

爱词霸 每日一词爬取
要爬取的目标网站是金山词霸的每日一句栏目
本人热衷英语学习,同时觉得其使用的图片以后可以当做素材,作为一个什么限制也没有的基础网站,学习爬虫的初学者拿这个网站试手就很好。
本次爬虫所要爬取的内容包括每日一句的英文,翻译,以及对应的图片。
创建工程
scrapy startproject iciba
生成spider文件
scrapy genspider IcibaSpider news.iciba.com/views/dailysentence/daily.html#!/detail/title/2019-06-04
分析链接
http://news.iciba.com/views/dailysentence/daily.html#!/detail/title/2019-06-04
1.url分析 连接的开头是http://news.iciba.com/views/dailysentence/daily.html#!/detail/title/ 后面加上YYYY-MM-DD格式的日期
2.网站内容分析 发现整个tab都在 class="detail-content"的div下面
打开cmd
使用scrapy shell http://news.iciba.com/views/dailysentence/daily.html#!/detail/title/2019-06-04
response.body.decode('utf8') 查看下整个页面的返回内容
发现没有我们想要的数据。
不服气啊,再看看标签detail-content下面的数据
response.xpath('//div[@class="detail-content"]').extract()
一堆杂毛数据,确实没有我们想要的,换个思路。
3.查看网页请求,按F12监控其network请求
找找js下面的内容
发现下面这个js携带了我们需要的数据
index.php?callback=jQuery190013302076789326667_1559638506130&c=dailysentence&m=getTodaySentence&_=1559638506134 HTTP/1.1
赶紧搞出来看看
把请求的url从head里面摘取出来,得到下面的链接
http://sentence.iciba.com/index.php?callback=jQuery190013302076789326667_1559638506130&c=dailysentence&m=getTodaySentence&_=1559638506134
一脸懵逼,看不出来传参的规律。
不要急,再看看前一天的取数链接
http://sentence.iciba.com/index.php?callback=jQuery19009440094763792144_1559639303547&c=dailysentence&m=getdetail&title=2019-06-03&_=1559639303551
好像有那么点意思了哦,再看看前一天的
http://sentence.iciba.com/index.php?callback=jQuery19009440094763792144_1559639303547&c=dailysentence&m=getdetail&title=2019-06-02&_=1559639303554
