python 爬取全本免费小说网的小说
这几天朋友说想看电子书,但是只能在网上看,不能下载到本地后看,问我有啥办法?我找了好几个小说网址看了下,你只能直接在网上看,要下载txt要冲钱买会员,而且还不能在浏览器上直接复制粘贴。之后我就想到python的爬虫不就可以爬取后下载吗?
码源下载:
https://github.com/feiquan123/GetEBook/
思路:
首先,选择网址:http://www.yznnw.com/files/article/html/1/1129/index.html 这个是全本免费小说网上《龙血战神》的网址:

F12,分析网页元素,可以看到,在此页的 .zjlist4 li a 下存放了所有章节的URL,首先我们要获取这些url放在一个数组里。然后循环遍历下载
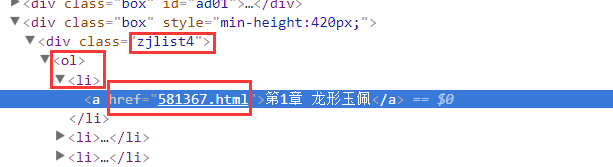
有了这些网址后开始分析具体的每一章:
书名:

章节名:

内容:

下一章:

有了这些信息我们就可以开始爬取了(其实这里可以不爬取下一章的,主要我之前的思路是:下载小说的第一章后,返回小说的下一章,之后不断递归直到最后一页,这么做后下载速度慢,不能并发,还有就是一直递归占用资源大,一直请求服务器会断开连接,导致失败)
所以我换成了这种思路:就是先获取所有的章节的网页连接,再用线程(你也可以用进程)开始下载,果然速度上升了好多,
但是,仔细分析后发现,其实有些章节是作者的感言啥的,这些是不用下载的,而真正的章节的标题一定含有:****章*****,所以要用正则排除掉(这个要具体分析,不一定每个作者的感言标题都是这样的,不过直接使用此程序也可以,这样也没啥)


