
2.Linux文件IO编程
2.1Linux文件IO概述
2.1.0POSIX规范
POSIX:(Portable Operating System Interface)可移植操作系统接口规范。
由IEEE制定,是为了提高UNIX(也适用于Linux)环境下应用程序的可移植性。
2.1.1虚拟文件系统
Linux具有与其他操作系统和谐共存的能力。
Linux文件系统由两层构建:第一层是虚拟文件系统(VFS),第二层是各种不同的具体的文件系统。
VFS把各种具体的文件系统的公共部分抽取出来,形成一个抽象层,是系统内核的一部分。
位于用户程序和具体的文件系统之间,为用户程序提供标准的文件系统调用接口。对用户屏蔽底层文件系统的实现细节和差异。



1 nodev sysfs 2 nodev rootfs 3 nodev ramfs 4 nodev bdev 5 nodev proc 6 nodev cpuset 7 nodev cgroup 8 nodev tmpfs 9 nodev devtmpfs 10 nodev debugfs 11 nodev tracefs 12 nodev securityfs 13 nodev sockfs 14 nodev bpf 15 nodev pipefs 16 nodev devpts 17 ext3 18 ext2 19 ext4 20 squashfs 21 nodev hugetlbfs 22 vfat 23 nodev ecryptfs 24 fuseblk 25 nodev fuse 26 nodev fusectl 27 nodev pstore 28 nodev mqueue 29 nodev rpc_pipefs 30 nodev nfs 31 nodev nfs4 32 nodev nfsd
2.1.2 文件和文件描述符
Linux文件系统是基于文件概念的。文件是以字符序列构成的信息载体。可以把IO设备当做文件来处理。
Linux中的文件主要分为6种:普通文件、目录文件、符号链接文件、管道文件、套接字文件和设备文件。
一个进程启动时,都会打开3个流,标准输入、标准输出和标准错误。
对应的文件描述符0、1、2,宏分别STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO。
2.1.3 文件IO和标准IO的区别
1.只要在开发环境中有标准C库,标准IO就可以使用。Linux既可以使用标准IO,也可以使用文件IO。
2.通过文件IO读写文件时,每次操作都会执行相关系统调用。好处:直接读写实际文件。坏处:频繁的系统调用会增加系统开销。
3.文件IO中用文件描述符表示一个打开的文件,可以访问不同类型的文件(普通文件、管道文件、设备文件等)。
标准IO中用FILE(流)表示一个打开的文件,通常只是用来访问普通文件。
2.2文件IO操作
主要介绍文件IO相关函数:open()、read()、write()、lseek()和close()。它们不带缓冲,直接对文件(包括设备)进行读写操作。
2.2.1 文件打开和关闭
打开:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
说明:open用于创建或打开文件,在打开或创建文件时可以指定文件打开方式及文件的访问权限。
关闭: int close(int fd);
说明:用于关闭一个被打开的文件。当一个进程终止时,所有打开的文件都有内核自动关闭。
很多程序都利用这一特性而不显式地关闭一个文件。
1 /******************************************************************* 2 * > File Name: 01-open.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Sun 03 Sep 2017 09:01:10 PM CST 6 ******************************************************************/ 7 8 #include <stdio.h> 9 #include <sys/types.h> 10 #include <sys/stat.h> 11 #include <fcntl.h> 12 #include <unistd.h> 13 14 int main(int argc, char* argv[]) 15 { 16 int fd; 17 18 if((fd = open("test.txt", O_RDWR|O_CREAT|O_TRUNC, 0666)) < 0){ 19 perror("Fail to open test.txt :"); 20 return (-1); 21 }else{ 22 printf("Succeed to open test.txt, fd = %d\n ", fd); 23 } 24 25 close(fd); 26 27 return 0; 28 }
1 OPEN(2) Linux Programmer's Manual OPEN(2) 2 3 4 5 NAME 6 open, creat - open and possibly create a file or device 7 8 SYNOPSIS 9 #include <sys/types.h> 10 #include <sys/stat.h> 11 #include <fcntl.h> 12 13 int open(const char *pathname, int flags); 14 int open(const char *pathname, int flags, mode_t mode); 15 16 int creat(const char *pathname, mode_t mode); 17 18 DESCRIPTION 19 Given a pathname for a file, open() returns a file descriptor, a small, nonnegative integer for use in subse‐ 20 quent system calls (read(2), write(2), lseek(2), fcntl(2), etc.). The file descriptor returned by a success‐ 21 ful call will be the lowest-numbered file descriptor not currently open for the process. 22 23 By default, the new file descriptor is set to remain open across an execve(2) (i.e., the FD_CLOEXEC file 24 descriptor flag described in fcntl(2) is initially disabled; the O_CLOEXEC flag, described below, can be used 25 to change this default). The file offset is set to the beginning of the file (see lseek(2)). 26 27 A call to open() creates a new open file description, an entry in the system-wide table of open files. This 28 entry records the file offset and the file status flags (modifiable via the fcntl(2) F_SETFL operation). A 29 file descriptor is a reference to one of these entries; this reference is unaffected if pathname is subse‐ 30 quently removed or modified to refer to a different file. The new open file description is initially not 31 shared with any other process, but sharing may arise via fork(2). 32 33 The argument flags must include one of the following access modes: O_RDONLY, O_WRONLY, or O_RDWR. These 34 request opening the file read-only, write-only, or read/write, respectively. 35 36 In addition, zero or more file creation flags and file status flags can be bitwise-or'd in flags. The file 37 creation flags are O_CLOEXEC, O_CREAT, O_DIRECTORY, O_EXCL, O_NOCTTY, O_NOFOLLOW, O_TRUNC, and O_TTY_INIT. 38 The file status flags are all of the remaining flags listed below. The distinction between these two groups 39 of flags is that the file status flags can be retrieved and (in some cases) modified using fcntl(2). The 40 full list of file creation flags and file status flags is as follows: 41 42 O_APPEND 43 The file is opened in append mode. Before each write(2), the file offset is positioned at the end of 44 the file, as if with lseek(2). O_APPEND may lead to corrupted files on NFS filesystems if more than 45 one process appends data to a file at once. This is because NFS does not support appending to a file, 46 so the client kernel has to simulate it, which can't be done without a race condition. 47 48 O_ASYNC 49 Enable signal-driven I/O: generate a signal (SIGIO by default, but this can be changed via fcntl(2)) 50 when input or output becomes possible on this file descriptor. This feature is available only for 51 terminals, pseudoterminals, sockets, and (since Linux 2.6) pipes and FIFOs. See fcntl(2) for further 52 details. 53 54 O_CLOEXEC (Since Linux 2.6.23) 55 Enable the close-on-exec flag for the new file descriptor. Specifying this flag permits a program to 56 avoid additional fcntl(2) F_SETFD operations to set the FD_CLOEXEC flag. Additionally, use of this 57 flag is essential in some multithreaded programs since using a separate fcntl(2) F_SETFD operation to 58 set the FD_CLOEXEC flag does not suffice to avoid race conditions where one thread opens a file 59 descriptor at the same time as another thread does a fork(2) plus execve(2). 60 61 O_CREAT 62 If the file does not exist it will be created. The owner (user ID) of the file is set to the effec‐ 63 tive user ID of the process. The group ownership (group ID) is set either to the effective group ID 64 of the process or to the group ID of the parent directory (depending on filesystem type and mount 65 options, and the mode of the parent directory, see the mount options bsdgroups and sysvgroups 66 described in mount(8)). 67 68 mode specifies the permissions to use in case a new file is created. This argument must be supplied 69 when O_CREAT is specified in flags; if O_CREAT is not specified, then mode is ignored. The effective 70 permissions are modified by the process's umask in the usual way: The permissions of the created file 71 are (mode & ~umask). Note that this mode applies only to future accesses of the newly created file; 72 the open() call that creates a read-only file may well return a read/write file descriptor. 73 74 The following symbolic constants are provided for mode: 75 76 S_IRWXU 00700 user (file owner) has read, write and execute permission 77 78 S_IRUSR 00400 user has read permission 79 80 S_IWUSR 00200 user has write permission 81 82 S_IXUSR 00100 user has execute permission 83 84 S_IRWXG 00070 group has read, write and execute permission 85 86 S_IRGRP 00040 group has read permission 87 88 S_IWGRP 00020 group has write permission 89 90 S_IXGRP 00010 group has execute permission 91 92 S_IRWXO 00007 others have read, write and execute permission 93 94 S_IROTH 00004 others have read permission 95 96 S_IWOTH 00002 others have write permission 97 98 S_IXOTH 00001 others have execute permission 99 100 O_DIRECT (Since Linux 2.4.10) 101 Try to minimize cache effects of the I/O to and from this file. In general this will degrade perfor‐ 102 mance, but it is useful in special situations, such as when applications do their own caching. File 103 I/O is done directly to/from user-space buffers. The O_DIRECT flag on its own makes an effort to 104 transfer data synchronously, but does not give the guarantees of the O_SYNC flag that data and neces‐ 105 sary metadata are transferred. To guarantee synchronous I/O, O_SYNC must be used in addition to 106 O_DIRECT. See NOTES below for further discussion. 107 108 A semantically similar (but deprecated) interface for block devices is described in raw(8). 