事件循环
事件循环与浏览器有关,需要先了解其进程模型。
浏览器的进程模型
进程
程序运行需要其专属的内存空间,用于存储变量、执行函数等操作,可以将这块内存空间简单地理解为进程。
每个应用至少有一个进程,进程之间相互独立,即使要通信,也需要双方同意。
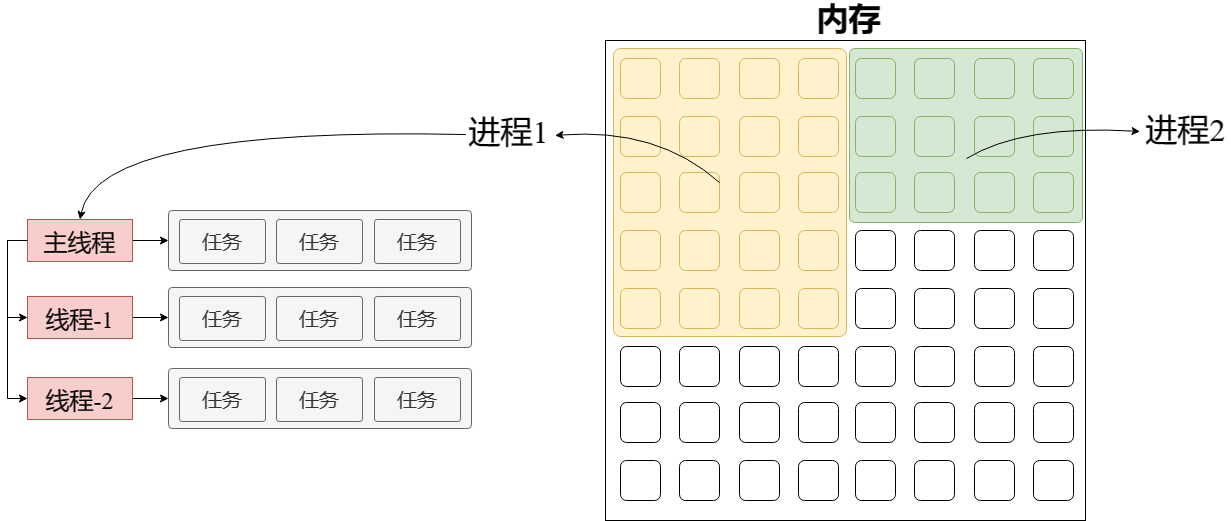
线程
有了进程后,就可以运行程序的代码了,由线程运行代码。
一个进程至少有一个线程,在进程开启后会自动创建一个线程来执行代码,称为主线程。
如果主线程结束了,那么进程就结束了。
如果程序需要同时执行多块代码,主线程就会启动更多的线程来执行代码,所以一个进程中可以包含多个线程。
浏览器的进程和线程
浏览器是一个多进程多线程的应用程序。
为了避免相互影响,为了减少连环崩溃的几率,当启动浏览器后,它会自动启动多个进程。
现代浏览器已经非常复杂了,复杂程度在向操作系统靠近。
启动chrome浏览器,打开其任务管理器:
可以发现尽管没有访问任何网页,也有一些进程是自动启动的。
打开一个新的标签页,这里打开了百度,可以发现不同的标签页属于不同的进程。
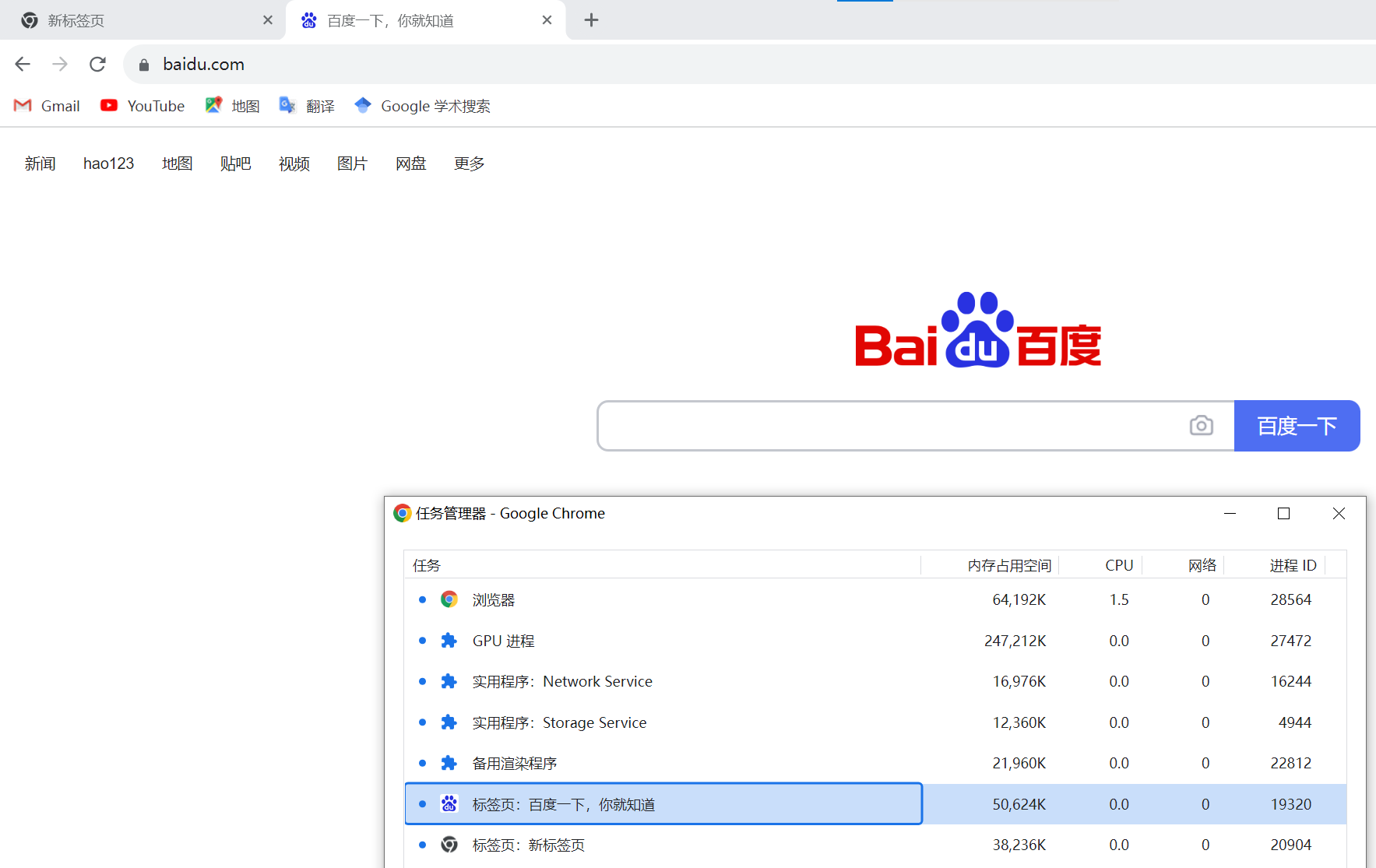
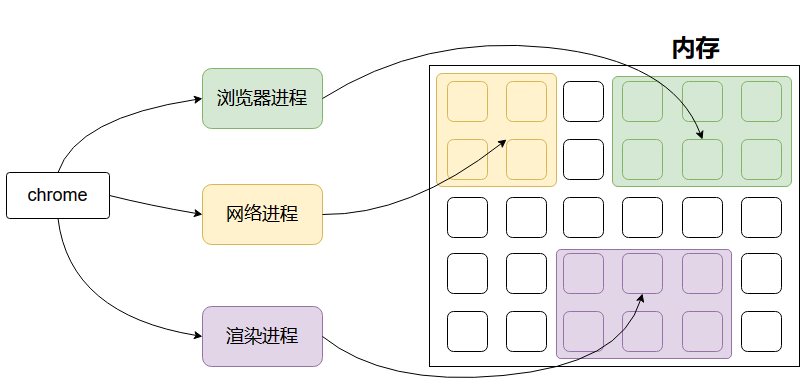
其中,最主要的进程有:
-
浏览器进程
浏览器进程是最先启动的进程,其它进程由它启动。
主要负责界面显示、用户交互、子进程管理等。浏览器进程内部会启动多个线程处理不同的任务。
这里的界面显示不是指网页的内容渲染,而是指浏览器的界面,比如浏览器的头部:

