pc5
Pc1已发送arp请求,获取到了pc2的mac-已记录到ce1中。此时pc5想要和pc2通信,也会发送arp请求,到达ce1,ce1已经知道了pc2的mac,ce1会将这个arp请求直接单播发给ce2(不在给ce3和4),就不再需要头端复制这种行为了,减少了arp报文复制的情况。此为arp广播抑制功能(在ce处直接将arp广播请求,转变为dip为目标nve的arp单播请求)。第一次解析的时候是需要头端复制的,后续不需要了。除非ce1上关于pc2的mac地址已经失效或者老化了。arp广播报文抑制功能,减轻了ce1进行arp广播报文头端复制的负担,同时减轻了整个dc中arp报文的数量。
此功能详见ce12800 vxlan中vxlan增强功能,arp广播抑制。本质是在ce将接收到的arp广播请求转换为arp单播请求直接发送给目标主机-属于nve的增强功能
1.通过vxlan网络将underlay网络变成超大的sw。
2.利用vni实现了广播域的隔离-让这台超大sw具备了vlan的能力
通过集中式网关部署vpn实例,又能实现vni之间的三层互访
这个就是网络虚拟化,而非网络功能虚拟化。
underlay网络只需要支持ip的转发,就能支持vxlan,从而构建overlay网络。
水平分割(防环机制):在nve1对bum报文进行的头端复制,发送给nve2,nve2会直接发给其下的主机,而不会发送给其他的nve节点。即从网络侧收到的vxlan报文只能发送给用户侧(这点说的不对,外层ip包的dip是确定的,nve接收到肯定不会再转发给其他nve了)。
Ip overlay ttl:最外层ip的防环
基于ip路由:指底层ip网络通过igp计算隧道间的最短路径
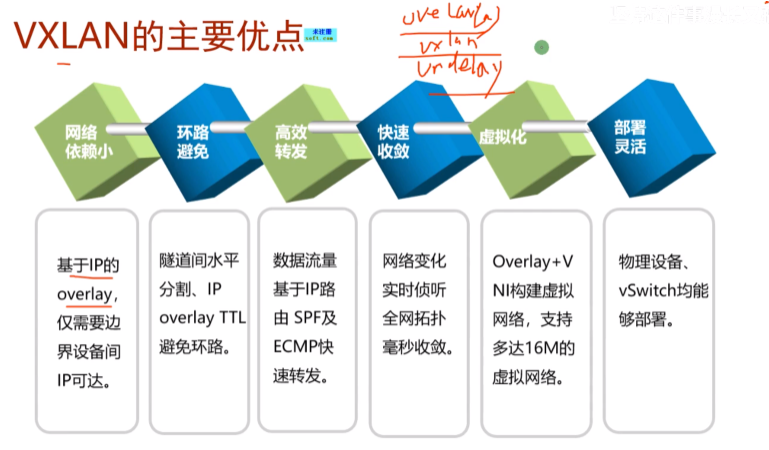
dc间的互联链路40G起步,server的网卡就是10G接入sw,这个sw之间是40g互联,百G骨干。如果还是用stp的话,就会阻塞40G的链路,利用资源率低,那就走三层,跑路由协议,不存在环路风险同时支持负载分担,充分利用带宽资源,即在dc中不需要用到stp。纯ip网络,支持等价负载分担,所以vxlan报文额外添加了udp端口信息,基于5元组来实现负载分担
如图:1.1到达2.2仅隧道,会走如上的两条路,vxlan报文上到接入sw后,会根据封装的5元组,通过这两条路进行负载分担且能冗余。
因此dc场景中就不需要stp,这是个纯ip的网络,实现基于ip的选路,基于流的负载分担。所以在dc里,首选用vxlan,原因在:vxlan可以和传统的ip网络很好融合,标准化的协议,所有厂商都支持。客户也可以利旧现有设备
第4条快速收敛:指隧道变了(端点的路由变了,能借助ip网络来进行隧道的收敛),ex 最佳路径失效,但还有备用路径,那只要ip路由协议收敛后,隧道就能恢复了。这个不是指vm热迁移,这个网络是感知不到的,需要云平台来感知。云平台在感知到vm迁移后在通过和控制器联动来实现全网的收敛。这里指的是隧道本身路由的收敛是依赖于ip网络的
6灵活部署:vxlan通过软硬件sw都能实现。open switch指linux下面的一个开源软件,安装之后你的pc上就像安装了一台软件sw。华为里称为ovs-open vswitch,升级称为evs-增强型虚拟sw
华为还开发ce1800v,软件sw。在现网部署一般是来接管vmvare云平台的-在其他厂商的服务器上安装华为ce1800v,产生虚拟sw,本质就是为了兼容其他云平台产品

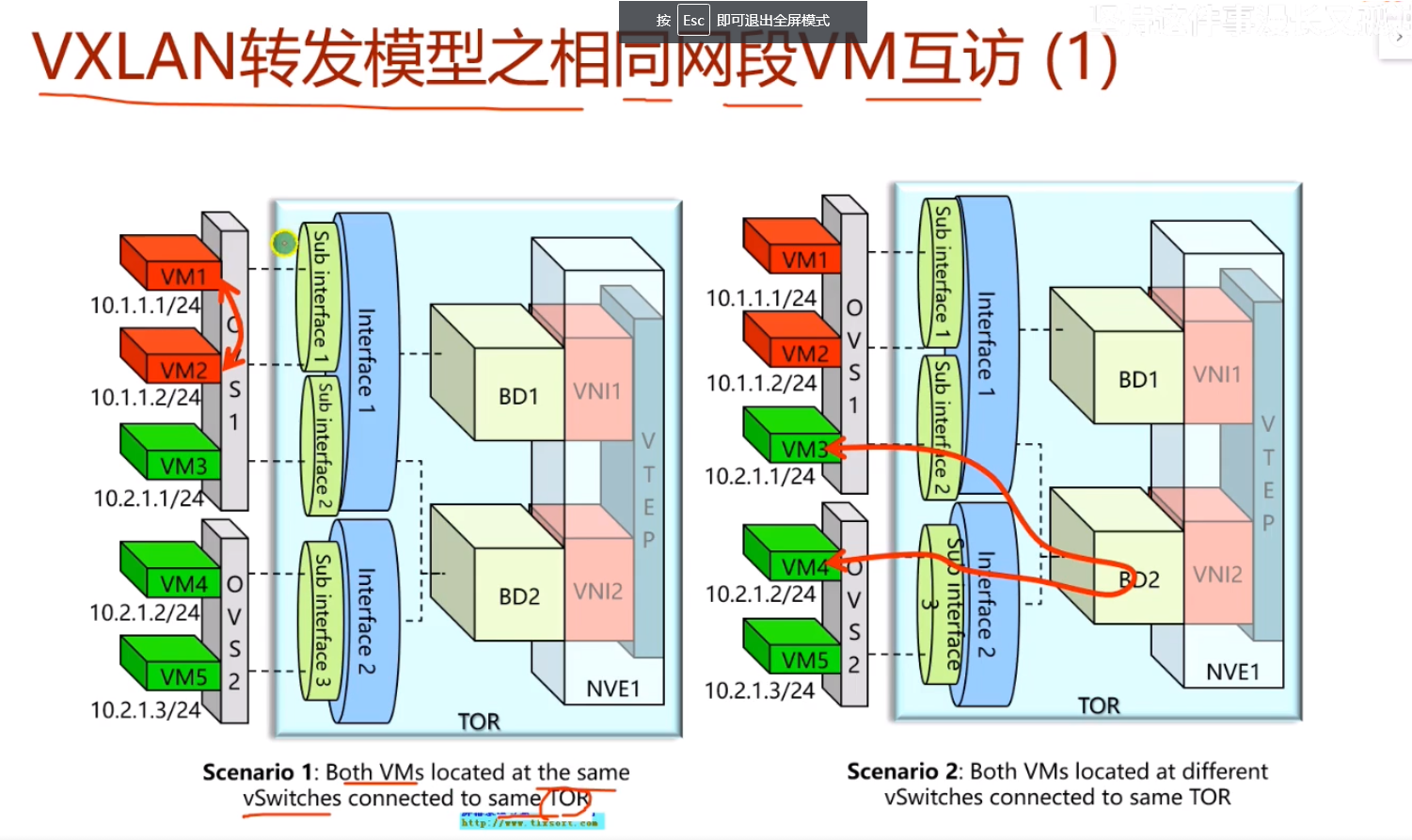
情况1.vm1和2之间的流量通过vsw直接转发,不需要vxlan的封装和解封装(vm连接到同一个vsw,并且这个vsw连接到同一个tor sw上)
情况2.两台vm在不同的vsw上,但是在同一个tor上,且属于相同的bd域,就能直接实现二层互访,也不需要vxlan的隧道封装。
两台vm在不同的ovs,ovs又接到不同的tor sw上,这就跟lab一样,需要建立vxlan隧道

总结:以上在dc的部署中,同一子网下vm有以上三种画圈接入的情况(上联同一个vsw),部署很灵活
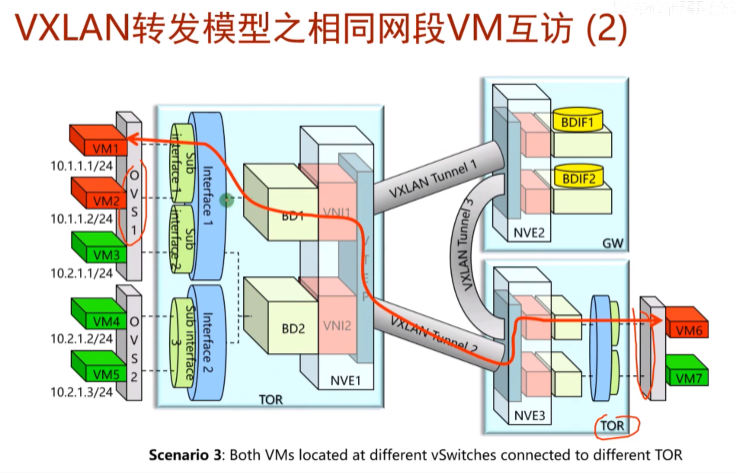
跨子网的互访在集中式网关的场景下的特点。
在vxlan网络中,所有vni要实现跨子网的互访,需要由网(右上的GW)关来实现路由。称为集中式网关
场景1.2台vm处于不同的网段,但接入了同一个ovs上,又连接到同一台tor 交换机上,此情况的跨子网互访,业务流量先通过vxlan隧道走到自己的网关设备,然后再由网关设备查路由在送到这台tor sw上,再由tor sw发给vsw,这就导致了流量的迂回-这是集中式网关的一个缺点-物理服务器发出去的流量又会收回来,网卡要处理这个报文两次,且途径的硬件网络设备也要对报文处理两次。所以引出分布式网关,但这个只是集中式网关相对分布式网关的缺点。传统vlan网络就存在流量迂回的问题,不同vlan间互通,都需要经过网关。以前不说迂回,是因为在基于vlan的路由机制下,只有这一种解决方案。但在vxlan网络中,就可以使用分布式网关进行解决。
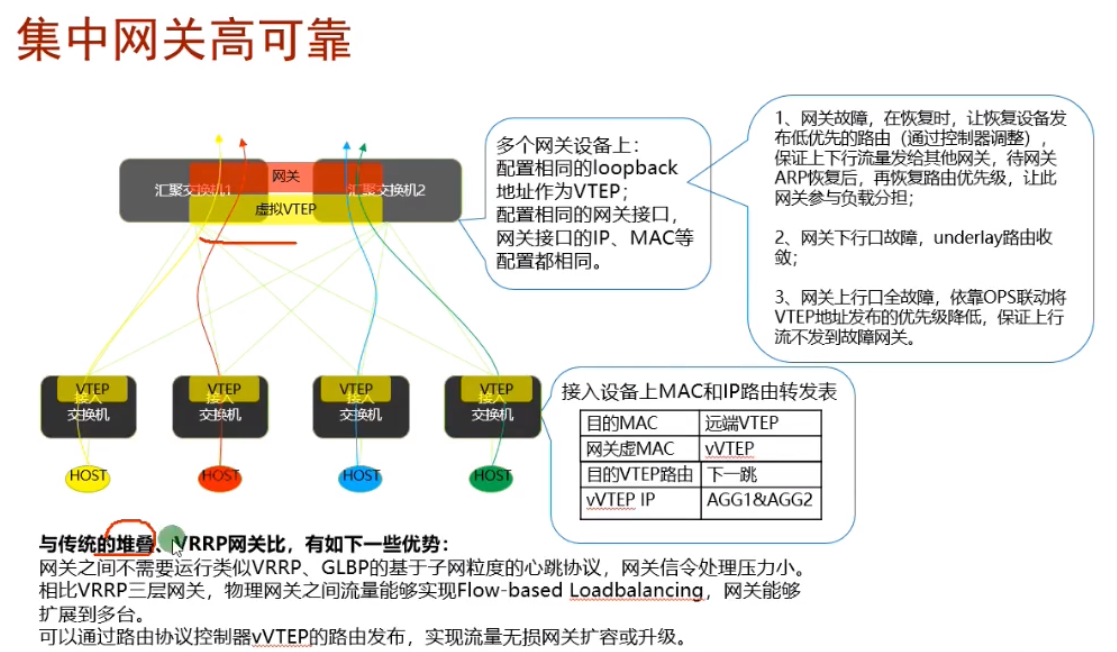
网关需要维护vm的arp信息,如果采用集中式网关,会造成这台设备的arp表项会非常多,造成网络的瓶颈;同时因为网关的内存有限,在维护arp、路由信息后,达到上限,无法扩容。涉及后面要讲的集中式网关的扩容问题
传统网络,因为资源是分散的,所以设备的容量,表项资源是足够的。但在云计算的场景中,因为资源是共享的,那对网关的表项资源来说就存在瓶颈,会制约业务的发展-这就是规划和设计方面的问题,集中式网关场景,如何保证网关容量瓶颈的问题和网关可靠性的问题。网关下移就是分布式网关。