109 110 O_DIRECTORY 111 If pathname is not a directory, cause the open to fail. This flag is Linux-specific, and was added in 112 kernel version 2.1.126, to avoid denial-of-service problems if opendir(3) is called on a FIFO or tape 113 device. 114 115 O_EXCL Ensure that this call creates the file: if this flag is specified in conjunction with O_CREAT, and 116 pathname already exists, then open() will fail. 117 118 When these two flags are specified, symbolic links are not followed: if pathname is a symbolic link, 119 then open() fails regardless of where the symbolic link points to. 120 121 In general, the behavior of O_EXCL is undefined if it is used without O_CREAT. There is one excep‐ 122 tion: on Linux 2.6 and later, O_EXCL can be used without O_CREAT if pathname refers to a block device. 123 If the block device is in use by the system (e.g., mounted), open() fails with the error EBUSY. 124 125 On NFS, O_EXCL is supported only when using NFSv3 or later on kernel 2.6 or later. In NFS environ‐ 126 ments where O_EXCL support is not provided, programs that rely on it for performing locking tasks will 127 contain a race condition. Portable programs that want to perform atomic file locking using a lock‐ 128 file, and need to avoid reliance on NFS support for O_EXCL, can create a unique file on the same 129 filesystem (e.g., incorporating hostname and PID), and use link(2) to make a link to the lockfile. If 130 link(2) returns 0, the lock is successful. Otherwise, use stat(2) on the unique file to check if its 131 link count has increased to 2, in which case the lock is also successful. 132 133 O_LARGEFILE 134 (LFS) Allow files whose sizes cannot be represented in an off_t (but can be represented in an off64_t) 135 to be opened. The _LARGEFILE64_SOURCE macro must be defined (before including any header files) in 136 order to obtain this definition. Setting the _FILE_OFFSET_BITS feature test macro to 64 (rather than 137 using O_LARGEFILE) is the preferred method of accessing large files on 32-bit systems (see fea‐ 138 ture_test_macros(7)). 139 140 O_NOATIME (Since Linux 2.6.8) 141 Do not update the file last access time (st_atime in the inode) when the file is read(2). This flag 142 is intended for use by indexing or backup programs, where its use can significantly reduce the amount 143 of disk activity. This flag may not be effective on all filesystems. One example is NFS, where the 144 server maintains the access time. 145 146 O_NOCTTY 147 If pathname refers to a terminal device—see tty(4)—it will not become the process's controlling termi‐ 148 nal even if the process does not have one. 149 150 O_NOFOLLOW 151 If pathname is a symbolic link, then the open fails. This is a FreeBSD extension, which was added to 152 Linux in version 2.1.126. Symbolic links in earlier components of the pathname will still be fol‐ 153 lowed. See also O_NOPATH below. 154 155 O_NONBLOCK or O_NDELAY 156 When possible, the file is opened in nonblocking mode. Neither the open() nor any subsequent opera‐ 157 tions on the file descriptor which is returned will cause the calling process to wait. For the han‐ 158 dling of FIFOs (named pipes), see also fifo(7). For a discussion of the effect of O_NONBLOCK in con‐ 159 junction with mandatory file locks and with file leases, see fcntl(2). 160 161 O_PATH (since Linux 2.6.39) 162 Obtain a file descriptor that can be used for two purposes: to indicate a location in the filesystem 163 tree and to perform operations that act purely at the file descriptor level. The file itself is not 164 opened, and other file operations (e.g., read(2), write(2), fchmod(2), fchown(2), fgetxattr(2), 165 mmap(2)) fail with the error EBADF. 166 167 The following operations can be performed on the resulting file descriptor: 168 169 * close(2); fchdir(2) (since Linux 3.5); fstat(2) (since Linux 3.6). 170 171 * Duplicating the file descriptor (dup(2), fcntl(2) F_DUPFD, etc.). 172 173 * Getting and setting file descriptor flags (fcntl(2) F_GETFD and F_SETFD). 174 175 * Retrieving open file status flags using the fcntl(2) F_GETFL operation: the returned flags will 176 include the bit O_PATH. 177 178 179 * Passing the file descriptor as the dirfd argument of openat(2) and the other "*at()" system calls. 180 181 * Passing the file descriptor to another process via a UNIX domain socket (see SCM_RIGHTS in 182 unix(7)). 183 184 When O_PATH is specified in flags, flag bits other than O_DIRECTORY and O_NOFOLLOW are ignored. 185 186 If the O_NOFOLLOW flag is also specified, then the call returns a file descriptor referring to the 187 symbolic link. This file descriptor can be used as the dirfd argument in calls to fchownat(2), 188 fstatat(2), linkat(2), and readlinkat(2) with an empty pathname to have the calls operate on the sym‐ 189 bolic link. 190 191 O_SYNC The file is opened for synchronous I/O. Any write(2)s on the resulting file descriptor will block the 192 calling process until the data has been physically written to the underlying hardware. But see NOTES 193 below. 194 195 O_TRUNC 196 If the file already exists and is a regular file and the open mode allows writing (i.e., is O_RDWR or 197 O_WRONLY) it will be truncated to length 0. If the file is a FIFO or terminal device file, the 198 O_TRUNC flag is ignored. Otherwise the effect of O_TRUNC is unspecified. 199 200 Some of these optional flags can be altered using fcntl(2) after the file has been opened. 201 202 creat() is equivalent to open() with flags equal to O_CREAT|O_WRONLY|O_TRUNC. 203 204 RETURN VALUE 205 open() and creat() return the new file descriptor, or -1 if an error occurred (in which case, errno is set 206 appropriately). 207 208 ERRORS 209 EACCES The requested access to the file is not allowed, or search permission is denied for one of the direc‐ 210 tories in the path prefix of pathname, or the file did not exist yet and write access to the parent 211 directory is not allowed. (See also path_resolution(7).) 212 213 EDQUOT Where O_CREAT is specified, the file does not exist, and the user's quota of disk blocks or inodes on 214 the filesystem has been exhausted. 215 216 EEXIST pathname already exists and O_CREAT and O_EXCL were used. 217 218 EFAULT pathname points outside your accessible address space. 219 220 EFBIG See EOVERFLOW. 221 222 EINTR While blocked waiting to complete an open of a slow device (e.g., a FIFO; see fifo(7)), the call was 223 interrupted by a signal handler; see signal(7). 224 225 EINVAL The filesystem does not support the O_DIRECT flag. See NOTES for more information. 226 227 EISDIR pathname refers to a directory and the access requested involved writing (that is, O_WRONLY or O_RDWR 228 is set). 229 230 ELOOP Too many symbolic links were encountered in resolving pathname, or O_NOFOLLOW was specified but path‐ 231 name was a symbolic link. 232 233 EMFILE The process already has the maximum number of files open. 234 235 ENAMETOOLONG 236 pathname was too long. 237 238 ENFILE The system limit on the total number of open files has been reached. 239 240 ENODEV pathname refers to a device special file and no corresponding device exists. (This is a Linux kernel 241 bug; in this situation ENXIO must be returned.) 242 243 ENOENT O_CREAT is not set and the named file does not exist. Or, a directory component in pathname does not 244 exist or is a dangling symbolic link. 245 246 ENOMEM Insufficient kernel memory was available. 247 248 ENOSPC pathname was to be created but the device containing pathname has no room for the new file. 249 250 ENOTDIR 251 A component used as a directory in pathname is not, in fact, a directory, or O_DIRECTORY was specified 252 and pathname was not a directory. 253 254 ENXIO O_NONBLOCK | O_WRONLY is set, the named file is a FIFO and no process has the file open for reading. 255 Or, the file is a device special file and no corresponding device exists. 