
[Python] 特殊函数小结
1. 带双下划线的函数
1.1 init()
这个方法一般用于初始化一个类
但是 当实例化一个类的时候, init__并不是第一个被调用的, 第一个被调用的是__new
1.2 new()
对比
__new__方法是创建类实例的方法, 创建对象时调用, 返回当前对象的一个实例
__init__方法是类实例创建之后调用, 对当前对象的实例的一些初始化, 没有返回值
1.3 call()
Python 中,凡是可以将 () 直接应用到自身并执行,都称为
可调用对象。
对象通过提供一个__call__(self, *args, *kwargs)方法可以模拟函数的行为, 如果一个对象提供了该方法, 可以向函数一样去调用它。
对于可调用对象,实际上“名称()”可以理解为是“名称.call()”的简写。
在Python中,函数其实是一个对象:
>>> f = abs
>>> f.__name__
'abs'
>>> f(-123)
123
>>> f.__call__(-21)
21
由于 f 可以被调用,所以,f 被称为可调用对象。
所有的函数都是可调用对象。
一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__()。
我们把 Person 类变成一个可调用对象:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, friend):
print 'My name is %s...' % self.name
print 'My friend is %s...' % friend
>>> p = Person('Bob', 'male')
>>> p('Tim')
My name is Bob...
My friend is Tim...
单看 p('Tim') 你无法确定 p 是一个函数还是一个类实例,所以,在Python中,函数也是对象,对象和函数的区别并不显著。
1.4 str()
这是一个内置方法, 只能返回字符串, 并且只能有一个参数self
1.5 演示
代码1:
class Person(object):
def __init__(self, name, age, height):
print("Object __init__")
self.name = name
self.age = age
self.height = height
# 静态方法
@staticmethod
def __new__(cls, name, age, height):
print("Object __new__")
return super(Person, cls).__new__(cls) # 返回为类对象,如果没有返回将不会调用__init__.
def introduce(self):
print("Person name is %s, age is %s, and height is %s" % (self.name, self.age, self.height))
def __call__(self, *args, **kwargs):
print("Object __call__")
self.name = kwargs["name"]
self.age = kwargs["age"]
self.introduce()
def __str__(self):
print("Object __str__")
return "Person name is %s, age is %s, and height is %s" % (self.name, self.age, self.height)
print("Class Per" + "=" * 40)
p1 = Person("1111", "222", "333") # init的效果
p1.introduce()
p1(name="1", age="2") # call的效果,像使用函数一样使用这个类实例
print(p1) # str的效果,直接打印类变量
输出:
Class Per========================================
Object __new__
Object __init__
Person name is 1111, age is 222, and height is 333
Object __call__
Person name is 1, age is 2, and height is 333
Object __str__
Person name is 1, age is 2, and height is 333
1.6 内建函数callable()
可以检查一个对象是否是可调用的 。
对于函数, 方法, lambda 函数式, 类, 以及实现了 _ call _ 方法的类实例, 它都返回 True.
1.6.1 函数是可调用的
>>> def add(x,y):
... return x+y
...
>>> callable(add)
True
1.6.2 类和类内的方法是可调用的
>>> class C:
... def printf(self):
... print 'This is class C!'
...
>>> objC=C()
>>> callable(C)#类是可调用的,调用它们, 就产生对应的类实例.
True
>>> callable(C.printf)
True
>>> callable(objC.printf)
True
1.6.3 实现了__call__()方法的类实例是可调用的
>>> class A:
... def printf(self):
... print 'This is class A!'
...
>>> objA=A()
>>> callable(A) #类是可调用的,调用它们, 就产生对应的类实例.
True
>>> callable(objA) #类A没有实现__call__()方法,因此,类A的实例是不可调用的
False
>>> class B:
... def __call__(self):
... print 'This is class B!'
...
>>> objB=B()
>>> callable(B) #类是可调用的,调用它们, 就产生对应的类实例.
