
PostgreSQL数据库查询——scan.l分析
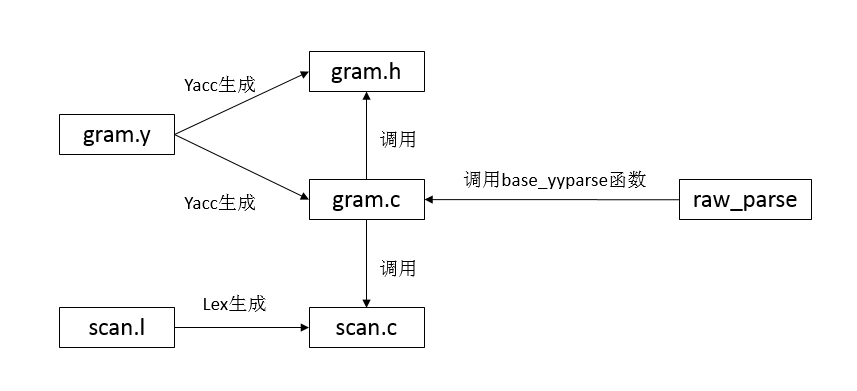
src/backend/parser/scan.l --> lexical scanner for PostgreSQL 该文件中的规则需要和psql lexer一致。Lex用来生成扫描器,其工作是识别一个一个的模式,比如数字、字符串、特殊符号等,然后将其传给Yacc。
定义段
定义段包括文字块(literal block)、定义(definition)、内部表声明(internal table declaration)、起始条件(start condition)和转换(translation)。
1 %{ 2 ... 3 #include "postgres.h" 4 #include <unistd.h> 5 #include "parser/gramparse.h" 6 #include "parser/keywords.h" 7 #include "parser/scansup.h" 8 #include "mb/pg_wchar.h" 9 ... 10 static unsigned char unescape_single_char(unsigned char c); 11 %}
定义段包含了需要引入的头文件,定义的全局变量,静态变量,声明函数,声明静态函数和宏定义。这里主要关注以下几种定义:
GUC变量。 这直接违反了gram.y开头给出的警告,即flex / bison代码不得依赖于任何GUC变量; 因此,更改其值可能会导致非常不直观的行为。 但是,我们必须将它作为短期的事情来忍受,直到完成对SQL标准字符串语法的转换为止。
1 int backslash_quote = BACKSLASH_QUOTE_SAFE_ENCODING; 2 bool escape_string_warning = true; 3 bool standard_conforming_strings = false; 4 static bool warn_on_first_escape; 5 static bool saw_non_ascii = false;
当需要多个规则来解析单个文字时,literalbuf用于累积文字值。调用startlit将缓冲区重置为空,调用addlit添加文本。 请注意,缓冲区是palloc分配的,并在每个解析周期重新开始生命。
1 static char *literalbuf; /* expandable buffer */ 2 static int literallen; /* actual current length */ 3 static int literalalloc; /* current allocated buffer size */ 4 #define startlit() (literalbuf[0] = '\0', literallen = 0) 5 static void addlit(char *ytext, int yleng); 6 static void addlitchar(unsigned char ychar); 7 static char *litbufdup(void); 8 static char *litbuf_udeescape(unsigned char escape); 9 #define lexer_errposition() scanner_errposition(yylloc) 10 static void check_escape_warning(void); 11 static void check_string_escape_warning(unsigned char ychar);
每次对yylex的调用都必须将yylloc设置为找到的标记的位置(表示为距输入文本开头的字节偏移量)。 当我们解析需要多个词法分析器规则来处理的令牌时,应在第一个此类规则中完成,否则yylloc将指向令牌的中间。
1 #define SET_YYLLOC() (yylloc = yytext - scanbuf)
处理到词法分析器内部使用的缓冲区
1 static YY_BUFFER_STATE scanbufhandle; 2 static char *scanbuf;
flex的选项(%option)影响最终生成的词法分析器的属性和行为。这些选项可以在运行flex命令时在终端输入,也可以在.l文件中使用%option指定。option的主要分类:Options for Specifying Filenames、Options Affecting Scanner Behavior、Code-Level And API Options、Options for Scanner Speed and Size、Debugging Options、Miscellaneous Options
下面说明几个常用的选项
1. Options for Specifying Filenames
--header-file=FILE,%option header-file="FILE":逗号前的用于终端输入,逗号前后用于.l文件。该选项告诉flex生成名为"FILE"的头文件,该文件包含XX.yy.c文件中的一些类型和定义。
-oFILE, --outfile=FILE, %option outfile="FILE":指明词法分析源文件名,如果没有指明该选项,那么生成的词法分析源文件被命名XX.yy.c。
2. Options Affecting Scanner Behavior
-i, --case-insensitive, %option case-insensitive:忽略符号的大小写,符号即人们要分析的各种字符。