用户交互是指用户在浏览器上的点击、键盘、滚轮等操作,浏览器需要监听这些用户交互操作。
子进程管理包含网络进程、渲染进程等等。
-
网络进程
负责加载网络资源。网络进程内部会启动多个线程来处理不同的网络任务。
-
渲染进程
渲染进程启动后,会开启一个渲染主线程,主线程负责执行HTML、CSS、JS代码。
默认情况下,浏览器会为每个标签页开启一个新的渲染进程,以保证不同的标签页之间不相互影响。
这种模式可能会在以后的版本被替换掉,因为每个标签页都开启一个新渲染进程会导致chrome成为“内存杀手”。——2023.10
Chromium Docs - Process Model and Site Isolation (googlesource.com)
👆这个文档提到了,以后可能会发展成“一个站点对应一个进程”。
例如:用户在使用淘宝的时候,首先打开了淘宝首页,然后搜索商品进入了商品搜索页,点击商品进入商品详情页,尽管有三个标签页,但是都是同一站点,只对应一个进程。
当然,这是以后的发展规划,了解即可。
关于浏览器的进程模型就介绍到这里,本文主要是写事件循环,而事件循环就发生在渲染主线程中。
渲染主线程
渲染主线程是浏览器中最繁忙的线程,需要它处理的任务包括但不限于:
- 解析HTML:比如解析标记语言的语法。
- 解析CSS:比如解析样式表的语法。
- 计算样式:比如将
em,%等单位换算成px,以及重复的属性如何考虑其优先级等等。 - 布局:每个元素的宽高、位置,都需要计算,统称为几何信息。
- 处理图层:与