256 257 EOVERFLOW 258 pathname refers to a regular file that is too large to be opened. The usual scenario here is that an 259 application compiled on a 32-bit platform without -D_FILE_OFFSET_BITS=64 tried to open a file whose 260 size exceeds (2<<31)-1 bits; see also O_LARGEFILE above. This is the error specified by POSIX.1-2001; 261 in kernels before 2.6.24, Linux gave the error EFBIG for this case. 262 263 EPERM The O_NOATIME flag was specified, but the effective user ID of the caller did not match the owner of 264 the file and the caller was not privileged (CAP_FOWNER). 265 266 EROFS pathname refers to a file on a read-only filesystem and write access was requested. 267 268 ETXTBSY 269 pathname refers to an executable image which is currently being executed and write access was 270 requested. 271 272 EWOULDBLOCK 273 The O_NONBLOCK flag was specified, and an incompatible lease was held on the file (see fcntl(2)). 274 275 CONFORMING TO 276 SVr4, 4.3BSD, POSIX.1-2001. The O_DIRECTORY, O_NOATIME, O_NOFOLLOW, and O_PATH flags are Linux-specific, and 277 one may need to define _GNU_SOURCE (before including any header files) to obtain their definitions. 278 279 The O_CLOEXEC flag is not specified in POSIX.1-2001, but is specified in POSIX.1-2008. 280 281 O_DIRECT is not specified in POSIX; one has to define _GNU_SOURCE (before including any header files) to get 282 its definition. 283 284 NOTES 285 Under Linux, the O_NONBLOCK flag indicates that one wants to open but does not necessarily have the intention 286 to read or write. This is typically used to open devices in order to get a file descriptor for use with 287 ioctl(2). 288 289 Unlike the other values that can be specified in flags, the access mode values O_RDONLY, O_WRONLY, and 290 O_RDWR, do not specify individual bits. Rather, they define the low order two bits of flags, and are defined 291 respectively as 0, 1, and 2. In other words, the combination O_RDONLY | O_WRONLY is a logical error, and 292 certainly does not have the same meaning as O_RDWR. Linux reserves the special, nonstandard access mode 3 293 (binary 11) in flags to mean: check for read and write permission on the file and return a descriptor that 294 can't be used for reading or writing. This nonstandard access mode is used by some Linux drivers to return a 295 descriptor that is to be used only for device-specific ioctl(2) operations. 296 297 The (undefined) effect of O_RDONLY | O_TRUNC varies among implementations. On many systems the file is actu‐ 298 ally truncated. 299 300 There are many infelicities in the protocol underlying NFS, affecting amongst others O_SYNC and O_NDELAY. 301 302 POSIX provides for three different variants of synchronized I/O, corresponding to the flags O_SYNC, O_DSYNC, 303 and O_RSYNC. Currently (2.6.31), Linux implements only O_SYNC, but glibc maps O_DSYNC and O_RSYNC to the 304 same numerical value as O_SYNC. Most Linux filesystems don't actually implement the POSIX O_SYNC semantics, 305 which require all metadata updates of a write to be on disk on returning to user space, but only the O_DSYNC 306 semantics, which require only actual file data and metadata necessary to retrieve it to be on disk by the 307 time the system call returns. 308 309 Note that open() can open device special files, but creat() cannot create them; use mknod(2) instead. 310 311 On NFS filesystems with UID mapping enabled, open() may return a file descriptor but, for example, read(2) 312 requests are denied with EACCES. This is because the client performs open() by checking the permissions, but 313 UID mapping is performed by the server upon read and write requests. 314 315 If the file is newly created, its st_atime, st_ctime, st_mtime fields (respectively, time of last access, 316 time of last status change, and time of last modification; see stat(2)) are set to the current time, and so 317 are the st_ctime and st_mtime fields of the parent directory. Otherwise, if the file is modified because of 318 the O_TRUNC flag, its st_ctime and st_mtime fields are set to the current time. 319 320 O_DIRECT 321 The O_DIRECT flag may impose alignment restrictions on the length and address of user-space buffers and the 322 file offset of I/Os. In Linux alignment restrictions vary by filesystem and kernel version and might be 323 absent entirely. However there is currently no filesystem-independent interface for an application to dis‐ 324 cover these restrictions for a given file or filesystem. Some filesystems provide their own interfaces for 325 doing so, for example the XFS_IOC_DIOINFO operation in xfsctl(3). 326 327 Under Linux 2.4, transfer sizes, and the alignment of the user buffer and the file offset must all be multi‐ 328 ples of the logical block size of the filesystem. Under Linux 2.6, alignment to 512-byte boundaries suf‐ 329 fices. 330 331 O_DIRECT I/Os should never be run concurrently with the fork(2) system call, if the memory buffer is a pri‐ 332 vate mapping (i.e., any mapping created with the mmap(2) MAP_PRIVATE flag; this includes memory allocated on 333 the heap and statically allocated buffers). Any such I/Os, whether submitted via an asynchronous I/O inter‐ 334 face or from another thread in the process, should be completed before fork(2) is called. Failure to do so 335 can result in data corruption and undefined behavior in parent and child processes. This restriction does 336 not apply when the memory buffer for the O_DIRECT I/Os was created using shmat(2) or mmap(2) with the 337 MAP_SHARED flag. Nor does this restriction apply when the memory buffer has been advised as MADV_DONTFORK 338 with madvise(2), ensuring that it will not be available to the child after fork(2). 339 340 The O_DIRECT flag was introduced in SGI IRIX, where it has alignment restrictions similar to those of Linux 341 2.4. IRIX has also a fcntl(2) call to query appropriate alignments, and sizes. FreeBSD 4.x introduced a 342 flag of the same name, but without alignment restrictions. 343 344 O_DIRECT support was added under Linux in kernel version 2.4.10. Older Linux kernels simply ignore this 345 flag. Some filesystems may not implement the flag and open() will fail with EINVAL if it is used. 346 347 Applications should avoid mixing O_DIRECT and normal I/O to the same file, and especially to overlapping byte 348 regions in the same file. Even when the filesystem correctly handles the coherency issues in this situation, 349 overall I/O throughput is likely to be slower than using either mode alone. Likewise, applications should 350 avoid mixing mmap(2) of files with direct I/O to the same files. 351 352 The behaviour of O_DIRECT with NFS will differ from local filesystems. Older kernels, or kernels configured 353 in certain ways, may not support this combination. The NFS protocol does not support passing the flag to the 354 server, so O_DIRECT I/O will bypass the page cache only on the client; the server may still cache the I/O. 355 The client asks the server to make the I/O synchronous to preserve the synchronous semantics of O_DIRECT. 356 Some servers will perform poorly under these circumstances, especially if the I/O size is small. Some 357 servers may also be configured to lie to clients about the I/O having reached stable storage; this will avoid 358 the performance penalty at some risk to data integrity in the event of server power failure. The Linux NFS 359 client places no alignment restrictions on O_DIRECT I/O. 360 361 In summary, O_DIRECT is a potentially powerful tool that should be used with caution. It is recommended that 362 applications treat use of O_DIRECT as a performance option which is disabled by default. 363 364 "The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid, and 365 was probably designed by a deranged monkey on some serious mind-controlling substances."—Linus 366 367 BUGS 368 Currently, it is not possible to enable signal-driven I/O by specifying O_ASYNC when calling open(); use 369 fcntl(2) to enable this flag. 370 371 SEE ALSO 372 chmod(2), chown(2), close(2), dup(2), fcntl(2), link(2), lseek(2), mknod(2), mmap(2), mount(2), openat(2), 373 read(2), socket(2), stat(2), umask(2), unlink(2), write(2), fopen(3), fifo(7), path_resolution(7), symlink(7) 374 375 COLOPHON 376 This page is part of release 3.54 of the Linux man-pages project. A description of the project, and informa‐ 377 tion about reporting bugs, can be found at http://www.kernel.org/doc/man-pages/. 378 379 380 381 Linux 2013-08-09 OPEN(2)