代码如下:
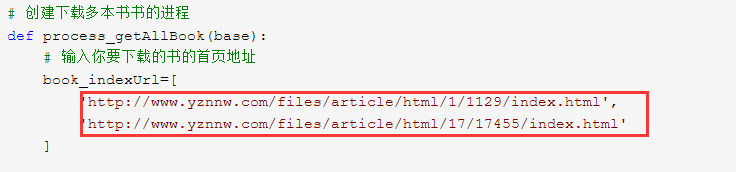
#coding:utf-8 import urllib import urllib.request import multiprocessing from bs4 import BeautifulSoup import re import os import time def get_pages(url): soup="" try: # 创建请求日志文件夹 if 'Log' not in os.listdir('.'): os.mkdir(r".\Log") # 请求当前章节页面 params为请求参数 request = urllib.request.Request(url) response = urllib.request.urlopen(request) content = response.read() data = content.decode('gbk') # soup转换 soup = BeautifulSoup(data, "html.parser") except Exception as e: print(url+" 请求错误\n") with open(r".\Log\req_error.txt",'a',encoding='utf-8') as f: f.write(url+" 请求错误\n") f.close() return soup # 通过章节的url下载内容,并返回下一页的url def get_ChartTxt(url,title,num): soup=get_pages(url) # 获取章节名称 subtitle = soup.select('#htmltimu')[0].text # 判断是否有感言 if re.search(r'.*?章', subtitle) is None: return # 获取章节文本 content = soup.select('#htmlContent')[0].text # 按照指定格式替换章节内容,运用正则表达式 content = re.sub(r'\(.*?\)', '', content) content = re.sub(r'\r\n', '', content) content = re.sub(r'\n+', '\n', content) content = re.sub(r'<.*?>+', '', content) # 单独写入这一章 try: with open(r'.\%s\%s %s.txt' % (title, num,subtitle), 'w', encoding='utf-8') as f: f.write(subtitle + content) f.close() print(num,subtitle, '下载成功') except Exception as e: print(subtitle, '下载失败',url) errorPath='.\Error\%s'%(title) # 创建错误文件夹 try : os.makedirs(errorPath) except Exception as e: pass #写入错误文件 with open("%s\error_url.txt"%(errorPath),'a',encoding='utf-8') as f: f.write(subtitle+"下载失败 "+url+'\n') f.close() return # 通过首页获得该小说的所有章节链接后下载这本书 def thread_getOneBook(indexUrl): soup = get_pages(indexUrl) # 获取书名 title = soup.select('#htmldhshuming')[0].text # 根据书名创建文件夹 if title not in os.listdir('.'): os.mkdir(r".\%s" % (title)) print(title, "文件夹创建成功———————————————————") # 加载此进程开始的时间 print('下载 %s 的PID:%s...' % (title, os.getpid())) start = time.time() # 获取这本书的所有章节 charts_url = [] # 提取出书的每章节不变的url indexUrl = re.sub(r'index.html', '', indexUrl) charts = soup.select(".zjlist4 li a") for i in charts: # print(j+i.attrs['href']) charts_url.append(indexUrl + i.attrs['href']) # 创建下载这本书的进程 p = multiprocessing.Pool() #自己在下载的文件前加上编号,防止有的文章有上,中,下三卷导致有3个第一章 num=1 for i in charts_url: p.apply_async(get_ChartTxt, args=(i,title,num)) num+=1 print('等待 %s 所有的章节被加载......' % (title)) p.close() p.join() end = time.time() print('下载 %s 完成,运行时间 %0.2f s.' % (title, (end - start))) print('开始生成 %s ................' %title ) sort_allCharts(r'.',"%s.txt"%title) return # 创建下载多本书书的进程 def process_getAllBook(base): # 输入你要下载的书的首页地址 print('主程序的PID:%s' % os.getpid()) book_indexUrl=[ 'http://www.yznnw.com/files/article/html/1/1129/index.html', 'http://www.yznnw.com/files/article/html/29/29931/index.html', 'http://www.yznnw.com/files/article/html/0/868/index.html' ] print("-------------------开始下载-------------------") p = [] for i in book_indexUrl: p.append(multiprocessing.Process(target=thread_getOneBook, args=(i,))) print("等待所有的主进程加载完成........") for i in p: i.start() for i in p: i.join() print("-------------------全部下载完成-------------------") return
#合成一本书 def sort_allCharts(path,filename): lists=os.listdir(path) # 对文件排序 # lists=sorted(lists,key=lambda i:int(re.match(r'(\d+)',i).group())) lists.sort(key=lambda i:int(re.match(r'(\d+)',i).group())) # 删除旧的书 if os.path.exists(filename): os.remove(filename) print('旧的 %s 已经被删除'%filename) # 创建新书 with open(r'.\%s'%(filename),'a',encoding='utf-8') as f: for i in lists: with open(r'%s\%s' % (path, i), 'r', encoding='utf-8') as temp: f.writelines(temp.readlines()) temp.close() f.close() print('新的 %s 已经被创建在当前目录 %s '%(filename,os.path.abspath(filename))) return if __name__=="__main__": # # 主页 base = 'http://www.yznnw.com' # 下载指定的书 process_getAllBook(base)
#如果下载完出现卡的话,请单独执行如下命令 # sort_allCharts(r'.\龙血战神',"龙血战神.txt")
如果要下载其他书的话,找到书的首页,添加到如下位置:
找书的首页URL,随便点开一章,删除后面的***.html,后回车,就是这本书的首页URL。

运行结果:




请求URL失败的网页放在,Log\req_error.txt中
爬取失败的章节存放在这本书的目录下的error_url.txt中
之后,你可以使用电子书生成器,生成就好,也可以在跟目录下看到相应的总的小说:
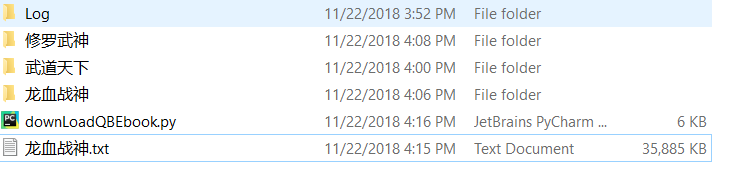
这个是我爬了3本书的结果,爬完后程序卡了,只能结束掉,单独执行最后一条命令了。。。。。。。。
手机端打开,目录也正确


版权 作者:feiquan 出处:http://www.cnblogs.com/feiquan/ 版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 大家写文都不容易,请尊重劳动成果~ 这里谢谢大家啦(*/ω\*)
若没有标明转载链接,此篇文章属于本人的原创文章,其版权所属:
作者:feiquan
出处:http://www.cnblogs.com/feiquan/
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
大家写文都不容易,请尊重劳动成果~ 这里谢谢大家啦(*/ω\*)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号