dya6小数据池、集合、编码、深浅copy
一、小知识点:
1、id:测试内容的内存地址
s = 'abc' print(id(s) 》》》 2174306953568
2、is:判断内存地址是否相等
s = 'abc' s1 = 'abc' print(s is s1) 》》》 Ture
3、小数据池:共用相同的id(也就是如果在这个范围内,a ,b 分别被赋予相同的值的话,那么他们的内存地址相同)
int:-5~~~256存在小数据池概念
str:只包含数字或者字母元素的,单个字母*int(20以内)存在小数据池概念
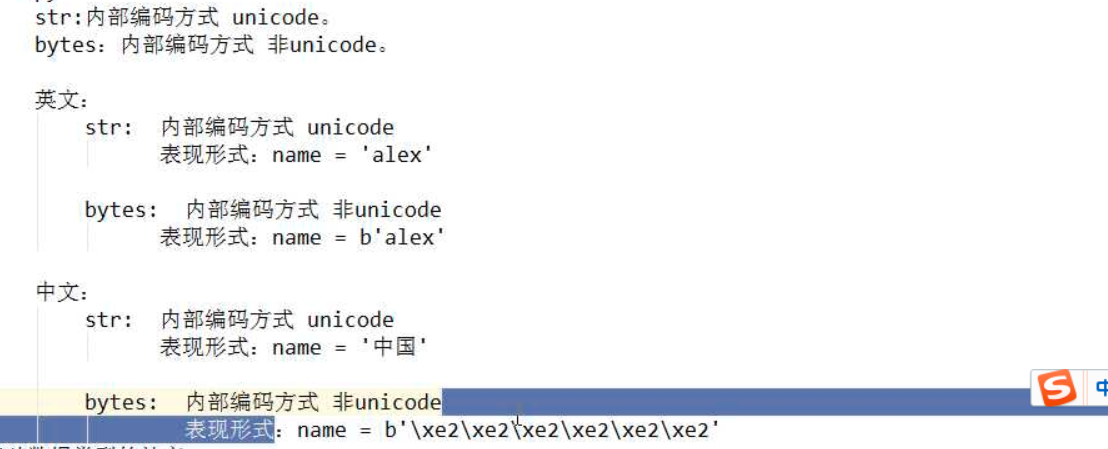
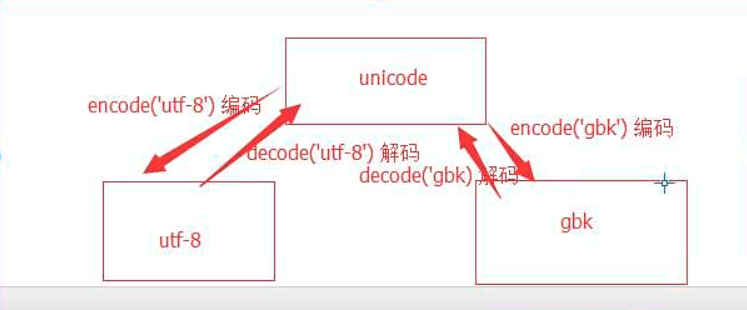
4、编码归类


5、元组的补充知识点
当元组内只包含一个元素时,此元组的type类型不是元组,而是对应元素的type类型,例:
tuple1 = (1) tuple2 = ('wangjifei') tuple3 = ([1,2,3]) print(type(tuple1)) print(type(tuple2)) print(type(tuple3)) 》》》 <class 'int'> <class 'str'> <class 'list'>
6、字典和元组之间的转换:
字典可以转化为列表,但是转化成的列表只包含key值,没有对应的value值,但是列表不能转化为字典
dic = {'k1': 'v1','v1':111, 'k2': 'v2','k3': 'v3','name': 'wangjifei'}
print(list(dic))
》》》
['k1', 'v1', 'k2', 'k3', 'name']
二、集合:
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合set(),就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系
根据集合的特点,可以判断集合内的元素只能是数字、字符串、元组、bool值。
1、集合的创建:空集合为 set():单个{}为空字典
set1 = {1,2,(1,2,3),'wangjifei',False}
print(set1,type(set1),len(set1))
》》》
{False, 1, 2, 'wangjifei', (1, 2, 3)} <class 'set'> 5
2、增加 add(),update()迭代增加
set1 = {1,2,(1,2,3),'wangjifei'}
set1.add('alex')
print(set1)
set1.update('我是中国人')
print(set1)
》》》
{1, 2, (1, 2, 3), 'alex', 'wangjifei'}
{1, 2, '国', '我', '人', (1, 2, 3), '是', '中', 'alex', 'wangjifei'}
3、集合的删除 remove(),pop(),clear(),del
set1 = {'alex','wusir','ritian','egon','barry'}
set1.remove('alex') # 删除一个元素
print(set1)
set1.pop() # 随机删除一个元素
print(set1)
set1.clear() # 清空集合
print(set1)
del set1 # 删除集合
print(set1)
4、集合的其他操作:
4.1 交集。(& 或者 intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
4.2 并集。(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7}
4.3 差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
4.4 反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
4.5 子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
5、frozenset不可变集合,让集合变成不可变类型。
set = {1,'wangjifei'}
s = frozenset(set)
print(s,type(s)) # frozenset({1, 'wangjifei'}) <class 'frozenset'>
三、 深浅copy:
1、先来看赋值运算:
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的。
l1 = [1,2,3,['barry','alex']] l2 = l1 l1[0] = 111 print(l1) # [111, 2, 3, ['barry', 'alex']] print(l2) # [111, 2, 3, ['barry', 'alex']] l1[3][0] = 'wusir' print(l1) # [111, 2, 3, ['wusir', 'alex']] print(l2) # [111, 2, 3, ['wusir', 'alex']]
2、浅拷贝copy:
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性
l1 = [1,2,3,['barry','alex']] l2 = l1.copy() print(l1,id(l1)) # [1, 2, 3, ['barry', 'alex']] 2380296895816 print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2380296895048 l1[1] = 222 print(l1,id(l1)) # [1, 222, 3, ['barry', 'alex']] 2593038941128 print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2593038941896 l1[3][0] = 'wusir' print(l1,id(l1[3])) # [1, 2, 3, ['wusir', 'alex']] 1732315659016 print(l2,id(l2[3])) # [1, 2, 3, ['wusir', 'alex']] 1732315659016
3、深拷贝deepcopy:
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
import copy l1 = [1,2,3,['barry','alex']] l2 = copy.deepcopy(l1) print(l1,id(l1)) # [1, 2, 3, ['barry', 'alex']] 2915377167816 print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2915377167048 l1[1] = 222 print(l1,id(l1)) # [1, 222, 3, ['barry', 'alex']] 2915377167816 print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2915377167048 l1[3][0] = 'wusir' print(l1,id(l1[3])) # [1, 222, 3, ['wusir', 'alex']] 2915377167240 print(l2,id(l2[3])) # [1, 2, 3, ['barry', 'alex']] 2915377167304

 浙公网安备 33010602011771号
浙公网安备 33010602011771号