2.2.2 文件读写
ssize_t read(int fd, void *buf, size_t count);
说明:read函数从文件中读取数据存放到缓冲区中,并返回实际读取的字节数。若返回0,则表示没有数据可读,
即已达到文件尾。读操作从文件的当前读写位置开始读取内容,当前读写位置自动往后移动。
ssize_t write(int fd, const void *buf, size_t count);
说明:write函数将数据写入文件中,并将返回实际写入的字节数。写操作从文件的当前读写位置开始写入。
对磁盘文件进行写操作时,若磁盘已满,返回失败。
1 /******************************************************************* 2 * > File Name: 02-read.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Sun 03 Sep 2017 09:41:03 PM CST 6 ******************************************************************/ 7 8 #include <stdio.h> 9 #include <sys/types.h> 10 #include <sys/stat.h> 11 #include <fcntl.h> 12 #include <unistd.h> 13 14 #define N 64 15 16 int main(int argc, char* argv[]) 17 { 18 int fd, nbyte, sum = 0; 19 char buf[N]; 20 21 /*1.判断命令行参数*/ 22 if(argc < 2){ 23 printf("Usage : %s <file_name>\n", argv[0]); 24 return (-1); 25 } 26 27 /*2.打开文件*/ 28 if((fd = open(argv[1], O_RDONLY)) < 0){ 29 perror("Fail to open :"); 30 return (-1); 31 } 32 33 /*3.循环读取文件,累加读到的字节数*/ 34 while((nbyte = read(fd, buf, N)) > 0){ 35 sum += nbyte; 36 } 37 38 printf("The length of %s is %d bytes\n", argv[0], sum); 39 40 close(fd); 41 42 return 0; 43 }
2.2.3文件定位
off_t lseek(int fd, off_t offset, int whence);
offset(@param):相对基准点whence的偏移量,以字节为单位,正数表示向前移动,负数表示向后移动;
whence:SEEK_SET:文件的起始位置;SEEK_CUR:文件的当前读写位置;SEEK_END:文件的结束位置;
说明:lseek函数对文件当前读写位置进行定位。它只能对可定位(可随机访问)文件操作。
管道、套接字和大部分字符设备文件不支持此类访问。
1 /******************************************************************* 2 * > File Name: 05-lseek.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Mon 04 Sep 2017 11:49:08 PM CST 6 ******************************************************************/ 7 8 #include <stdio.h> 9 #include <sys/types.h> 10 #include <sys/stat.h> 11 #include <fcntl.h> 12 #include <unistd.h> 13 #include <stdlib.h> 14 15 #define BUFFER_SIZE (1024*1) /*每次读写缓存大小,影响运行效率*/ 16 #define SRC_FILE_NAME "src_file" /*源文件名*/ 17 #define DEST_FILE_NAME "dst_file" /*目标文件名*/ 18 #define OFFSET (1024*10) /*复制的数据大小*/ 19 20 int main(int argc, char* argv[]) 21 { 22 int fds, fdd; 23 unsigned char buff[BUFFER_SIZE]; 24 int read_len; 25 26 /*1.以只读方式打开源文件*/ 27 if((fds = open(SRC_FILE_NAME, O_RDONLY)) < 0){ 28 perror("Fail to open src_file :"); 29 return (-1); 30 } 31 32 /*2.以只写方式打开目标文件,若此文件不存在则创建,访问权限644*/ 33 if((fdd = open(DEST_FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0644)) < 0){ 34 perror("Fail to open dest_file :"); 35 return (-1); 36 } 37 38 /*3.将源文件的读写指针移到最后10KB的起始位置*/ 39 lseek(fds , -OFFSET, SEEK_END); 40 41 /*4.读取源文件的最后10KB数据并写入目标文件,每次读写1KB*/ 42 while((read_len = read(fds, buff, sizeof(buff))) > 0){ 43 write(fdd, buff, read_len); 44 } 45 46 close(fds); 47 close(fdd); 48 49 return 0; 50 }
1 LSEEK(2) Linux Programmer's Manual LSEEK(2) 2 3 4 5 NAME 6 lseek - reposition read/write file offset 7 8 SYNOPSIS 9 #include <sys/types.h> 10 #include <unistd.h> 11 12 off_t lseek(int fd, off_t offset, int whence); 13 14 DESCRIPTION 15 The lseek() function repositions the offset of the open file associated with the file descriptor fd to the 16 argument offset according to the directive whence as follows: 17 18 SEEK_SET 19 The offset is set to offset bytes. 20 21 SEEK_CUR 22 The offset is set to its current location plus offset bytes. 23 24 SEEK_END 25 The offset is set to the size of the file plus offset bytes. 26 27 The lseek() function allows the file offset to be set beyond the end of the file (but this does not change 28 the size of the file). If data is later written at this point, subsequent reads of the data in the gap (a 29 "hole") return null bytes ('\0') until data is actually written into the gap. 30 31 Seeking file data and holes 32 Since version 3.1, Linux supports the following additional values for whence: 33 34 SEEK_DATA 35 Adjust the file offset to the next location in the file greater than or equal to offset containing 36 data. If offset points to data, then the file offset is set to offset. 37 38 SEEK_HOLE 39 Adjust the file offset to the next hole in the file greater than or equal to offset. If offset points 40 into the middle of a hole, then the file offset is set to offset. If there is no hole past offset, 41 then the file offset is adjusted to the end of the file (i.e., there is an implicit hole at the end of 42 any file). 43 44 In both of the above cases, lseek() fails if offset points past the end of the file. 45 46 These operations allow applications to map holes in a sparsely allocated file. This can be useful for appli‐ 47 cations such as file backup tools, which can save space when creating backups and preserve holes, if they 48 have a mechanism for discovering holes. 49 50 For the purposes of these operations, a hole is a sequence of zeros that (normally) has not been allocated in 51 the underlying file storage. However, a filesystem is not obliged to report holes, so these operations are 52 not a guaranteed mechanism for mapping the storage space actually allocated to a file. (Furthermore, a 53 sequence of zeros that actually has been written to the underlying storage may not be reported as a hole.) 54 In the simplest implementation, a filesystem can support the operations by making SEEK_HOLE always return the 55 offset of the end of the file, and making SEEK_DATA always return offset (i.e., even if the location referred 56 to by offset is a hole, it can be considered to consist of data that is a sequence of zeros). 57 58 The _GNU_SOURCE feature test macro must be defined in order to obtain the definitions of SEEK_DATA and 59 SEEK_HOLE from <unistd.h>. 60 61 RETURN VALUE 62 Upon successful completion, lseek() returns the resulting offset location as measured in bytes from the 63 beginning of the file. On error, the value (off_t) -1 is returned and errno is set to indicate the error. 64 65 ERRORS 66 EBADF fd is not an open file descriptor. 67 68 EINVAL whence is not valid. Or: the resulting file offset would be negative, or beyond the end of a seekable 69 device. 70 71 EOVERFLOW 72 The resulting file offset cannot be represented in an off_t. 73 74 ESPIPE fd is associated with a pipe, socket, or FIFO. 75 76 ENXIO whence is SEEK_DATA or SEEK_HOLE, and the current file offset is beyond the end of the file. 77 78 CONFORMING TO 79 SVr4, 4.3BSD, POSIX.1-2001. 80 81 SEEK_DATA and SEEK_HOLE are nonstandard extensions also present in Solaris, FreeBSD, and DragonFly BSD; they 82 are proposed for inclusion in the next POSIX revision (Issue 8). 83 84 NOTES 85 Some devices are incapable of seeking and POSIX does not specify which devices must support lseek(). 86 87 On Linux, using lseek() on a terminal device returns ESPIPE. 88 89 When converting old code, substitute values for whence with the following macros: 90 91 old new 92 0 SEEK_SET 93 1 SEEK_CUR 94 2 SEEK_END 95 L_SET SEEK_SET 96 L_INCR SEEK_CUR 97 L_XTND SEEK_END 98 99 Note that file descriptors created by dup(2) or fork(2) share the current file position pointer, so seeking 100 on such files may be subject to race conditions. 101 102 SEE ALSO 103 dup(2), fork(2), open(2), fseek(3), lseek64(3), posix_fallocate(3) 104 105 COLOPHON 106 This page is part of release 3.54 of the Linux man-pages project. A description of the project, and informa‐ 107 tion about reporting bugs, can be found at http://www.kernel.org/doc/man-pages/. 108 109 110 111 Linux 2013-03-27 LSEEK(2)
2.2.4 文件锁
int fcntl(int fd, int cmd, ... /* arg */ );
当多个程序共同操作一个文件时,给文件上锁,来解决对共享资源的竞争。
建议性锁:要求每个相关程序在访问文件之前检查是否有锁存在,并且尊重已有锁。(不建议使用,无法保证每个程序都自动检查是否有锁)
强制性锁:由内核执行的锁,当一个文件被上锁进行写入操作的时候,内核将阻止其他任何程序对该文件进行读写操作。
采用强制性锁对性能的影响较大,每次读写内核都检查是否有锁存在。
实现上锁的函数:lockf():对文件施加建议性锁。
fcntl():可以施加建议性锁,也可以施加强制性锁。还能对文件的某一记录上锁,即记录锁。
记录锁:分读取锁(共享锁)和写入锁(排斥锁)。
