[整理] 音频视频基础知识
音频的基础知识
声音的物理性质
-
声音是波
说到声音我相信只要听力正常的人都听见过声音,那么声音是如何产生的呢?
物理课本上的描述 - 声音是由物体的振动而产生的。其实声音是一种压力波,当敲打某个物体或演奏某个乐器时,它们的振动都会引起空气有节奏的振动,使周围的空气产生疏密变化,形成疏密相间的纵波,由此就产生了声波,这种现象会一直延续到振动消失为止。 -
声波的三要素
声波的三要素是频率、振幅、和波形,频率代表音阶的高低,振幅代表响度,波形代表音色。 -
声音的传播介质
声音的传播介质很广,它可以通过空气、液体和固体进行传播;而且介质不同,传播的速度也不同,比如声音在空气中的传播速度为 340m/s , 在蒸馏水中的传播速度为 1497 m/s , 而在铁棒中的传播速度则可以高达 5200 m/s ;不过,声音在真空中时无法传播的。 -
回声
当我们在高山或者空旷地带高声大喊的时候,经常会听到回声,之所以会有回声是因为声音在传播过程中遇到障碍物会反弹回来,再次被我们听到。
但是,若两种声音传到我们的耳朵里的时差小于 80 毫秒,我们就无法区分开这两种声音了,其实在日常生活中,人耳也在收集回声,只不过由于嘈杂的外接环境以及回声的分贝比较低,所以我们的耳朵分辨不出这样的声音,或者说是大脑能接收到但分辨不出。 -
共鸣
自然界中有光能,水能,生活中有机械能,电能,其实声音也可以产生能量,例如两个频率相同的物体,敲打其中一个物体时另一个物体也会振动发生。这种现象称为共鸣,共鸣证明了声音传播可以带动另一个物体振动,也就是说,声音的传播过程也是一种能量的传播过程。
数字音频
为了将模拟信号数字化,将分为 3 个概念对数字音频进行讲解,分别是采样、量化和编码。
首先要对模拟信号进行采样,所谓采样就是在时间轴上对信号进行数字化。
根据奈奎斯特定理(也称采样定理),按比声音最高频率高 2 倍以上的频率对声音进行采样,对于高质量的音频信号,其频率范围在 20Hz ~ 20kHz ,所以采样频率一般为 44.1kHz ,这样就保证采样声音达到 20kHz 也能被数字化,从而使得经过数字化处理之后,人耳听到的声音质量不会被降低。而所谓的 44.1 kHz 就是代表 1 s 会采样 44100 次。
那么,具体的每个采样又该如何表示呢?这就涉及到将要讲解的第二个概念: 量化。量化是指在幅度轴上对信号进行数字化,比如用 16 bit 的二进制信号来表示声音的一个采样,而 16 bit 所表示的范围是 [-32768 , 32767] , 共有 65536 个可能取值,因此最终模拟的音频信号在幅度上也分为了 65536 层。
既然每一个分量都是一个采样,那么这么多的采样该如何进行存储呢?这就涉及将要讲解的第三个概念: 编码。所谓编码,就是按照一定的格式记录采样和量化后的数字数据,比如顺序存储或压缩存储等等。
这里涉及了很多中格式,通常所说的音频的裸数据就是 PCM (Pulse Code Modulation) 数据。
描述一段 PCM 数据一般需要以下几个概念:量化格式(sampleFormat)、采样率(sampleRate)、声道数 (channel) 。
以 CD 的音质为例:量化格式为 16 bit (2 byte),采样率 44100 ,声道数为 2 ,这些信息就描述了 CD 的音质。而对于声音的格式,还有一个概念用来描述它的大小,称为数据比特率,即 1s 时间内的比特数目,它用于衡量音频数据单位时间内的容量大小。而对于 CD 音质的数据,比特率为多少呢? 计算如下:
44100 * 16 * 2 = 1378.125 kbps
那么在一分钟里,这类 CD 音质的数据需要占据多大的存储空间呢?计算如下:
1378.125 * 60 / 8 / 1024 = 10.09 MB
当然,如果 sampleFormat 更加精确 (比如用 4 个字节来描述一个采样),或者 sampleRate 更加密集 (比如 48kHz 的采样率), 那么所占的存储空间就会更大,同时能够描述的声音细节就会越精确。存储的这段二进制数据即表示将模拟信号转为数字信号了,以后就可以对这段二进制数据进行存储,播放,复制,或者进行其它操作。