True
>>> callable(objB) #类B实现了__call__()方法,因此,类B实例是可调用的
True
1.6.4 lambda表达式是可调用的
>>> f=lambda x,y:x+y
>>> f(2,3)
5
>>> callable(f)
True
1.6.5 其它的,像整数,字符串,列表,元组,字典等等,都是不可调用的
>>> callable(2)
False
>>> callable('python')
False
>>> l=[1,2,3]
>>> callable(l)
False
>>> t=(4,5,6)
>>> callable(t)
False
>>> d={'a':1,'b':2}
>>> callable(d)
False
1.7 用 call() 弥补 hasattr() 函数的短板
hasattr() 函数的用法,该函数的功能是查找类的实例对象中是否包含指定名称的属性或者方法,但该函数有一个缺陷,即它无法判断该指定的名称,到底是类属性还是类方法。
要解决这个问题,我们可以借助可调用对象的概念。要知道,类实例对象包含的方法,其实也属于可调用对象,但类属性却不是。举个例子:
class CLanguage:
def __init__(self):
self.name = "C语言中文网"
self.add = "http://c.biancheng.net"
def say(self):
print("我正在学Python")
clangs = CLanguage()
if hasattr(clangs, "name"):
print(hasattr(clangs.name, "__call__"))
if hasattr(clangs, "say"):
print(hasattr(clangs.say, "__call__"))
2. 其它特殊函数
这里有个内置函数表:
https://www.runoob.com/python/python-built-in-functions.html
2.1 过滤函数filter
定义:filter 函数的功能相当于过滤器。调用一个布尔函数bool_func来迭代遍历每个列表中的元素;返回一个使bool_func返回值为true的元素的序列。
filter(function, iterable)
- function -- 判断函数。
- iterable -- 可迭代对象。
>>> import math
>>> def is_sqr(x):
return math.sqrt(x) % 1 == 0
>>> newlist = filter(is_sqr, range(1, 101))
>>> print(newlist)
<filter object at 0x00000213783A32B0>
>>> for i in newlist: print(i)
1
4
9
16
……
2.2 映射和归并函数map/reduce
这里说的map和reduce是Python的内置函数,不是Goggle的MapReduce架构。
2.2.1 map函数
map函数的格式:map( func, seq1[, seq2...] )
Python函数式编程中的map()函数是将func作用于列表中的每一个元素,并用一个列表给出返回值。如果func为None,作用等同于一个zip()函数。
下图是当列表只有一个的时候,map函数的工作原理图:
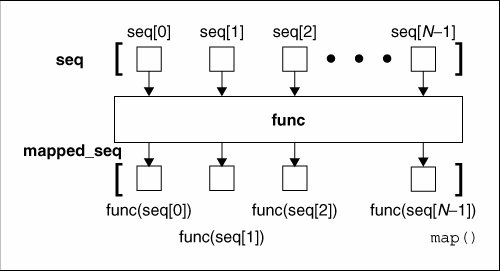
举个简单的例子:将列表中的元素全部转换为None。
map(lambda x : None,[1,2,3,4])
输出:[None,None,None,None]。
当列表有多个时,map()函数的工作原理图:
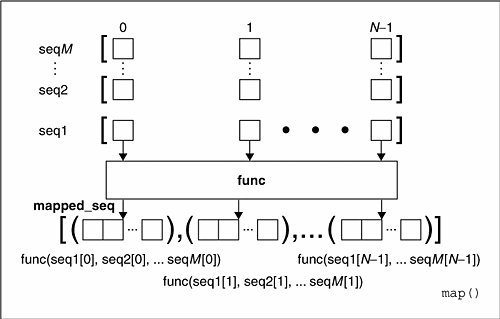
也就是说每个seq的同一位置的元素在执行过一个多元的func函数之后,得到一个返回值,这些返回值放在一个结果列表中。
下面的例子是求两个列表对应元素的积,可以想象,这是一种可能会经常出现的状况,而如果不是用map的话,就要使用一个for循环,依次对每个位置执行该函数。
print map( lambda x, y: x * y, [1, 2, 3], [4, 5, 6] ) # [4, 10, 18]
上面是返回值是一个值的情况,实际上也可以是一个元组。下面的代码不止实现了乘法,也实现了加法,并把积与和放在一个元组中。
print map( lambda x, y: ( x * y, x + y), [1, 2, 3], [4, 5, 6] ) # [(4, 5), (10, 7), (18, 9)]
还有就是上面说的func是None的情况,它的目的是将多个列表相同位置的元素归并到一个元组,在现在已经有了专用的函数zip()了。
print map( None, [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
print zip( [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
注意:不同长度的多个seq是无法执行map函数的,会出现类型错误。
2.2.2 reduce函数
reduce函数格式:reduce(func, seq[, init]).