z-index有关,也和元素的内容与其background的绘制有关。 - 每秒把页面绘制60次:FPS
- 执行全局JS代码
- 执行事件处理函数
- 执行计时器的回调函数
- ......
为什么渲染进程不适用多个线程来处理这些事情?
答:
浏览器渲染进程通常是单线程的,这是因为多线程处理可能会引发很多问题。以下是一些可能的问题:
竞态条件:多线程处理会导致访问共享内存的竞争条件,可能导致数据不一致和死锁等问题。
同步问题:多线程需要进行同步,避免数据竞争和死锁,这会增加代码的复杂度和开销。
安全问题:多线程可能会存在安全漏洞,如数据泄露、内存溢出等问题。
性能问题:多线程处理可能会导致过多的上下文切换和内存消耗,从而降低程序的性能和稳定性。相比之下,单线程处理有以下优点:
简单易用:单线程的处理方式更加简单易用,开发人员不需要考虑多线程处理中的竞态条件、同步问题和安全问题。
可靠稳定:单线程处理避免了多线程处理中的死锁和资源争用等问题,从而提高了程序的可靠性和稳定性。
高效节省:单线程处理可以避免多线程处理中的上下文切换和内存消耗等问题,从而提高了程序的性能和节省了系统资源。
既然主线程非常繁忙,那么首先需要解决的问题就是:应该如何调度任务?
比如:
- 正在执行一个JS函数,执行到一半的时候用户点击了按钮,是否应该立即去执行点击事件的处理函数?
- 正在执行一个JS函数,执行到一半的时候某个计时器到达了时间,是否应该立即去执行其回调?
- 当“用户点击事件”,与“计时器到达时间”同时发生,应该先处理哪个任务?
- ......