1 FCNTL(2) Linux Programmer's Manual FCNTL(2) 2 3 4 5 NAME 6 fcntl - manipulate file descriptor 7 8 SYNOPSIS 9 #include <unistd.h> 10 #include <fcntl.h> 11 12 int fcntl(int fd, int cmd, ... /* arg */ ); 13 14 DESCRIPTION 15 fcntl() performs one of the operations described below on the open file descriptor fd. The operation is 16 determined by cmd. 17 18 fcntl() can take an optional third argument. Whether or not this argument is required is determined by cmd. 19 The required argument type is indicated in parentheses after each cmd name (in most cases, the required type 20 is int, and we identify the argument using the name arg), or void is specified if the argument is not 21 required. 22 23 Duplicating a file descriptor 24 F_DUPFD (int) 25 Find the lowest numbered available file descriptor greater than or equal to arg and make it be a copy 26 of fd. This is different from dup2(2), which uses exactly the descriptor specified. 27 28 On success, the new descriptor is returned. 29 30 See dup(2) for further details. 31 32 F_DUPFD_CLOEXEC (int; since Linux 2.6.24) 33 As for F_DUPFD, but additionally set the close-on-exec flag for the duplicate descriptor. Specifying 34 this flag permits a program to avoid an additional fcntl() F_SETFD operation to set the FD_CLOEXEC 35 flag. For an explanation of why this flag is useful, see the description of O_CLOEXEC in open(2). 36 37 File descriptor flags 38 The following commands manipulate the flags associated with a file descriptor. Currently, only one such flag 39 is defined: FD_CLOEXEC, the close-on-exec flag. If the FD_CLOEXEC bit is 0, the file descriptor will remain 40 open across an execve(2), otherwise it will be closed. 41 42 F_GETFD (void) 43 Read the file descriptor flags; arg is ignored. 44 45 F_SETFD (int) 46 Set the file descriptor flags to the value specified by arg. 47 48 File status flags 49 Each open file description has certain associated status flags, initialized by open(2) and possibly modified 50 by fcntl(). Duplicated file descriptors (made with dup(2), fcntl(F_DUPFD), fork(2), etc.) refer to the same 51 open file description, and thus share the same file status flags. 52 53 The file status flags and their semantics are described in open(2). 54 55 F_GETFL (void) 56 Get the file access mode and the file status flags; arg is ignored. 57 58 F_SETFL (int) 59 Set the file status flags to the value specified by arg. File access mode (O_RDONLY, O_WRONLY, 60 O_RDWR) and file creation flags (i.e., O_CREAT, O_EXCL, O_NOCTTY, O_TRUNC) in arg are ignored. On 61 Linux this command can change only the O_APPEND, O_ASYNC, O_DIRECT, O_NOATIME, and O_NONBLOCK flags. 62 63 Advisory locking 64 F_GETLK, F_SETLK and F_SETLKW are used to acquire, release, and test for the existence of record locks (also 65 known as file-segment or file-region locks). The third argument, lock, is a pointer to a structure that has 66 at least the following fields (in unspecified order). 67 68 struct flock { 69 ... 70 short l_type; /* Type of lock: F_RDLCK, 71 F_WRLCK, F_UNLCK */ 72 short l_whence; /* How to interpret l_start: 73 SEEK_SET, SEEK_CUR, SEEK_END */ 74 off_t l_start; /* Starting offset for lock */ 75 off_t l_len; /* Number of bytes to lock */ 76 pid_t l_pid; /* PID of process blocking our lock 77 (F_GETLK only) */ 78 ... 79 }; 80 81 The l_whence, l_start, and l_len fields of this structure specify the range of bytes we wish to lock. Bytes 82 past the end of the file may be locked, but not bytes before the start of the file. 83 84 l_start is the starting offset for the lock, and is interpreted relative to either: the start of the file (if 85 l_whence is SEEK_SET); the current file offset (if l_whence is SEEK_CUR); or the end of the file (if l_whence 86 is SEEK_END). In the final two cases, l_start can be a negative number provided the offset does not lie 87 before the start of the file. 88 89 l_len specifies the number of bytes to be locked. If l_len is positive, then the range to be locked covers 90 bytes l_start up to and including l_start+l_len-1. Specifying 0 for l_len has the special meaning: lock all 91 bytes starting at the location specified by l_whence and l_start through to the end of file, no matter how 92 large the file grows. 93 94 POSIX.1-2001 allows (but does not require) an implementation to support a negative l_len value; if l_len is 95 negative, the interval described by lock covers bytes l_start+l_len up to and including l_start-1. This is 96 supported by Linux since kernel versions 2.4.21 and 2.5.49. 97 98 The l_type field can be used to place a read (F_RDLCK) or a write (F_WRLCK) lock on a file. Any number of 99 processes may hold a read lock (shared lock) on a file region, but only one process may hold a write lock 100 (exclusive lock). An exclusive lock excludes all other locks, both shared and exclusive. A single process 101 can hold only one type of lock on a file region; if a new lock is applied to an already-locked region, then 102 the existing lock is converted to the new lock type. (Such conversions may involve splitting, shrinking, or 103 coalescing with an existing lock if the byte range specified by the new lock does not precisely coincide with 104 the range of the existing lock.) 105 106 F_SETLK (struct flock *) 107 Acquire a lock (when l_type is F_RDLCK or F_WRLCK) or release a lock (when l_type is F_UNLCK) on the 108 bytes specified by the l_whence, l_start, and l_len fields of lock. If a conflicting lock is held by 109 another process, this call returns -1 and sets errno to EACCES or EAGAIN. 110 111 F_SETLKW (struct flock *) 112 As for F_SETLK, but if a conflicting lock is held on the file, then wait for that lock to be released. 113 If a signal is caught while waiting, then the call is interrupted and (after the signal handler has 114 returned) returns immediately (with return value -1 and errno set to EINTR; see signal(7)). 115 116 F_GETLK (struct flock *) 117 On input to this call, lock describes a lock we would like to place on the file. If the lock could be 118 placed, fcntl() does not actually place it, but returns F_UNLCK in the l_type field of lock and leaves 119 the other fields of the structure unchanged. If one or more incompatible locks would prevent this 120 lock being placed, then fcntl() returns details about one of these locks in the l_type, l_whence, 121 l_start, and l_len fields of lock and sets l_pid to be the PID of the process holding that lock. 122 123 In order to place a read lock, fd must be open for reading. In order to place a write lock, fd must be open 124 for writing. To place both types of lock, open a file read-write. 125 126 As well as being removed by an explicit F_UNLCK, record locks are automatically released when the process 127 terminates or if it closes any file descriptor referring to a file on which locks are held. This is bad: it 128 means that a process can lose the locks on a file like /etc/passwd or /etc/mtab when for some reason a 129 library function decides to open, read and close it. 130 131 Record locks are not inherited by a child created via fork(2), but are preserved across an execve(2). 132 133 Because of the buffering performed by the stdio(3) library, the use of record locking with routines in that 134 package should be avoided; use read(2) and write(2) instead. 135 136 Mandatory locking 137 (Non-POSIX.) The above record locks may be either advisory or mandatory, and are advisory by default. 138 139 Advisory locks are not enforced and are useful only between cooperating processes. 140 141 Mandatory locks are enforced for all processes. If a process tries to perform an incompatible access (e.g., 142 read(2) or write(2)) on a file region that has an incompatible mandatory lock, then the result depends upon 143 whether the O_NONBLOCK flag is enabled for its open file description. If the O_NONBLOCK flag is not enabled, 144 then system call is blocked until the lock is removed or converted to a mode that is compatible with the 145 access. If the O_NONBLOCK flag is enabled, then the system call fails with the error EAGAIN. 