音频编码
上面提到了 CD 音质的数据采样格式,曾计算出每分钟需要的存储空间约为 10.09 MB ,如果仅仅是将其存储在光盘或者硬盘中,可能是可以接受的,但是若要在网络中实时在线传输的话,那么这个数据量可能就太大了,所以必须对其进行压缩编码。压缩编码的基本指标之一就是压缩比,压缩比通常小于 1 。
压缩算法包括有损压缩和无损压缩。
无损压缩是指解压后的数据可以完全复原。在常用的压缩格式中,用的较多的是有损压缩,有损压缩是指解压后的数据不能完全恢复,会丢失一部分信息,压缩比越小,丢失的信息就比越多,信号还原后的失真就会越大。
根据不同的应用场景 (包括存储设备、传输网络环境、播放设备等),可以选用不同的压缩编码算法,如 PCM 、WAV、AAC 、MP3 、Ogg 等。
-
WAV 编码
WAV 编码就是在 PCM 数据格式的前面加了 44 个字节,分别用来存储 PCM 的采样率、声道数、数据格式等信息。特点: 音质好,大量软件支持。
场景: 多媒体开发的中间文件、保存音乐和音效素材。 -
MP3 编码
MP3 具有不错的压缩比,使用 LAME 编码 (MP3 编码格式的一种实现)的中高码率的 MP3 文件,听感上非常接近源 WAV 文件,当然在不同的应用场景下,应该调整合适的参数以达到最好的效果。特点: 音质在 128 Kbit/s 以上表现还不错,压缩比比较高,大量软件和硬件都支持,兼容性好。
场景: 高比特率下对兼容性有要求的音乐欣赏。 -
AAC 编码
AAC 是新一代的音频有损压缩技术,它通过一些附加的编码技术(比如 PS 、SBR) 等,衍生出了 LC-AAC 、HE-AAC 、HE-AAC v2 三种主要的编码格式。
LC-AAC 是比较传统的 AAC ,相对而言,其主要应用于中高码率场景的编码 (>=80Kbit/s) ; HE-AAC 相当于 AAC + SBR 主要应用于中低码率的编码 (<= 80Kbit/s); 而新推出的 HE-AAC v2 相当于 AAC + SBR + PS 主要用于低码率场景的编码 (<= 48Kbit/s) 。事实上大部分编码器都设置为 <= 48Kbit/s 自动启用 PS 技术,而 > 48Kbit/s 则不加 PS ,相当于普通的 HE-AAC。特点: 在小于 128Kbit/s 的码率下表现优异,并且多用于视频中的音频编码。
场景: 128 Kbit/s 以下的音频编码,多用于视频中音频轨的编码。 -
Ogg 编码
Ogg 是一种非常有潜力的编码,在各种码率下都有比较优秀的表现,尤其是在中低码率场景下。Ogg 除了音质好之外,还是完全免费的,这为 Ogg 获得更多的支持打好了基础,Ogg 有着非常出色的算法,可以用更小的码率达到更好的音质,128 Kbit/s 的 Ogg 比 192kbit/s 甚至更高码率的 MP3 还要出色。但是目前因为还没有媒体服务软件的支持,因此基于 Ogg 的数字广播还无法实现。Ogg 目前受支持的情况还不够好,无论是软件上的还是硬件上的支持,都无法和 MP3 相提并论。特点: 可以用比 MP3 更小的码率实现比 MP3 更好的音质,高中低码率下均有良好的表现,兼容性不够好,流媒体特性不支持。
场景: 语言聊天的音频消息场景。
视频的基础知识
图像的物理现象
做过 Camera 采集或者做过帧动画其实应该知道,视频是由一幅幅图像或者说一帧帧 YUV 数据组成,所以要学习视频还得从图像开始学习。
我们回顾一下,应该是初中的时候做过一个三棱镜实验,内容是如何利用三棱镜将太阳光分解成彩色的光带?第一个做这个实验者是牛顿,各色光因其所形成的折射角不同而彼此分离,就像彩虹一样,所以白光能够分解成多种色彩的光。后来人们通过实验证明,红绿蓝三种色光无法被分解,故称为三原色光,等量的三原色光相加会变为白光,即白光中含有等量的红光(R),绿光(G),蓝光(B)。
在日常生活中,由于光的反射,我们才能看到各类物体的轮廓和颜色。但是如果将这个理论应用到手机中,那么该结论还成立吗?