-l, --lex-compat, %option lex-compat:最大程度兼容AT&T的flex实现。
-B, --batch, %option batch:关闭超前搜索。
-I, --interactive, %option interactive:打开超前搜索。
--default, %option default:使用默认规则,不明白默认规则是什么。。。
--stack, %option stack:激活开始条件栈。
--yylineno, %option yylineno:记录符号所在行号。如果使用了%option lex-compat,则隐含地使用了该选项。
--yywrap, %option yywrap:noyywrap表示在该.l文件中不会调用yywrap(),而是假设生成的扫描器只扫描单个文件;%option yywrap自然与之相反
3. Code-Level And API Options
--bison-bridge, %option bison-bridge:生成的扫描器API能够被bision调用。API为与bision兼容而作了些小改变。
-R, --reentrant, %option reentrant:生成可重用的扫描器API,这些API用于多线程环境。
-+, --c++, %option c++:如果没有指定该选项,生成的扫描器.c文件是C语言格式的,指定后则生成C++文件。
--array, %option array:yytext的类型由char *变为数组。
--array, %option pointer:与--array, %option array相反。
-PPREFIX, --prefix=PREFIX, %option prefix="PREFIX":将flex中所有yy前缀改为PREFIX,例如指定%option prefix="foo"后,yytext变成footext,yylex变成foolex。
4. Options for Scanner Speed and Size
5. Debugging Options
-b, --backup, %option backup:生成备份信息文件lex.backup,包含一些需要备份的扫描器状态信息和相关的输入符号。
-d, --debug, %option debug:扫描器在debug模式下运行
1 %option 8bit 2 %option never-interactive 3 %option nodefault 4 %option noinput 5 %option nounput 6 %option noyywrap 7 %option prefix="base_yy"
下面是lex / flex规则行为的简短描述。始终选择与输入字符串匹配的最长模式。对于等长模式,选择规则列表中的第一个。INITIAL是所有非条件规则都适用的起始状态。处于活动状态时,排他状态会更改解析规则。 处于排他状态时,仅适用于为该状态定义的那些规则。我们将独占状态用于加引号的字符串,扩展的注释,并消除数字字符串的解析麻烦。
1 /* 2 * We use exclusive states for quoted strings, extended comments, 3 * and to eliminate parsing troubles for numeric strings. 4 * Exclusive states: 5 * <xb> bit string literal 6 * <xc> extended C-style comments 7 * <xd> delimited identifiers (double-quoted identifiers) 8 * <xh> hexadecimal numeric string 9 * <xq> standard quoted strings 10 * <xe> extended quoted strings (support backslash escape sequences) 11 * <xdolq> $foo$ quoted strings 12 * <xui> quoted identifier with Unicode escapes 13 * <xus> quoted string with Unicode escapes 14 */ 15 %x xb 16 %x xc 17 %x xd 18 %x xh 19 %x xe 20 %x xq 21 %x xdolq 22 %x xui 23 %x xus
为了使Windows和Mac客户端以及Unix客户端更加安全,我们接受\ n或\ r作为换行符。 DOS风格的\ r \ n序列将被视为两个连续的换行符,但这不会引起任何问题。 以-开头并扩展到下一个换行符的注释被视为等效于单个空格字符。注意一点:如果在-后面没有换行符,我们将把所有输入内容作为注释。 这是对的。 较旧的Postgres版本无法识别-如果输入内容不以换行符结尾,则将其作为注释。XXX也许\ f(换页符)也应被视为换行符? 如果您更改了空白字符集,则为XXX,请修复scanner_isspace()以使其同意,另请参阅plpgsql lexer。
1 space [ \t\n\r\f] 2 horiz_space [ \t\f] 3 newline [\n\r] 4 non_newline [^\n\r] 5 comment ("--"{non_newline}*) 6 whitespace ({space}+|{comment})
SQL要求在空格中至少有一个换行符,以分隔要串联的字符串文字。 傻了,但是我们要争论谁呢? 请注意,{whitespace_with_newline}之后不应带有*,而{whitespace}通常应带有* ...