146 147 To make use of mandatory locks, mandatory locking must be enabled both on the filesystem that contains the 148 file to be locked, and on the file itself. Mandatory locking is enabled on a filesystem using the "-o mand" 149 option to mount(8), or the MS_MANDLOCK flag for mount(2). Mandatory locking is enabled on a file by dis‐ 150 abling group execute permission on the file and enabling the set-group-ID permission bit (see chmod(1) and 151 chmod(2)). 152 153 The Linux implementation of mandatory locking is unreliable. See BUGS below. 154 155 Managing signals 156 F_GETOWN, F_SETOWN, F_GETOWN_EX, F_SETOWN_EX, F_GETSIG and F_SETSIG are used to manage I/O availability sig‐ 157 nals: 158 159 F_GETOWN (void) 160 Return (as the function result) the process ID or process group currently receiving SIGIO and SIGURG 161 signals for events on file descriptor fd. Process IDs are returned as positive values; process group 162 IDs are returned as negative values (but see BUGS below). arg is ignored. 163 164 F_SETOWN (int) 165 Set the process ID or process group ID that will receive SIGIO and SIGURG signals for events on file 166 descriptor fd to the ID given in arg. A process ID is specified as a positive value; a process group 167 ID is specified as a negative value. Most commonly, the calling process specifies itself as the owner 168 (that is, arg is specified as getpid(2)). 169 170 If you set the O_ASYNC status flag on a file descriptor by using the F_SETFL command of fcntl(), a 171 SIGIO signal is sent whenever input or output becomes possible on that file descriptor. F_SETSIG can 172 be used to obtain delivery of a signal other than SIGIO. If this permission check fails, then the 173 signal is silently discarded. 174 175 Sending a signal to the owner process (group) specified by F_SETOWN is subject to the same permissions 176 checks as are described for kill(2), where the sending process is the one that employs F_SETOWN (but 177 see BUGS below). 178 179 If the file descriptor fd refers to a socket, F_SETOWN also selects the recipient of SIGURG signals 180 that are delivered when out-of-band data arrives on that socket. (SIGURG is sent in any situation 181 where select(2) would report the socket as having an "exceptional condition".) 182 183 The following was true in 2.6.x kernels up to and including kernel 2.6.11: 184 185 If a nonzero value is given to F_SETSIG in a multithreaded process running with a threading 186 library that supports thread groups (e.g., NPTL), then a positive value given to F_SETOWN has a 187 different meaning: instead of being a process ID identifying a whole process, it is a thread ID 188 identifying a specific thread within a process. Consequently, it may be necessary to pass 189 F_SETOWN the result of gettid(2) instead of getpid(2) to get sensible results when F_SETSIG is 190 used. (In current Linux threading implementations, a main thread's thread ID is the same as 191 its process ID. This means that a single-threaded program can equally use gettid(2) or get‐ 192 pid(2) in this scenario.) Note, however, that the statements in this paragraph do not apply to 193 the SIGURG signal generated for out-of-band data on a socket: this signal is always sent to 194 either a process or a process group, depending on the value given to F_SETOWN. 195 196 The above behavior was accidentally dropped in Linux 2.6.12, and won't be restored. From Linux 2.6.32 197 onward, use F_SETOWN_EX to target SIGIO and SIGURG signals at a particular thread. 198 199 F_GETOWN_EX (struct f_owner_ex *) (since Linux 2.6.32) 200 Return the current file descriptor owner settings as defined by a previous F_SETOWN_EX operation. The 201 information is returned in the structure pointed to by arg, which has the following form: 202 203 struct f_owner_ex { 204 int type; 205 pid_t pid; 206 }; 207 208 The type field will have one of the values F_OWNER_TID, F_OWNER_PID, or F_OWNER_PGRP. The pid field 209 is a positive integer representing a thread ID, process ID, or process group ID. See F_SETOWN_EX for 210 more details. 211 212 F_SETOWN_EX (struct f_owner_ex *) (since Linux 2.6.32) 213 This operation performs a similar task to F_SETOWN. It allows the caller to direct I/O availability 214 signals to a specific thread, process, or process group. The caller specifies the target of signals 215 via arg, which is a pointer to a f_owner_ex structure. The type field has one of the following val‐ 216 ues, which define how pid is interpreted: 217 218 F_OWNER_TID 219 Send the signal to the thread whose thread ID (the value returned by a call to clone(2) or get‐ 220 tid(2)) is specified in pid. 221 222 F_OWNER_PID 223 Send the signal to the process whose ID is specified in pid. 224 225 F_OWNER_PGRP 226 Send the signal to the process group whose ID is specified in pid. (Note that, unlike with 227 F_SETOWN, a process group ID is specified as a positive value here.) 228 229 F_GETSIG (void) 230 Return (as the function result) the signal sent when input or output becomes possible. A value of 231 zero means SIGIO is sent. Any other value (including SIGIO) is the signal sent instead, and in this 232 case additional info is available to the signal handler if installed with SA_SIGINFO. arg is ignored. 233 234 F_SETSIG (int) 235 Set the signal sent when input or output becomes possible to the value given in arg. A value of zero 236 means to send the default SIGIO signal. Any other value (including SIGIO) is the signal to send 237 instead, and in this case additional info is available to the signal handler if installed with SA_SIG‐ 238 INFO. 239 240 By using F_SETSIG with a nonzero value, and setting SA_SIGINFO for the signal handler (see sigac‐ 241 tion(2)), extra information about I/O events is passed to the handler in a siginfo_t structure. If 242 the si_code field indicates the source is SI_SIGIO, the si_fd field gives the file descriptor associ‐ 243 ated with the event. Otherwise, there is no indication which file descriptors are pending, and you 244 should use the usual mechanisms (select(2), poll(2), read(2) with O_NONBLOCK set etc.) to determine 245 which file descriptors are available for I/O. 246 247 By selecting a real time signal (value >= SIGRTMIN), multiple I/O events may be queued using the same 248 signal numbers. (Queuing is dependent on available memory). Extra information is available if 249 SA_SIGINFO is set for the signal handler, as above. 250 251 Note that Linux imposes a limit on the number of real-time signals that may be queued to a process 252 (see getrlimit(2) and signal(7)) and if this limit is reached, then the kernel reverts to delivering 253 SIGIO, and this signal is delivered to the entire process rather than to a specific thread. 254 255 Using these mechanisms, a program can implement fully asynchronous I/O without using select(2) or poll(2) 256 most of the time. 257 258 The use of O_ASYNC, F_GETOWN, F_SETOWN is specific to BSD and Linux. F_GETOWN_EX, F_SETOWN_EX, F_GETSIG, and 259 F_SETSIG are Linux-specific. POSIX has asynchronous I/O and the aio_sigevent structure to achieve similar 260 things; these are also available in Linux as part of the GNU C Library (Glibc). 261 262 Leases 263 F_SETLEASE and F_GETLEASE (Linux 2.4 onward) are used (respectively) to establish a new lease, and retrieve 264 the current lease, on the open file description referred to by the file descriptor fd. A file lease provides 265 a mechanism whereby the process holding the lease (the "lease holder") is notified (via delivery of a signal) 266 when a process (the "lease breaker") tries to open(2) or truncate(2) the file referred to by that file 267 descriptor. 