答案是否定的,因为在黑暗中我们也可以看到手机屏幕中的内容,实际上人眼能看到手机屏幕上的内容的原理如下。
假设一部手机屏幕的分辨率是 1920 * 1080 ,说明水平方向有 1080 个像素点,垂直方向有 1920 个像素点,所以整个屏幕就有 1920 * 1080 个像素点(这也是分辨率的含义)。每个像素点都由三个子像素点组成,如下图所示,
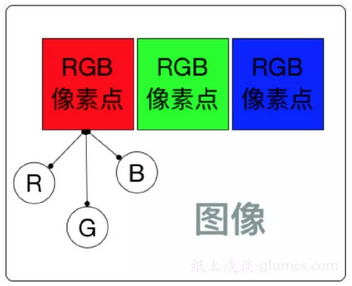
这些密密麻麻的子像素点在图像放大或者在显微镜下可以看得一清二楚。当要显示某篇文字或者某幅图像时,就会把这幅图像的每一个像素点的 RGB 通道分别对应的屏幕位置上的子像素点绘制到屏幕上,从而显示整个图像。
所以在黑暗的环境下也能看到手机屏幕上的内容,是因为手机屏幕是自发光的,而不是通过光的反射才被人们看到的。
图像的数值表示
RGB 表示方式
通过上一小节我们清楚的知道任何一个图像都是由 RGB 组成,那么一个像素点的 RGB 该如何表示呢?音频里面的每一个采样 (sample) 均使用 16 bit 来表示,那么像素里面的子像素又该如何表示呢?通常的表示方式有以下几种。
- 浮点表示:
取值范围在 0.0 ~ 1.0 之间,比如在 OpenGL ES 中对每一个子像素点的表示使用的就是这种方式。 - 整数表示:
取值范围为 0 ~ 255 或者 00 ~ FF , 8 个 bit 表示一个子像素点,32 个 bit 表示一个像素,这就是类似某些平台上表示图像格式的 RGBA_8888 数据格式。比如 Android 平台上的 RGB_565 的表示方法为 16 个 bit 模式表示一个像素, R 用 5 个 bit , G 用 6 个 bit, B 用 5 个 bit 来表示。
对于一幅图像,一般使用整数表示方法进行描述,比如计算一张 1920 * 1080 的 RGB_8888 的图像大小,可采用如下计算方式:
1920 * 1080 * 4 / 1024 / 1024 ≈ 7.910 MB
这也是 Bitmap 在内存中所占用的大小,所以每一张图像的裸数据都是很大的。对于图像的裸数据来说,直接来网络中进行传输也是不大可能的,所以就有了图像的压缩格式。
比如基于 JPEG 压缩 :JPEG 是静态图像压缩标准,由 ISO 制定。 JPEG 图像压缩算法在提供良好的压缩性能的同时,具有较好的重建质量。这种算法被广泛应用于图像处理领域,当然它也是一种有损压缩。在很多网站如淘宝上使用的都是这种压缩之后的图像。
但是,这种压缩不能直接应用于视频压缩,因为对于视频来讲,还有一个时域上的因素需要考虑,也就是说不仅仅要考虑帧内编码,还要考虑帧间编码。视频采用的是更加成熟的算法,关于视频压缩算法的相关内容我们会在后面进行介绍。
YUV 表示方式
YUV 颜色编码采用的是明亮度和色度来指定像素的颜色。其中,Y 表示明亮度(Luminance、Luma),而 U 和 V 表示色度(Chrominance、Chroma)。
而色度又定义了颜色的两个方面:色调和饱和度。使用 YUV 颜色编码表示一幅图像,它应该下面这样的:
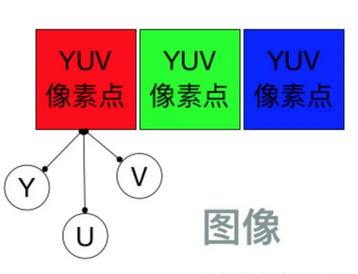
YUV 是一种颜色编码方法。常使用在各个视频处理组件中。 YUV在对照片或视频编码时,考虑到人类的感知能力,允许降低色度的带宽。
对于视频帧的裸数据表示,其实更多的是 YUV 数据格式的表示, YUV 主要应用于优化彩色视频信号的传输,使其向后兼容老式黑白电视。在 RGB 视频信号传输相比,它最大的优点在于只需要占用极少的频宽(RGB 要求三个独立的视频信号同时传输)。其中 Y 表示明亮度,是透过 RGB 输入信号来建立的,方法是将 RGB 信号的特定部分叠加到一起。“色度” 则定义了颜色的两个方面 - 色调与饱和度,分别用 Cr 和 Cb 来表示。其中,Cr 反应了 RGB 输入信号红色部分与 RGB 信号亮度值之间的差异,而 Cb 反映的则是 RGB 输入信号蓝色部分与 RGB 信号亮度值之间的差异。
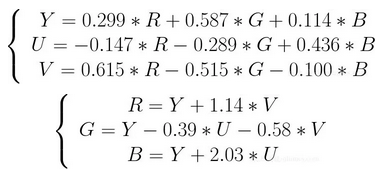
之所以采用 YUV 色彩空间,是因为它的亮度信号 Y 和色度信号 U、V 是分离的。如果只有 Y 信号分量而没有 U 、V 分量,那么这样表示的图像就是黑白灰图像。彩色电视采用 YUV 空间正是为了用亮度信号 Y 解决彩色电视机与黑白电视机的兼容问题,使黑白电视机也能接收彩色电视信号,最常用的表示形式是 Y、U、V 都使用 8 字节来表示,所以取值范围是 0 ~ 255 。 在广播电视系统中不传输很低和很高的数值,实际上是为了防止信号变动造成过载, Y 的取值范围都是 16 ~ 235 ,UV 的取值范围都是 16 ~ 240。
YUV 最常用的采样格式是 4:2:0 , 4:2:0 并不意味着只有 Y 、Cb 而没有 Cr 分量。它指的是对每行扫描线来说,只有一种色度分量是以 2:1 的抽样率来存储的。相邻的扫描行存储着不同的色度分量,也就是说,如果某一行是 4:2:0,那么下一行就是 4:0:2,在下一行是 4:2:0,以此类推。对于每个色度分量来说,水平方向和竖直方向的抽象率都是 2:1,所以可以说色度的抽样率是 4:1。对非压缩的 8 bit 量化的视频来说,8*4 的一张图片需要占用 48 byte 内存。
相较于 RGB ,我们可以计算一帧为 1920 * 1080 的视频帧,用 YUV420P 的格式来表示,其数据量的大小如下:
(1920 * 1080 * 1 + 1920 * 1080 * 0.5 ) / 1024 /1024 ≈ 2.966MB
如果 fps(1 s 的视频帧数量)是 25 ,按照 5 分钟的一个短视频来计算,那么这个短视频用 YUV420P 的数据格式来表示的话,其数据量的大小就是 :
2.966MB * 25fps * 5min * 60s / 1024 ≈ 21GB
可以看到仅仅 5 分钟的视频数据量就能达到 21 G, 像抖音,快手这样短视频领域的代表这样的话还不卡死,那么如何对短视频进行存储以及流媒体播放呢?答案肯定是需要进行视频编码,后面会介绍视频编码的内容。
视频的编码方式
视频编码
