
Oracle Essentials
Oracle 数据类型
| 数据类型 | 参数 | 描述 |
| char(n) | n=1 to 2000字节 | 定长字符串,n字节长,如果不指定长度,缺省为1个字节长(一个汉字为2字节) |
| varchar2(n) | n=1 to 4000字节 | 可变长的字符串,具体定义时指明最大长度n,这种数据类型可以放数字、字母以及ASCII码字符集(或者EBCDIC等数据库系统接受的字符集标准)中的所有符号。如果数据长度没有达到最大值n,Oracle 8i会根据数据大小自动调节字段长度,如果你的数据前后有空格,Oracle 8i会自动将其删去。VARCHAR2是最常用的数据类型。可做索引的最大长度3209。 |
| number(m,n) | m=1 to 38 n=-84 to 127 | 可变长的数值列,允许0、正值及负值,m是所有有效数字的位数,n是小数点以后的位数。如:number(5,2),则这个字段的最大值是99,999,如果数值超出了位数限制就会被截取多余的位数。如:number(5,2),但在一行数据中的这个字段输入575.316,则真正保存到字段中的数值是575.32。如:number(3,0),输入575.316,真正保存的数据是575。 |
| date | 无 | 从公元前4712年1月1日到公元4712年12月31日的所有合法日期, Oracle 8i其实在内部是按7个字节来保存日期数据,在定义中还包括小时、分、秒。缺省格式为DD-MON-YY,如07-11月-00 表示2000年11月7日。 |
| long | 无 | 可变长字符列,最大长度限制是2GB,用于不需要作字符串搜索的长串数据,如果要进行字符搜索就要用varchar2类型。 long是一种较老的数据类型,将来会逐渐被BLOB、CLOB、NCLOB等大的对象数据类型所取代。 |
| raw(n) | n=1 to 2000 | 可变长二进制数据,在具体定义字段的时候必须指明最大长度n,Oracle 8i用这种格式来保存较小的图形文件或带格式的文本文件,如Miceosoft Word文档。 raw是一种较老的数据类型,将来会逐渐被BLOB、CLOB、NCLOB等大的对象数据类型所取代。 |
| long raw | 无 | 可变长二进制数据,最大长度是2GB。Oracle 8i用这种格式来保存较大的图形文件或带格式的文本文件,如Miceosoft Word文档,以及音频、视频等非文本文件。在同一张表中不能同时有long类型和long raw类型,long raw也是一种较老的数据类型,将来会逐渐被BLOB、CLOB、NCLOB等大的对象数据类型所取代。 |
| blob clob nclob | 无 | 三种大型对象(LOB),用来保存较大的图形文件或带格式的文本文件,如Miceosoft Word文档,以及音频、视频等非文本文件,最大长度是4GB。 LOB有几种类型,取决于你使用的字节的类型,Oracle 8i实实在在地将这些数据存储在数据库内部保存。可以执行读取、存储、写入等特殊操作。 |
| bfile | 无 | 在数据库外部保存的大型二进制对象文件,最大长度是4GB。这种外部的LOB类型,通过数据库记录变化情况,但是数据的具体保存是在数据库外部进行的。 Oracle 8i可以读取、查询BFILE,但是不能写入。大小由操作系统决定。 |
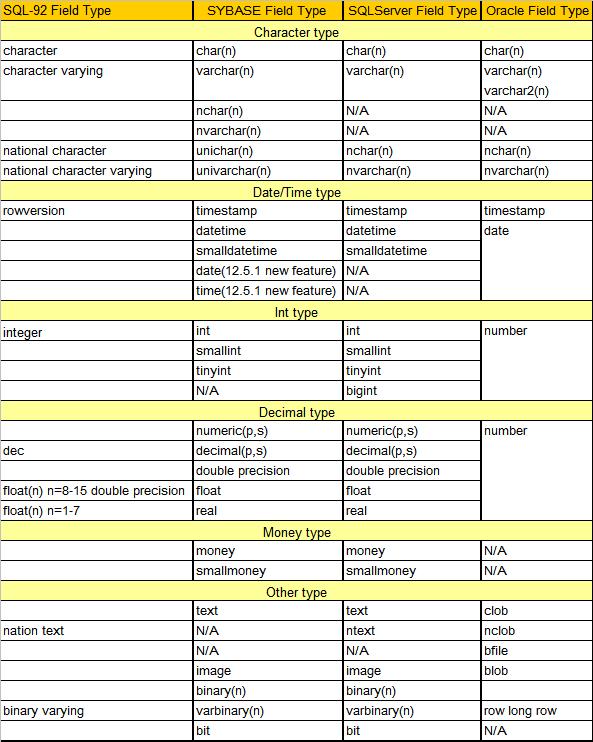
差异:
SQLServer版本为2000版本,Sybase版本为12.5.1版本,Oracle版本9.2版本
SQLServer2000的字符类型长度最大均为8K,而Sybase字符类型的最大长度与页的大小相等。
SQLServer2000 中没有unichar和univarchar字符类型;在Sybase中nchar和nvarchar代表本地语言字符集,而unichar和 univarchar代表unicode方式;而SQLServer2000中nchar和nvarchar才代表unicode方式。
SQLServer2000中新增bigint整数类型;Sybase中没有。
SQLServer2000和Sybase中都有numeric和decimal类型,这两个类型的区别在于numeric(n,0)可以用来表示identity字段,但是decimal不行。
SQLServer2000中有ntext类型;而Sybase中没有
SQLServer2000中的bit类型可以表示为0/1/NULL,而Sybase中只能为1/0两种选择
Sybase中新增date和time类型
Oracle中新增varchar2类型
Oracle中无unichar和univarchar类型,但是nchar和nvarchar表示unicode方式
Oracle中只有date类型
Oracle中的Number类型可以代替Sybase和SQLServer中的所有数字类型
.Oracle中没有货币类型
Oracle中有文件指针类型bfile
Oracle中没有bit类型
数据类型比较
|
类型名称 |
SQLServer |
比较 | |
| 字符数据类型 | CHAR | CHAR | 都是固定长度字符资料但oracle里面最大度为2kb,SQLServer里面最大长度为8kb |
| 变长字符数据类型 | VARCHAR2 | VARCHAR | Oracle里面最大长度为4kb,SQLServer里面最大长度为8kb |