268 269 F_SETLEASE (int) 270 Set or remove a file lease according to which of the following values is specified in the integer arg: 271 272 F_RDLCK 273 Take out a read lease. This will cause the calling process to be notified when the file is 274 opened for writing or is truncated. A read lease can be placed only on a file descriptor that 275 is opened read-only. 276 277 F_WRLCK 278 Take out a write lease. This will cause the caller to be notified when the file is opened for 279 reading or writing or is truncated. A write lease may be placed on a file only if there are no 280 other open file descriptors for the file. 281 282 F_UNLCK 283 Remove our lease from the file. 284 285 Leases are associated with an open file description (see open(2)). This means that duplicate file descrip‐ 286 tors (created by, for example, fork(2) or dup(2)) refer to the same lease, and this lease may be modified or 287 released using any of these descriptors. Furthermore, the lease is released by either an explicit F_UNLCK 288 operation on any of these duplicate descriptors, or when all such descriptors have been closed. 289 290 Leases may be taken out only on regular files. An unprivileged process may take out a lease only on a file 291 whose UID (owner) matches the filesystem UID of the process. A process with the CAP_LEASE capability may 292 take out leases on arbitrary files. 293 294 F_GETLEASE (void) 295 Indicates what type of lease is associated with the file descriptor fd by returning either F_RDLCK, 296 F_WRLCK, or F_UNLCK, indicating, respectively, a read lease , a write lease, or no lease. arg is 297 ignored. 298 299 When a process (the "lease breaker") performs an open(2) or truncate(2) that conflicts with a lease estab‐ 300 lished via F_SETLEASE, the system call is blocked by the kernel and the kernel notifies the lease holder by 301 sending it a signal (SIGIO by default). The lease holder should respond to receipt of this signal by doing 302 whatever cleanup is required in preparation for the file to be accessed by another process (e.g., flushing 303 cached buffers) and then either remove or downgrade its lease. A lease is removed by performing an 304 F_SETLEASE command specifying arg as F_UNLCK. If the lease holder currently holds a write lease on the file, 305 and the lease breaker is opening the file for reading, then it is sufficient for the lease holder to down‐ 306 grade the lease to a read lease. This is done by performing an F_SETLEASE command specifying arg as F_RDLCK. 307 308 If the lease holder fails to downgrade or remove the lease within the number of seconds specified in 309 /proc/sys/fs/lease-break-time then the kernel forcibly removes or downgrades the lease holder's lease. 310 311 Once a lease break has been initiated, F_GETLEASE returns the target lease type (either F_RDLCK or F_UNLCK, 312 depending on what would be compatible with the lease breaker) until the lease holder voluntarily downgrades 313 or removes the lease or the kernel forcibly does so after the lease break timer expires. 314 315 Once the lease has been voluntarily or forcibly removed or downgraded, and assuming the lease breaker has not 316 unblocked its system call, the kernel permits the lease breaker's system call to proceed. 317 318 If the lease breaker's blocked open(2) or truncate(2) is interrupted by a signal handler, then the system 319 call fails with the error EINTR, but the other steps still occur as described above. If the lease breaker is 320 killed by a signal while blocked in open(2) or truncate(2), then the other steps still occur as described 321 above. If the lease breaker specifies the O_NONBLOCK flag when calling open(2), then the call immediately 322 fails with the error EWOULDBLOCK, but the other steps still occur as described above. 323 324 The default signal used to notify the lease holder is SIGIO, but this can be changed using the F_SETSIG com‐ 325 mand to fcntl(). If a F_SETSIG command is performed (even one specifying SIGIO), and the signal handler is 326 established using SA_SIGINFO, then the handler will receive a siginfo_t structure as its second argument, and 327 the si_fd field of this argument will hold the descriptor of the leased file that has been accessed by 328 another process. (This is useful if the caller holds leases against multiple files). 329 330 File and directory change notification (dnotify) 331 F_NOTIFY (int) 332 (Linux 2.4 onward) Provide notification when the directory referred to by fd or any of the files that 333 it contains is changed. The events to be notified are specified in arg, which is a bit mask specified 334 by ORing together zero or more of the following bits: 335 336 DN_ACCESS A file was accessed (read, pread, readv) 337 DN_MODIFY A file was modified (write, pwrite, writev, truncate, ftruncate). 338 DN_CREATE A file was created (open, creat, mknod, mkdir, link, symlink, rename). 339 DN_DELETE A file was unlinked (unlink, rename to another directory, rmdir). 340 DN_RENAME A file was renamed within this directory (rename). 341 DN_ATTRIB The attributes of a file were changed (chown, chmod, utime[s]). 342 343 (In order to obtain these definitions, the _GNU_SOURCE feature test macro must be defined before 344 including any header files.) 345 346 Directory notifications are normally "one-shot", and the application must reregister to receive fur‐ 347 ther notifications. Alternatively, if DN_MULTISHOT is included in arg, then notification will remain 348 in effect until explicitly removed. 349 350 A series of F_NOTIFY requests is cumulative, with the events in arg being added to the set already 351 monitored. To disable notification of all events, make an F_NOTIFY call specifying arg as 0. 352 353 Notification occurs via delivery of a signal. The default signal is SIGIO, but this can be changed 354 using the F_SETSIG command to fcntl(). In the latter case, the signal handler receives a siginfo_t 355 structure as its second argument (if the handler was established using SA_SIGINFO) and the si_fd field 356 of this structure contains the file descriptor which generated the notification (useful when estab‐ 357 lishing notification on multiple directories). 358 359 Especially when using DN_MULTISHOT, a real time signal should be used for notification, so that multi‐ 360 ple notifications can be queued. 361 362 NOTE: New applications should use the inotify interface (available since kernel 2.6.13), which pro‐ 363 vides a much superior interface for obtaining notifications of filesystem events. See inotify(7). 364 365 Changing the capacity of a pipe 366 F_SETPIPE_SZ (int; since Linux 2.6.35) 367 Change the capacity of the pipe referred to by fd to be at least arg bytes. An unprivileged process 368 can adjust the pipe capacity to any value between the system page size and the limit defined in 369 /proc/sys/fs/pipe-max-size (see proc(5)). Attempts to set the pipe capacity below the page size are 370 silently rounded up to the page size. Attempts by an unprivileged process to set the pipe capacity 371 above the limit in /proc/sys/fs/pipe-max-size yield the error EPERM; a privileged process 372 (CAP_SYS_RESOURCE) can override the limit. When allocating the buffer for the pipe, the kernel may 373 use a capacity larger than arg, if that is convenient for the implementation. The F_GETPIPE_SZ opera‐ 374 tion returns the actual size used. Attempting to set the pipe capacity smaller than the amount of 375 buffer space currently used to store data produces the error EBUSY. 376 377 F_GETPIPE_SZ (void; since Linux 2.6.35) 378 Return (as the function result) the capacity of the pipe referred to by fd. 379 380 RETURN VALUE 381 For a successful call, the return value depends on the operation: 382 383 F_DUPFD The new descriptor. 384 385 F_GETFD Value of file descriptor flags. 386 387 F_GETFL Value of file status flags. 388 389 F_GETLEASE 390 Type of lease held on file descriptor. 391 392 F_GETOWN Value of descriptor owner. 393 394 F_GETSIG Value of signal sent when read or write becomes possible, or zero for traditional SIGIO behavior. 395 396 F_GETPIPE_SZ 397 The pipe capacity. 398 399 All other commands 400 Zero. 401 402 On error, -1 is returned, and errno is set appropriately. 403 404 ERRORS 405 EACCES or EAGAIN 406 Operation is prohibited by locks held by other processes. 407 408 EAGAIN The operation is prohibited because the file has been memory-mapped by another process. 