音频的编码主要是去除冗余信息,从而实现数据量的压缩。那么对于视频压缩,又该从哪几个方面来对数据进行压缩呢?其实与之前提到的音频编码类似,视频压缩也是通过去除冗余信息来进行压缩的。相较于音频数据,视频数据有极强的相关性,也就是说有大量的冗余信息,包括空间上的冗余信息和时间上的冗余信息,具体包括以下几个部分。
- 运动补偿: 运动补偿是通过先前的局部图像来预测,补偿当前的局部图像,它是减少帧序列冗余信息的有效方法。
- 运动表示: 不同区域的图像需要使用不同的运动矢量来描述运动信息。
- 运动估计: 运动估计是从视频序列中抽取运动信息的一整套技术。
使用帧内编码技术可以去除空间上的冗余信息。
大家还记得之前提到的图像编码 JPEG 吗?对于视频, ISO 同样也制定了标准: Motion JPEG 即 MPEG ,MPEG 算法是适用于动态视频的压缩算法,它除了对单幅图像进行编码外,还利用图像序列中的相关原则去除冗余,这样可以大大提高视频的压缩比,截至目前,MPEG 的版本一直在不断更新中,主要包括这样几个版本: Mpeg1(用于 VCD)、Mpeg2(用于 DVD)、Mpeg4 AVC(现在流媒体使用最多的就是它了)。
想比较 ISO 指定的 MPEG 的视频压缩标准,ITU-T 指定的 H.261、H.262、H.263、H.264 一系列视频编码标准是一套单独的体系。其中,H.264 集中了以往标准的所有优点,并吸取了以往标准的经验,采样的是简洁设计,这使得它比 Mpeg4 更容易推广。现在使用最多的就是 H.264 标准, H.264 创造了多参考帧、多块类型、整数变换、帧内预测等新的压缩技术,使用了更精准的分像素运动矢量(1/4、1/8) 和新一代的环路滤波器,这使得压缩性能得到大大提高,系统也变得更加完善。
编码概念
视频编码中,每帧都代表着一幅静止的图像。而在进行实际压缩时,会采取各种算法以减少数据的容量,其中 IPB 帧就是最常见的一种。
-
IPB 帧
- I 帧(intra picture): 表示关键帧,你可以理解为这一帧画面的完整保留,解码时只需要本帧数据就可以完成(包含完整画面)。
- P 帧(predictive[prə'dɪktɪv]-frame): 表示的是当前 P 帧与上一帧( I 帧或者 P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别生成最终画面。(也就是差别帧, P 帧没有完整画面数据,只有与前一帧的画面差别的数据。)
- B 帧(bi-directional interpolated [ɪnˈtɜrpəˌleɪt] prediction frame): 表示双向差别帧,也就是 B 帧记录的是当前帧与前后帧(前一个 I 帧或 P 帧和后面的 P 帧)的差别(具体比较复杂,有 4 种情况), 换言之,要解码 B 帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面数据与本帧数据的叠加取得最终的画面。B 帧压缩率高,但是解码时 CPU 会比较吃力。
-
IDR 帧与 I 帧的理解
在 H264 的概念中有一个帧称为 IDR 帧,那么 IDR 帧与 I 帧的区别是什么呢 ?