reduce函数即为化简,它是这样一个过程:每次迭代,将上一次的迭代结果(第一次时为init的元素,如没有init则为seq的第一个元素)与下一个元素一同执行一个二元的func函数。在reduce函数中,init是可选的,如果使用,则作为第一次迭代的第一个元素使用。
简单来说,可以用这样一个形象化的式子来说明:
reduce(func, [1,2,3])=func(func(1,2), 3)
reduce函数的工作原理图如下所示:
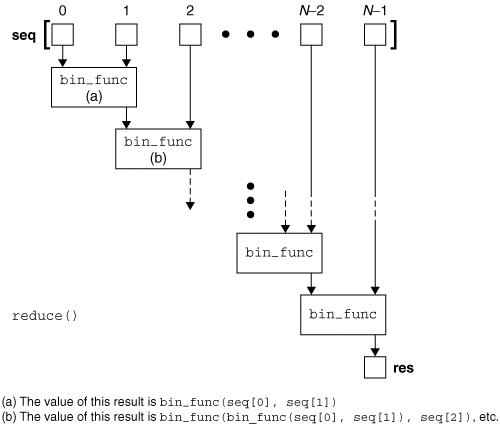
举个例子来说,阶乘是一个常见的数学方法,Python中并没有给出一个阶乘的内建函数,我们可以使用reduce实现一个阶乘的代码。
n = 5
print reduce(lambda x, y: x * y, range(1, n + 1)) # 120
reduce(func, [1,2,3])=func(func(1,2), 3)
那么,如果我们希望得到2倍阶乘的值呢?这就可以用到init这个可选参数了。
m = 2
n = 5
print reduce( lambda x, y: x * y, range( 1, n + 1 ), m ) # 240
reduce(func, [1,2,3])=func(func(1,2), 3)
2.3 装饰器@
2.3.1 什么是装饰器(函数)?
定义:装饰器就是一函数,用来包装函数的函数,用来修饰原函数,将其重新赋值给原来的标识符,并永久的丧失原函数的引用。
2.3.2 装饰器的用法
先举一个简单的装饰器的例子:
import time
def foo():
print('in foo()')
# 定义一个计时器,传入一个,并返回另一个附加了计时功能的方法
def timeit(func):
# 定义一个内嵌的包装函数,给传入的函数加上计时功能的包装
def wrapper():
start = time.perf_counter()
func()
end = time.perf_counter()
print('used:', end - start)
# 将包装后的函数返回
return wrapper
foo = timeit(foo)
foo()
输出:
in foo()
used: 1.6399999999999748e-05
python中专门为装饰器提供了一个@符号的语法糖,用来简化上面的代码,他们的作用一样。上述的代码还可以写成这样(装饰器专有的写法,注意符号“@”):
import time
# 定义一个计时器,传入一个,并返回另一个附加了计时功能的方法
def timeit(func):
# 定义一个内嵌的包装函数,给传入的函数加上计时功能的包装
def wrapper():
start = time.perf_counter()
func()
end = time.perf_counter()
print('used:', end - start)
# 将包装后的函数返回
return wrapper
@timeit
def foo():
print('in foo()')
foo() # 注意这里不需要前面那段的 foo = timeit(foo) 了
其实对装饰器的理解,我们可以根据它的名字来进行,主要有三点:
- 首先装饰器的特点是,它将函数名作为输入(这说明装饰器是一个高阶函数);
- 通过装饰器内部的语法将原来的函数进行加工,然后返回;
- 原函数通过装饰器后被赋予新的功能,新函数覆盖原函数,以后再调用原函数,将会起到新的作用。
说白了,装饰器就相当于是一个函数加工厂,可以将函数进行再加工,赋予其新的功能。
装饰器的嵌套:
def makebold(fn):
def wrapped():
return "<b>" + fn() + "</b>"
return wrapped
def makeitalic(fn):
def wrapped():
return "<i>" + fn() + "</i>"
return wrapped
@makebold
@makeitalic
def hello():
return "hello world"
print(hello())
输出结果:
<b><i>hello world</i></b>
为什么是这个结果呢?