两台vm不在同一个子网,也不在同一个ovs,但接入了同一台tor,流量还是会经过gw 迂回
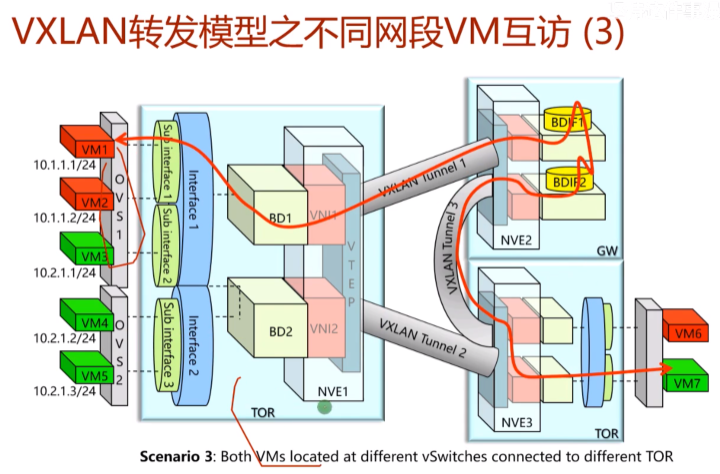
vm不在同一个ovs上,也不在同一个tor上,这种情况就要经过两次vxlan隧道
业务互访的情况,一共就上述6种-同子网、跨子网
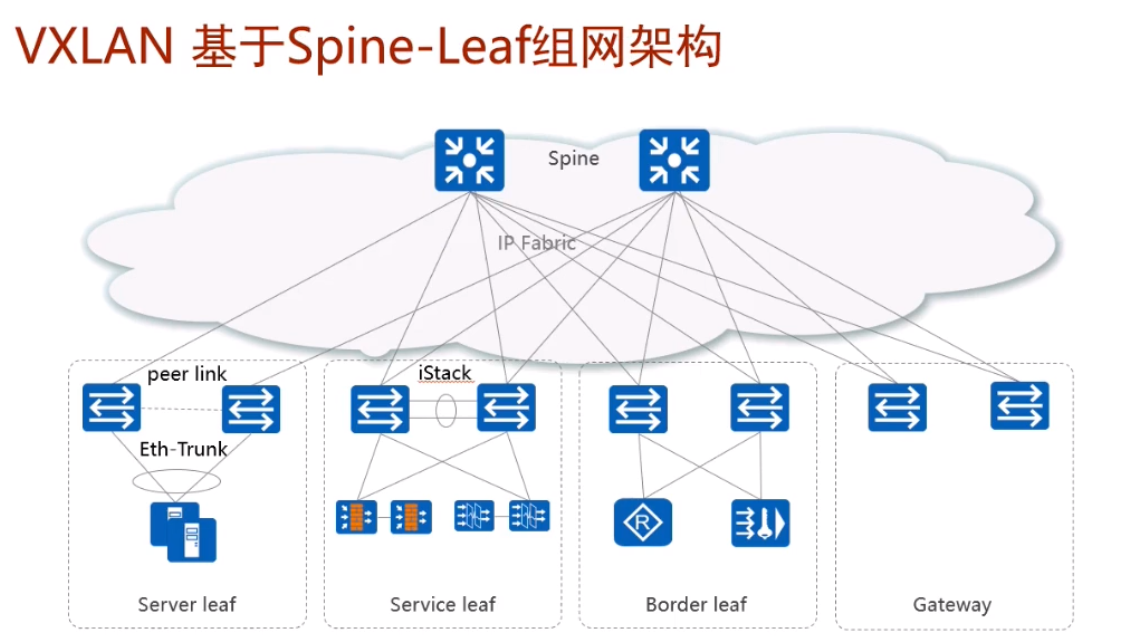
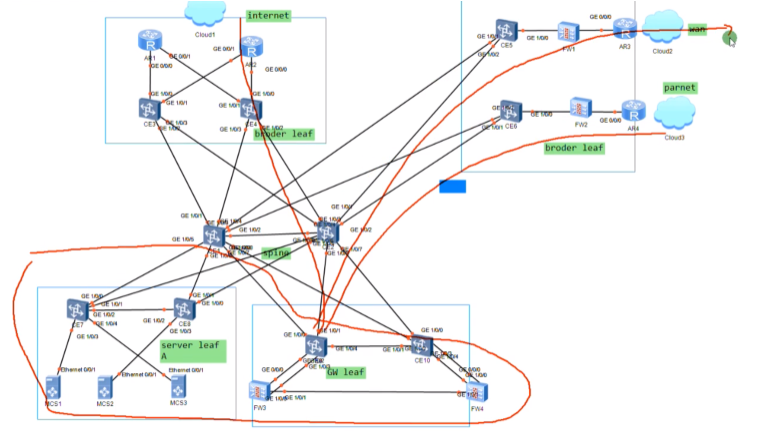
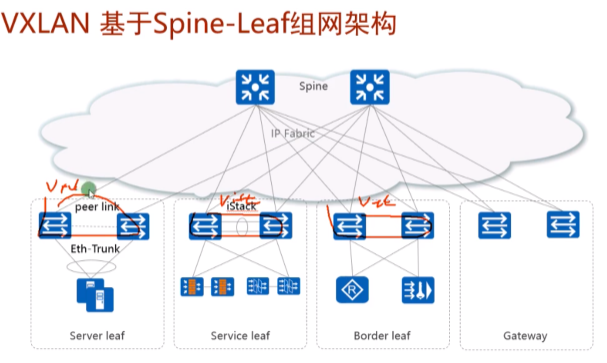
传统的dc和园区网都采用三层网络,接入+汇聚+核心。但当前dc中流行两层的spine+leaf的组网结构(胖树结构)。服务器接入流行的技术是m-lug,也可以在leaf 上做istack,在接入上做eth。但是堆叠系统的升级会引起业务的中断,用户有的不接受,而像m-lug部署,设备是分离的,一台设备在升级的时候,流量可以经过另一台设备走,对业务影响最小。
server leaf是用来部署服务器的。
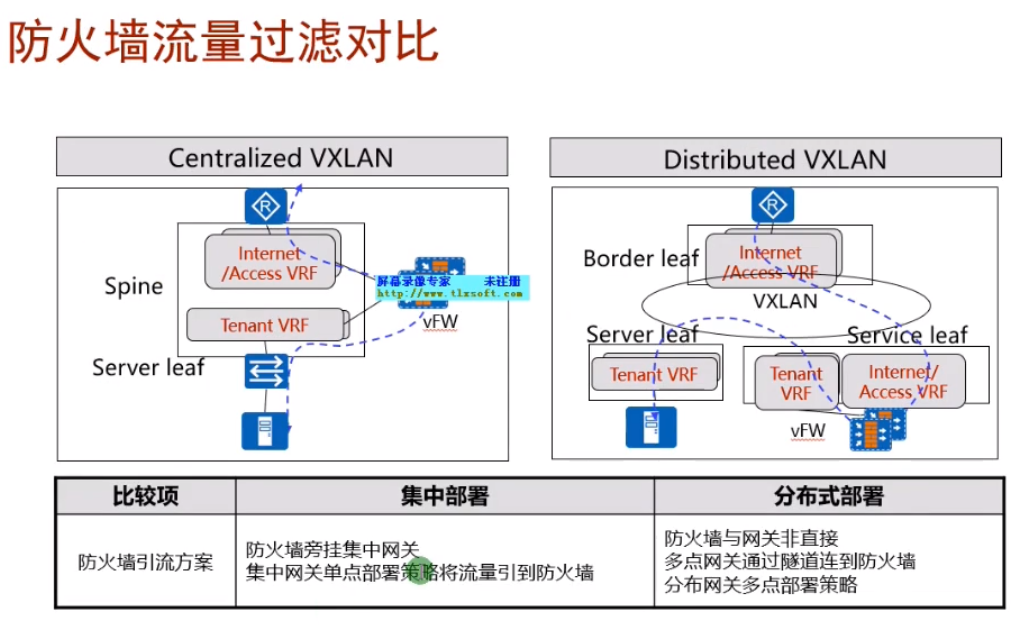
图2的sevice leaf是用来部署增值服务的网络(指istack的那两台sw),ex 防火墙、流量过滤这些安全增值服务的网络设备都可以通过这个service leaf接入到dc-可理解为高速的服务区
而border leaf一般用于连接广域网的设备接入到dc。而设计出来的两台sw。
本质就是把整个dc的功能进行了分区,连接合作伙伴、广域网、互联网都可以使用专门的border leaf来接入。
Gateway leaf:集中式网关,所有vm要实现路由功能就通过他来实现。
现网这个图里的spine不做网关,只进行流量的转发-和上面的lab不同
如果在部署一个防火墙border leaf,设计就复杂,流量经server leaf-gw经过路由后-防火墙做过滤-gw-border leaf(从防护墙出来就没再经过gw),全部使用vxlan隧道来实现。现在华为的解决方案中,基本都是直接在gateway旁边旁挂式部署防火墙,流量路径为service leaf-gw经过路由后-防火墙做过滤-gw-border leaf。在防火墙上做nat。
某些业务不需要经过防火墙,那就流量直接到达gw-border leaf(ex 租户只租服务器,不需要你的安全服务。而有的公司的安全性要求高,在公有云里希望云能提供防火墙服务,则流量到达网关,nh到防火墙)。
dc本质上就是将这些网络功能拆分,按照用户的需求卖给用户。
用service leaf除了可以旁挂防火墙,还能挂svn做ssl vpn的接入,还可以挂负载分担的LB,如下图
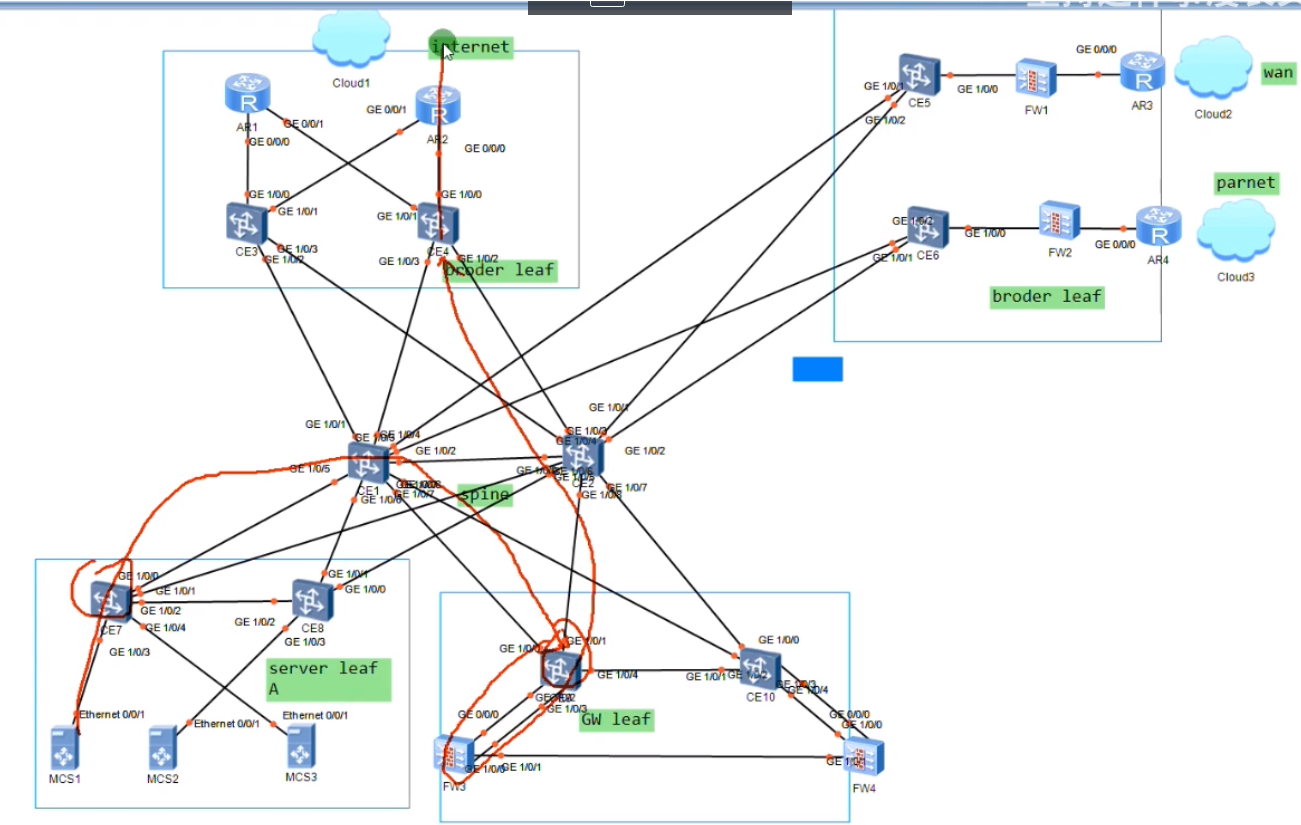
集中式网关分离部署,在大型的公有云/私有云的部署套路(最烧钱,牛逼的解决方案)
部署两台leaf sw,来实现和互联网出口路由器的互通
R3-连自己企业的广域网,r4连合作伙伴。实现了不同的border leaf承载不同的业务的流量,border leaf对外可部署防火墙
东风汽车的部署,就是一个合作伙伴,就是一个专线,一套防火墙,太浪费。
上图中的spine就是整个dc中核心的核心,spine只做报文转发。
业务区块就是各种各样的服务器了,server leaf(针对A业务)。传统的园区网和dc网络都是这种架构
vm的网关单独部署两台ce9和10,网关要求双活,不能只有1台,上图就把网关从spine里分离出来了。网关leaf。在项目中,通常采用在网关leaf上旁挂防火墙,做到service leaf也行,就是部署更复杂。两台防火墙之间要做双机热备,会话同步,要有心跳线。
上图红线为业务流量访问互联网的路线:server leaf-网关上走vxlan隧道,网关再绕道防火墙做过滤,做安全防护,在绕回给网关,再将报文交给border leaf访问互联网,全程vxlan隧道。
现在的问题是网关把流量送给防火墙,在从防火墙回来,在送到border leaf上,如何实现?看后面的视频
上图下面划圈为私有云,连线就是私有云如何连外网、合作伙伴、下属的分支机构.
这里网关做成单独的leaf,就是为了后期的扩容。网络规模过大,网关装不下过多vm的arp表项。如果将网关部署为单独的gw leaf,那直接就可以对gw leaf进行扩容
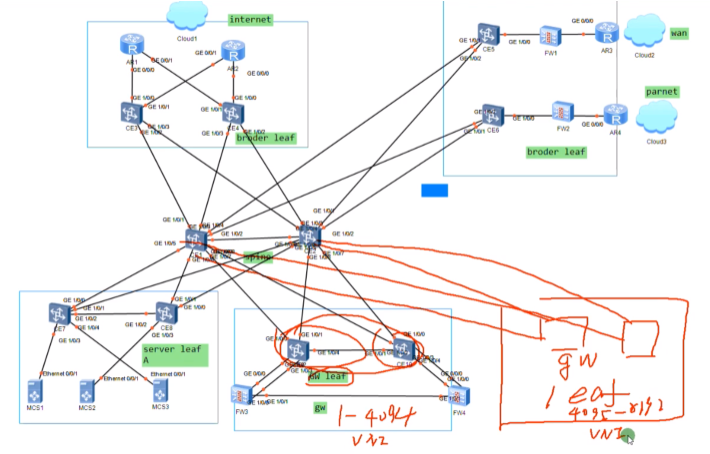
新旧gw leaf分别作为不同vni的网关,就不存在扩展性问题了。这种称为spine和gw的分离部署。同理border leaf也能通过这种方式进行扩展,随着业务的增加,可以按照分区的方式进行扩展。而如果spine的转发能力不够了,直接增加新的spine sw就可以了,因为在spine上不存在业务功能,也不是网关,只需要配置路由,通了就ok,核心层扩容就很方便。如果核心做网关,则是要承载网关的业务,此时那在扩展两台的话,这两台首先要配置网关功能,然后要把所有设备都接入上去,工程量太大
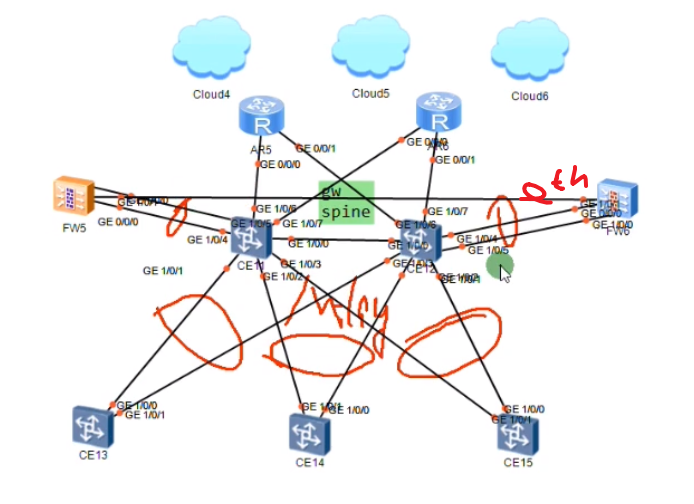
小型私有云架构,网关和spine的融合部署(融合的小型私有云/小业务公有云)
防火墙旁挂在GW上,互联用一根线两根线都行,看使用的技术。防火墙做双机热备,镜像模式-会同步状态,会话表项,所以数据从哪边的墙出去都可以。在下面服务器接入的时候也是m-lug,全网都是m-lug组网,不需要用到stp
通过外联路由器接入到各种广域网
防火墙部署在出口上,容易出现单点故障。旁挂式的话,墙挂了,流量还能走
练习从业务的(用户需求)角度来谈项目,而非站在技术的角度。
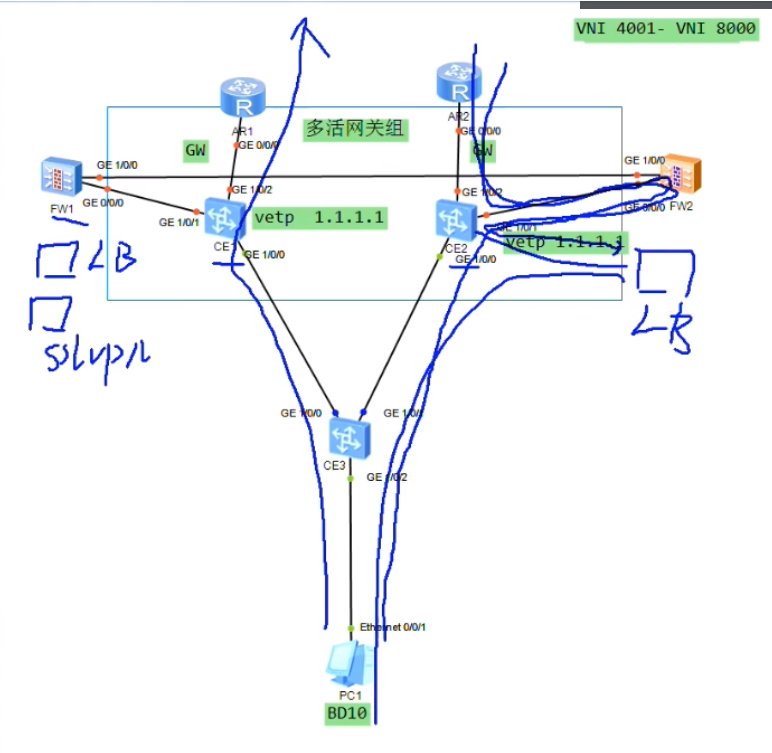
网关冗余-lab中只有一个网关,挂了,就全挂了
华为的解决方案中有一个种vxlan集中式网关双活技术
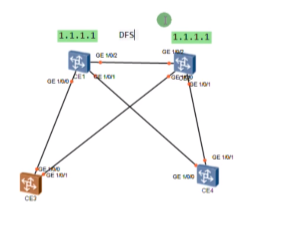
双活-能够同时帮助你转发业务流量。两台网关配置相同的vtep地址,那3.3就能和1.1建立等价的两条隧道,报文就根据负载分担算法送到相应的网关,网关解封装在查路由出去。一个网关挂了,路由收敛,所有的报文都可以经过另一个网关出去,提高了可靠性。但假如存在pc1和pc2,pc1走ce1,只有ce1能学到pc1的arp缓存,而另一个网关ce2是学习不到的。如果回包经过ce2,因这个网关没有pc1的mac
为了避免来回报文路径不一致,导致网关无法正常转发报文。需要在双活网关上部署华为的私有协议dfs((Dynamic Fabric Service Group)动态交换服务组)-用来实现两个网关的arp表项同步和mac地址表项的同步。从一个网关学到的arp缓存会通过dfs group同步到另一个网关上。所以不管流量怎么走,在双活网关上的arp表项都是齐全的-该技术模拟器不支持,但是双活模拟器可以做出来。
这个双活网关组能力不够了,可以扩一组。华为设备支持4台设备做成多活网关组,提高了转发性能,负载分担的能力,但是因为四台的表项是同步的,表项不会扩大。
模拟器是基于包的负载分担,而不是基于流的,所以双活的效果就做出来了。Ce3向1.1的1包就走ce1,2包就走ce2。导致两台spine就都学到了下面pc的mac,做出了dfs的效果。但真机是基于流的,pc1发出的某流,只会经过一个网关,另一个网关收不到,就需要使用dfs来同步mac+arp缓存
为每一个租户分配一个虚墙
网关双活,直接使用dfs技术,不需要在用堆叠和vrrp
-----------------------------------------------------------------------------
2023-05-10 11:04
Video5
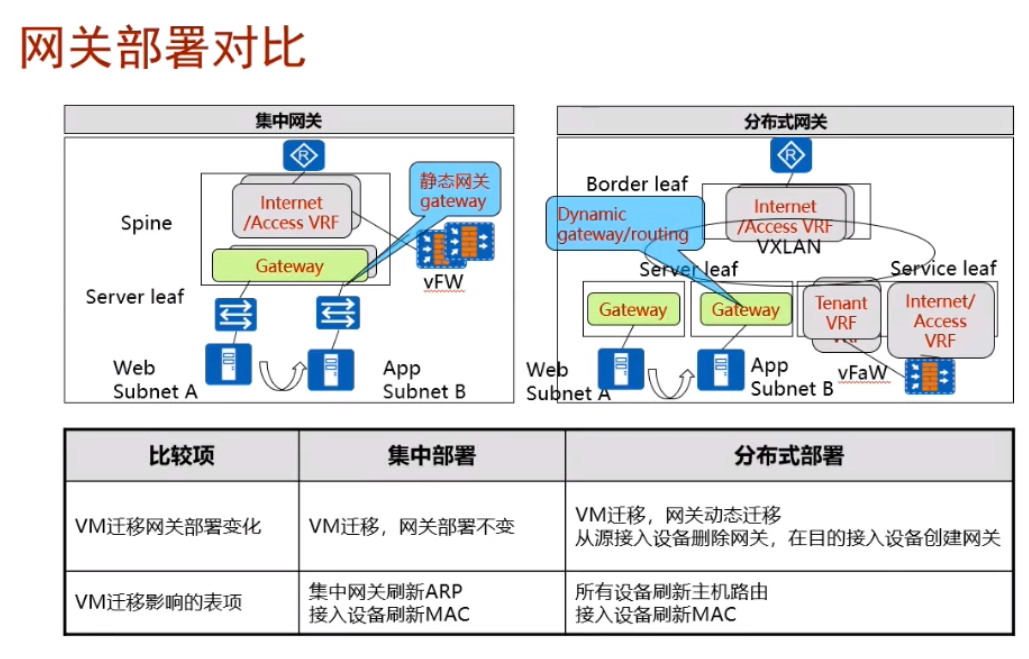
集中式网关的问题:1.流量存在迂回问题;2.网关需要维护主机的mac和arp,对设备的表项容量要求高,容易遇到瓶颈;3.gw存在单点故障。集中式网关的特点:跨子网的流量由网关来完成,流量有明显的控制点。
gw维护用户路由+arp+mac+vxlan隧道路由信息。-同子网互访不需要经过gw,直接在两台leaf上走vxlan隧道(因为leaf间,leaf-spine间都建立了vxlan隧道)。Leaf 只需要维护vxlan隧道地址的路由信息和mac地址信息-用户vm的网段的路由信息是在leaf上的,而无需维护用户之间的路由信息。
集中式网关的解决方案:

融合/分离组网,指的是gw和spine
例:Gw1只担任vni1-50的网关,gw2担任vni51-100的网关。这就称为多组网关。多活网关,不是简单的主备,而是同时能转发vxlan业务。
做后面的实验需要下两个12800的镜像

510不要用-会丢配置。要下500这个的ce6800镜像(可以用来做集中式网关,双活,但这个对evpn协议支持的不好)。做evpn和分布式网关就用最新版的spc100的镜像中ce.zip
500的解压缩后的名字是svrpbox.img,最新版解压出来叫ce.img.
老版本镜像导入-使用管理员权限打开virtual box,将ce删除。然后在ensp中,添加启动设备,导入镜像。 Virtual box版本为5.2.26
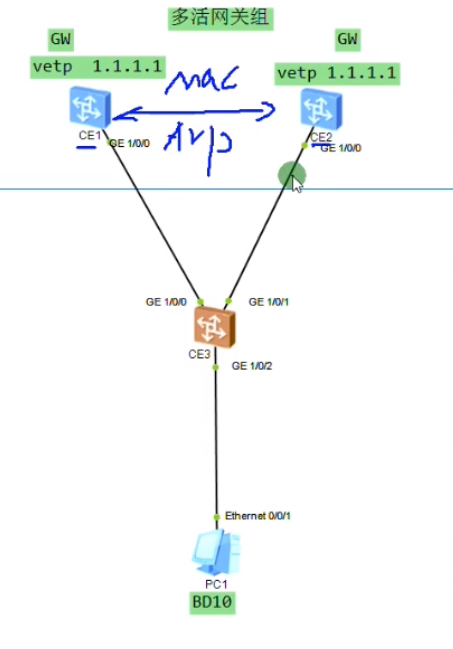
Lab 集中式网关的多活部署,关键在于vtep设置为同一个地址
因pc上来的数据包没有tag,ce3 的下联口直接用untag类型,先配置underlay网络
华为华东地区的项目很多都是用的vxlan和evpn,sdn项目
R3就是ce3,其到达1.1.1.1会存在两条等价的路径。在r3的g1/0/2.10 mode l2下选择封装类型untag。配置vxlan时,peer选择1.1.1.1,此时底层igp到达1.1.1.1的路由是等价的,根据r的负载分担算法(check 现网是基于流进行负载分担,那不会只走一边么?),报文会从左和右走,上面的两个网关都能收到报文,在根据自己的路由将报文发送到外网。
双活:依赖于底层igp的负载分担特性。而vxlan报文有udp封装,根据5元组来进行负载分担,上面两台网关都能收到业务报文,网关在根据自己的路由发送出去。
只需要在两个网关间保证mac和arp的同步(避免来回路径不一致,导致另一个网关上没有相应的表项,导致另一个网关向vm发送arp解析,增加网关的压力),双活网关不需要保证会话的同步(就是不需要保持两端gw和其他设备的会话状态)。但是需要在两个网关间配置dfs协议来实现mac地址和arp表项的同步。配置m-lag时也会用到dfs-group协议来进行双归设备的接口状态、表项等同步。
模拟器不支持dfs
在两个网关上配置vpn ins,配置vbd if接口binding进vpn ins中,以租户的形式配置双活
两个网关的vbd if(网关)ip和mac地址都要配置成相同的
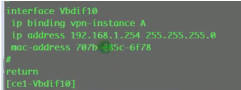
vxlan隧道的验证命令

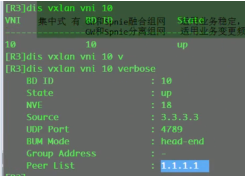
现网是基于流量进行负载分担的,双活网关是通过dfs来进行arp和mac表项同步的。而这个lab是因为模拟器是根据数据包进行负载分担的 。
华为设备目前最多能把4台设备组成一个多活网关组。后续扩容:1.表项的扩容-新增加多活网关组,这种称为多活多组网关组;2带宽的扩容-将多活网关组中增加到4台设备。
通过以上方法,解决了集中式网关的可靠性问题,容量扩展性问题。so在大型私有云和公有云的场景中,也可以部署集中式网关。其优点:流量有明确的控制点,都会通过网关来进行路由,流量的管控更方便。
双活网关做通后,流量如何经过防火墙?
项目中常常这样做,两个网关连防火墙,防火墙之间做会话同步-墙之间的连线就是干这个用的。本质就是防火墙做双机热备,旁挂到两台网关上,提供增值服务。有的用户购买了防火墙,就让其流量经过墙,而有的用户没有购买,可以通过路由让其流量直接出去。
集中式网关的时候,LB、sslvpn都可以使用防火墙这种旁挂式部署。
Ex 购买lb服务,流量经过防火墙之后,扔到lb,再由lb扔到下面的主机(lb是针对进来到云平台的流量说的,负载到内部不同的server上)
因为配置量太大,就需要sdb来做,在sdn上将业务下发后,sdn自动全局将配置下发到每一台设备上。
流量如何绕到防火墙
项目实现:一般防火墙和sw之间连接两条线,配置为eth,trunk,每一个租户通过vlanif和防火墙的vlanif做三层互联。防火墙为每一个租户配置一个虚墙,vlan if绑定到虚墙上。再做一个vlanif和根墙做绑定,通过根墙走出来,再到ce1-ar1,绕到ce1的public路由表上。网关不能在防火墙上,只能配置在ce1上。如果网关在防火墙,那后期的扩容就是扩防火墙,并且有的用户是不需要防火墙业务的,这种方案可以实现,但不建议这样做,最好还是按功能分开。
逻辑简化图如上。把流量引到到防火墙?在gw上写路由指到fw就ok了
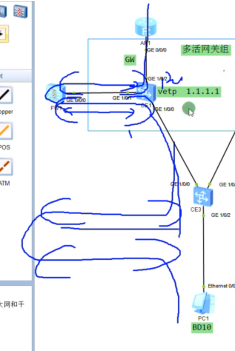
流量经过fw,如何绕到外网去?
在ce1上是有vpn ins的,就可以认为其是一个租户。同样需要在fw上创建一个虚墙,为该租户提供虚拟的安全防护。用户的流量是先到达自己的虚墙,再走到内部的根墙,再绕出来。
网关设备是有public路由表+租户的vpn ins路由表的。根墙和网关的public路由表对接,而两台设备的vpn 实例对接-就类似跨域的option A。
流量上来到达网关,通过vpn实例绕到虚墙后,虚墙再把流量交给根墙,再绕到网关的public路由表。本质就是在gw-防火墙上都存在两个vpn实例,流量从一个vpn实例再绕到另一个vpn实例。
组网规划如下

![]()
方案有多种,可以用一条线将租户的流量引到防火墙,再用另外一条线把流量引到public上。拓扑中是共享一条物理链路。
项目中通常是fw和sw之间做eth,并配置为trunk
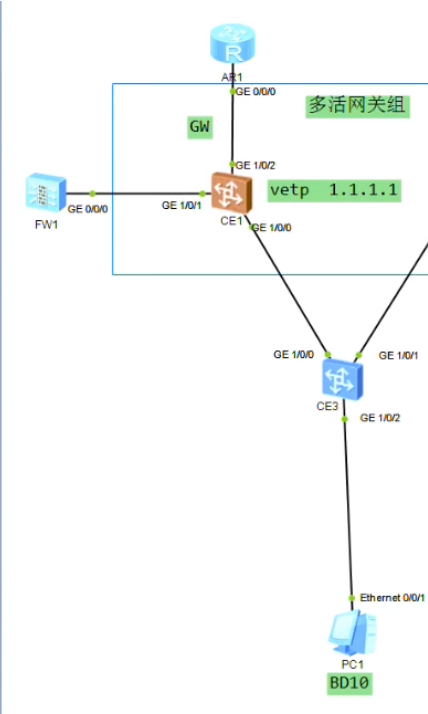
lab只是使用了一条物理链路来演示。防火墙默认的用户名admin,密码Admin@123
防火墙的配置,需要将接口配置为二层接口portswitch
Vsys enable//开启fw的虚拟防火墙功能
Vsys name A //创建虚墙A
Assign vlan 10 //将vlan 10关联到虚墙A上
配置int vlanif10 的ip add
这样vlanif 10就属于虚墙A,虚墙A就有了一个逻辑的接口。
一般用户的内网划分到fw的trust区域-安全区域
Switch vsys A //切换到虚墙A
System

每一个创建的虚墙也会有4个安全区域
将vlanif 10加入到这个虚墙的trust区域
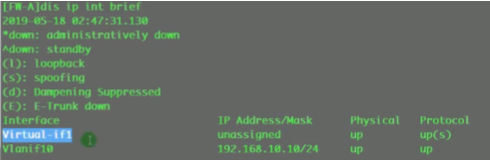
查看虚墙上有哪些接口,上图的虚拟接口。华为的ngfw默认出厂存在一个virtual if 0-属于根墙的逻辑接口。
退到根墙,也存在virtual if 0-就是同一个口,虚墙和根墙是通过virtual 接口进行互联的。
如何看虚拟接口属于哪个虚墙?进入到虚墙,通过dis ip int b,看自己有哪个virtual if接口,哪个虚拟接口就属于自己。两个虚拟接口之间存在的逻辑关系
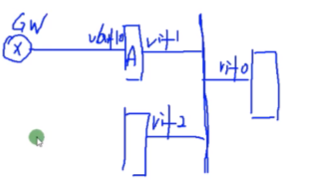
想:在虚拟防火墙内部有一台sw,左侧的虚拟防火墙和根墙都通过虚拟接口-sw上 ,从而实现互联。不用设地址也能通。A墙的vlan if 10是和网关互联的,网关向下连着vm。
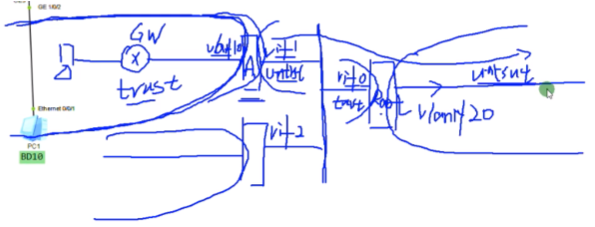
上图最左侧就是trust区域,虚墙连到用户的区域。将虚墙的vlanif接口放到untrust区域。这样就在dc中实现了租户网络,内网和外网的隔离。
在dc中,用户的虚拟网络,如果是跨墙走的,终止于防火墙 (在逻辑上看,虚墙就是租户连接外网最边缘的设备)。同理,有其他的租户,就在下面构建虚墙B,类似。
上图最左侧为vm。根墙是被所有租户共享的。流量可以通过根墙的某一个物理接口或者vlan if接口流出去。所以要按上图将虚墙和根墙的对应接口划分到不同的区域。
流量真正要访问外网需要经过两堵墙。未来左侧两个区域A和B虚墙的虚拟接口,也可以实现租户之间的跨墙互访,即dc中的租户之间也可以通过虚墙来实现互访-在防火墙放行策略就ok了。
以下以数据中心华为项目的解决方案为例
Switch vsys A
Firewall zone untrust
Add int virtual-if 1
Vlan if10到A墙的trust区域,虚拟接口就在untrust区域
防火墙的接口默认是禁ping的

在对应vlanif接口下开启ping 测试
至此租户的vlanif10和租户虚墙的vlan if10已三层互通
在根墙上将virtual if 10放到trust区域,将vlanif20放到根墙的untrust区域
对应的逻辑拓扑 ,左侧的方格为虚墙,右侧为根墙。
Ce1(gw)和fw的两条互联链路已通的前提下,如何将到达ce1 的流量引到到fw?
在ce1的租户A的vpn实例中创建默认路由,nh为虚墙
虚墙在写一条回到内网的路由。此时在pc1就可以ping通fw1的虚墙了,这就是dc的套路(vpn路由的泄露),后期使用控制器下发配置,其本质也是一样的,命令都是一样的,只不过是控制器自动下发。
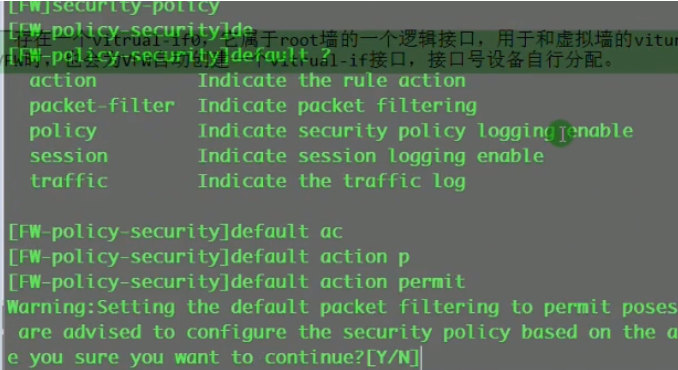
fw,如何把虚墙的流量放出去?在虚墙上写安全策略,流量从虚墙的trust区域发送到untrust区域,匹配流量,然后放行。

首先需要在虚墙上放行租户的内网地址(可根据需要精确放行), 然后在虚墙上写一条缺省路由,nh为public。check,没有调用?
![]()
其意义为,所有找不到路由的报文都扔给根墙,就实现了跨墙的转发。
so在虚墙的路由表中,就可以看到这条缺省路由的出接口是根墙的虚拟接口。192.168.1.0的路由,是为了后面向pc1回包的回程路由。
根墙在项目中通常这样配置
租户只需要管理自己的虚墙,无法管理根墙。在项目中,会把根墙的安全策略配置为全部放行,当路由器来使用。如果在根墙上再做配置,会增加防火墙的负担。
根墙上需要写一条缺省路由,nh为public
so在dc的场景中,虚墙是控制安全的关键,根墙就当做R,把双向的默认策略都放行
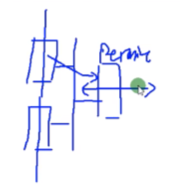
左侧是虚墙,中间是虚拟的sw,右侧为根墙
内网用户访问外网需要做nat-在用户的虚墙上做
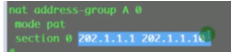
(这步不需要,删了)配置租户A所申请到的公网地址,在根墙上先做地址池资源。模式是端口模式-因内网用户要共享上网。下一步将这个地址池分配给虚墙A
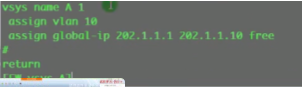
Vsys name A//进入虚墙A
上述网段是分配给虚墙A的。然后在虚墙下创建地址池A
Switch vsys A
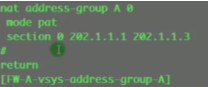
把这段地址做成地址池,即后续内网用户经过防火墙虚墙出去时,地址都会变成202网段。
在虚墙上做nat 的policy
是从trust到untrust区域的流量,匹配源地址,执行规定的动作
根墙收到的地址应该就是202开头的,外网回包要会给202,那根墙怎么把202的回包发给-在根墙上写一条回到202的静态路由,让其回到虚拟接口1-和虚墙对接。

在防火墙上查看会话表项。在虚墙A上1.1的报文被转化为202的源地址去访问8.8.8.8(R1)的外网,这个报文在经过根桥时,源地址已经变为了202。
R1为外网,要配置到达202的静态路由。在现网中可以将202.1.1.0/24这个公网网段分配给阿里云,阿里云又将这段地址经过npat分配给各个租户-这就是公有云和私有云的玩法。所以sp上就把这一段分配给阿里云的公网地址的路由,全指到你的边界路由器ce1上。Ce1既做了网关又做了网络的出口设备。在ce1上配置静态路由,将指向202的nh指定到虚墙上。dc内部就可以使用私网地址。
用户在私有云的网络中如何和外部通信,通过网关来实现数据中心内部的通信,通过vxlan实现同一个网段的通信。
内网的服务器,在内网的虚墙上做nat server-就是由虚墙来进行nat。
sdn就是各种静态路由指向外网。
在dc的场景中,是把传统的技术高度融合到一起来解决问题,sdn仅是多了一款软件-配置不需要手动去敲了。
华为/华三的sdn,cisco的aci都是通过sdb去下发配置,不是传统意义上的转控分离。
右侧再加一套防火墙的话,地址池要配置一样。华为的解决方案中,防火墙双机热备做成镜像模式-两台实际为1台,nat会话,配置等都需要同步。真正的项目ce1和ce2与fw配置的是m-lag。
在项目中,防火墙通常如上旁挂式接入。hrp来同步心跳。lab里是按照逻辑拓扑做成了1条线。
fw上每创建一个虚墙,自动会创建一个同名的vpn ins。
以上为集中式网关出墙的场景
----------------------------------------------------------------
2023-05-11 11:17
Video6
以分布式vlxan网关来讲一下evpn
静态vxlan是没有控制平面的,ptp做没有问题,但是当vm迁移后,就需要进行原有隧道的拆除和新隧道的建立,但静态vxlan本身是不具备这种能力的,这就不利于维护。
为了让vxlan隧道能够有动态建立、维护、和拆除的能力,就引入evpn协议作为vxlan的控制平面

type2只是携带的网络参数不同,所以细分成arp和irb类型的路由。Type 3路由,虽然叫集成组播路由,但和组播没有任何关系。
rfc也定义了类型1(ad-auto discovery)和4的evpn路由,只不过华为dc解决方案没用到。在广域网双规接入场景中,使用evpn协议的话,才会用到协议type1和4。
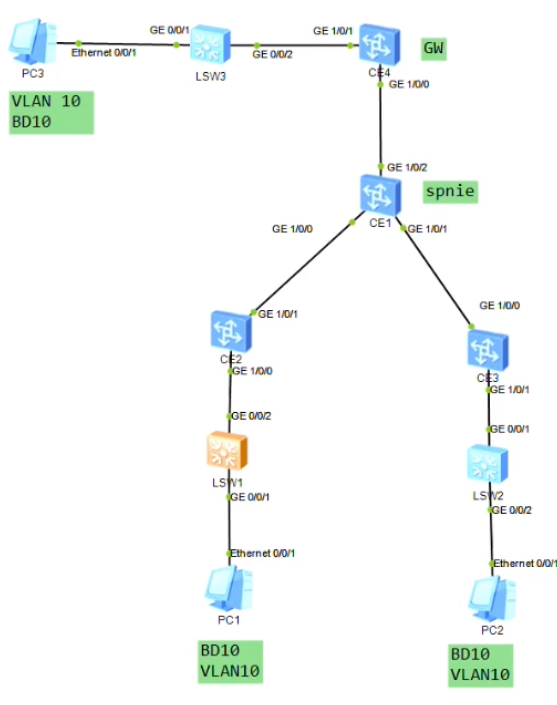
先做下面的lab,再回来看上面的理论。做evpn的lab记得换12800的镜像文件
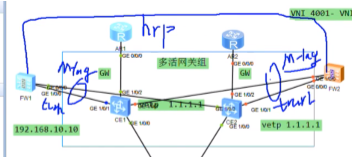
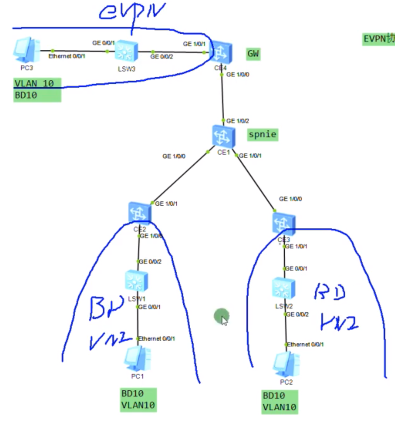
Ce1-spine,ce2-service leaf1,ce3-service leaf2,ce4-border leaf
先看一下头端复制列表-二层vxlan隧道怎么维护
在ce2-ce3之间建立vxlan的隧道,将ce1配置为evpn的rr,其他的ce都作为client。
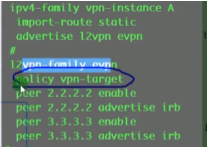
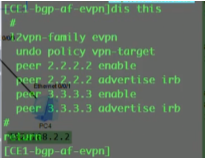
evpn的配置:
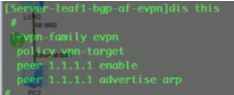
首先全局启用evpn overlay功能:evpn-overlay enable//ne40 在全局下无此命令