首先要看下 IDR 的英文全称 instantaneous decoding refresh picture , 因为 H264 采用了多帧预测,所以 I 帧之后的 P 帧有可能会参考 I 帧之前的帧,这就使得在随机访问的时候不能以找到 I 帧作为参考条件,因为即使找到 I 帧,I 帧之后的帧还是有可能解析不出来,而 IDR 帧就是一种特殊的 I 帧,即这一帧之后的所有参考帧只会参考到这个 IDR 帧,而不会再参考前面的帧。在解码器中,一旦收到第一个 IDR 帧,就会立即清理参考帧缓冲区,并将 IDR 帧作为被参考的帧。 -
PTS 与 DTS
DTS 主要用视频的解码,全称为(Decoding Time Stamp), PTS 主要用于解码阶段进行视频的同步和输出, 全称为 (Presentation Time Stamp) 。
在没有 B 帧的情况下, DTS 和 PTS 的输出顺序是一样的。因为 B 帧打乱了解码和显示的顺序,所以一旦存在 B 帧, PTS 与 DTS 势必就会不同。在大多数编解码标准(H.264 或者 HEVC) 中,编码顺序和输入顺序并不一致,于是才会需要 PTS 和 DTS 这两种不同的时间戳。 -
GOP 的概念
两个 I 帧之间形成的一组图片,就是 GOP (Group Of Picture) 的概念。通常在为编码器设置参数的时候,必须要设置 gop_size 的值,其代表的是两个 I 帧之间的帧数目。一个 GOP 中容量最大的帧就是 I 帧,所以相对来讲,gop_size 设置得越大,整个画面的质量就会越好,但是在解码端必须从接收到的第一个 I 帧开始才可以正确的解码出原始图像,否则会无法正确解码,在提高视频质量的技巧中,还有个技巧是多使用 B 帧,一般来说,I 的压缩率是 7 (与 JPG 差不多),P 是 20 ,B 可以达到 50 ,可见使用 B 帧能节省大量空间,节省出来的空间可以用来更多地保存 I 帧,这样就能在相同的码率下提供更好的画质,所以我们要根据不同的业务场景,适当地设置 gop_size 的大小,以得到更高质量的视频。
由于把视频编码成I,B,P等帧,如下图
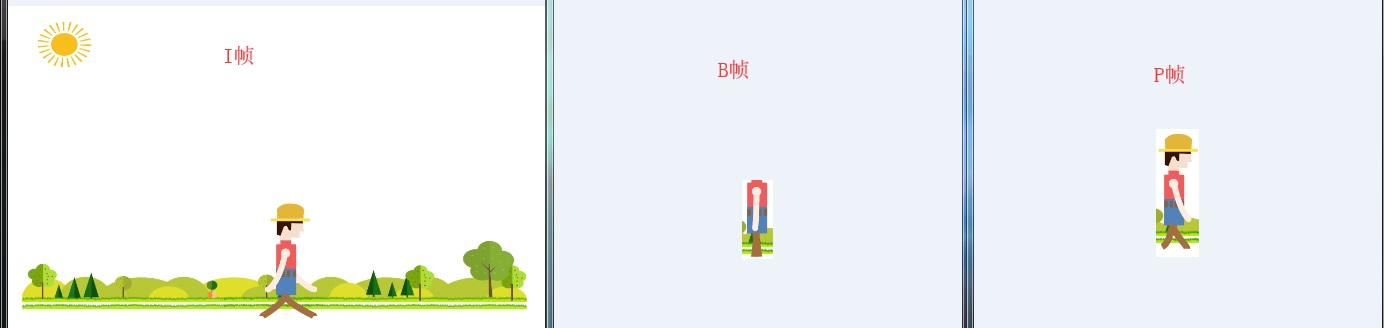
假设现在有I,B,P帧,那么要传输和显示呢??
如果按照显示顺序传输的话:
传输顺序就是I->B>P
当对B帧进行解码后,由于B帧无法单独显示,只能等待后面的P帧
如果不按照顺序传输,按照解码顺序传输的话:
传输顺序就是I->P->B
无论用哪种方式传输和显示,一旦有了B帧这个东西,就都需要告诉对方什么时候该显示这帧
于是就有了PTS和DTS,即Presentation Time Stamp和Decode Time Stamp
PTS告诉对方什么时候该显示这帧,而DTS则告诉什么时候该解码这帧
如果没有B帧的情况,PTS和DTS都是一样的:

有B帧的情况下,PTS和DTS才会不一致:

下面给出一个GOP为15的例子,其解码的参照frame及其解码的顺序都在里面:
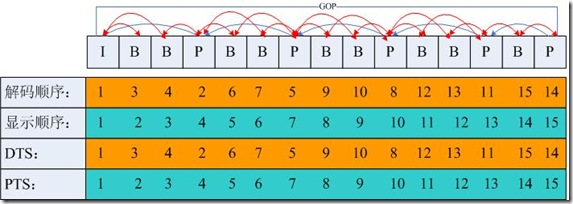
如上图:I frame 的解码不依赖于任何的其它的帧.而p frame的解码则依赖于其前面的I frame或者P frame.B frame的解码则依赖于其前的最近的一个I frame或者P frame 及其后的最近的一个P frame.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号