


【转】递归计算向非递归计算转换模板
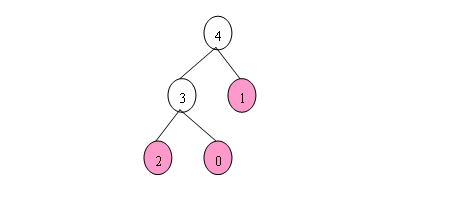
最近由于工作上的需要,研究了一下递归计算向非递归计算的转换问题。理论上而言,所有递归程序都可以用非递归程序来实现;这种理论的基础是递归程序的计算总能用一颗树型结构来表示。递归计算从求树根节点的值开始,树根节点的值依赖一个或多个子节点的值,子节点的值又依赖下一级子节点的值,如此直至树的叶子节点。叶子节点的值能直接计算出来,也就是递归程序的出口。如下图所示,是递归函数f(x) = f(x-1) + f(x-3), f(x) = 10 (x < 3)当x=4时的递归调用树。简单的递归计算,比如尾部递归,可以直接用循环来转换成非递归;对于复杂的递归,比如递归程序中递归调用点有多个,就是树型结构中一个父节点的值会依赖多个子节点的值,这种情形的递归转换成非递归通常需要借助堆栈加循环的方式。
 直接用编程语言中的递归函数实现递归时,在时间和空间上都有可能造成浪费。从时间上来讲,如果递归调用点有多个,会由于中间计算结果没有被保存重用而导致大量的重复计算。比如递归函数f(x) = f(x-1) + f(x-3),计算f(x)时,会先计算f(x-1)的值,在计算f(x-1)时会计算出许多子节点的值,这些值在计算f(x-3)时是可以重用的,但是当退出f(x-1)的调用后都被丢弃了,导致在计算f(x-3)时会重复很多计算。空间上,由于每次递归调用都要保留现场,递归变深时,树会迅速膨胀,占用的空间也会激增。
直接用编程语言中的递归函数实现递归时,在时间和空间上都有可能造成浪费。从时间上来讲,如果递归调用点有多个,会由于中间计算结果没有被保存重用而导致大量的重复计算。比如递归函数f(x) = f(x-1) + f(x-3),计算f(x)时,会先计算f(x-1)的值,在计算f(x-1)时会计算出许多子节点的值,这些值在计算f(x-3)时是可以重用的,但是当退出f(x-1)的调用后都被丢弃了,导致在计算f(x-3)时会重复很多计算。空间上,由于每次递归调用都要保留现场,递归变深时,树会迅速膨胀,占用的空间也会激增。
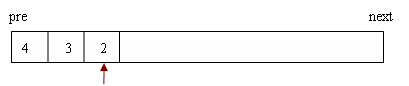 递归程序转换成非递归程序时有固定的模式可循,将这个模式抽象成通用的模板,就有可能实现递归至非递归程序的自动转换。根据前面的分析,将递归计算用树型结构来表达,计算父节点时,会要求计算出其子节点的值。如果用一个堆栈来表示,则计算父节点时,会先将该父节点压入堆栈,待到其依赖的所有子节点的值都计算出时,再将其弹出并计算其值;在计算其子节点时依照相同的原理,直至遇到叶子节点。考虑递归函数f(x) = f(x-1) + f(x-3), f(x) = 10 (x < 3), x 的初始值为4,用如图所示的数据结构表示,往pre方向是堆栈的底部,往next的方向是堆栈的顶部,堆栈指针指向当前正在计算的节点。计算第一个子节点的堆栈情况如下所示:
递归程序转换成非递归程序时有固定的模式可循,将这个模式抽象成通用的模板,就有可能实现递归至非递归程序的自动转换。根据前面的分析,将递归计算用树型结构来表达,计算父节点时,会要求计算出其子节点的值。如果用一个堆栈来表示,则计算父节点时,会先将该父节点压入堆栈,待到其依赖的所有子节点的值都计算出时,再将其弹出并计算其值;在计算其子节点时依照相同的原理,直至遇到叶子节点。考虑递归函数f(x) = f(x-1) + f(x-3), f(x) = 10 (x < 3), x 的初始值为4,用如图所示的数据结构表示,往pre方向是堆栈的底部,往next的方向是堆栈的顶部,堆栈指针指向当前正在计算的节点。计算第一个子节点的堆栈情况如下所示:
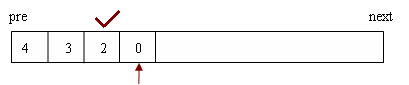
计算f(4)时会先计算f(3),计算f(3)时会先计算f(2),f(2)=10,是叶子节点,那么f(3)的第一个子节点f(2)计算完成,开始计算f(3)的第二个节点f(0):
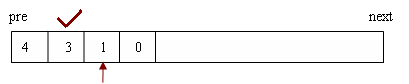
f(0)=10,至此f(3)的两个子节点都计算完成,可以求出f(3) = f(2) +f(0) = 20。f(3)求出后,相当于f(4)的第一个子节点被计算出来了,开始计算f(4)的第二个子节点的值f(1):
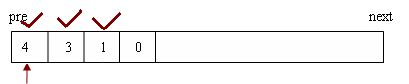
f(1)=10,那么f(4)的两个子节点都已经被计算出来了,可以直接求f(4) = f(3) + f(1) = 30。由于此时已到堆栈底部,计算完成,弹出f(4)的计算结果,即为最终结果。
以上的示例虽然简单,但足以总结出如下规律:
结算某个节点的值时,有两种情况:
- 1) 该节点为叶子节点,可以直接求出其值;
- 2) 该节点为非叶子节点,需要先计算其依赖的子节点。该节点可能依赖多个子节点,子节点一个一个地计算,当最后一个子节点计算出来后,该节点的值可以顺利求出;
- 3) 在2)中计算子节点时,要么其子节点为叶子节点,进入1),值能直接求出;否则,又进入2)计算下一级子节点。每个节点完成计算时都需要监测自己是不是父节点的最后一个子节点。如果是,就可以直接求父节点的值;如果非,就继续求下一个兄弟节点,即父节点的下一个子节点的值。
最后一条很关键,当每个节点完成计算时,它甚至没有信息可以判断前面哪个节点是其父节点!子节点没有父节点的信息,但父节点通过设置状态可以记录当前是在计算哪个子节点。对于特定的递归程序,每个父节点依赖的子节点的数目是确定的,就是递归调用点的数目;比如f(x) = f(x-1) + f(x-3),递归调用点为2,可以确定每个父节点依赖2个子节点。