然后在里l2vpn evpn地址簇下,激活这些peer,并配置为客户机,如下:

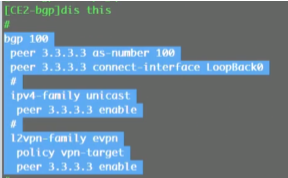
在三台leaf sw上配置和ce1的l2vpn evpn peer关系,如下模板
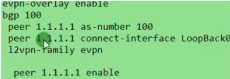
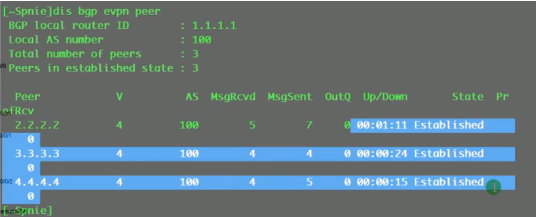
Evpn peer已建立完毕
evpn如何自动在ce2和ce3之间动态建立vxlan隧道?只要有相同bd域的leaf之间针对这个vni10,就会自动的在各nve节点将隧道建立起来。
配置bd域业务的接入
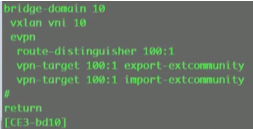
+创建bd10
用evpn来进行vxlan隧道建立时,还需要创建evpn instance
evpn协议中,本地的每个bd域,都可以看成是一个独立的evpn实例,一个2层的广播域
如上图,都有自己的bd域,vni10。上图三个bd域都可以理解为一个独立的evpn实例,未来就是把这三个bd域在二层上做通,能够二层互访。
相比vpn ins是三层独立的路由实例,用来维护路由信息的实例。而evpn实例可以看成是一个二层的实例,用来实现同子网互访,所以每个bd域都要绑定一个evpn实例 ,操作如下:在这个bd域下的,evpn里配置
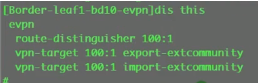
Ce2上这样配置

再配置evpn实例:b d10,vxlan vni10。Ce3类似
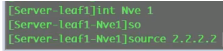

source就是设置本端的vtep地址
peer list 里的这两个地址就是头端复制列表,后续的bum报文,就会交给他们。现在用evpn的时候,ce2上就配置为+protocol bgp
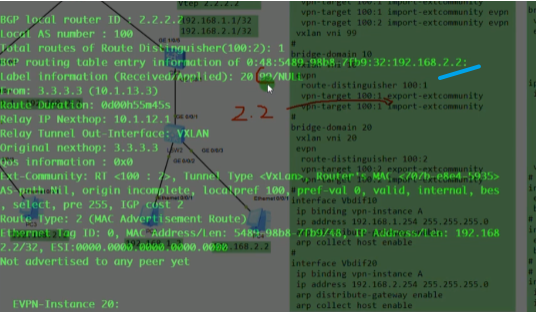
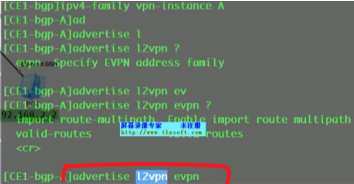
Vni 10 (20)head-end peer-list protocol bgp //vni 10的 隧道就交给evpn协议去做,相比在传统网络中,让bgp发布路由就是network,而在evpn里,这条命令就是让其针对vni10发送一条类型3的路由(配置了几个vni protocol(如vni10,vni20),就会发布几条类型3的路由,就和network几次一样)
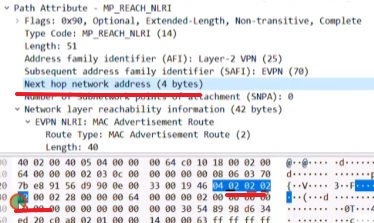
执行上述命令后,ce2会针对bd域10(仅本地有意义么?对,peer在检查的时候实际看的是bd域下绑定的vni)发送一条类型3 的集成组播路由

可以看Ce16800手册,evpn vxlan配置
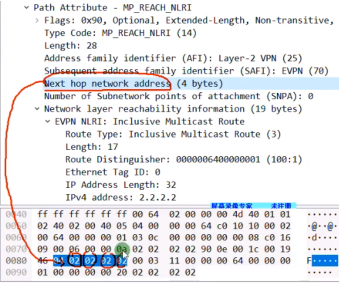
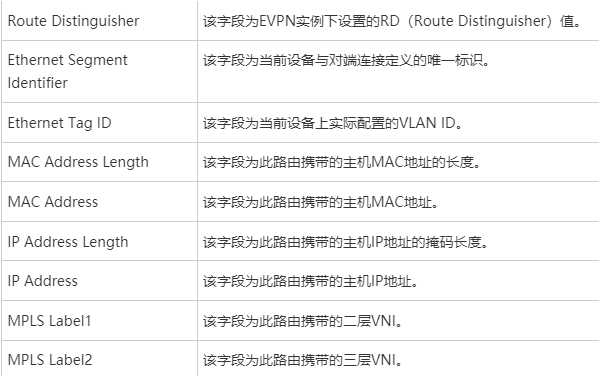
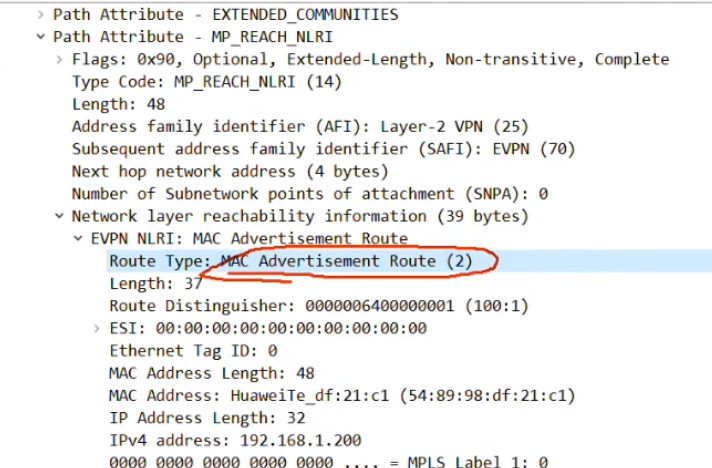
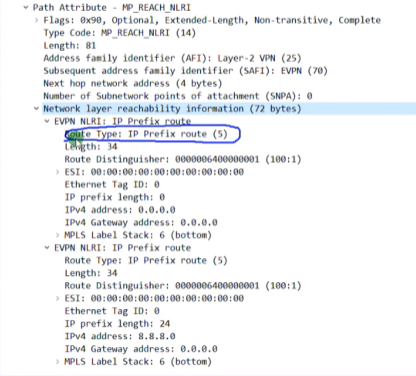
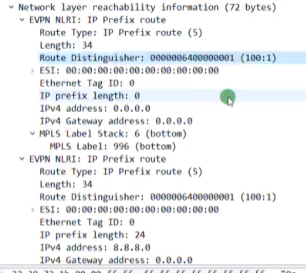
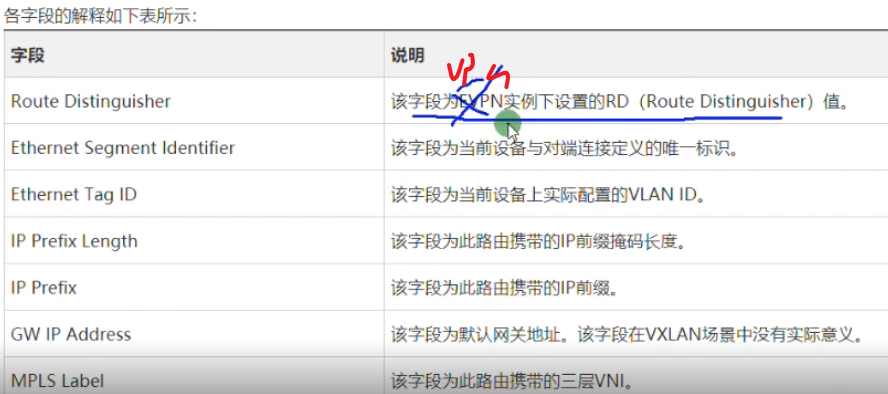
Type3的集成组播路由=前缀+pmsi属性(Premium Messaging Services Interface多播服务接口)
rd:就是刚才配置的evpn的rd。
Ethernet tag id:在vxlan的业务场景下,这个值始终=0,没有意义
Ip add length:描述的是代表ip地址的长度。1个字节是255,然后ipv4是32b,ipv6是128b,都能容纳。
Originaling router’s ip add:代表vtep的ip(看你配置的是ipv4还是v6的)
主要关心1和4
pmsi属性

flags:在vxlan的场景中,该字段没有意义。
type:目前在vxlan场景中,支持的type只有6:ingress replication,即头端复制,用于bum报文的转发。
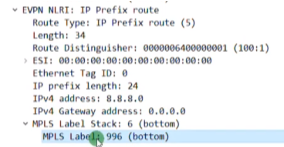
Mpls label:就是bd域的二层vni,lab中配置的是vni 10(这个不是mpls 标签啊)
总结:类型3路由只需要关注 rd+vtep(在前缀中携带)+6(头端复制)+vni+vtep(这个跟前面的是一样的,只不过是在pmsi中携带)
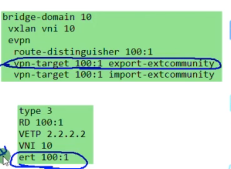
执行protocol bgp后,通告的bgp报文中还会携带evpn实例的ert(evpn rt)信息-放到扩展团体属性,不是在类型3的路由里(类似vpnv4路由)。Ce2会将这些发送给自己的evpn peer:rr
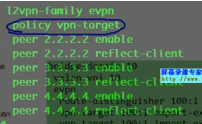
rr上因为没有evpn实例,vpn-target就会让rr将类型3的evpn路由丢弃。So 需要undo policy target。rr需要将该路由反射给其他的client。
Ce3收到这条类型3的evpn路由,会根据报文中携带的ert查找本地bd域里的evpn实例,有没有感兴趣的实例

有,就接收。

接收到类型3 evpn路由的动作(2和3的动作意义存在重复啊?不,2是建立了vtep的隧道,3是将对端vtep地址加入到头端复制列表里,后续bum报文就利用头端复制列表转发)
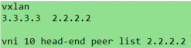
2和3的步骤如上
后续,pc2发了针对bd10的bum报文,ce3就会进行头端复制给ce2和ce4,实现bum报文的转发。
Ce2上在int nve下,配置完protocol bgp之后,然后在ce2 的g1/0/1接口进行抓包(上联)
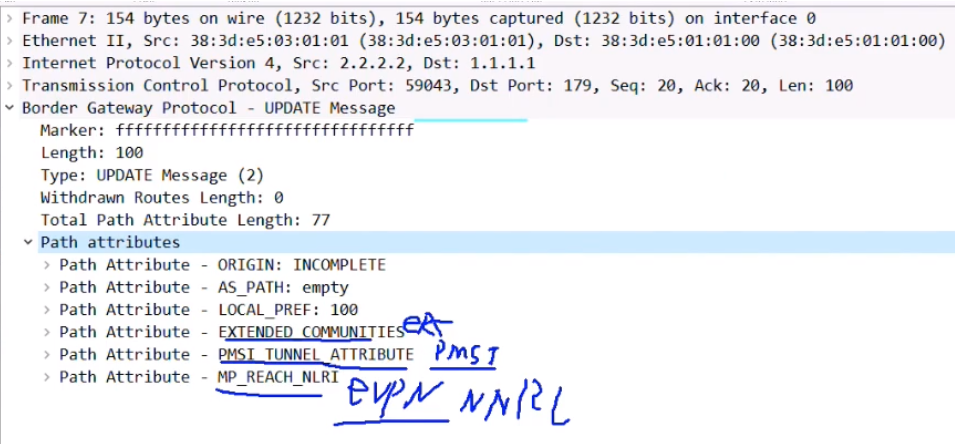
2.2.2.2向rr 1.1.1.1发送bgp update报文
路径属性展开
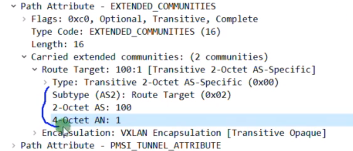
rt值
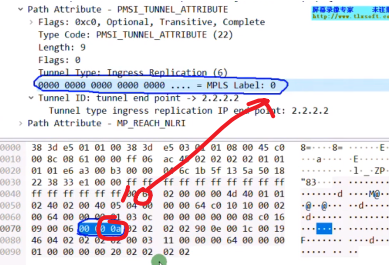
pmsi中携带vni 10(wireshark要看其16进制的取值,就是mpls lable-二层vni)和vtep。这个字段长度3B,24b=vni的长度24b
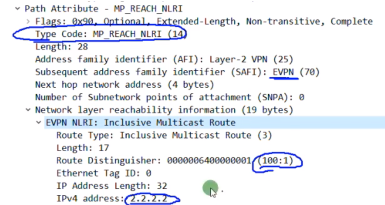
在mp-bgp中,携带了一个evpn地址族的前缀信息,包含rd+vtep的地址。Ip add长度32b,route type:3
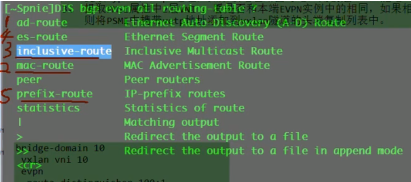
在rr上通该命令看类型3的evpn路由 。看其他type的关键字见红色字
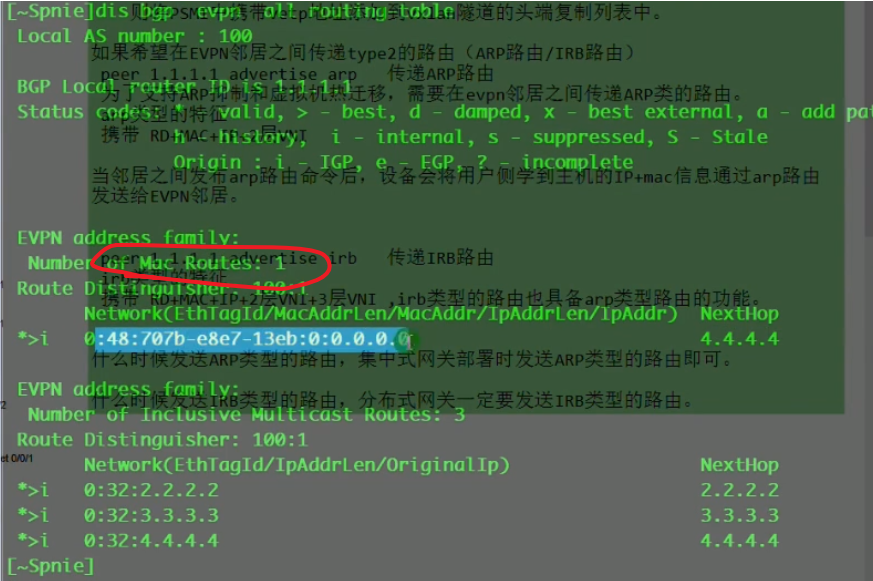
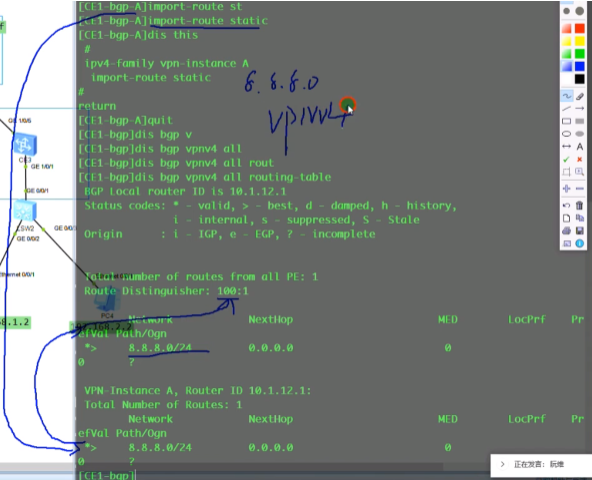
集成组播路由
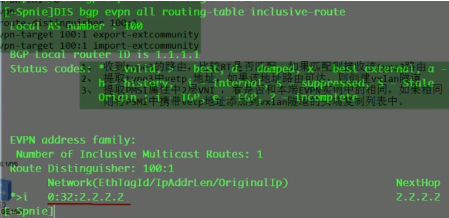
rr上dis bgp evpn rout 看到的type3的路由nh就是报文中的nh network add的值(抓包的时候看不到这个地址,但是在解码的时候可以看到)。路由表中的0:代表报文中的ethernet tag id:0;32代表报文中的ip add length:32;2.2.2.2代表报文中的ipv4 add 2.2.2.2
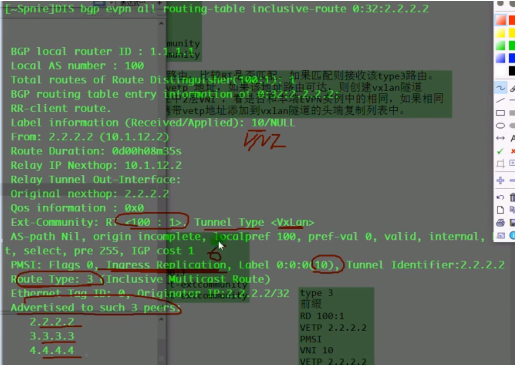
查看明细的类型3的路由,advertise peer说明rr已经将该路由通告给列表里的peer
R3是要和R2创建vlan隧道的

