
一致性hash算法
提出问题
为了防止数据直接访问MySQL导致访问速度变慢,我们需要将数据放在缓存中,当数据量过大时,我们就需要将数据进行平均分配,也就是使用分布式集群机制将数据分开存储。
解决问题
假设我们有三台缓存服务器用于平均分配数据,平均的算法为 请求值取hash值除2取模,这样就能平均分配到两台不同的缓存服务器上了。
但是如果新添加一台服务器,那么就要改变平均的算法了,请求值取hash值除3取模,但是有一些问题,我之前存放的数据的计算结果值为1,但是算法进行了改变,那么重新访问的值为2,那么就无法访问到结果,这是就要进行数据重构,但是这个操作很麻烦,需要消耗很多时间。
一致性hash就能较好的解决这个问题,我们可以把所有的数据节点,都放到一个环内,然后把缓存服务器按照hash值也存放在一个环内,这样添加新的缓存节点,也不需要进行重构,只需要交换一个节点的数据就好了。
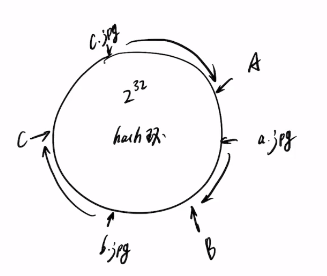
但是仍然存在一个问题,这个环会导致hash倾斜,有一大部分数据放置在一个缓存服务器中,只有一小部分存放在另一个缓存服务器中。
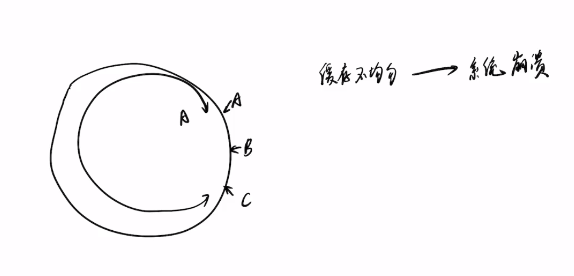
我们可以通过设置虚拟节点来解决这个问题,设置一个节点的虚拟节点,使这个环更加平均分配数据。
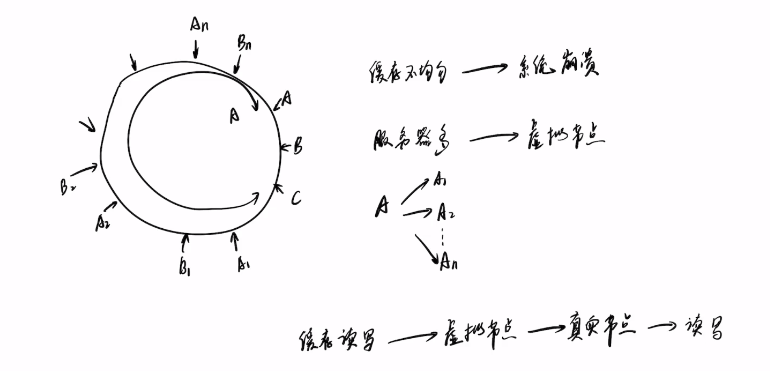
应用场景
redis集群的新增redis数据库 https://www.cnblogs.com/FengGeBlog/p/10615345.html
nginx的负载均衡 https://blog.csdn.net/huzilinitachi/article/details/79615596