基于前面如图所示的堆栈结构,计算父节点时会依次计算其子节点,其子节点会依次紧跟在父节点之后压入堆栈。设每个节点的初始状态为0,计算完成后状态为3;则刚进入递归时树根节点的状态为0,此时把该节点当作父节点,开始计算其第一个子节点,父节点的状态设置成1,表示在计算它的第一个子节点。第一个子节点计算完成后,自身状态为3,回溯检查,发现前面的节点状态为1,可以确定其为父节点,并且仅计算出了第一个子节点的值,还需要计算第二个子节点的值。这时将该父节点的状态设置成2,表示在计算它的第二个子节点。第二个子节点计算完成自身状态变为3后,回溯检查,至第一个子节点,第一个子节点状态为3,再回溯,至状态为2的父节点,由于该父节点总共只有两个依赖的子节点,所以可以断定该父节点的最后一个子节点已经完成了计算,可以计算该父节点的值了。根据前面的数据结构可知该父节点的两个子节点依次紧跟其后,可以直接依次取出计算父节点的值。当该父节点完成计算后,状态变为3,这个时候就该回溯去寻找该父节点的父节点了。当最后一个父节点找到并完成计算后,递归计算就完成了。如上所示的堆栈中保存的是递归参数的值,在实际程序中,我们还需要空间来保存递归参数对应的计算出来的值,一般一个HashMap就足够了。
经过上面的分析,应该能很容易地将例子中的递归程序转换成非递归程序。今天有点累了,明天会附上用java实现的非递归程序。我们可以清楚的从代码中看出既定的规律,进而归纳出一个通用的递归向非递归程序转换的模板。
上一篇文章对递归向非递归转换的原理和过程作了介绍,本篇谈谈具体的代码实现。还是考虑上一篇文章中的递归例子:f(x) = f(x-1) + f(x-3), f(x) = 10 (x < 3)。用上文分析出来的规律,其实现如下:
- public static double nonRecursion(double x) {
- double initValue = x;
- final int endFlag = 3; // count of branches plus 1
- Map<Double, Double> values = new HashMap<Double, Double>();
- StackItem ci = new StackItem(initValue);
- while (ci != null) {
- switch (ci.flag) {
- case 0:
- x = ci.number;
- if (x < 3) { // exit of recursion
- values.put(x, 10.0);
- ci.flag = endFlag;
- } else {
- ci.flag = ci.flag + 1;
- StackItem sub;
- if (ci.next == null) {
- sub = new StackItem();
- sub.pre = ci;
- ci.next = sub;
- } else {
- sub = ci.next;
- }
- sub.number = x - 1; // branch one
- if (values.containsKey(sub.number)) {
- sub.flag = endFlag;
- } else {
- sub.flag = 0;
- }
- ci = sub;
- }
- break;
- case 1:
- x = ci.number;
- ci.flag = ci.flag + 1;
- StackItem sub;
- if (ci.next.next == null) {
- sub = new StackItem();
- sub.pre = ci.next;
- ci.next.next = sub;
- } else {
- sub = ci.next.next;
- }
- sub.number = x - 3; // branch two
- if (values.containsKey(sub.number)) {
- sub.flag = endFlag;
- } else {
- sub.flag = 0;
- }
- ci = sub;
- break;
- case 2: // two sub items are ready, calculating using sub items
- x = ci.number;
- double f1 = values.get(ci.next.number);
- double f2 = values.get(ci.next.next.number);
- double result = f1 + f2; // recursive body
- values.put(x, result);
- ci.flag = endFlag;
- break;
- case endFlag: // current item is ready, back to previous item
- ci = ci.pre;
- break;
- }
- }
- return values.get(initValue);
- }
其中本地的Map类型的变量values用来存放递归因子和它对应的计算出来的值。堆栈是用双向链表来实现的,双向链表非常方便向前回溯和向后取得父节点的子节点。双向链表的item类型为StackItem,它除了拥有向前和向后的指针外,还包含当前递归因子的值和状态。其结构如下:
- public class StackItem {
- public double number;
- public int flag;
- public StackItem pre = null;
- public StackItem next = null;
- public StackItem() {
- this(0);
- }
- public StackItem(double number) {
- this.number = number;
- this.flag = 0;
- }
- }
在本机上运行了一下,由于转换后的非递归程序保存了中间递归因子的计算值,它比直接用java语言实现递归在时间上要快不少。递归参数越大时,其优势越明显。
上一篇文章提到要把分析出来的规律总结成一个通用模板,其实从上面的实现代码中可以看出,模板的框架已经浮现出来了。根据递归函数中的递归调用点,可以确定计算完成时的状态值,进而确定循环体中case的个数。其中每个case里面的代码块都具备可以模板化的特点。总体来说,将一个递归函数分解成如下几块,安插至case框架里面即可:
- 递归调用出口(exit of recursion):在当前节点状态为0,即初次遍历至该节点时,会检查递归因子的值。如果能直接计算出来,则计算出来并将状态置为完成;否则,状态递增1,开始计算第一个子节点的值;
- 递归调用点(branch),包括递归因子的收敛公式,根据其在递归体中出现的顺序安插至case代码体中去;
- 递归体(recursive body),当节点的所有子节点都完成计算后,根据递归体计算当前节点的值。代码的位置位于倒数第二个case中。
根据上面的分解,递归至非递归的转换模板就已经很清晰了,可以轻易的用模板技术,比如velocity或freemarker来实现。
下面再用上面的规律对一个递归函数进行非递归转换,以验证模板的通用性:
递归函数:f(x) = ( f(x-1) + f(x-3) + x) / f(x-2), f(x) = 10 (x < 3)
附上的代码是对以上函数的递归和非递归的java实现:
- public static double recursion(double x) {
- if (x < 3)
- return 10.0;
- double f1 = recursion(x - 1);
- double f2 = recursion(x - 3);
- double f3 = recursion(x - 2);
- return (f1 + f2 + x) / f3;
- }
- public static double nonRecursion(double x) {
- double initValue = x;
- final int endFlag = 4; // count of branches plus 1
- Map<Double, Double> values = new HashMap<Double, Double>();
- StackItem ci = new StackItem(initValue);
- while (ci != null) {
- switch (ci.flag) {
- case 0:
- x = ci.number;
- if (x < 3) { // exit of recursion
- values.put(x, 10.0);
- ci.flag = endFlag;
- } else {
- ci.flag = ci.flag + 1;
- StackItem sub;
- if (ci.next == null) {
- sub = new StackItem();
- sub.pre = ci;
- ci.next = sub;
- } else {
- sub = ci.next;
- }
- sub.number = x - 1; // branch one
- if (values.containsKey(sub.number)) {
- sub.flag = endFlag;
- } else {
- sub.flag = 0;
- }
- ci = sub;
- }
- break;
- case 1:
- x = ci.number;
- ci.flag = ci.flag + 1;
- StackItem sub1;
- if (ci.next.next == null) {
- sub1 = new StackItem();
- sub1.pre = ci.next;
- ci.next.next = sub1;
- } else {
- sub1 = ci.next.next;
- }
- sub1.number = x - 3; // branch two
- if (values.containsKey(sub1.number)) {
- sub1.flag = endFlag;
- } else {
- sub1.flag = 0;
- }
- ci = sub1;
- break;
- case 2:
- x = ci.number;
- ci.flag = ci.flag + 1;
- StackItem sub2;
- if (ci.next.next.next == null) {
- sub2 = new StackItem();
- sub2.pre = ci.next.next;
- ci.next.next.next = sub2;
- } else {
- sub2 = ci.next.next.next;
- }
- sub2.number = x - 2; // branch three
- if (values.containsKey(sub2.number)) {
- sub2.flag = endFlag;
- } else {
- sub2.flag = 0;
- }
- ci = sub2;
- break;
- case 3: // three sub items are ready, calculating using sub items
- x = ci.number;
- double f1 = values.get(ci.next.number);
- double f2 = values.get(ci.next.next.number);
- double f3 = values.get(ci.next.next.next.number);
- values.put(x, (f1 + f2 + x) / f3); // recursive body
- ci.flag = endFlag;
- break;
- case endFlag: // current item is ready, back to previous item
- ci = ci.pre;
- break;
- }
- }
- return values.get(initValue);
- }
posted on 2010-05-31 13:00 LeeXiaoLiang 阅读(218) 评论(0) 编辑 收藏 举报