没有创建成功,是因为在R3上的nve if下vni10没有指定source(头端地址)的ip地址,evpn不知道用哪个地址来建立隧道

配置之后,就能通过类型3的路由动态建立隧道
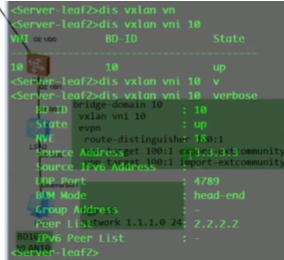
查看vxlan的头端复制列表。如果ce3发送过来的vni=10,正好和本端一致,那就要把2.2.2.2针对vni10放到其头端列表中。现在在Head-end列表中,已存在2.2.2.2。后期在bd10里发送bum报文,会复制一份发给2.2.2.2。
以上就是通过evpn动态建立vxlan隧道,动态形成头端复制列表,然后动态进行bum报文的转发。
数据层面分析
Pc1访问pc3
arp请求时,如果目标mac不知道,target mac就用0.0.0.0代表-不是用ffff
ce2接收到数据帧后的源mac地址学习行为
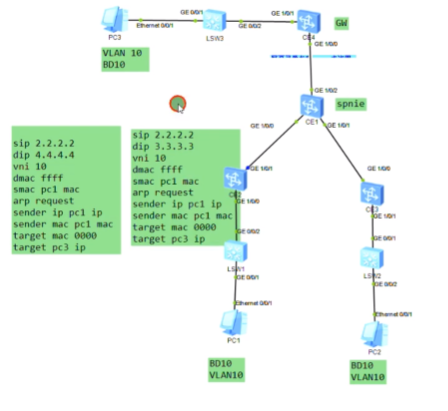
Ce2的头端复制行为

arp请求到达ce3、4,ce3、4能根据该报文学到pc1的mac,并关联到bd10,从2.2.2.2学到
然后再进行解封装,重新打上用户的vlan tag10
Pc3回复arp应答。即学到mac地址后,后续的单播帧就能根据mac地址表直接进行二层通信
后续省略
ensp转发层面有时候bug,做不通。但是控制层面没有问题,不,都是有问题。
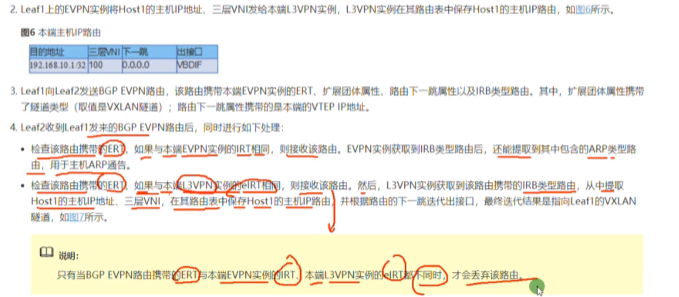
用evpn协议做集中式网关,网关设备上也需要运行evpn协议,让每个leaf设备都能和网关设备建立vxlan隧道,网关在配置vlanif接口就ok了。网关和leaf,以及leaf之间都要建立evpn的邻居关系,之间要传递类型3的路由-只要建立vxlan隧道,都需要配置evpn邻居关系,才能传递类型3的路由。

将ce3做成集中式网关,跨网段的流量都需要经过ce3
如果要做多租户的话,就再在vbd if中binding vpn ins。只需要配置ip地址就行了。
在配置evpn邻居关系时,如果要发送类型2的arp路由,需要配置上述最后一条命令。
产品手册里也没有敲这条命令。当需要支持虚拟机热迁移时,需要敲这条命令,用来才支持传递类型2的路由

默认只传递类型3的路由(传递类型3的路由就能实现2层互访),只有配置上述命令后才会传递类型2的路由。
因为配置集中式网关,只需要跟网关建立vxlan 2层隧道,这样在跨子网互访时,是先把报文通过2层vxlan隧道传送给网关,网关再查路由通过另一个vni的隧道到达目标主机,这种场景只需要传递类型3的路由就足够了。
arp类型的路由如何支持广播抑制

类型2路由的格式(包含三种:arp、mac路由表里有这种,但是配置上没有这个选项,应该是在arp类型中,只包含mac、rd、vni,相比arp类型路由不包含ip、irb-集成路由和桥接Integrated Routing and Bridging。相比arp多携带了一个3层vni信息),其既可以传递vm的mac地址,也能传递vm的ip地址-传递这俩,本质就是arp了。在传递vm的ip地址时,就类似于在传递一条主机路由,类型2的路由不用来建立隧道(只需类型3即可建立隧道)//本质就是不同类型的路由,实现的作用是不同的。
esi在该场景可不管
Ethernet tag id在vxlan中一直是0
Mac add length 48b
Ip add ,vm的ip地址
Mpls label 1:已配置为10
Mpls label 2:暂未配置
bgp下 l2vpn-family evpn 下peer
arp路由本质是携带rd+vm的mac+ip+2层vni信息(irb路由多了一个3层vni信息)

arp类型路由和irb类型路由(具备arp类型路由的功能)的区别,主要在于是否携带3层vni。在evpn邻居之间通告arp或者irb类型的路由。
在集中式网关跨子网互访时,是由网关来实现路由的,故只需要一个二层vni,用户只需要将自己的流量交给网关,再由网关将数据包发送给目标主机,所以不需要3层vni信息。2层vni和3层vni的差别,check
在分布式网关的场景中,同子网互访是要用到二层vni来进行报文的转发,而跨子网互访需要用到三层vni来实现转发。
在项目实施时,集中式网关部署用arp就行了,而在分布式网关部署时一定要用irb
可以看看华为标准化支付方案-配置模板
集中式网关场景下配置了arp类型的路由。这样配置是为了实现vm的热迁移和arp广播抑制。二层互访只需要发送类型3的。
分布式网关在建立evpn peer时传递的是irb类型的路由。
通过vxlan隧道,只需要二层vni就能把报文发给网关。因为vm1访问vm2时,dmac是网关的(nh),在跨子网互访时数据帧是交给网关的,本质是先在一个广播域内通信,再到网关的另一个广播域。而网关上都是直连路由可达。
只能看到主机的mac,不能看到主机的ip地址,不对。13eb是网关的mac
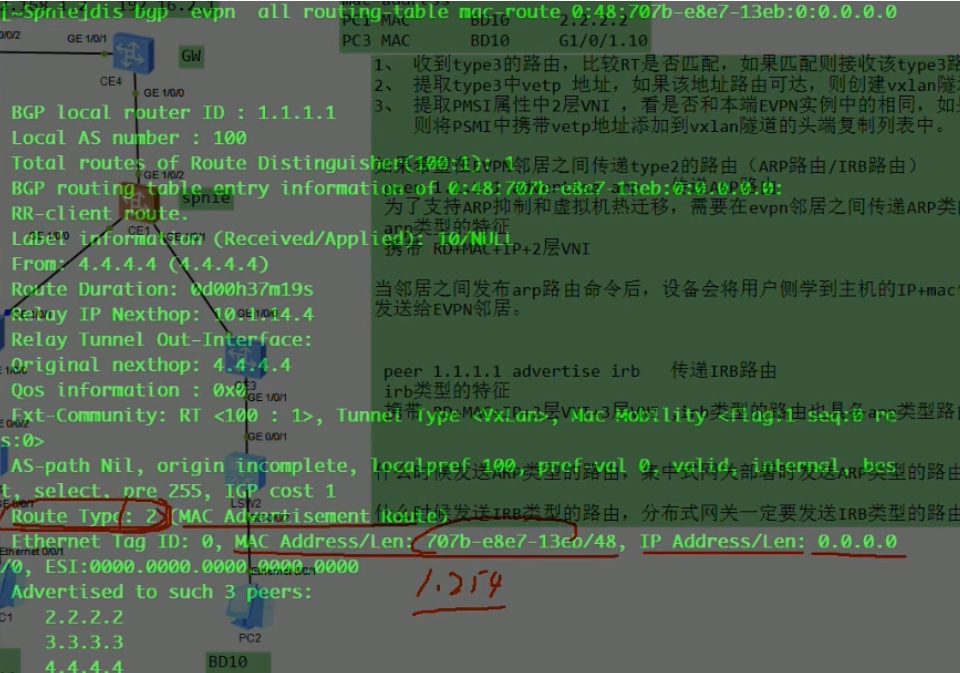
看明细,网关将自己的mac地址啥的,通过类型2的路由通告出去。只携带了自己的rd,mac,这个mac是网关1.254的mac,网关所属的bd域的二层vni,evpn实例的ert(这个和类型2的路由没有关系),但没有将网关的地址带出来

明细里,通告了主机mac,和二层vni信息,ip地址没有通告
arp广播抑制
假设ce2已经从用户侧学到了pc1(vm)的mac地址和ip地址,ce2就会把这些信息通过arp类型的路由发布给evpn邻居

消息如上
Ce4收到之后,会把报文中携带的vm的mac提取(这是从网络侧学到的 ),生成本地的mac地址表,并绑定到bd10,以及是从nve 2.2.2.2学到的。
即,vm发送arp,nve1接收到后就会提取主机的arp信息,通过类型2 的路由发送给所有evpn的peer。对端nve接收后,把arp类型的路由提取出来,把vm的mac,bd域和源端vtep的地址放入自己的mac地址表中。
如何实现arp广播抑制
Pc3向.100发送arp请求
报文到达ce4,如果ce4开启了arp广播抑制功能,如果开启了,就会查本地的arp表,有没有这个vm ip地址对应的mac(就是arp缓存表)。如果有,就会把这个arp请求的dmac改为目标主机的mac地址,该行为称为arp广播变单播,如下
之前ce4在收到pc1-ce1发送的arp广播时,已经将其放入到arp缓存表中,然后通过arp缓存将其变成mac地址表中的一个表项。
因为变成单播了,就去检查mac地址表,发现对端是2.2.2.2,则这个请求报文只需要封装vni10。
通过以上步骤,arp报文就不需要头端复制,只需要针对你要请求的目标主机所在的vtep,单独发一份报文过来,就起到了arp广播抑制的作用,减少了arp报文在dc中的泛洪。

2.在后面的vm热迁移的场景(原网关的撤销vm arp和主机路由行为)
lab实现没成功,是因为使用的是集中式网关,没配置三层网关。如果配置分布式网关的话,就能成功
将网关下移到到ce2(做成分布式网关)
+Vxlan vni 100 //这个是三层vni,绑定在vpn ins A下,相比二层vni是在bd域下配置的
Gw enable//启用分布式网关功能
Host//收集主机路由信息
至此在ce2上就有了分布式网关
在ce2的g1/0/1抓包(上联)
只通告了Label 1是二层vni

修改,undo arp,再通告irb类型的路由
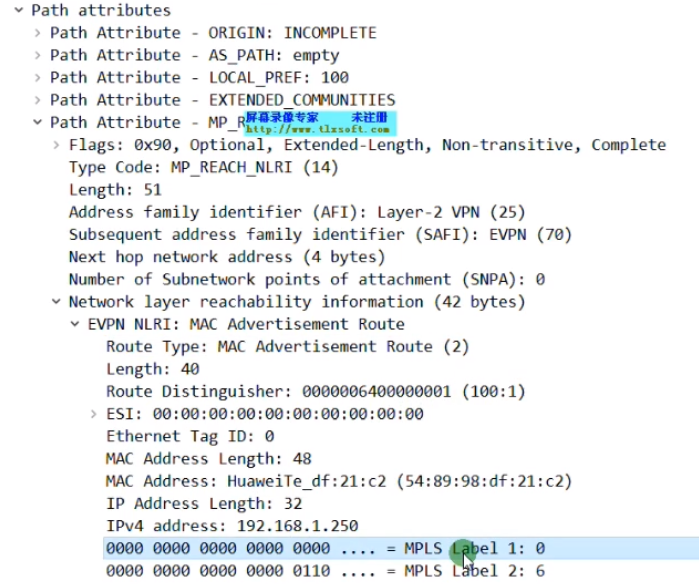
二层vni是0A(得看下面解码的),三层vni是16进制的64-即10进制的100
这就是arp和irb路由的区别,就是是否携带三层vni。
在集中式网关的场景,仅ce1是网关,ce2不是网关,没有办法进行arp信息的收集,所以就看不见arp类型的路由。手册里写的是:三层网关学习到子网的主机arp时,才会生成arp类型的路由通告给邻居。在集中式网关中,这里没有网关功能,而在分布式网关的场景下,把网关功能打开后,在向邻居通告arp类型路由时,网关已经知道了主机的arp信息后,就能发送arp类型的路由了。如果发送irb类型的,就多了三层vni。
总结:集中式网关的场景下,去发送arp,是发不成功的,so在产品手册里,部署evpn时,不需要配置peer arp enable。而分布式网关,发arp和irb都行。
arp广播抑制的逻辑:
Ce2有网关功能的话,通过接收pc1发送的数据帧,就能收集其mac和ip,所属vni,rd以及vtep地址,格式如下:

通过arp类型的路由发布给evpn邻居

Evpn peer收到会提取arp信息里的mac地址,加到自己的mac地址表中,pc1的mac绑定bd10,远端的地址是2.2.2.2,提取到它的二层网关的mac地址表中
本端nve在接收到arp请求时,因为自己具有网关功能,会去arp信息表里查询 dip对应的mac。就起到了arp广播抑制的功能。
还一个功能是热迁移的功能,用在分布式网关的场景下
假设现在全网已学到pc1 的mac
Ce4、ce3都会和ce2建立隧道
此时发生vm热迁移,分布式网关场景下上图的三个表项都是错误的了。集中式网关不存在此问题,因为这种情况下,vm的arp信息都是在网关上。在vm发生热迁移后,集中式网关只需要网关刷新隧道。但是在分布式网关的场景下,全网都要刷新隧道。所以这就是arp路由的第二个作用。
vm在新的交换机ce3上线后,ce3就会学到pc1的mac并关联bd10,int g1/0/2
上图在同一个bd域10,学到了相同的mac地址,一个是从网络侧学到的,另一个是用户侧学到。此为典型的mac地址冲突场景,新学到的会把旧学到的mac地址替换掉。然后通过arp类型的路由:包含pc1的mac,2层vni 10,pc1的mac,pc1的 ip地址,自己的vtep地址3.3.3.3通过arp类型的路由通告到全网
Ce4接收到之后,表项写入,有点蒙,去pc1有两个nve,咋办?
Ce2接收到之后,会把这个arp信息同步到二层网关(就是自己),ce2同样会用新学到的,把后学到的清空掉。Ce2在从网络侧学到冲突的mac地址,会主动向用户侧发送arp探查,去问自己下面是否还存在主机,如果vm已经迁移走,就不会有回应,则ce2(原网关)会发送arp撤销的路由-就像bgp通告一条删除路由一样。

格式如上
全网的路由器在接收到这个撤销的路由后,老的表项就会被删除了,未来要访问vm就会通过新的隧道去(如ce4)。arp路由的撤销用来刷新隧道信息。
根据lab,只有分布式网关的场景下才能抓到类型2的路由,集中式网关场景无:因为没有网关(ce2、3/4等),没法针对接收到的arp报文进行arp路由的生成。
集中式网关的场景下,因为不保存arp信息所以不能发类型2的arp类型路由。而mac路由只要有mac地址,rd和vni就能发。
可以通过流量就学到mac地址,而不需要在额外发送mac类型的路由。arp类型和irb类型的路由只有在分布式网关的场景才能看到。
arp类型的路由,是用来优化用的,二层通信的本身不需要arp类型的路由,通过流量就可以学到mac,arp类型路由仅用来实现arp广播抑制和vm热迁移。
只要通告了arp类型的路由,则从用户侧学到的mac和arp信息就会主动的发送给evpn邻居。这个类型2的路由里也会携带rt。接收端如果rt匹配,则接受这个arp类型的路由放到自己的arp三层信息中,再下发到二层mac地址表中,用来实现广播抑制和分布式网关下vm热迁移的一些优化
evpn实例的ert(ethernet rt)+下面类型2的路由(mac类型路由)
接收到查看这个bd域放到哪个本地的evpn实例中,arp类型的表项,再注入到evpn实例的mac表项里,生成二层信息。
-------------------------------------------------------------------------
2023-05-16 11:12
Video 7
Lab :类型2的路由,分布式网关的配置。直接在R2(ce2)和R3之间建立evpn peer,做分布式网关的部署

Ce2和ce3都是网关,192.168.1.1属于租户A的一个子网,需要通过vpn实例来和其他的子网进行隔离。
先配置underlay网络,然后配置evpn peer
evpn-overlay enable
实验先只通告类型3的路由,类型2的先不通告
上集的问题,只有在存在vpn ins,有一个三层网关辅助的情况下才能发送arp类型的路由,否则看不到效果
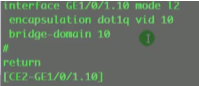
配置vxlan的接入
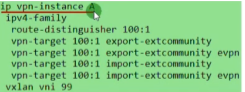
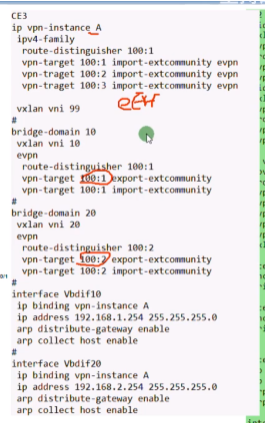
此拓扑分布式网关,就需要在ce2和3上分别创建vpn ins
在配置分布式网关时,每一个网关针对每一个租户都要生成一个vpn实例
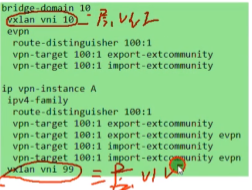
分布式网关的完整配置,2层vni用于同子网互访,3层vni用于跨子网互访
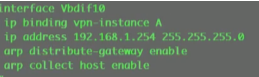
绑定网关,并打开分布式网关功能,收集主机信息功能。
此时在leaf ce2上,相当于给租户a在ce2这个bd域下的主机提供了一个网关功能。
将网关用vpn实例绑定起来,是因为在云计算的网络里,这台leaf sw可能接入不同租户的网络,就需要使用vpn ins将租户的网络隔离起来-实现后续多租户的需求
Ce2的 ins A的路由表就出现192.168.1.0这条路由了
Pc1设置为.1,网关设置为.254.现在已可以ping通网关
新增pc3-属于租户A的第二个子网,现在想通过这个ins,在ce2上直接实现互访,用vlan 20和bd20
Ce2现在的配置-增加了vni20
此时逻辑拓扑如上,通过ce2(router)。Pc3配置2.1,网关为2.254,已能ping通本网关。Pc1ping pc3通过本地网关ce2,就能ping通
说明分布式网关的一个特点,如果两台vm接在同一台网关leaf上,则互访的流量在leaf上就可以实现直接路由。
新增pc4-同样属于用户A。(PC2为192.168.1.2)
实现pc1和2的互访,pc3和4互访-同子网互访,通过类型3的路由-集成组播路由就可以实现了,是建立vxlan隧道。pc1-3本地路由就可以实现互访,这就相当于小的集中式网关,由本地网关帮助进行路由。
如果是2.1访问1.1或1.1访问2.2这种跨子网怎么解决-不同leaf上不同网段的vm如何实现跨子网互访
Ce2和ce3查看arp,就能看到本地vm的mac和ip信息
现在利用分布式网关-在本地leaf下,在本地跨子网(及同子网)互访是通了。当前想实现跨leaf之后同子网互访以及跨子网互访
发布类型3的路由。Ce3配置相同
vxlan隧道没有起来,可以先查看evpn peer establishen否
ensp会出现直连不通的情况,换接口试,bug
500的镜像,做分布式网关,数据层面做不通,路由的效果是有了

vxlan隧道已建立成功
查看详细信息
此时同网段互访,如1.1-1.2已通

现在只发送类型3的路由,已经通了。还没在peer间配置arp类型的路由,当前ce的bgp配置如上。
so类型3的路由通告之后,同子网互访就能实现,不需要发送类型2的路由,因为流量本身也可以让设备学到地址信息。
抓包看,2.2访问3.3,是封装在vni 10的数据帧中
lab中,子网192.168.2.0段就不通,ensp bug
左右是两个vpn 实例,想让1.1访问2.2,需要网关ce2上vpn ins A的路由表中,有2.2的路由才行
so,让evpn协议,能够把主机的路由信息在vpn实例中来进行互相的通告,就类似三层vpn
Ce3当前vpn A的路由表中,没有对端的任何路由,只有本端的直连路由
在分布式网关的场景下,配置通告irb类型的路由
1.1和1.2路由两边的ce已经学到了,但2.1和2.2没学习到(因为之前在int nve1下没配置vni 20 head-end peer-list protocol bgp)
Ce3已经能学到对端的主机路由了-通过evpn的irb类型路由传递过来了,并引入到vpn ins中。本质就是让本端leaf 网关学到对端vm的路由
理解,公司A在ce2上有一张路由表,在ce3上有一张路由表,在两张路由表上进行交换。路由通了,怎么访问都行了。
Refresh bgp evpn x.x.x.x export //触发更新
2.2.2.2向3.3.3.3发送了update信息
Ce2已学到2.1的mac地址。但是ce3没学到2.1的路由,分析是没发,还是发了没收
从抓包看,2.1的路由已经传递过去了
但ce3上仍没有看到2.1的主机路由
配置总结如上
为何两边2.0这个网段的主机路由互相不学习,虽然发过去了
Vni99是绑定在vpn ins下的,称为三层vni;bd域下配置的vni称为2层vni。在跨子网互访时,报文打上的vni是三层vni 99-1.1访问2.2,其封装的vni就是99,1.1-1.2,封装的vni就是10。跨子网互访就打上99的3层vni,同子网互访就打上各自bd域的2层vni
两个vnp ins之间要进行主机路由的通告,就需要在邻居间通告irb类型的路由
为何2.1和2.2的路由不互相学习?
查看2.2.2.2发给3.3.3.3的update报文