渲染主线程的处理方式是:排队(消息队列 Message queue)。
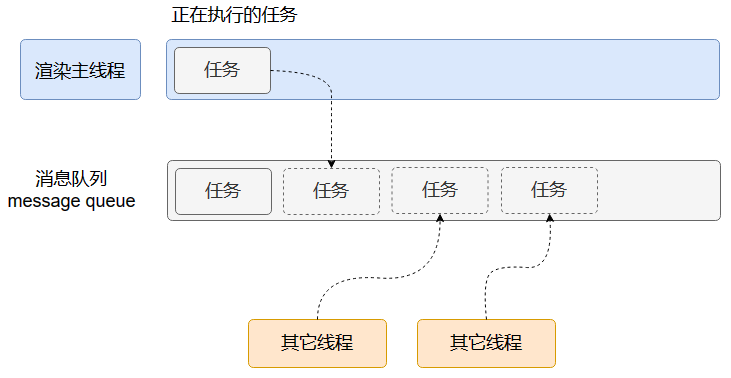
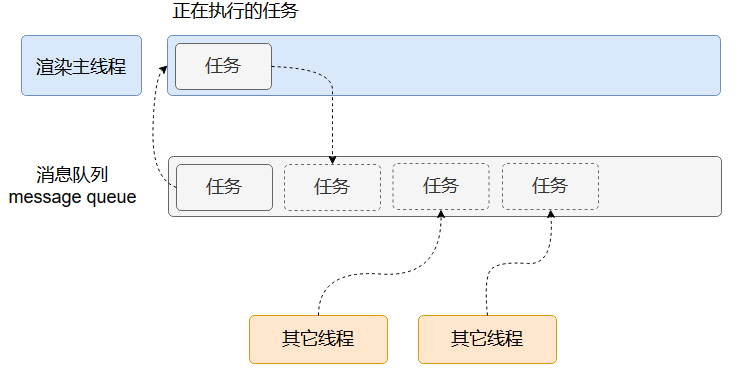
-
在最开始的时候,渲染主线程会进入一个无限循环;
可以在github上找到chromium的源码,在消息队列的相关实现代码中可以看到一个无限循环:
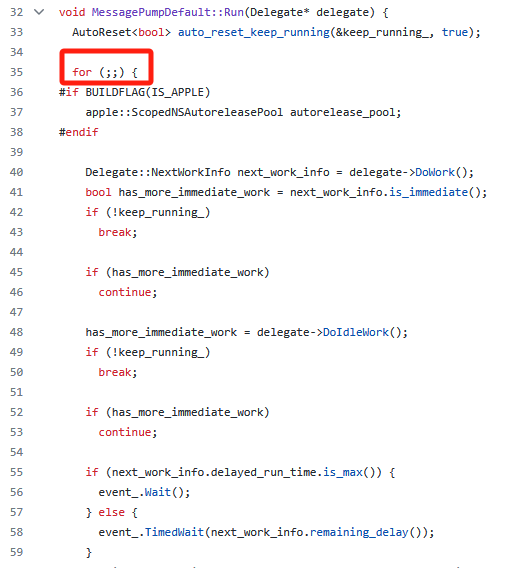
chromium和chrome的关系:
- chrome是基于chromium的、功能更丰富的浏览器;
- chrome不开源,chromium开源。
- 每一次循环会检查消息队列中是否有任务存在。
- 如果有,就取出第一个任务执行,执行完一个后进入下一次循环;
- 如果没有,则进入休眠状态。
- 其它所有线程(包括其它进程的线程)可以随时向消息队列添加任务。新任务会加到消息队列的末尾。在添加新任务时,如果主线程是休眠状态,则会将其唤醒以继续循环拿取任务。
这样一来,就可以让每个任务有条不紊地、持续地进行下去了。
整个过程,被称之为事件循环(消息循环)。
- 在w3c的标准中被称为:
event loop事件循环 - 在google的标准中被称为:
message loop消息循环
回过头来看上文提到的一个问题:
正在执行一个JS函数,执行到一半的时候用户点击了按钮,是否应该立即去执行点击事件的处理函数?
答:此时应该将点击事件的处理函数推到消息队列中,不影响JS函数的执行。
相关问题
异步是什么?