| 根据字符集而定的固定长度字符串 | NCHAR | NCHAR | 前者最大长度2kb后者最大长度4kb |
| 根据字符集而定的可变长度字符串 | NVARCHAR2 | NVARCHAR | 二者最大长度都为4kb |
| 日期和时间数据类型 | DATE | 有Datetime和Smalldatetime两种 | 在oracle里面格式为DMY在SQLSerser里面可以调节,默认的为MDY |
| 数字类型 | NUMBER(P,S) | NUMERIC[P(,S)] | Oracle里面p代表小数点左面的位数,s代表小数点右面的位数。而SQLServer里面p代表小数点左右两面的位数之和,s代表小数点右面的位数。 |
| 数字类型 | DECIMAL(P,S) | DECIMAL[P(,S)] | Oracle里面p代表小数点左面的位数,s代表小数点右面的位数。而SQLServer里面p代表小数点左右两面的位数之和,s代表小数点右面的位数。 |
| 整数类型 | INTEGER | INT | 同为整数类型,存储大小都为4个字节 |
| 浮点数类型 | FLOAT | FLOAT | |
| 实数类型 | REAL | REAL |
Oracle |
SQL Server |
|
SELECT语句基本是一致的 但是有如下不同: SQL Server 不支持Oracle START WITH…CONNECT BY 语句. 你可以替换为SQLServer的一个stored procedure来做同样的工作。 Oracle 的INTERSECT and MINUS 在SQL SERVER中是不被支持的,不过可以用SQLServer的 EXISTS and NOT EXISTS 语句来完成相同的工作。 Oracle特殊的用语性能优化的cost-based optimizer hints 是不被SQL SERVER支持的,建议删除。在SQL SERVER中请用SQL SERVER的cost-based optimization。 SELECT 语法如下: | |
| Subquery [ for_update_clause] ; subquery::= SELECT [ hint ] [ ALL| DISTINCT| UNIQUE ] { * | { {expr [ [ AS ] c_alias ] | schema.{ table | view | snapshot }.*} [ ,…n ] }* FROM { < query_table_expression_clause > [ ,…n ] } [ where_clause ] [ [group_by_clause | hierarchical_query] [,…n] ] [ where_clause ] [ [group_by_clause | hierarchical_query ] […n] ] { UNION [ ALL ] | INTERSECT | MINUS } ( subquery ) ] [ order_by_clause ] query_table_expression_clause::= |
SELECT select_list[ INTO new_table ] FROM table_source [ WHERE search_condition ] [ GROUP BY group_by_expression ] [ HAVING search_condition ] [ ORDER BY order_expression [ ASC | DESC ] ] 语法 SELECT statement ::=< query_expression >[ ORDER BY { order_by_expression | column_position [ ASC | DESC ] }[ ,...n ]] [ COMPUTE{ { AVG | COUNT | MAX | MIN | SUM } ( expression ) } [ ,...n ][ BY expression [ ,...n ] ]] [ FOR { BROWSE | XML { RAW | AUTO | EXPLICIT }[ , XMLDATA ][ , ELEMENTS ][ , BINARY base64 ]} ] [ OPTION ( < query_hint > [ ,...n ]) ] < query expression > ::={ < query specification > | ( < query expression > ) }[ UNION [ ALL ] < query specification> | ( < query expression > ) [...n ] ] < query specification > ::=SELECT [ ALL | DISTINCT ][ { TOP integer | TOP integer PERCENT } [ WITH TIES ] ]< select_list >[ INTO new_table ][ FROM { < table_source > } [ ,...n ] ][ WHERE < search_condition > ][ GROUP BY [ ALL ] group_by_expression [ ,...n ][ WITH { CUBE | ROLLUP } ]][HAVING <search_condition>] |