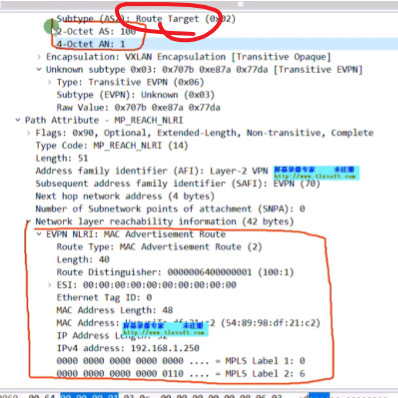
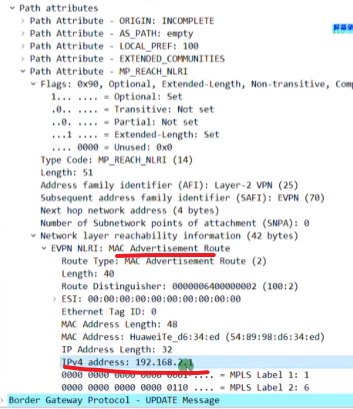
irb类型路由 ,包括,rd,vm的ip和mac,以及关联的两个vni,vni值得看下面解码,再把16进制换算成10进制。20和99
Ce2的bd10 和20所对应的vbd if接口都是关联在vpn ins A上,在传递irb类型路由时,192.168.2.1这台主机是归属于bd20的一台主机。Pc3在发包时ce2能知道其ip是归属在bd20,so其会提取出bd20的rd和2层vni,而这个bd域(bd域的网关接口)又关联到了vpn ins中,就能找到其三层vni了
类型2的irb路由的核心字段,pc3的ip

类型2的报文,bd域的rd

报文中携带evpn的团体属性的rt,就是vm所在bd域的evpn实例的ert
nh地址是自己的vtep地址,2.2.2.2
以上为irb类型路由携带的核心参数
Pc1和pc2这两条类型2的irb类型的路由会发给ce3
Pc1的,Ce3接收到之后,会将这条路由的ert和自己本地bd域的irt进行匹配
如果匹配,1.则接受该irb类型的路由,并提取arp信息,将pc1的mac和ip,二层vni提取出来放到evpn 实例的路由表中,用于实现arp的广播抑制和vm的热迁移等优化-arp类型路由的功能;2.把ert和本地vpn实例的带有evpn参数的irt(eirt)进行匹配,有,则 提取这个pc的主机路由和三层vni放入这个vpn实例的路由表中
即,在ce3上能得到这台vm的主机路由,但没有192.168.2.1的路由
华为称带有evpn参数的为,evpn+ x rt
Pc2的报文到达ce3
Ce3的动作,evpn的rt,100:2,本地bd域中有匹配的,ce3会接收该路由,并提取arp信息,用来实现优化。接下来看本地vpn实例中是否存在100:2,没有,so这条主机路由就不能放到vpn ins A的路由表中。此时bd20只能起到arp的广播抑制和vm热迁移的动态优化,但并不能把bd域内的这条主机路由放入到租户A的vpn实例路由表中,为了让其能正常接收该路由,则:
CE2上要补充100:2 import evpn
Ce3已能学到2.1的路由。此时,ce3的vpn A中已能成功学习到对端vpn ins里的vm主机路由
现在分布式网关就实现了同一个租户内的二层互通和三层互通。实现了集中式网关能达到通信的效果

跨子网互访,1.pc1ping2.2封装的三层vni就是99,需要匹配本地哪个vpn实例,vni是 99,然后这个报文就使用这个实例的路由表进行转发,就类似于mpls vpn里的私网标签,代表这个报文是属于哪个vpn实例的
所以两边ce2和ce3就需要配置相同的三层vni-针对同一个租户
通过路由表去查去往2.2,nh为3.3
interface vxlan,代表要进行vxlan封装的报文
报文上来后,匹配这个vpn 实例a。所以就会携带三层vni
通过路由表查2.2转发的话,会打上3层vni

同子网互访(如pc3和4)不查路由表,查的是mac地址表。dmac是pc4的mac,ce2在接收到数据帧后,判断dmac不是自己的mac就会查mac地址表,打二层vni然后进行二层转发。如果是跨网段互访,dmac就是网关,网关会先进行二层解封装,再看三层,发现是跨网段的,就去查路由表发现这条路由的三层vni是99,则打上99的标签出去。
2层查mac表,mac表对应的2层vni,3层查的是路由表,对应的封装在3层vni
发送irb类型的路由,只会发送这个bd域所配置的ert参数,这个vpn实例里的任何参数都不会发布,如下,bd10只发送100:1,bd20只发送100:2,和vpn ins A没有关系。接收irb类型路由流程见上面,2步。假如不匹配evpn实例(每个bd域下都有evpn实例,主机属于bd10,则发送的irb类型路由就属于evpn实例100:1),但是匹配vpn实例,就不提取arp信息,但可以生成路由信息,实现三层互访。故在接收路由时,上述两个检测只需要满足一个,就能按照规则去执行。
产品文档相应内容,通过irb类型路由发布主机ip路由部分
如果只匹配evpn实例,接收时只提取arp信息;如果匹配vpn实例信息,则生成路由信息,但arp不要。以上为irb类型路由的处理方式。
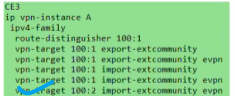
如果公司A在云里有100个子网,则需要在ce2上创建100个bd。想要实现这100个bd间跨子网的互访,在配置vpn ins时,就需要把所有bd域的export rt添加到vpn实例里去,工作量很大
如,增加3.1网段 bd e rt 100:3

不带evpn的rt不配置都行,配置了就能在未来和vpnv4传递过来的路由互相学习。加evpn是用来学习evpn地址族路由的
上述配置,就能让vpn A既可以学到irb类型的路由,又能学到vpnv4传递过来的路由
在发送irb类型的路由,发送的仅是bd域下的rt,和vpn ins A的rt没有关系
为了简化配置,在bd域的evpn实例下,添加100:100的ert,统一下
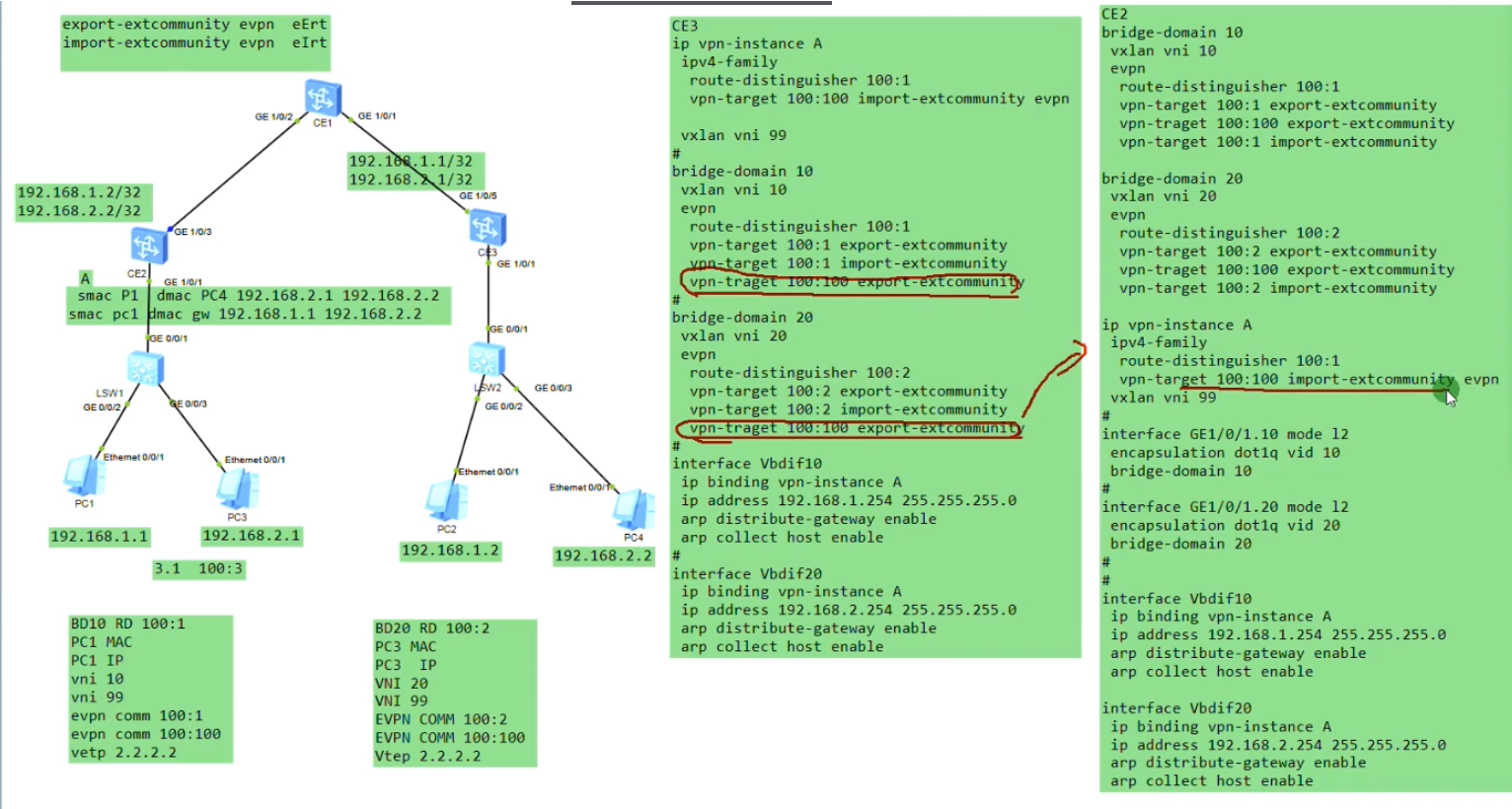
简化逻辑:每个bd域仅是某公司的不同子网,但这些bd域属于同一个vpn ins-这两个bd域中产生的主机路由应该在同一个vpn路由表中出现。
租户:在公有云里组了一个dc,该租户下包含很多子网(vdc和vpc的概念)。各个bd域就相当于我在dc中的不同子网-公司A的私有网络。那为这两个子网分配相同e rt的话,从概念上讲,这两个bd域就属于同一个公司
从配置理解就是,为每个bd额外的分配一个e rt,用来和这个租户对应的vpn实例的e rt去匹配。
100:100可以理解为一个租户,然后100:1和100:2可以理解为属于该租户的子网
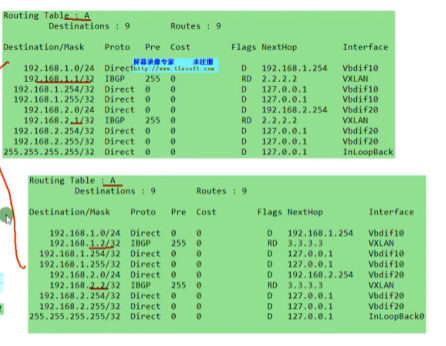
分布式网关不仅是网关在ce2和ce3处,最牛的地方分布式网关部署完成后,在每台网关上看的路由表都是一样的-在每一台leaf上看路由表都是一样的
以上为Ce2和ce3关于vpn ins A的路由表。这种情况,不管vm如何迁移,因为全网的路由表是同一张表。对租户来说,网关无处不在。
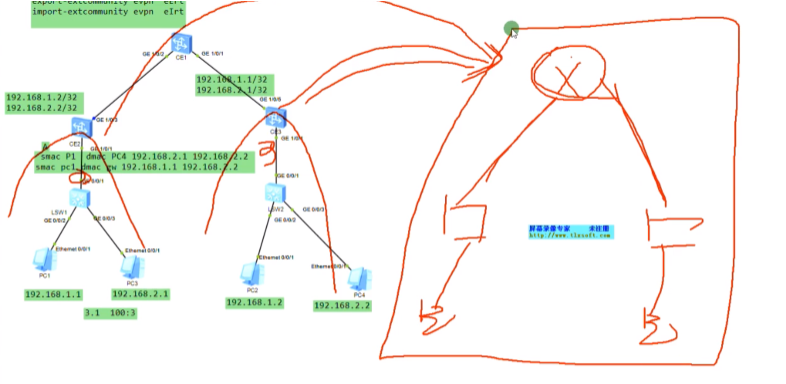
站在租户的角度,会将网络简化成右图-即分布式网关最后形成的逻辑拓扑和集中式网关相同。
集中式网关虚拟出来的网络和分布式网关虚拟出来的业务网络相同。分布式网关的优势在于,网关只需要维护rt匹配的路由信息,不匹配的路由信息可以不学,同时不需要维护不匹配的mac地址信息(对表项资源要求不高)。而集中式网关所有的路由和mac地址都是在网关上学的。
在分布式网关的场景下,只要你能找到网关,在这台leaf上有这个vpn实例的网关存在,就能迁移过去。而集中式的网关场景,vm只能热迁移到能够和网关建立隧道的leaf。总结,就是分布式网关,能够支持的大二层的范围更广。
So vm可以在dc内部迁移,也可以跨dc进行迁移。但在集中式网关,跨数据中心就不好迁移了,因为你迁移到新的dc后,还要能找回原来的网关,流量要跨 dc,广域网费用贵。
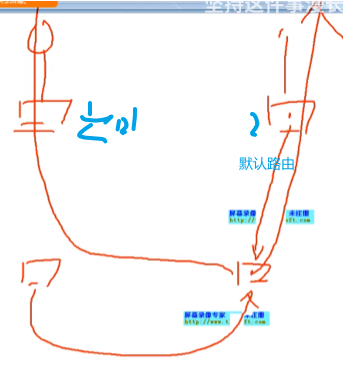
而分布式网关,上两台为对端出口互联设备(非网关),当vm迁移到右侧,通过出口下发缺省路由给右侧网关,该网关通过缺省路由走右边出口就出去了,流量就不需要摇到dc内部再出去。
左右为两个dc,下面为分布式网关,上面为互联网出口。
分布式网关,vm飘到2,由出口下发默认路由,2就可以利用缺省路由出去。但飘到3,如果出口1再向3发缺省路由,则就是跨dc的流量了。那可以从出口2向3发送缺省,就能正常的出去了,流量不需要跨数据中心跑。
集中式网关,在一个dc内飘是没问题的,但是飘到另一个dc后,源出口会和新的leaf建立隧道,流量会跨dc。
总结:分布式网关在vm热迁移和路由处理更灵活。集中式网关定死了,而分布式网关就无处不在,只要你在哪个leaf接入,这个leaf就可以成为网关。然后全网做了evpn,建立vxlan隧道,vm随便飘,vm的主机路由都可以通过irb类型的路由实时进行更新,全网同步。
举例:1.1的路由,别人访问1.1走CE2,当1.1 迁移到ce3下时,ce3会发布主机路由,而ce2会撤销原来的主机路由。
出公网,需要做nat。双出口,你迁移后会使用不同的公网运营商的地址做nat出去。如果是dc的server迁移,则你的dns、LB、nat都需要进行相应的配置,还需要考虑是否使用的是同一个isp的网络