1 special_whitespace ({space}+|{comment}{newline}) 2 horiz_whitespace ({horiz_space}|{comment}) 3 whitespace_with_newline ({horiz_whitespace}*{newline}{special_whitespace}*)
为了确保{quotecontinue}可以被扫描而无需在完整模式不匹配的情况下进行备份,我们在{quotestop}中包含尾随空格。 这匹配所有{quotecontinue}均不匹配的情况,除了{quote}后跟空格和仅一个“-”(不是两个,将开始一个{comment})。 为了解决这个问题,我们有{quotefail}。 {quotestop}和{quotefail}的操作必须抛出超出引号本身的字符。
1 quote ' 2 quotestop {quote}{whitespace}* 3 quotecontinue {quote}{whitespace_with_newline}{quote} 4 quotefail {quote}{whitespace}*"-"
位串
诱使(tempting)的是仅在字符串中扫描那些允许的字符。 但是,如果字符串中包含非法字符,则会导致无声地吞下字符。 例如,如果xbinside为[01],则B'ABCD'被解释为零长度的字符串,而ABCD'将丢失! 最好向前传递字符串,并让输入例程验证内容。
1 xbstart [bB]{quote} 2 xbinside [^']*
十六进制数字
1 xhstart [xX]{quote} 2 xhinside [^']*
国际字符
1 xnstart [nN]{quote}
带引号的字符串,允许反斜杠转义
1 xestart [eE]{quote} 2 xeinside [^\\']+ 3 xeescape [\\][^0-7] 4 xeoctesc [\\][0-7]{1,3} 5 xehexesc [\\]x[0-9A-Fa-f]{1,2}
扩展报价xqdouble实现嵌入式报价''''
xqstart {quote} xqdouble {quote}{quote} xqinside [^']+
$ foo $样式引号(“美元引号”)用引号引起来的字符串以$ foo $开头,其中“ foo”是标识符形式的可选字符串,但它可能不包含“ $”,并一直扩展到第一次出现 相同的字符串。 引号文本没有处理。
{dolqfailed}是一条错误规则,可避免{dolqdelim}尾部的“ $”不匹配时避免扫描仪备份。
1 dolq_start [A-Za-z\200-\377_] 2 dolq_cont [A-Za-z\200-\377_0-9] 3 dolqdelim \$({dolq_start}{dolq_cont}*)?\$ 4 dolqfailed \${dolq_start}{dolq_cont}* 5 dolqinside [^$]+
双引号
允许在标识符中嵌入空格和其他特殊字符。
1 dquote \" 2 xdstart {dquote} 3 xdstop {dquote} 4 xddouble {dquote}{dquote} 5 xdinside [^"]+
Unicode转义
1 uescape [uU][eE][sS][cC][aA][pP][eE]{whitespace}*{quote}[^']{quote}
错误规则,以避免备份
1 uescapefail ("-"|[uU][eE][sS][cC][aA][pP][eE]{whitespace}*"-"|[uU][eE][sS][cC][aA][pP][eE]{whitespace}*{quote}[^']|[uU][eE][sS][cC][aA][pP][eE]{whitespace}*{quote}|[uU][eE][sS][cC][aA][pP][eE]{whitespace}*|[uU][eE][sS][cC][aA][pP]|[uU][eE][sS][cC][aA]|[uU][eE][sS][cC]|[uU][eE][sS]|[uU][eE]|[uU])
带Unicode转义的带引号的标识符
1 xuistart [uU]&{dquote} 2 xuistop1 {dquote}{whitespace}*{uescapefail}? 3 xuistop2 {dquote}{whitespace}*{uescape}
带Unicode转义的带引号的字符串
1 xusstart [uU]&{quote} 2 xusstop1 {quote}{whitespace}*{uescapefail}? 3 xusstop2 {quote}{whitespace}*{uescape}
错误规则,以避免备份
1 xufailed [uU]&
C风格评论
“扩展注释”语法与允许的运算符语法非常相似。 这里最棘手的部分是让lex识别以斜杠星号开头的字符串作为注释,当将其解释为运算符时会产生更长的匹配---请记住lex会更喜欢更长的匹配! 另外,如果我们有类似plus-slash-star的内容,那么lex会认为这是3个字符的运算符,而我们希望将其视为+运算符和注释开头。
解决方案有两个:
1.将{op_chars} *附加到xcstart,以便与{operator}匹配尽可能多的文本。 然后,决胜局(相同长度的第一个匹配规则)确保xcstart获胜。 我们用yyless()放回了多余的东西,以防它包含一个星号斜线,以终止注释。
2.在运算符规则中,检查运算符内是否有斜杠星号,如果找到,请使用yyless()将其返回。 这样可以解决加号-斜杠-星号的问题。
短划线注释与运算符规则具有相似的交互作用。
1 xcstart \/\*{op_chars}* 2 xcstop \*+\/ 3 xcinside [^*/]+ 4 digit [0-9] 5 ident_start [A-Za-z\200-\377_] 6 ident_cont [A-Za-z\200-\377_0-9\$] 7 identifier {ident_start}{ident_cont}* 8 typecast "::"
“ self”是应作为单字符令牌返回的一组字符。 “ op_chars”是可以组成“ Op”令牌的一组字符,长度可以是一个或多个字符(但是,如果单个字符令牌出现在“ self”集中,则不应将其作为Op返回。 )。 请注意,这些集合重叠,但是每个集合都有一些不在另一个集合中的字符。 如果更改其中任何一个,请调整出现在“操作员”规则中的字符列表!