规律出来了哦,去掉多余的信息,即可得到我们所要访问的目标参数
http://sentence.iciba.com/?&c=dailysentence&m=getdetail&title=2019-06-04
我们再用scrapy shell "http://sentence.iciba.com/?&c=dailysentence&m=getdetail&title=2019-06-04"
注意,这里的url要用双引号括起来
再次使用命令response.body.decode(‘utf8’)发现不能直接将转码的数据转成中文。
再分析下返回的结果,发现是个json。那就使用json类来解析
import json
json.loads(response.body.decode('utf8'),encoding='utf-8')
搞定,返回了我们想要的结果。
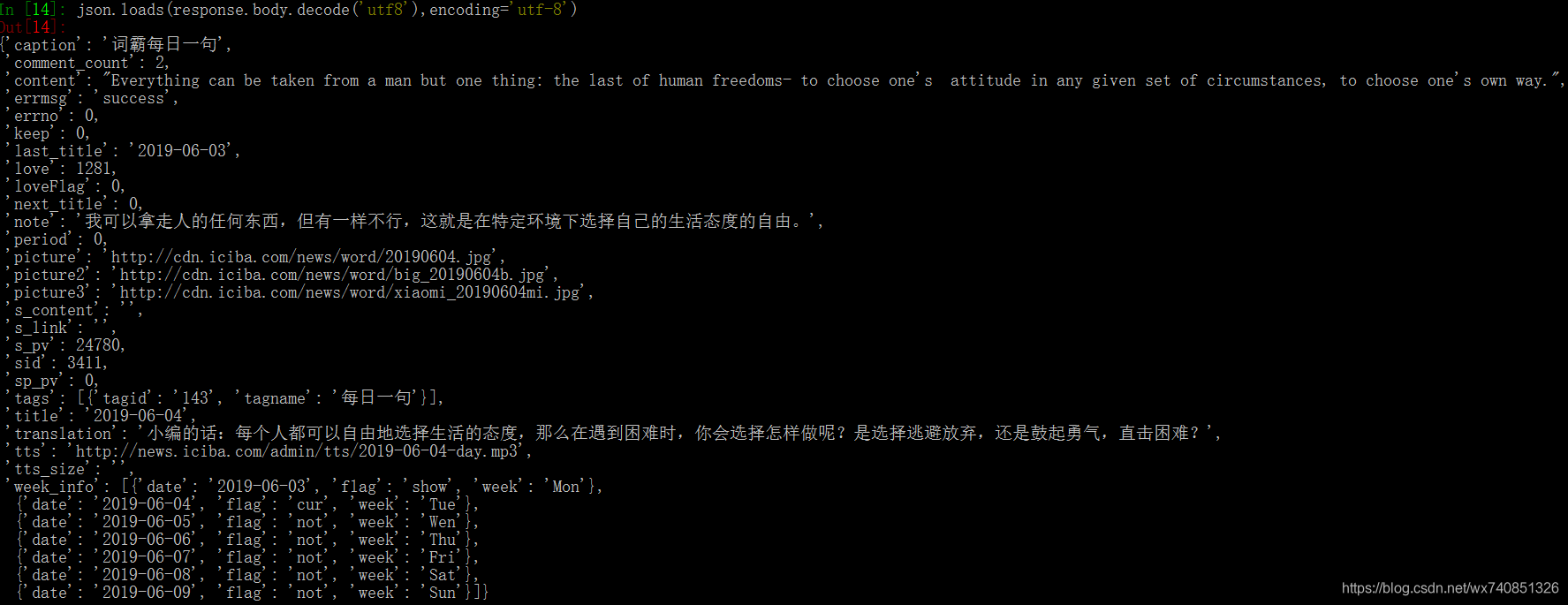
可以看到,我们想要的内容对应的key值分别为content,last_title,note,picture2,translation,title
这里的图片的链接,我们可以直接访问一下,发现picture是小图,picture2是大图,因此我们选用这个值。
所有的分析工作已经做好了,下面就开始进入pycharm,完成我们的爬虫代码把。
IcibaItem里定义好我们需要爬取的字段
content,last_title,note,picture2,translation,title
修改IcibaspiderSpider里的起始url为http://sentence.iciba.com/?&c=dailysentence&m=getdetail&title=2019-06-04
贴一下部分代码
class IcibaspiderSpider(scrapy.Spider):
name = ‘IcibaSpider’
# allowed_domains = [‘news.iciba.com/views/dailysentence/daily.html#!/detail/title/2019-06-04’]
# start_urls = [‘http://news.iciba.com/views/dailysentence/daily.html#!/detail/title/2019-06-04/’]
def start_requests(self):
start_url = 'http://sentence.iciba.com/?&c=dailysentence&m=getdetail&title=2017-12-31'
yield scrapy.Request(start_url, callback=self.parse)
def parse(self, response):
items = IcibaItem()
json_obj = json.loads(response.body.decode('utf8'),encoding='utf-8')
items['content'] = json_obj.get('content')
items['last_title'] = json_obj.get('last_title')
items['title'] = json_obj.get('title')