| Insert在 ORACLE与SQL SERVER中基本是一致的,有如下的不同:
SQL SERVER的 Transact SQL language 支持 inserts into tables and views,但是不支持INSERT operations into SELECT statements,如果ORACLE中包含inserts into SELECT statements则需要改变。 SQL SERVER的Transact SQL values_list parameter 提供的 SQL-92 standard keyword DEFAULT在ORACLE中是不被支持的。 SQL SERVER中一个非常有用的Transact SQL option (EXECute procedure_name) 是用来执行一个 procedure 并将输出结果导入一个目标表或视图,但在Oracle 中是不被支持的。 INSERT 语法如下: | |
| INSERT [ hint ] INTO table_expression_clause [ (<column> [,…n] ) ] { values_clause | subquery } [,…n] ;
DML_table_expression_clause::= subquery:见SELECT语法重的subquery. with_clause::= table_collection_expression::= values_clause::= returning_clause::= |
INSERT [ INTO]{ table_name WITH ( < table_hint_limited > [ ...n ] )| view_name| rowset_function_limited} {[ ( column_list ) ]{ VALUES( { DEFAULT | NULL | expression } [ ,...n] )| derived_table| execute_statement} } | DEFAULT VALUES < table_hint_limited > ::={ FASTFIRSTROW| HOLDLOCK| PAGLOCK| READCOMMITTED| REPEATABLEREAD| ROWLOCK| SERIALIZABLE| TABLOCK| TABLOCKX| UPDLOCK } |
| DELETE和UPDATE在 ORACLE与SQL SERVER中基本是一致的 | |
| DELETE 语法: DELETE [ hint ] [ FROM ] table_expression_clause [ where_clause ] [ returning_clause ] ; DML_table_expression_clause::= subquery:见SELECT语法重的subquery. table_collection_expression::=TABLE ( collection_expression ) [ ( * ) ] where_clause::= returning_clause::= |
DELETE[ FROM ]{ table_name WITH ( < table_hint_limited > [ ...n ] ) | view_na| rowset_function_limited} [ FROM { < table_source > } [ ,...n ] ] [ WHERE{ < search_condition >| { [ CURRENT OF{ { [ GLOBAL ] cursor_name }| cursor_variable_name} ] }} ] [ OPTION ( < query_hint > [ ,...n ] ) ] < table_source > ::=table_name [ [ AS ] table_alias ] [ WITH ( < table_hint > [ ,...n ] ) ]| view_name [ [ AS ] table_alias ]| rowset_function [ [ AS ] table_alias ]| derived_table [ AS ] table_alias [ ( column_alias [ ,...n ] ) ]| < joined_table > < joined_table > ::=< table_source > < join_type > < table_source > ON < search_condition >| < table_source > CROSS JOIN < table_source >| < joined_table > < join_type > ::=[ INNER | { { LEFT | RIGHT | FULL } [OUTER] } ][ < join_hint > ] JOIN < table_hint_limited > ::={ FASTFIRSTROW | HOLDLOCK | PAGLOCK | READCOMMITTED | REPEATABLEREAD| ROWLOCK| SERIALIZABLE| TABLOCK| TABLOCKX| UPDLOCK } < table_hint > ::={ INDEX ( index_val [ ,...n ] )| FASTFIRSTROW| HOLDLOCK| NOLOCK| PAGLOCK| READCOMMITTED| READPAST| READUNCOMMITTED| REPEATABLEREAD| ROWLOCK| SERIALIZABLE| TABLOCK| TABLOCKX| UPDLOCK} < query_hint > ::={ { HASH | ORDER } GROUP| { CONCAT | HASH | MERGE } UNION| FAST number_row| FORCE ORDER| MAXDOP| ROBUST PLAN| KEEP PLAN} |