1 self [,()\[\].;\:\+\-\*\/\%\^\<\>\=] 2 op_chars [\~\!\@\#\^\&\|\`\?\+\-\*\/\%\<\>\=] 3 operator {op_chars}+
我们不再允许一元减号。 相反,我们将其分别传递给解析器。 在那里它通过doNegate()被强制-莱昂1999年8月20日
添加了{realfail1}和{realfail2}以防止在{real}规则完全不匹配时需要扫描程序备份。
integer {digit}+
decimal (({digit}*\.{digit}+)|({digit}+\.{digit}*))
real ({integer}|{decimal})[Ee][-+]?{digit}+
realfail1 ({integer}|{decimal})[Ee]
realfail2 ({integer}|{decimal})[Ee][-+]
param \${integer}
other .
以美元引用的字符串是完全不透明的,并且不会对其进行转义。 其他带引号的字符串必须允许一些特殊字符,例如单引号和换行符。
嵌入式单引号既以两个相邻的单引号“''”的SQL标准样式实现,又以逸出引号“ \'”的Postgres / Java样式实现。
其他嵌入的转义字符会显式匹配,并且从字符串中删除前导反斜杠。
请注意,如上所述,xcstart必须出现在运算符之前! 同样,空格(注释)必须出现在运算符之前。
规则段
规则段包含模式行和C代码。以空白开始的行或包围在"%{"和"%}"中的内容是C代码。以任何其他东西开始的行是模式行。C代码被逐字拷贝到生成的C文件中。规则段开头的行靠近生成的yylex()函数的开头,并且应该是与模式相关的代码所使用的变量声明或扫描程序的初始化代码。
当lex扫描程序运行时,它把输入与规则段的模式进行匹配。每次发现一个匹配(被匹配的输入称为标记)时就执行与那种模式相关的C代码。如果模式后面跟着一条竖线而不是C代码,那么这个模式将使用与文件中的下一个模式相同的C代码。当输入字符不匹配模式时,词法分析程序的动作就好像它匹配上了代码为"ECHO;"的模式,ECHO将标记的拷贝写到输出。
1 {whitespace} { 2 /* ignore */ 3 } 4 5 {xcstart} { 6 /* Set location in case of syntax error in comment */ 7 SET_YYLLOC(); 8 xcdepth = 0; 9 BEGIN(xc); 10 /* Put back any characters past slash-star; see above */ 11 yyless(2); 12 } 13 14 <xc>{xcstart} { 15 xcdepth++; 16 /* Put back any characters past slash-star; see above */ 17 yyless(2); 18 } 19 ...