代码在执行过程中,会遇到一些无法理解处理的任务,比如:
- 计时完成后需要执行的任务——
setTimeout、setInterval - 网络通信完成后需要执行的任务——
XHR、Fetch - 用户操作后需要执行的任务——
addEventListener
如果让渲染主线程等待这些任务的时机到达,就会导致主线程长期处于阻塞的状态,从而导致浏览器卡死。
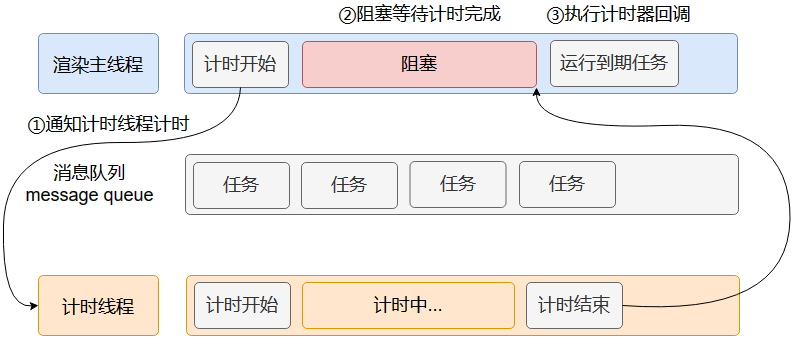
如上图,在主线程中使用setTimeout(fn, 3000)将回调函数与计时时长告知计时线程,计时线程开始计时等待。
此时,如果主线程跟随一起等待,则是同步,唯一的好处是时间线同步,但是好处远远小于坏处,非常浪费时间。
计时线程的底层实现其实是调用了操作系统提供的接口。其实现十分复杂。
渲染主线程承担着极其重要的工作,无论如何都不能阻塞。
如果因为上述三种任务阻塞了主线程,那么消息队列中可能存在着渲染任务无法执行,也可能用户触发了点击事件,但是没有被执行,从用户角度来说就是“页面卡死了”。
因此,浏览器选择了异步来解决这个问题。
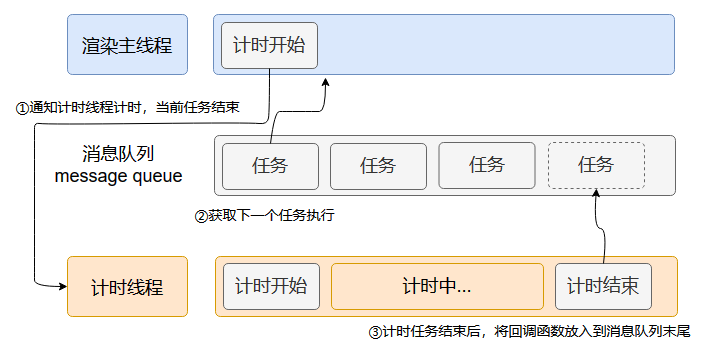
如上图,主线程在调用了setTimeout之后,其实只是起到了一个预约的作用,最后是由计时线程将任务交给消息队列。
使用异步的方式,渲染主线程不会阻塞,不断地拿取消息队列里的任务去执行,遇到计时器、网络请求、事件监听,则交给其它线程,渲染主线程从消息队列中获取下一个任务继续工作。
面试题:如何理解JS的异步?
参考答案:
JS是一门单线程的语言,这是因为它运行在浏览器的渲染主线程中,而渲染主线程只有一个。
而渲染主线程承担着诸多的工作,渲染页面、执行JS都在其中运行。
如果使用同步的方式,就极有可能导致主线程产生阻塞,从而导致消息队列中的很多其他任务无法得到执行。
这样一来,一方面会导致繁忙的主线程白白的消耗时间,另一方面导致页面无法及时更新,给用户造成卡死现象。
所以浏览器采用异步的方式来避免。具体做法是当某些任务发生时,比如计时器、网络、事件监听,主线程将任务交给其他线程去处理,自身立即结束任务的执行,转而执行后续代码。当其他线程完成时,将事先传递的回调函数包装成任务,加入到消息队列的未尾排队,等待主线程调度执行。
在这种异步模式下,浏览器永不阻塞,从而最大限度的保证了单线程的流畅运行。
JS为何会阻碍渲染?
