

声音类型识别库运行环境搭建
1)安装Anaconda
https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
Anaconda 是一个用于科学计算的 Python 发行版,支持 Linux, Mac, Windows, 包含了众多流行的科学计算、数据分析的 Python 包。
支持python运行环境创建,不同环境之间可以切换,默认集成了base运行环境。
需要配置的环境变量:
D:\wzrui\Anaconda3\;
D:\wzrui\Anaconda3\Scripts\;
D:\wzrui\Anaconda3\Library\bin;
2)修改包下载镜像地址(conda)
2.1) 命令行运行指令生成用户配置文件(windows)
conda config --set show_channel_urls yes
2.2) 将网址中的代码拷贝到用户目录下的.condarc 文件
网址:https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
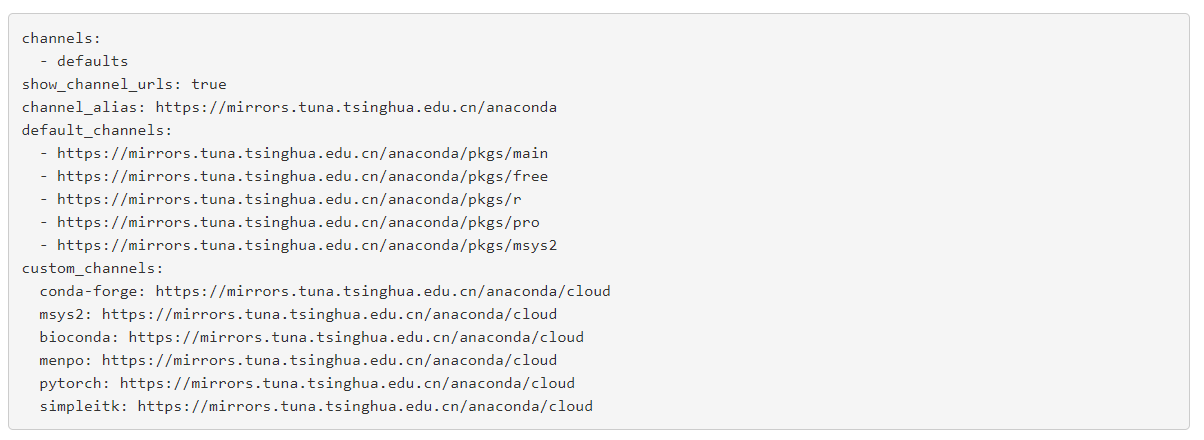
2.3)pip设置默认国内镜像,当使用pip安装时用
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
3)激活base默认环境

4)安装如下的库

numpy==1.17.4
matplotlib==3.1.1
requests==2.23.0
torchlibrosa==0.0.4
torchsummary==1.5.1
librosa==0.6.3
librosa需要采用如下的安装方式,普通方法安装不上。
conda install -c conda-forge librosa
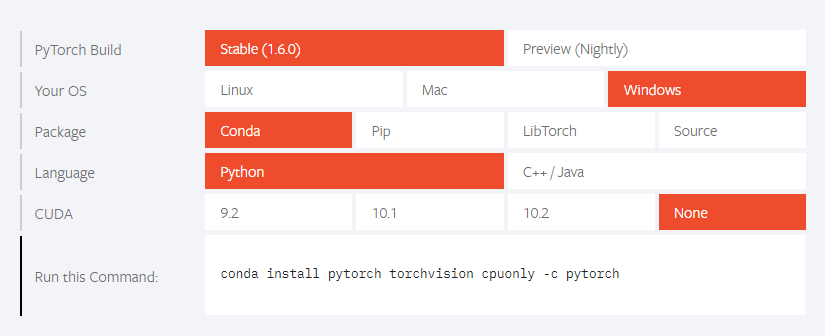
5)安装torch==1.2.0库
通过官网https://pytorch.org/生成安装指令
6)运行获取声音类型
python predict.py --data_url 音频文件地址
结果保存在当前文件夹中的predict_result.txt文件中,多个类别的声音会用空格隔开,例如 演讲 0.48067293 音乐 0.10661166 箭头 0.09293184,
前面为标签后面为标签的置信度。