用户子例程段
用户子例程段的内容被lex逐字拷贝到C文件。这一部分通常包括从规则中调用的例程。
Scanner_errposition
如果可能,报告一个词法分析器或语法错误的光标位置。预期将在ereport()调用中使用它。 返回值是一个虚拟值(实际上始终为0)。请注意,这只能用于原始解析期间发出的消息(本质上是scan.l和gram.y),因为它要求scanbuf仍然有效。
1 int scanner_errposition(int location) 2 { 3 int pos; 4 Assert(scanbuf != NULL); /* else called from wrong place */ 5 if (location < 0) 6 return 0; /* no-op if location is unknown */ 7 /* Convert byte offset to character number */ 8 pos = pg_mbstrlen_with_len(scanbuf, location) + 1; 9 /* And pass it to the ereport mechanism */ 10 return errposition(pos); 11 }
yyerror
报告词法分析器或语法错误。
消息的光标位置标识了最近词汇化的标记。 对于来自Bison解析器的语法错误消息,这是可以的,因为一旦到达第一个不可解析的令牌,Bison解析器就会报告错误。 注意不要将yyerror用于其他目的,因为光标位置可能会引起误解!
void yyerror(const char *message){ const char *loc = scanbuf + yylloc; if (*loc == YY_END_OF_BUFFER_CHAR){ ereport(ERROR, (errcode(ERRCODE_SYNTAX_ERROR), /* translator: %s is typically the translation of "syntax error" */ errmsg("%s at end of input", _(message)), lexer_errposition())); }else{ ereport(ERROR, (errcode(ERRCODE_SYNTAX_ERROR), /* translator: first %s is typically the translation of "syntax error" */ errmsg("%s at or near \"%s\"", _(message), loc), lexer_errposition())); } }
在任何实际解析完成之前调用
1 void scanner_init(const char *str) { 2 Size slen = strlen(str); 3 /* Might be left over after ereport() */ 4 if (YY_CURRENT_BUFFER) 5 yy_delete_buffer(YY_CURRENT_BUFFER); 6 /* Make a scan buffer with special termination needed by flex.*/ 7 scanbuf = palloc(slen + 2); 8 memcpy(scanbuf, str, slen); 9 scanbuf[slen] = scanbuf[slen + 1] = YY_END_OF_BUFFER_CHAR; 10 scanbufhandle = yy_scan_buffer(scanbuf, slen + 2); 11 /* initialize literal buffer to a reasonable but expansible size */ 12 literalalloc = 1024; 13 literalbuf = (char *) palloc(literalalloc); 14 startlit(); 15 BEGIN(INITIAL); 16 }
解析完成后调用以在scanner_init()之后进行清理
1 void scanner_finish(void) { 2 yy_delete_buffer(scanbufhandle); 3 pfree(scanbuf); 4 scanbuf = NULL; 5 }
其他函数
1 static void addlit(char *ytext, int yleng) { 2 /* enlarge buffer if needed */ 3 if ((literallen+yleng) >= literalalloc){ 4 do { 5 literalalloc *= 2; 6 } while ((literallen+yleng) >= literalalloc); 7 literalbuf = (char *) repalloc(literalbuf, literalalloc); 8 } 9 /* append new data, add trailing null */ 10 memcpy(literalbuf+literallen, ytext, yleng); 11 literallen += yleng; 12 literalbuf[literallen] = '\0'; 13 } 14 15 static void addlitchar(unsigned char ychar) { 16 /* enlarge buffer if needed */ 17 if ((literallen+1) >= literalalloc){ 18 literalalloc *= 2; 19 literalbuf = (char *) repalloc(literalbuf, literalalloc); 20 } 21 /* append new data, add trailing null */ 22 literalbuf[literallen] = ychar; 23 literallen += 1; 24 literalbuf[literallen] = '\0'; 25 } 26 27 28 /* One might be tempted to write pstrdup(literalbuf) instead of this, but for long literals this is much faster because the length is already known. 29 */ 30 static char * litbufdup(void){ 31 char *new; 32 new = palloc(literallen + 1); 33 memcpy(new, literalbuf, literallen+1); 34 return new; 35 } 36 37 static int hexval(unsigned char c) { 38 if (c >= '0' && c <= '9') 39 return c - '0'; 40 if (c >= 'a' && c <= 'f') 41 return c - 'a' + 0xA; 42 if (c >= 'A' && c <= 'F') 43 return c - 'A' + 0xA; 44 elog(ERROR, "invalid hexadecimal digit"); 45 return 0; /* not reached */ 46 } 47 48 static void check_unicode_value(pg_wchar c, char * loc) { 49 if (GetDatabaseEncoding() == PG_UTF8) 50 return; 51 if (c > 0x7F) { 52 yylloc += (char *) loc - literalbuf + 3; /* 3 for U&" */ 53 yyerror("Unicode escape values cannot be used for code point values above 007F when the server encoding is not UTF8"); 54 } 55 } 56 57 static char * litbuf_udeescape(unsigned char escape) { 58 char *new; 59 char *in, *out; 60 if (isxdigit(escape)|| escape == '+'|| escape == '\''|| escape == '"'|| scanner_isspace(escape)){ 61 yylloc += literallen + yyleng + 1; 62 yyerror("invalid Unicode escape character"); 63 } 64 /* This relies on the subtle assumption that a UTF-8 expansion cannot be longer than its escaped representation.