首先看示例代码:
btn.onclick = function(){
// 修改DOM节点的内容
p.innerText = "hello world";
// 模拟很耗时长的JS代码,这里等了3秒
start = Date.now()
while(Date.now()-start<3000){}
}
- 错误的理解:点击按钮之后,先修改DOM节点文本,再等待3秒;
- 实际现象:点击按钮之后,会先阻塞等待3秒,然后才能看到DOM节点的文本更新。
具体的流程如下:
- 首先,主线程解析全局JS代码,解析到这一段代码的时候,检测到是事件绑定,将函数转交给交互线程。
- 交互线程监听按钮点击,当监听到按钮被点击之后,将函数包装成任务推送到消息队列尾部。
- 当其它任务被渲染主线程执行完成之后,该任务被主线程获取,执行内部的代码。
- 修改DOM节点的操作,属于绘制任务,会被包装成任务推送到消息队列尾部。
- 与此同时,上述代码的这个任务还在执行中,while语句阻塞3秒。
- 3秒之后,该任务执行完成。渲染主线程继续从消息队列中获取任务,当获取到绘制任务并执行的时候,界面才会更新。
简单的理解:
-
在浏览器上,JS解析和页面渲染都在渲染主线程上被执行,同一时间只能完成一个任务。
-
在JS中生成的渲染任务,需要JS执行完成之后才会被更新到页面上。
任务有优先级吗?
任务没有优先级,在消息队列中先进先出。但消息队列是有优先级的。
根据W3C的最新解释:
-
每个任务都有一个任务类型,同一个类型的任务必须在一个队列,不同类型的任务可以分属于相同的队列(即一个队列可以用于存放多种类型的任务)。
在一次事件循环中,浏览器可以根据实际情况从不同的队列中取出任务执行。不同浏览器或者同一浏览器的不同版本的做法可能不同。
在chromium的源码中,我们可以找到👉task_type.h,其中声明了许多任务类型:

-
浏览器必须准备好一个微队列(microtask queue),微队列中的任务优先所有其它任务执行。
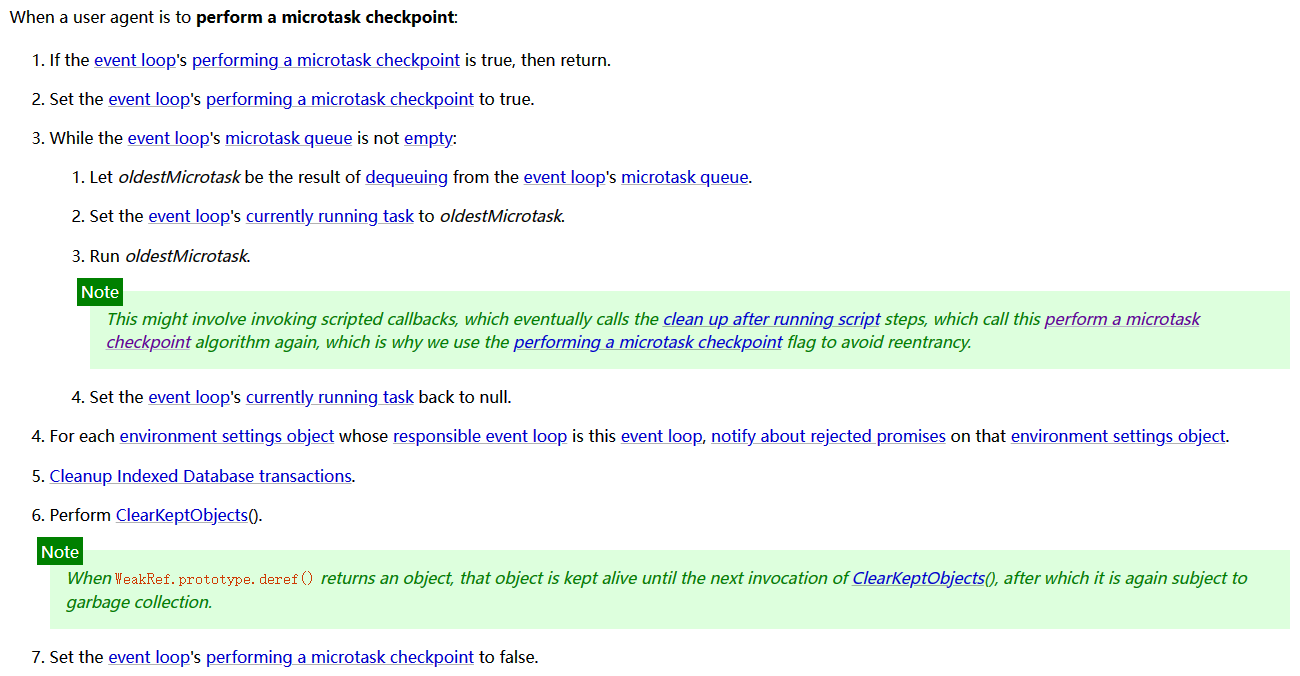
随着浏览器的复杂度急剧提升,W3C不再使用宏队列的说法。
在目前chrome的实现中,至少包含了下面的队列:
- 延时队列:用于存放计时器到达后的回调任务,优先级中;
- 交互队列:用于存放用户操作后产生的事件处理任务,优先级高;
- 微队列:用户存放需要最快执行的任务,优先级最高。
添加任务到微队列的主要方式主要是使用
Promise、MutationObserver例如:
// 立即把一个函数添加到微队列 Promise.resolve().then(函数)
浏览器还有很多其它的队列,与前端的开发关系不大。
面试题:阐述一下 JS 的事件循环
参考答案:
事件循环又叫做消息循环,是浏览器渲染主线程的工作方式。