|
UPDATE 语法: UPDATE [ hint ] table_expression_clause set_clause [ where_clause ] [ returning_clause ] ; |
UPDATE{ table_name WITH ( < table_hint_limited > [ ...n ] )| view_name| rowset_function_limited} SET{ column_name = { expression | DEFAULT | NULL }| @variable = expression| @variable = column = expression } [ ,...n ] |
| DML_table_expression_clause::= { { [ schema. ] { table{ [ PARTITION ( partition ) | SUBPARTITION ( subpartition ) ] | @ dblink } } | { view | snapshot } [ @dblink ] } | ( subquery [ with_clause ] ) | table_collection_expression } [ t_alias ] subquery:见SELECT语法重的subquery. with_clause::= table_collection_expression::= set_clause::= where_clause::= returning_clause::= |
{ { [ FROM { < table_source > } [ ,...n ] ][ WHERE < search_condition > ] } [ WHERE CURRENT OF{ { [ GLOBAL ]cursor_name } | cursor_variable_name }] } [ OPTION ( < query_hint > [ ,...n ] ) ] < table_source > ::=table_name [ [ AS ] table_alias ] [ WITH ( < table_hint > [ ,...n ] ) ]| view_name [ [ AS ] table_alias ]| rowset_function [ [ AS ] table_alias ]| derived_table [ AS ] table_alias [ ( column_alias [ ,...n ] ) ]| < joined_table > < joined_table > ::=< table_source > < join_type > < table_source > ON < search_condition >| < table_source > CROSS JOIN < table_source >| < joined_table > < join_type > ::=[ INNER | { { LEFT | RIGHT | FULL } [OUTER] } ][ < join_hint > ]JOIN < table_hint_limited > ::={FASTFIRSTROW| HOLDLOCK| PAGLOCK| READCOMMITTED| REPEATABLEREAD| ROWLOCK| SERIALIZABLE| TABLOCK| TABLOCKX| UPDLOCK} < table_hint > ::={INDEX ( index_val [ ,...n ] | FASTFIRSTROW| HOLDLOCK| NOLOCK| PAGLOCK| READCOMMITTED| READPAST| READUNCOMMITTED| REPEATABLEREAD| ROWLOCK| SERIALIZABLE| TABLOCK| TABLOCKX| UPDLOCK } < query_hint > ::={{ HASH | ORDER } GROUP| { CONCAT | HASH | MERGE } UNION| {LOOP | MERGE | HASH } JOIN| FAST number_rows| FORCE ORDER| MAXDOP| ROBUST PLAN| KEEP PLAN} |
使用 Oracle .NET Framework 数据提供程序: http://msdn.microsoft.com/zh-cn/library/77d8yct7(VS.80).aspx
To be continued...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号