比如使用公网202的地址出去,让电信把202的路由做到你的dc这来,让联通也把202的路由做到这里。这就是如何与isp做dc的这个外网部署。
正常情况下vm的上下线是有设备(sw)来感知的,vm启动后会免费arp来进行触发。但在结合sdn控制器一起做的话,就是云平台才能知道vm的迁移了(比设备更快的感知),并将信息下发给控制器,控制器直接把配置进行刷新,收敛速度比用evpn协议收敛更快(设备自己也感知,就是感知的速度慢)
举例:ce2这些sw会和华为的云平台服务器配置lldp协议,当某台vm从物理服务器迁移走之后,云平台会告知控制器,某台vm迁移走了,控制器就能知道这台vm从哪台设备接入的。
主要是跑lldp协议来感知服务器,物理交换机和服务器上的虚拟交换机open sw运行lldp,因vm是连接在虚拟sw的,故vm的上线和下线虚拟sw是能感知的,so 虚拟sw快速感知vm的变化后,就通过lldp协议交互给sdn服务器,服务器就能知道这台vm原来是从哪里接入的,然后下发相应的配置或流表来实现快速收敛,就不是利用evpn协议来收敛(纯路由协议)
私有协议一般是openflow,netconf
厂家的控制器,硬件overlay:华为 ac,华三vcf,cisco aci。大厂的控制器,只能适配自己的设备
vm软件nsx是纯软件的sdn,和大厂的sdn没有关系,就不符合硬件厂家的利益了。称为vm 软件overlay
分布式网关场景下rt的规划
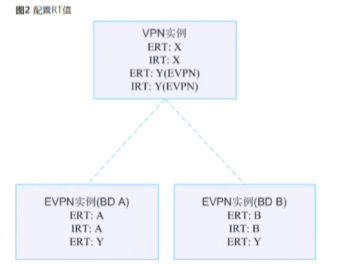
每一个evpn实例,配置一对相同的rt,用于同子网互访。如果这两个bd域(子网),是属于同一个vpn的话,单独配置的e rt要一样。在对应的vpn实例下,带evpn参数的irt也设置成y
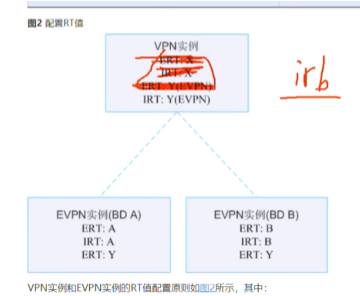
实际,通告irb类型的路由时,涂红的部分不需要配置:只需要匹配evpn实例的ert就能将主机路由加入到vpn实例路由表中。
实际是利用控制器集中下发配置,要不配置量太大了,两个ce就这么多配置量
下一视频,分布式网关的场景下如何访问外网
-------------------------------------------------------------------------------------------
2023-05-20 15:10
Video8
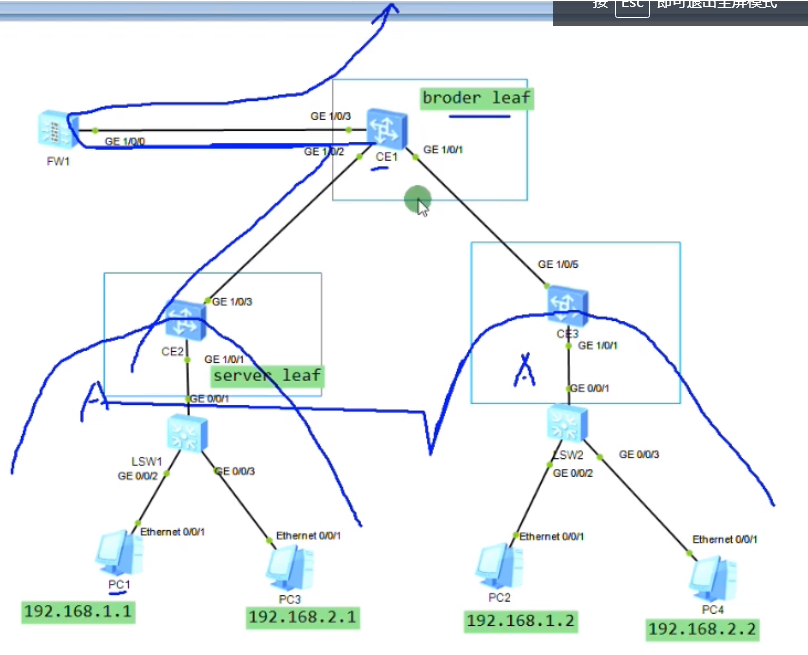
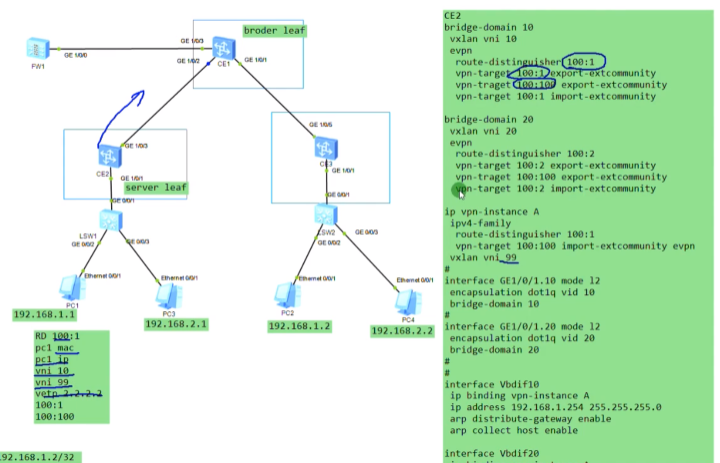
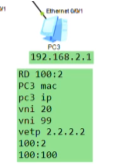
需求:Ce2和3上都有一个租户a的vpn实例,boarder leaf连接fw,如何让pc去访问外网·。
在集中式网关的场景中,boarder leaf(ce1)同时充当网关的功能,用户的流量就通过到网关的vxlan隧道走到网关,再从网关通过路由绕到防火墙再出去。
但现在在的场景是用户的网关都在自己的serive leaf下,是通过vpn实例来维护租户里面的路由。报文到达ce2就要查路由,再去防火墙。那如何让流量从ce2-ce1?
方案:在service leaf-boarder leaf之间建立evpn peer关系
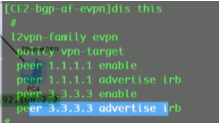
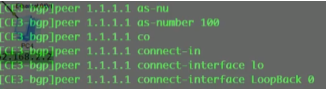
Ce3相同,先建立与ce1的bgp peer再建立evpn peer

leaf之间的evpn邻居关系已建立
将ce1的g1/0/3接口配置为trunk,放行vlan,再配置vlanif接口
在ce1上创建vpn ins A:用来描述租户A,100:1。给租户A创建vlanif接口,和这个租户的虚拟防火墙实现对接。在ce1的实例A里添加一条缺省路由,指向防火墙。现在只需要将缺省路由传递给ce2和3的vpn 实例A中。
也可以存在一条指向外网的明细路由 8.8.8.8/24(fwd的loop) 192.168.10.10

在border leaf上的这两条路由,首先要变成vpnv4路由-即添加rd参数的ipv4路由
将vpn A中的静态路由引入到VPN A的bgp中
现在需要将这两条vpnv4路由,通过evpn地址簇传递出去。
把vpn实例中的静态路由or igp路由引入到这个实例的bgp路由中,会自动变成一条vpnv4路由,现在需要将该vpnv4路由变为一条evpnv4的路由,在传递给evpn peer,放入到相应的vpn实例中
上图命令作用将vpnv4路由,转换为evpnv4路由再传递出去。
配置完这个,没抓到update报文,是因为带evpn参数的rt没配置,三层vni也没有设置(跟这个没有关系)。因为未来报文要送给border leaf,是要通过vxlan隧道来进行封装的

配置完 这个,仍然没有update报文
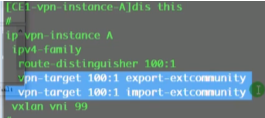
配置完rt还是没有update报文。再加evpn参数的rt之后就出现update报文了
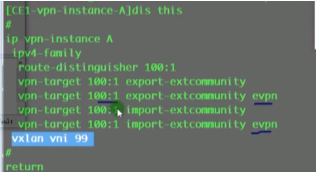
此时R2已经通过更新报文将下面的主机路由发布给了r1,但是在r1的vpn ins的路由表中却没有学习到
类型2的irb类型路由会携带上述参数
Pc3路由信息如上
在R2发往R1的报文中,能确认已发送该路由,但R1上没有两条主机路由。现在重新规划rt,删除100:1
在ce1上删除100:1的target,只留100:100的 ,改为这样
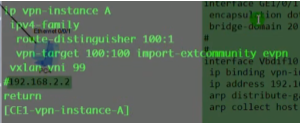
仍然没有2条主机路由
根本原因是:Ce1上没有配置二层bd,vxlan隧道都没建立,peer之间建立vxlan隧道是需要通过类型三的路由来建立的
没路由和evpn的vpn-target有关?Ce2传递给ce1的类型2和类型3的路由,由于没有匹配rt,就不和你建立隧道,不接收这些路由?
关闭rt检测试一下

类型3的路由不接收,隧道还是建立不起来
恢复。还是需要创建bd
配置成这样,才能保证类型3的路由在传递给你时,携带evpn实例下的两个参数
你本地有匹配的才会跟你建立vxlan隧道。
所以在boarder leaf上,虽然没有vxlan隧道的接入,但为了和下面的leaf间建立vxlan隧道,对应的bd域还是要创建。并匹配rt值
此时vxlan隧道建立成功

再看vpn实例的路由,分布式网关下的所有主机路由都传递给了boarder leaf的vpn实例A的路由表。这样做的 目的是未来外网的用户访问vpn实例里的虚拟机,到达了这个实例A后,要去访问1.1走2.2 的隧道,访问1.2走3.3的隧道
bd域创建的目的是让service leaf和border leaf之间可以通过类型3的路由建立vxlan隧道,然后再去检查传递的irb类型路由的rt值。
Ce1上 + 100:100 e e evpn?vpn实例下的?right
理论上,border leaf和service leaf之间是没有同网段互访的需求,但这之间建立vxlan隧道,是因为有跨子网互访的需求-通过vxlan隧道。虽然业务上不需要类型3的,但是在功能上必须要配置。
首先要建立隧道,然后再考虑路由传递的问题

此时在ce2上仍没看到ce1通告的8.0的路由。8.0的路由不属于任何evpn实例,不属于任何bd域里的路由,是被认为放到你这个vpn实例里的一条静态路由/或通过其他路由协议学到的igp路由。此时这个8.0的路由在通告出去时,携带的rt不是bd域里配置的rt,而是vpn实例中带有evpn参数的e ert,但ce1上还没配置 e ert,ce2和3就不会接收

配置之后,1。1就发bgp update报文
已学到8.0和缺省路由

类型5,ip前缀路由。与实际抓包对比
vpn实例下的rd
mpls label 即三层vni
类型5的路由就是传统的路由,不像类型2带mac地址

传递类型2路由的命令

传递类型5路由的命令:将vpnv4的路由,转换成evpn类型的路由,并把这个类型5的路由传递给evpn邻居
import,将静态路由变成vpnv4路由。

通过类型5来发布路由的话

如果传递的是irb类型的路由,其所携带的主机路由的rt是来自于bd域下的e rt;如果是传递的类型5的路由,所用到的rt是取自于vpn实例的e ert,如下


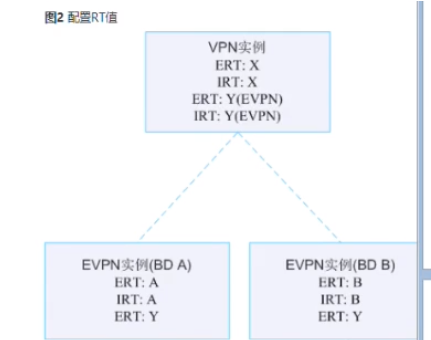
配置解析
每一个bd域要实现2层互访,要保证一对rt要匹配。Ce2和ce3的bd10通过RT 100:1可以通过类型3建立vxlan隧道,实现二层互访。
保证每个bd域,如vni10-相同的大二层,有一对rt可以匹配,未来就能实现vxlan隧道的建立,并且实现二层互访。
未来实现在分部式网关的场景下,同一个租户的vpn实例的主机路由能够彼此进行学习和交互,就需要保证每个bd域下的e rt,要和对端接收端的vpn实例的eI(input) rt匹配,未来ce2 两个bd域中的主机路由在传递给ce3后,就可以放到ce3的vpn实例a的路由表中。同时反向也要匹配。这样两边就能实现二层互访和三层互访:打通了dc中的东西流量(同一个租户同子网和跨子网)。为了让租户的主机能访问外网,在border leaf上也要创建对应的bd域和配置,用来建立vxlan隧道的各自bd域相匹配的rt,这样隧道才能在border leaf和service leaf间建立起来。接下来在border leaf上传递类型5的路由,在vpn实例中设置100:100的e ert和每个service leaf上的vpn实例下的e irt匹配,那么类型5的路由就能注入到这些service leaf的vpn实例中。
上图对比配置去看(ert和irt,主要是为了未来交互vpnv4路由)
需要发类型5路由的时候,才需配置eert(evpn ert)
Border leaf上不做bd域的配置的话,vxlan的隧道都无法建立,后期就算把类型5的路由传递过去,但是由于border和service leaf之间没有隧道,报文送不过去。
此时在ce2上已经存在缺省路由了
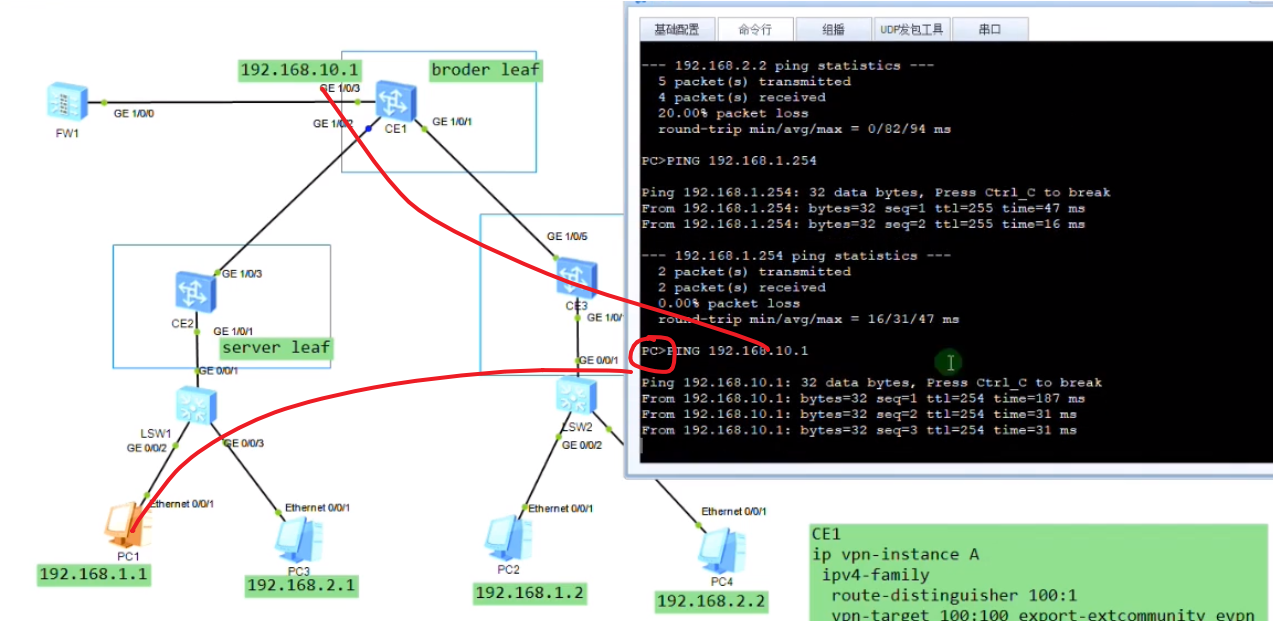
接下来pc就可以ping通fw,出去。
可以理解ce2和3是小集中,ce1是汇聚。网关下沉到ce2和3后,在ce1来一个汇聚,汇聚向下下发缺省路由,报文通过缺省路由出去(通过vxlan隧道)。
在此场景中,vm随便迁移都没关系,因为每一个网关上都用缺省路由,未来去外网都是通过ce1 border leaf出去
防火墙上使用子接口做单臂路由
将该子接口加入到安全区域中

在子接口上开启ping测试功能

防火墙上配置回包路由
已可ping通防火墙
dc中的虚拟网络是终止与虚拟防火墙
通过虚拟防火墙绕到public再去外网。所有用户的私有网络在dc内部都是通过vpn实例隔离起来的,然后通过墙绕到public再出去
分布式网关的场景
Server leaf可以作为网关,border leaf跑一个evpn给server leaf(某个vpn实例)下发缺省路由,流量就通过缺省路由直接到达border leaf上再出去了,这就没有经过防火墙。而对于需要经过防火墙的用户,就由service leaf向server leaf下发缺省路由,流量就先到达service leaf中的fw(fw使用一个vpn实例来接收该缺省路由),然后再从border leaf向service leaf下发缺省路由,绕墙走的就会通过border leaf出去了。
上述设备做了css,可以虚拟成一台设备,每台都有一个vtep地址。
访问互联网,合作伙伴,访问第三方机构,就可以在border leaf上(针对某个vpn实例,参照lab中的0.0.0.0和8.8)下发相应的路由到你的vpn实例中(未来要通过哪个border leaf出去,就由谁下发相应的evpn路由)
上图底层是一个ip网络,上面全是vpn实例,租户隔离,把路由注入到相应的vpn实例中,通过vxlan隧道来走(2/3层vni),二层互访可以通过类型3的来实现,3层互访可以通过类型3和5来实现,整个dc就是在evpn的管理下。同时这种胖树结构,拥有了灵活的扩展。

evpn的5种类型路由
no.1为Ad route
还有一种类型5的前缀路由

华为私有协议evn里会讲到类型1和4。evn是evpn的阉割版协议,用来和友商,如cisco的ovt协议-跨数据中心的大二层网络,来做竞标,华三也有自己的。即各大厂家在dc中都有自己的私有大二层协议,但华为自己没有,有点尴尬,就推出了个evn。我也有跨数据中心的大二层私有协议,呵呵。但目前各厂商在dc中用到的主流解决方案就是evpn+vxlan+自家的sdn软件来实现基于SDN架构的网络虚拟化解决方案。
cisco的控制器是aci(application centric infrastructure) ,华三的控制器是vcf(Virtual Converged Framework)

evn中的描述,evn只能实现二层互访,不能实现三层互访。
so对于类型2的路由来说,因为只用于二层互访,而不用于三层互访,就被阉割掉,删减掉arp和irb类型的路由,只需要实现mac地址的通告。
多归场景才会用到类型1
类型4,df-指定的转发pe路由器

evn的应用场景-用在基于vlan的dc的场景下实现跨数据中心的vlan互访,没有使用vxlan,还是使用vlan来实现二层的。而在跨dc时,如上图跨dc进行互访,就用到evn来解决。dc内部没有部署vxlan,只是使用vlan来实现二层的隔离,但为了能够让两个dc中相同的vlan能实现二层互访,就需要在pe之间通过evn协议来交换这些vm或者物理机的mac地址信息,从而通过vxlan来实现dc之间的互访(在上图ip网络边缘之间跑vxlan,进来跑的就是vlan)。

双规接入才需要类型1的路由和类型4的路由。如果是单归接入,类型1和4的作用就没有了(传递了,但是没效果)
双规接入,为了保证接入的可靠性。
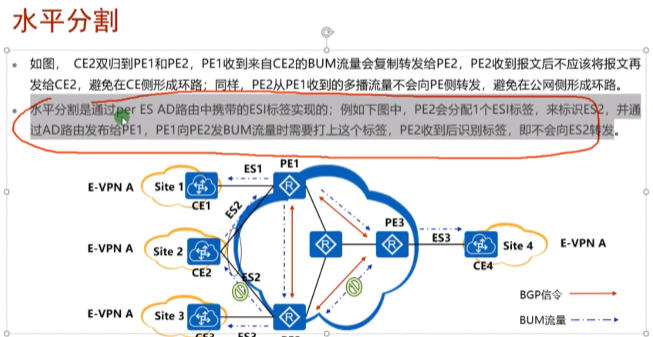
类型1路由的三种功能:水平分割、快速收敛和别名。
RD:evpn实例的rd,就是bd域下配置的rd。
esi:用来描述一条链路的。