在 Chrome 的源码中,它开启一个不会结束的for循环,每次循环从消息队列中取出第一个任务执行,而其他线程只需要在合适的时候将任务加入到队列未尾即可。
过去把消息队列简单分为宏队列和微队列,这种说法目前已无法满足复杂的浏览器环境,取而代之的是一种更加灵活多变的处理方式。
根据W3C官方的解释,每个任务有不同的类型,同类型的任务必须在同一个队列,不同的任务可以属于相同的队列。不同任务队列有不同的优先级,在一次事件循环中,由浏览器自行决定取哪一个队列的任务。但浏览器必须有一个微队列,微队列的任务一定具有最高的优先级,必须优先调度执行。
面试题:JS 中的计时器能做到精准计时吗?为什么?
参考答案:
不行,因为:
- 计算机硬件没有原子钟,无法做到精确计时;
- 操作系统的计时函数本身就有少量偏差,由于 JS 的计时器最终调用的是操作系统的函数,也就携带了这些偏差;
- 按照W3C的标准,浏览器实现计时器时,如果嵌套层级超过5层,则会带有4毫秒的最少时间,这样在计时时间少于4毫秒时又带来了偏差;
- 受事件循环的影响,计时器的回调函数只能在主线程空闲时运行,因此又带来了偏差。
补充:
-
setTimeout和setInterval的最终实现调用的操作系统的API,不同的操作系统的实现不同。 -
setTimeout嵌套层级(5层)与4毫秒的知识点:在chromium关于计时器的源码中可以找到:
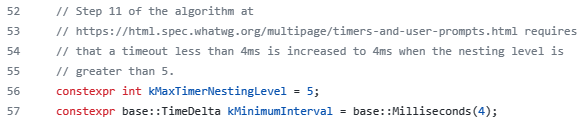
根据w3c的标准,当嵌套层级超过五层,定时器的时间如果低于4ms,会被提升至4ms。
例题
可以在草稿纸上写下渲染主线程、微队列、延时队列,并模拟任务在其中的变化。
例题1:下述代码的输出顺序是?
function a(){
console.log(1);
Promise.resolve().then(function(){
console.log(2);
});
}
setTimeout(function(){
console.log(3);
Promise.resolve().then(a);
}, 0);
Promise.resolve().then(function(){
console.log(4);
});
console.log(5);
例题 1 答案:
5
4
3
1
2
例题2:下述代码的输出顺序是?
function a(){
console.log(1);
Promise.resolve().then(function{
console.log(2);
});
}
setTimeout(function(){
console.log(3);
}, 0);
Promise.resolve().then(a);
console.log(5);
例题 2 答案:
5
1
2
3
总结
- 单线程是异步产生的原因;
- 事件循环是异步的实现方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号