items['note'] = json_obj.get('note')
items['picture'] = json_obj.get('picture2')
items['translation'] = json_obj.get('translation')
last_title = items['last_title']
title = items['title']
next_url = "http://sentence.iciba.com/?&c=dailysentence&m=getdetail&title=" + last_title
if title =="2015-06-01":
pass
else:
yield items
yield scrapy.Request(url=next_url, callback=self.parse)
编写存文档的pipline和图片下载器
class IcibaPipeline(object):
# 初始化创建文件的编码格式 名称 操作关键字 字符集
def process_item(self, item, spider):
content = item['content']
title = item['title']
note = item['note']
translation = item['translation']
file = open('spider_result.txt', 'a+', encoding='utf-8')
file.write('title' + title + '\n')
file.write('content' + content + '\n')
file.write('note:' + note + '\n')
file.write('translation:' + translation + '\n')
return item
class MyImagesPipeline(ImagesPipeline):
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
def get_media_requests(self, item, info):
yield Request(item['picture'])
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
os.rename(self.IMAGES_STORE + '\\' + image_paths[0].replace('/', '\\'),
self.IMAGES_STORE + '\\full\\' + item["title"] + ".jpg")
# item['image_paths'] = self.IMAGES_STORE + '\\full\\' + item["last_title"]
return item
在cmd里运行下我们的爬虫 scrapy crawl iciba

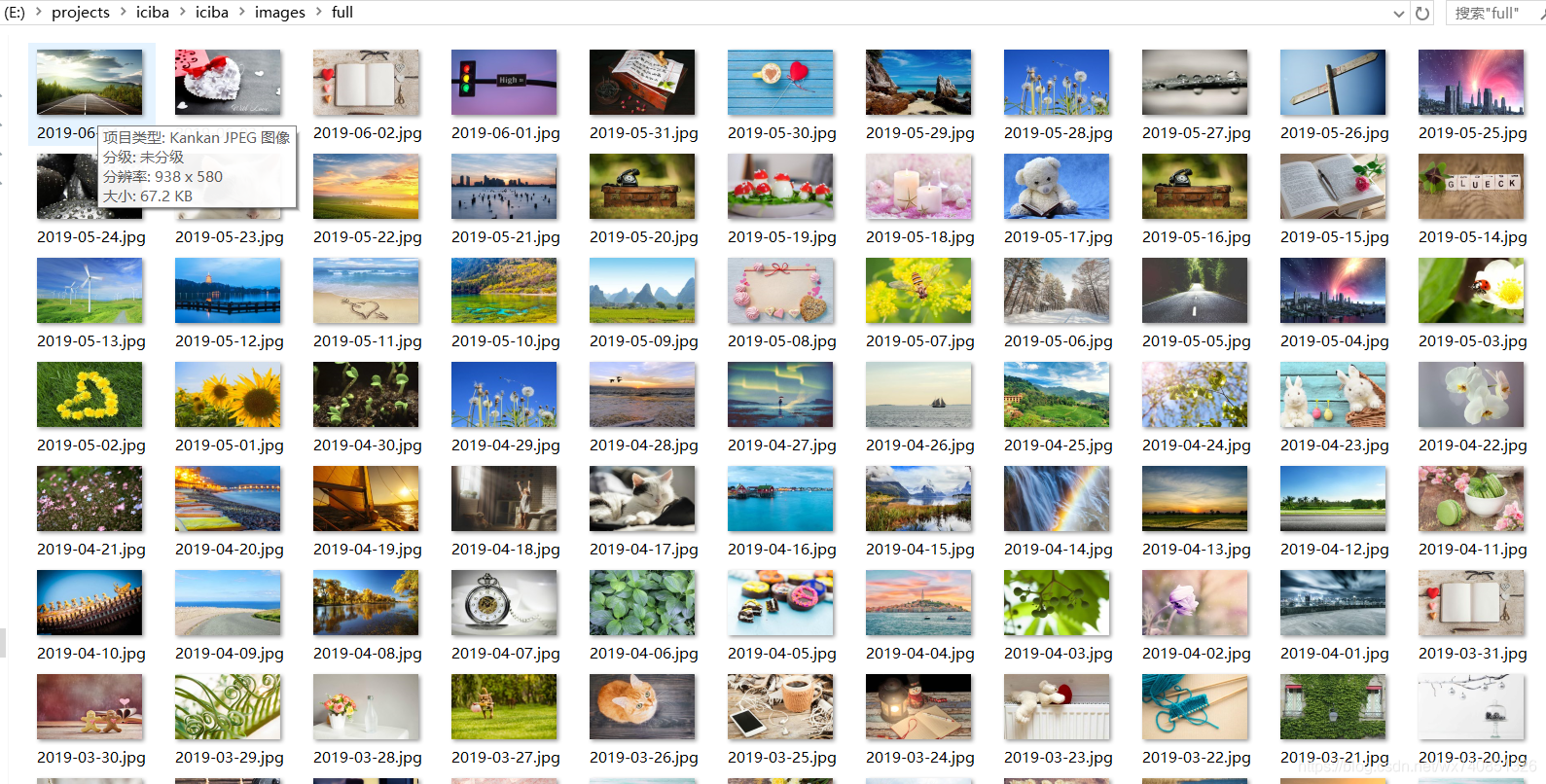
爬取完成。
这个网站的数据貌似被清理了,18年之前的每日一词数据已经没有了,所有只有几百条记录。
爬虫以爬取的网站数来评估,几百的量级仅仅是入个门。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端