如上图的链路标识符(esi),可以由管理员手动进行配置

esi的作用,可以让pe知道,其他的pe和我是否连接在同一台ce上。上图pe1和2上配置的esi都是a,后续两台pe在发送类型1的路由时,会携带esi标识符,那通过交互类型1 的路由,两台pe就能知道自己连接的是同一台ce。实现双规,甚至多归组网的发现。pe发送的类型1路由给rr,经rr反射后,pe1-3就能知道我们连接的是同一台ce。即:除了本端pe能够通过类型1的路由彼此知道连着同一个站点,对端pe4也能够知道他们3连接同一个站点
类型1的 路由,可以用来告诉pe对端pe所连接的站点的信息
Ethernet tag id用来描述pe和ce之间能够放行的vlan id

类似mstp(生成树)。先在pe上创建evpn实例,这个实例和某些vlan进行绑定,如vlan100/200都属于实例A,用来描述哪一些vlan和bd域是关联在一起的。
这里的Mpls label是二层vni
类型1路由里最重要的就是esi,其他看看就行。用于实现水平分割,快速收敛和别名,对转发没有帮助,双发才会用到。
看一下类型1路由如何进行防环
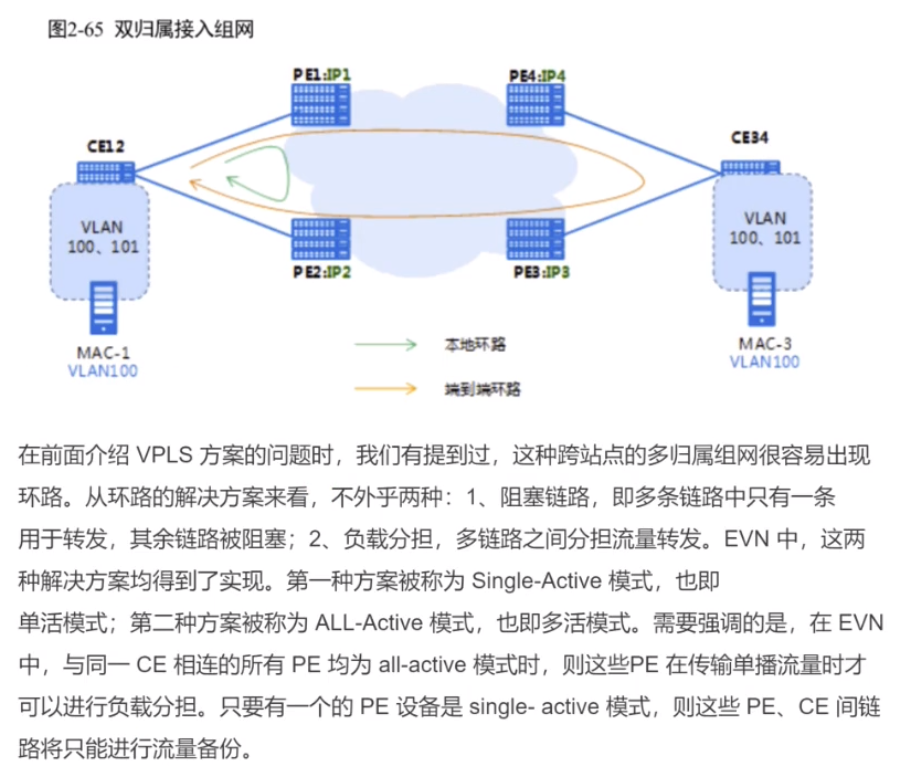
这里使用evpn或evn来实现双规组网,主要解决双归情况下的环路问题。Ce1连着两台pe,骨干网设备上都有用来建立vxlan隧道的vtep地址。通过阻塞来防止ce的本端环路(绿色),通过阻塞也能防止出现黄色线经过远端在绕回来的环路,此方案对带宽利用率低。方案2,同时可以防止本端和远端环路。上述的功能实现就要依靠1类和4类
在这种单归场景下,只要通告类型3的路由来建立隧道,通过类型2 的路由来传递站点间的mac地址,就能实现二层的数据单播转发。在这种但单归场景下,即便发了类型1和4的路由,也不会起到任何作用。
只有在双规场景下,通过传递类型1和类型4的路由来解决环路和流量的控制和网络收敛问题。
evpn也能用到类型1和4,只不过华为dc的解决方案没提出双规的场景,就没用到这两种路由。
第二种方式,所有pe都应该是all-active

上图的evn也可以理解为evpn,s-a(single active)模式进化为类似mstp 针对vlan来阻塞链路

流量在df(designate forwarding)之间传递,但部分链路资源是被浪费了。在mstp中,pe1可以成为ins 1的root,pe2可以成为ins2 的root,流量就能同时走两个链路。
Single-active算法
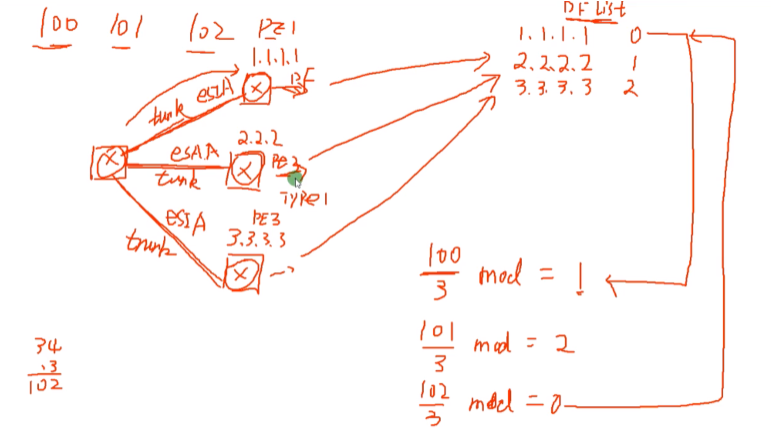
ce连接3台pe,这三条链路都可以传输vlan100.101和102的流量。每个pe都有ip地址用来建立vxlan隧道。在多归的场景中,3个pe-ce互联链路(esi)都要配置成相同的,代表pe群连接同一个站点 。三台pe通过互相通告的类型1 的路由就能知道他们都是连接ce的,此时每台pe就会以ip地址大小作为排列依据,从小到大把这三台pe的地址放到df列表中(就类似通告lsa,然后同步完之后进行计算)。并从0开始编号。则每台pe都有这样的一个相同的df列表。
以pe1为例,将其能通过的三个vlan(vlan号),除以df列表中df的数量,如100/3 mod=1,将这个余数1和自己的变化0对比,不一样,我就不能作为这个vlan的df,不会转发vlan 100的报文;vlan 101/3 mod=2,查编号还是不匹配,也不能做其df。102/3 mod 0 ,编号匹配,可以作为vlan102的df,未来vlan 102 的流量到达,就可以通过这里出去。同理pe2和3都能计算出自己是哪个vlan的df。各pe只转发经过算法计算出来和自己编号相同的vlan的流量,称为主df,其他称为备df。假如对端还存在pe4,pe间通过pe间交互的类型1 的路由,pe4也能计算出pe1-3是组成一个冗余组、对端pe n是vlan n的df(因为大家都用df列表,pe4虽然不参与,但是我可以计算。即整个网络都能知道df的选举结果-类型1路由的作用)

对应文档上的算法
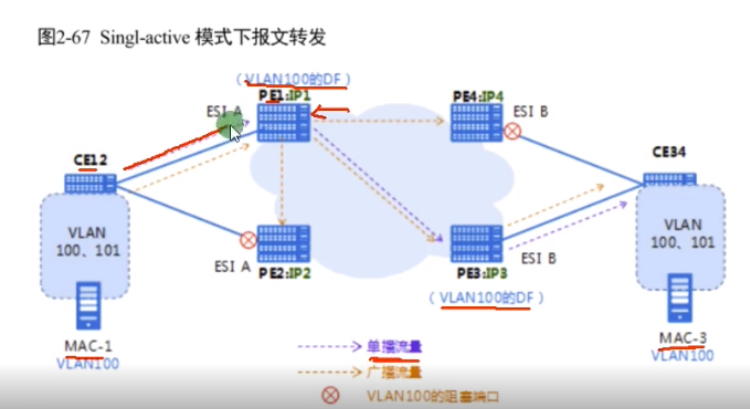
双规组网,pe1和2组成一个冗余组,pe3和4组成一个冗余组。因为配置的esi相同。现在有两个vlan要进行同vlan跨dc的互访-evn强项(evpn也可以实现这种二层互访)

Ip1<ip 2,得出结果pe1的编号是0,pe2的编号是1。经过算法计算,pe1称为vlan 100的主df,因为通过类型1的路由传递,pe3和4会知道pe1是vlan 100的主df。同理,右侧经过计算,pe3是vlan100的主df。两边vlan 100 的主df完成选举之后。以单播为例,因为都知道df是谁,pe1就通过vxlan隧道把报文发给pe3。
思考题
1.是无法通告mac地址路由。pe2不会学习mac-1,不学就不会产生类型2的路由,evpn peer就不知道通过你可以到达mac-1。即ce12上vlan 100的流量通过pe2走,不提供转发,阻塞。
ex pc发送了一个广播(arp),按道理讲ce12要进行泛洪,但只有主df才学习mac-1并通告mac地址路由,备df不会学(df是针对vlan的)
防环:
针对单播报文,不会有环路,单播报文是根据mac地址表走的。报文到达ce12会根据mac地址表送给主df,主df根据之前接收到的mac地址路由,找到另一边的主 df,建立vxlan隧道,传递流量。
针对bum报文,要进行头端复制
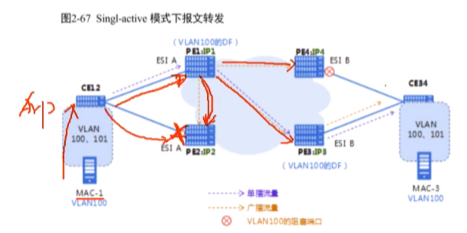

Pe1的头端复制行为,不会造成环路(因为pe2左侧接口的vlan100已经阻塞了),所以广播只会到pe3
Single-active模式并不是这条链路针对所有vlan都阻塞,而是可以针对vlan来选择路径,来做单活(类似mstp)
evn中的所有pe设备不支持流量解封装后再封装-水平分割。Pe1封装的到达pe2了,不能在pe2解封装之后再封装发给pe3。即pe接收到的vxlan报文,不能再发送给其他pe
df故障的举例
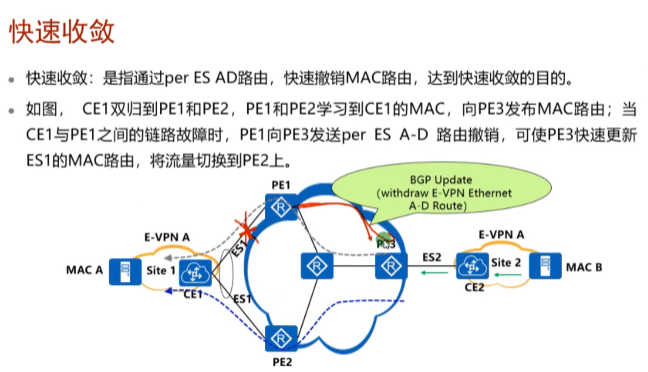
一台df挂了,剩下的会重新进行df的计算。Df-df建立这个vlan的vxlan隧道,如何实现网络的快速收敛

Pe2不学习mac-1,但是会向evpn peer间通告类型1的路由(不发类型2 的),主df要同时发送类型1 的路由和mac地址路由。Pe3通过这两台df通告的类型1路由中的esi就能知道其是连接到同一个ce
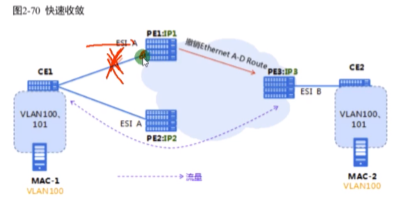

出现故障时,pe1上接口学到的mac地址(ex学到了1000条)已经没有了。在evpn协议中,是通过类型2的路由,通告了 ce背后vm的mac地址。路由不可达时不需要向bgp一样,需要通告10000条路由不可达信息。Pe1只需要告知pe3我不和ce1相连接了-只发撤销以太网ad路由。(通过通告类型1的路由,来撤销路由)Pe3就知道pe1不在和ce1相连,会直接把从pe1学到的类型2 路由删掉-不需要pe1通过类型2的路由让其删掉(在双规场景中,不需要删除,因为通过pe2也可以到达d,只需更改路由的nh)。可以提高路由收敛的速度。原来要1000条类型2才能删除的mac地址信息,现在1条类型1的就可以了。//pe1和ce1连线断了后,pe2应该会重新计算,成为主df,通告类型1和类型2的路由

类型2 的路由已经关联了esi(便于撤销路由),如果其他nve告知我这个我和这个esi没有关系了,那在local就可以把从这个vtep学到的和这个esi相连的mac地址全部删掉。类型3的路由就没有关联esi。
因为之前pe2已经通过类型1 的路由告知其peer,我和这个esi连着,pe3上的这1000条mac不需要删除,只需要更改vxlan隧道nh为pe2就行了,提高收敛速度。双规场景,mac地址不需要删除。单归需要删除。
单活的防环,搞清楚备df的特点:1.从用户侧学到的mac地址不通告出去,但是通告自己的类型1路由中的esi-为了实现快速收敛。2.收到不是自己作为主df的vlan数据帧,不从这个接口(阻塞的)转发出去。
多活模式
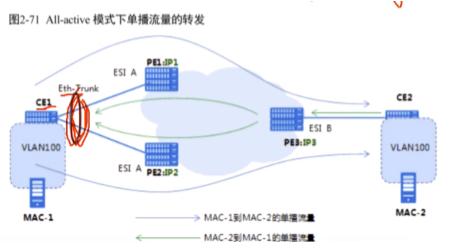


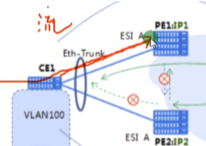
lacp不能进行跨设备的链路聚合,这里的捆绑有两种解决方案:1.m-lag(ce系列sw叫这个)。对ce1来说两条路,一个逻辑接口;2.e-trunk(只不过是s系列将m-lag技术称为了e-trunk(没有th))。这两种都叫跨框的链路聚合。
多活需要,在Ce1上的两个接口需要配置跨框链路聚合,是一个逻辑接口。而在单活模式,这两个接口就是独立的物理口。多活模式也会进行df选举,但是选举结果的应用不同。
单播是指mac地址已知的流量。Ce1上的mac地址表学习mac-2的地址,对应的mac地址表项的出口是逻辑e-trunk接口(不是物理接口)。在多活场景下,不管是否是这个vlan的主df,收到这个vlan的数据都会转发-因为单播流量不存在环路的风险。单播流量从ce1上看不是向上走pe1就是向下走pe2,流量到达pe1和2交给pe3就行了,就不需要基于单播进行阻塞。(在单活模式下阻塞:如果ce2发广播,分别从pe1和pe2泛洪到ce1,会导致这两个物理接口学到的mac震荡。而多活的模式对应的是一个逻辑接口,不会存在mac地址不稳定。Ce1直接根据hash算法来决定发给谁)
上图pe3形成mac-1的等价路由,即vxlan路由的ecmp
Pe1和pe2都会通告类mac-1的类型2的路由给pe3,pe3针对mac-1就能够学到等价负载的路由,在pe3回包时就能根据这两个地址进行等价负载分担
多活:通告单播走vlan 100的流量,ce1和pe之间的两条链路都能走,无环。关键就在ce1上的m-lag,组成了一个逻辑接口
针对bum流量
pc发一个广播,ce1只会泛洪给一台pe(因为其和pe互联的是一个逻辑口),广播(bum)会根据负载分担算法,要么发给pe1,要么发给pe2,不会复制两份的(这是一个逻辑接口)

evpn(evn也是)的水平分割,即主备df之间不能相互复制bum报文。bum报文到达vlan 100的主df,其要进行头端复制,备df收到后不会转发给用户侧(主df行为也相同)//应该是把备df从头端复制列表中踢出,right,细看上图
而在ce2发送的bum流量到达pe3,pe3发现pe1和pe2均存在域vlan 100的bum转发表,头端复制发给这俩,就可能造成ce1收到重复的2份组播流量?解决见上图(细见上图)
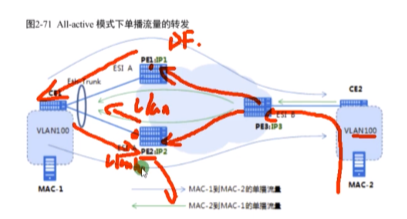
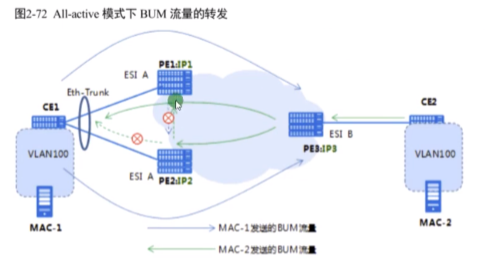
主df解封装右侧来的bum报文并泛洪给下面,pe2不是vlan100的主 df,就不解封装。把这个接口的下行退出vlan100(pe2-ce1方向),上行接收vlan100(ce1-pe2方向)
完美解决了环路问题,以环路为例:
Mac-1发送广播,根据hash算法,pe1收到或者pe2收到(上行未阻塞),但由于两个pe之间互相把彼此从头端复制列表中删除了,所以本端的广播不会在绕回本端,只会向远端进行头端复制。此时mac-2发送bum,pe3要复制发给pe1和2,这个vlan的主df负责解封装,而备df阻塞下行vlan 100的bum报文,就不会有环路了。
上图灰线是错误的
水平分割:让两台pe知道自己连接同一个esi。要根据是单活和多活两种场景来理解。多活:主df不会将bum报文发给备df(反之相同)。单活:对应vlan在备df直接被阻塞。
本质就是通过类型1 的路由,让pe群知道我们都是连接在同一台ce上,然后在根据单活或多活模式来实现相应的防环机制。
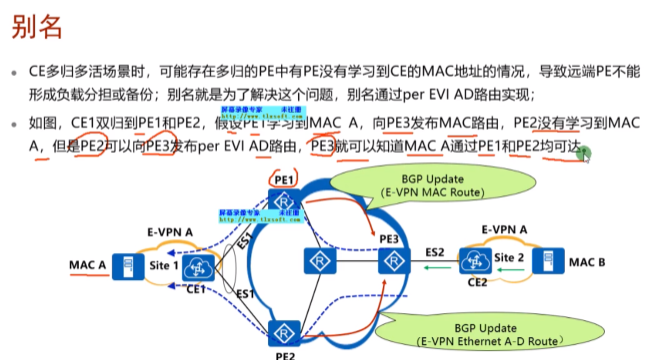
别名就是,即便pe2不向pe3通告mac-a的路由,但pe3仍然知道通过pe2可以到达mac a -就为了提高路由的收敛速度
负载分担是基于流的,同一个流的数据帧只会走一个方向,如上面。双活场景中,导致只有pe1可以学到mac-a,pe3回包时只能走pe1,导致双活链路失去了一条链路。而通过ad路由。Pe3知道这个mac-a通过pe2也可以到,在pe3进行回包时可以进行双活回包。但是pe2没学到mac-a,我怎么回包呢?发送arp请求?check
别名,在双活的场景下可以让回包更好的利用带宽资源。
vxlan完结
-------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号