

常用的一些命令行工具
alias
# 显示全部已定义的别名
alias
alias -p
# 显示已定义的别名(假设当前环境存在以下别名)
alias ls
alias ls grep
# 定义或修改别名的值
alias ls='ls --color=auto'
alias ls='ls --color=never' grep='grep --color=never'
fd
https://github.com/chinanf-boy/fd-zh
有中文,挺好
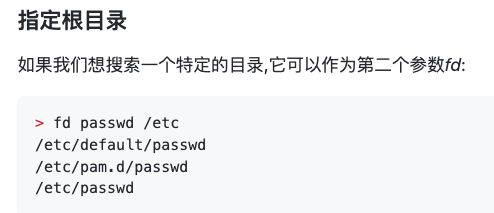

USAGE:
fd [FLAGS/OPTIONS] [<pattern>] [<path>...]
FLAGS:
-H, --hidden 搜索隐藏的文件和目录
-I, --no-ignore 不要忽略 .(git | fd)ignore 文件匹配
--no-ignore-vcs 不要忽略.gitignore文件的匹配
-s, --case-sensitive 区分大小写的搜索(默认值:智能案例)
-i, --ignore-case 不区分大小写的搜索(默认值:智能案例)
-F, --fixed-strings 将模式视为文字字符串
-a, --absolute-path 显示绝对路径而不是相对路径
-L, --follow 遵循符号链接
-p, --full-path 搜索完整路径(默认值:仅限 file-/dirname)
-0, --print0 用null字符分隔结果
-h, --help 打印帮助信息
-V, --version 打印版本信息
OPTIONS:
-d, --max-depth <depth> 设置最大搜索深度(默认值:无)
-t, --type <filetype>... 按类型过滤:文件(f),目录(d),符号链接(l),
可执行(x),空(e)
-e, --extension <ext>... 按文件扩展名过滤, fd -e txt hello,或者fd hello -e txt都是可以的
-x, --exec <cmd> 为每个搜索结果执行命令
-E, --exclude <pattern>... 排除与给定glob模式匹配的条目
--ignore-file <path>... 以.gitignore格式添加自定义忽略文件
-c, --color <when> 何时使用颜色:never,*auto*, always
-j, --threads <num> 设置用于搜索和执行的线程数
-S, --size <size>... 根据文件大小限制结果。
ARGS:
<pattern> the search pattern, a regular expression (optional)
<path>... the root directory for the filesystem search (optional)
ncdu
mac上的清理工具
grep
grep [pattern] [file/directory]
查找文件中包不包含指定字符串:
grep hello a.txt
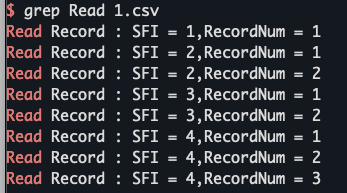
在当前目录中,查找后缀有 csv 字样的文件中包含 Num 字符串的文件:
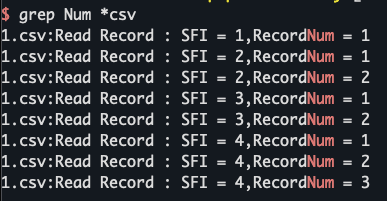
grep -rn * ./搜索当前目录下文件内容,类似于vscode的全局搜索,-n表示打印行号,-r表示递归搜索,与上一条的区别是这里不是指定文件,而是指定目录
awk sed
在个人one note上
less
文本查看,git log用的就是这个东西
-e:文件内容显示完毕后,自动退出;
-f:强制显示文件;
-g:不加亮显示搜索到的所有关键词,仅显示当前显示的关键字,以提高显示速度;
-l:搜索时忽略大小写的差异;
-N:每一行行首显示行号;
-s:将连续多个空行压缩成一行显示;
-S:在单行显示较长的内容,而不换行显示;
-x<数字>:将TAB字符显示为指定个数的空格字符。
git log留住文本在屏幕上
https://www.cnblogs.com/feipeng8848/p/16072474.html
less 支持vim操作,gg到底一样,d滚半屏,/查找等,q退出
expr
命令行计算器
加法运算:+
减法运算:-
乘法运算:\*
除法运算:/
求摸(取余)运算:%
注意要有空格
# kun @ Mac in ~
$ expr 3 \* 100
300
# kun @ Mac in ~
$ expr 4 / 7
0
# kun @ Mac in ~
$ expr 4 % 7
4
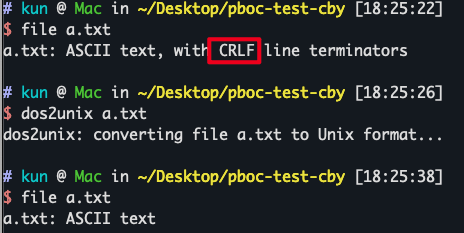
file
能看出文件类型
fmt
-w 指定每一列字符数
-s 只针对超过 -w指定的字符数拆分
-c或--crown-margin:每段前两列缩排;
-p<列起始字符串>或-prefix=<列起始字符串>:仅合并含有指定字符串的列,通常运用在程序语言的注解方面;
-s或--split-only:只拆开字数超出每列字符数的列,但不合并字数不足每列字符数的列;
-t或--tagged-paragraph:每列前两列缩排,但第1列和第2列的缩排格式不同;
-u或--uniform-spacing:每列字符之间都以一个空格字符间隔,每个句子之间则两个空格字符分隔;
-w<每列字符数>或--width=<每列字符数>或-<每列字符数>:设置每列的最大字符数。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2020-05-07 git重命名远程名称
2020-05-07 解决修改ignore文件无效的问题