- 首先hello函数经过makeitalic 函数的装饰,变成了这个结果hello world
- 然后再经过makebold函数的装饰,变成了hello world,这个理解起来很简单。
2.4 匿名函数lambda
2.4.1 什么是匿名函数?
在Python,有两种函数,一种是def定义,一种是lambda函数。
定义:顾名思义,即没有函数名的函数。Lambda表达式是Python中一类特殊的定义函数的形式,使用它可以定义一个匿名函数。与其它语言不同,Python的Lambda表达式的函数体只能有唯一的一条语句,也就是返回值表达式语句。
2.4.2 匿名函数的用法
lambda的一般形式是关键字lambda,之后是一个或者多个参数,紧跟的是一个冒号,之后是一个表达式:
lambda argument1 argument2 ... :expression using arguments
- lambda是一个表达式,而不是一个语句。
- lambda主体是一个单一的表达式,而不是一个代码块。
举一个简单的例子,假如要求两个数之和,用普通函数或匿名函数如下:
1)普通函数: def func(x,y):return x+y
2)匿名函数: lambda x,y: x+y
再举一例:对于一个列表,要求只能包含大于3的元素。
1)常规方法:
L1 = [1,2,3,4,5]
L2 = []
for i in L1:
if i>3:
L2.append(i)
2)函数式编程实现: 运用filter,给其一个判断条件即可
def func(x): return x>3
filter(func,[1,2,3,4,5])
3)运用匿名函数,则更加精简,一行就可以了:
filter(lambda x:x>3,[1,2,3,4,5])
总结: 从中可以看出,lambda一般应用于函数式编程,代码简洁,常和reduce,filter等函数结合使用。此外,在lambda函数中不能有return,其实“:”后面就是返回值。
2.4.2 为什么要用匿名函数?
1) 使用Python写一些执行脚本时,使用lambda可以省去定义函数的过程,让代码更加精简。
2) 对于一些抽象的,不会别的地方再复用的函数,有时候给函数起个名字也是个难题,使用lambda不需要考虑命名的问题。
3) 使用lambda在某些时候让代码更容易理解。
2.4.2 匿名函数的一个典型用法:
用List的内建函数list.sort进行排序:
list.sort(func=None, key=None, reverse=False)
# 排序
L = [2,3,1,4]
L.sort()
L
[1,2,3,4]
# 逆序排序
L = [2,3,1,4]
L.sort(reverse=True)
L
[4,3,2,1]
对list的某一列进行排序有可以修改key。
使用匿名函数对list数据第二列进行排序(自定义排序逻辑,相当于修改func参数,参数x,y表示不属于同一行):
# 使用key参数,对每一行的第二列排序:
L = [('b',6),('a',1),('c',3),('d',4)]
L.sort(key=lambda x:x[1])
L
[('a', 1), ('c', 3), ('d', 4), ('b', 6)]
# 使用匿名函数先对第二列进行排序,在对第一列进行排序(先对某一行的第2列进行排序,再对第1列进行排序):
L = [('d',2),('a',4),('b',3),('c',2)]
L.sort(key=lambda x:(x[1],x[0]))
L
[('c', 2), ('d', 2), ('b', 3), ('a', 4)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号