*/ 65 new = palloc(literallen + 1); 66 in = literalbuf; 67 out = new; 68 while (*in){ 69 if (in[0] == escape){ 70 if (in[1] == escape){ 71 *out++ = escape; 72 in += 2; 73 }else if (isxdigit(in[1]) && isxdigit(in[2]) && isxdigit(in[3]) && isxdigit(in[4])){ 74 pg_wchar unicode = hexval(in[1]) * 16*16*16 + hexval(in[2]) * 16*16 + hexval(in[3]) * 16 + hexval(in[4]); 75 check_unicode_value(unicode, in); 76 unicode_to_utf8(unicode, (unsigned char *) out); 77 in += 5; 78 out += pg_mblen(out); 79 } 80 else if (in[1] == '+'&& isxdigit(in[2]) && isxdigit(in[3])&& isxdigit(in[4]) && isxdigit(in[5])&& isxdigit(in[6]) && isxdigit(in[7])){ 81 pg_wchar unicode = hexval(in[2]) * 16*16*16*16*16 + hexval(in[3]) * 16*16*16*16 + hexval(in[4]) * 16*16*16 82 + hexval(in[5]) * 16*16 + hexval(in[6]) * 16 + hexval(in[7]); 83 check_unicode_value(unicode, in); 84 unicode_to_utf8(unicode, (unsigned char *) out); 85 in += 8; 86 out += pg_mblen(out); 87 }else{ 88 yylloc += in - literalbuf + 3; /* 3 for U&" */ 89 yyerror("invalid Unicode escape value"); 90 } 91 }else 92 *out++ = *in++; 93 } 94 *out = '\0'; 95 /* We could skip pg_verifymbstr if we didn't process any non-7-bit-ASCII codes; but it's probably not worth the trouble, since this isn't likely to be a performance-critical path. */ 96 pg_verifymbstr(new, out - new, false); 97 return new; 98 } 99 100 static unsigned char unescape_single_char(unsigned char c) { 101 switch (c){ 102 case 'b': 103 return '\b'; 104 case 'f': 105 return '\f'; 106 case 'n': 107 return '\n'; 108 case 'r': 109 return '\r'; 110 case 't': 111 return '\t'; 112 default: 113 /* check for backslash followed by non-7-bit-ASCII */ 114 if (c == '\0' || IS_HIGHBIT_SET(c)) 115 saw_non_ascii = true; 116 return c; 117 } 118 } 119 120 static void check_string_escape_warning(unsigned char ychar) { 121 if (ychar == '\''){ 122 if (warn_on_first_escape && escape_string_warning) 123 ereport(WARNING,(errcode(ERRCODE_NONSTANDARD_USE_OF_ESCAPE_CHARACTER), 124 errmsg("nonstandard use of \\' in a string literal"), 125 errhint("Use '' to write quotes in strings, or use the escape string syntax (E'...')."), 126 lexer_errposition())); 127 warn_on_first_escape = false; /* warn only once per string */ 128 }else if (ychar == '\\'){ 129 if (warn_on_first_escape && escape_string_warning) 130 ereport(WARNING, 131 (errcode(ERRCODE_NONSTANDARD_USE_OF_ESCAPE_CHARACTER), 132 errmsg("nonstandard use of \\\\ in a string literal"), 133 errhint("Use the escape string syntax for backslashes, e.g., E'\\\\'."), 134 lexer_errposition())); 135 warn_on_first_escape = false; /* warn only once per string */ 136 }else 137 check_escape_warning(); 138 } 139 140 static void check_escape_warning(void) { 141 if (warn_on_first_escape && escape_string_warning) 142 ereport(WARNING, 143 (errcode(ERRCODE_NONSTANDARD_USE_OF_ESCAPE_CHARACTER), 144 errmsg("nonstandard use of escape in a string literal"), 145 errhint("Use the escape string syntax for escapes, e.g., E'\\r\\n'."), 146 lexer_errposition())); 147 warn_on_first_escape = false; /* warn only once per string */ 148 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号