409 410 EBADF fd is not an open file descriptor, or the command was F_SETLK or F_SETLKW and the file descriptor open 411 mode doesn't match with the type of lock requested. 412 413 EDEADLK 414 It was detected that the specified F_SETLKW command would cause a deadlock. 415 416 EFAULT lock is outside your accessible address space. 417 418 EINTR For F_SETLKW, the command was interrupted by a signal; see signal(7). For F_GETLK and F_SETLK, the 419 command was interrupted by a signal before the lock was checked or acquired. Most likely when locking 420 a remote file (e.g., locking over NFS), but can sometimes happen locally. 421 422 EINVAL For F_DUPFD, arg is negative or is greater than the maximum allowable value. For F_SETSIG, arg is not 423 an allowable signal number. 424 425 EMFILE For F_DUPFD, the process already has the maximum number of file descriptors open. 426 427 ENOLCK Too many segment locks open, lock table is full, or a remote locking protocol failed (e.g., locking 428 over NFS). 429 430 EPERM Attempted to clear the O_APPEND flag on a file that has the append-only attribute set. 431 432 CONFORMING TO 433 SVr4, 4.3BSD, POSIX.1-2001. Only the operations F_DUPFD, F_GETFD, F_SETFD, F_GETFL, F_SETFL, F_GETLK, 434 F_SETLK and F_SETLKW, are specified in POSIX.1-2001. 435 436 F_GETOWN and F_SETOWN are specified in POSIX.1-2001. (To get their definitions, define BSD_SOURCE, or 437 _XOPEN_SOURCE with the value 500 or greater, or define _POSIX_C_SOURCE with the value 200809L or greater.) 438 439 F_DUPFD_CLOEXEC is specified in POSIX.1-2008. (To get this definition, define _POSIX_C_SOURCE with the value 440 200809L or greater, or _XOPEN_SOURCE with the value 700 or greater.) 441 442 F_GETOWN_EX, F_SETOWN_EX, F_SETPIPE_SZ, F_GETPIPE_SZ, F_GETSIG, F_SETSIG, F_NOTIFY, F_GETLEASE, and 443 F_SETLEASE are Linux-specific. (Define the _GNU_SOURCE macro to obtain these definitions.) 444 445 NOTES 446 The original Linux fcntl() system call was not designed to handle large file offsets (in the flock struc‐ 447 ture). Consequently, an fcntl64() system call was added in Linux 2.4. The newer system call employs a dif‐ 448 ferent structure for file locking, flock64, and corresponding commands, F_GETLK64, F_SETLK64, and F_SETLKW64. 449 However, these details can be ignored by applications using glibc, whose fcntl() wrapper function transpar‐ 450 ently employs the more recent system call where it is available. 451 452 The errors returned by dup2(2) are different from those returned by F_DUPFD. 453 454 Since kernel 2.0, there is no interaction between the types of lock placed by flock(2) and fcntl(). 455 456 Several systems have more fields in struct flock such as, for example, l_sysid. Clearly, l_pid alone is not 457 going to be very useful if the process holding the lock may live on a different machine. 458 459 BUGS 460 A limitation of the Linux system call conventions on some architectures (notably i386) means that if a (nega‐ 461 tive) process group ID to be returned by F_GETOWN falls in the range -1 to -4095, then the return value is 462 wrongly interpreted by glibc as an error in the system call; that is, the return value of fcntl() will be -1, 463 and errno will contain the (positive) process group ID. The Linux-specific F_GETOWN_EX operation avoids this 464 problem. Since glibc version 2.11, glibc makes the kernel F_GETOWN problem invisible by implementing 465 F_GETOWN using F_GETOWN_EX. 466 467 In Linux 2.4 and earlier, there is bug that can occur when an unprivileged process uses F_SETOWN to specify 468 the owner of a socket file descriptor as a process (group) other than the caller. In this case, fcntl() can 469 return -1 with errno set to EPERM, even when the owner process (group) is one that the caller has permission 470 to send signals to. Despite this error return, the file descriptor owner is set, and signals will be sent to 471 the owner. 472 473 The implementation of mandatory locking in all known versions of Linux is subject to race conditions which 474 render it unreliable: a write(2) call that overlaps with a lock may modify data after the mandatory lock is 475 acquired; a read(2) call that overlaps with a lock may detect changes to data that were made only after a 476 write lock was acquired. Similar races exist between mandatory locks and mmap(2). It is therefore inadvis‐ 477 able to rely on mandatory locking. 478 479 SEE ALSO 480 dup2(2), flock(2), open(2), socket(2), lockf(3), capabilities(7), feature_test_macros(7) 481 482 locks.txt, mandatory-locking.txt, and dnotify.txt in the Linux kernel source directory Documentation/filesys‐ 483 tems/ (on older kernels, these files are directly under the Documentation/ directory, and mandatory-lock‐ 484 ing.txt is called mandatory.txt) 485 486 COLOPHON 487 This page is part of release 3.54 of the Linux man-pages project. A description of the project, and informa‐ 488 tion about reporting bugs, can be found at http://www.kernel.org/doc/man-pages/. 489 490 491 492 Linux 2012-04-15 FCNTL(2)
1 /******************************************************************* 2 * > File Name: lock_set.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Mon 27 Nov 2017 10:35:41 PM CST 6 ******************************************************************/ 7 8 #include "lock_set.h" 9 10 int lock_set(int fd, int type){ 11 struct flock old_lock, lock; 12 13 lock.l_whence = SEEK_SET; 14 lock.l_start = 0; 15 lock.l_len = 0; 16 lock.l_type = type; 17 lock.l_pid = -1; 18 19 /*判断文件是否上锁*/ 20 fcntl(fd, F_GETLK, &lock); 21 22 if(lock.l_type != F_UNLCK){ 23 /*判断文件不能上锁的原因*/ 24 if(lock.l_type == F_RDLCK){ 25 /*该文件已有读取锁*/ 26 printf("Read lock already set by %d\n", lock.l_pid); 27 }else if(lock.l_type == F_WRLCK){ 28 /*该文件已有写入锁*/ 29 printf("Write lock already set by %d\n", lock.l_pid); 30 } 31 } 32 33 /*l_type可能已被F_GETLK修改过*/ 34 lock.l_type = type; 35 /*根据不同的type值进行阻塞上锁或解锁*/ 36 if((fcntl(fd, F_SETLKW, &lock)) < 0){ 37 printf("Lock failed :type = %d\n", lock.l_type); 38 return (-1); 39 } 40 41 switch(lock.l_type){ 42 case F_RDLCK: 43 { 44 printf("Read lock set by %d\n", getpid()); 45 } 46 break; 47 case F_WRLCK: 48 { 49 printf("Write lock set by %d\n", getpid()); 50 } 51 break; 52 case F_UNLCK: 53 { 54 printf("Release lock by %d\n", getpid()); 55 return 1; 56 } 57 break; 58 }/*end of switch*/ 59 60 return 0; 61 } 62 63 #if (0) 64 int main(void) 65 { 66 return 0; 67 } 68 #endif
1 #ifndef __LOCK_SET_H__ 2 #define __LOCK_SET_H__ 3 4 #include <stdio.h> 5 #include <unistd.h> 6 #include <fcntl.h> 7 #include "lock_set.h" 8 9 int lock_set(int fd, int type); 10 11 #endif
1 /******************************************************************* 2 * > File Name: fcntl_read.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Tue 28 Nov 2017 12:25:57 AM CST 6 ******************************************************************/ 7 8 #include <stdio.h> 9 #include <unistd.h> 10 #include <sys/file.h> 11 #include <sys/types.h> 12 #include <sys/stat.h> 13 #include <stdlib.h> 14 #include "lock_set.h" 15 16 int main(int argc, char* argv[]) 17 { 18 int fd; 19 20 fd = open("Hello", O_RDWR|O_CREAT, 0644); 21 if(fd < 0){ 22 printf("Open file error\n"); 23 exit(1); 24 } 25 26 /*给文件上读取锁*/ 27 lock_set(fd, F_RDLCK); 28 getchar(); 29 30 /*给文件解锁*/ 31 lock_set(fd, FUNLCK); 32 getchar(); 33 close(fd); 34 35 return 0; 36 }
1 /******************************************************************* 2 * > File Name: write_lock.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Mon 27 Nov 2017 11:45:20 PM CST 6 ******************************************************************/ 7 8 #include <stdio.h> 9 #include <sys/file.h> 10 #include <sys/stat.h> 11 #include <stdio.h> 12 #include <stdlib.h> 13 #include "lock_set.h" 14 15 int lock_set(int fd, int type); 16 17 int main(int argc, char* argv[]) 18 { 19 int fd; 20 21 /*首先打开文件*/ 22 if((fd = open("hello", O_RDWR|O_CREAT)) < 0){ 23 perror("fail to open"); 24 return -1; 25 } 26 27 /*给文件上锁*/ 28 lock_set(fd, F_WRLCK); 29 getchar(); //等待用户键盘输入 30 31 /*给文件解锁*/ 32 lock_set(fd, F_UNLCK); 33 getchar(); 34 close(fd); 35 36 return 0; 37 }
2.3实验内容——生产者和消费者
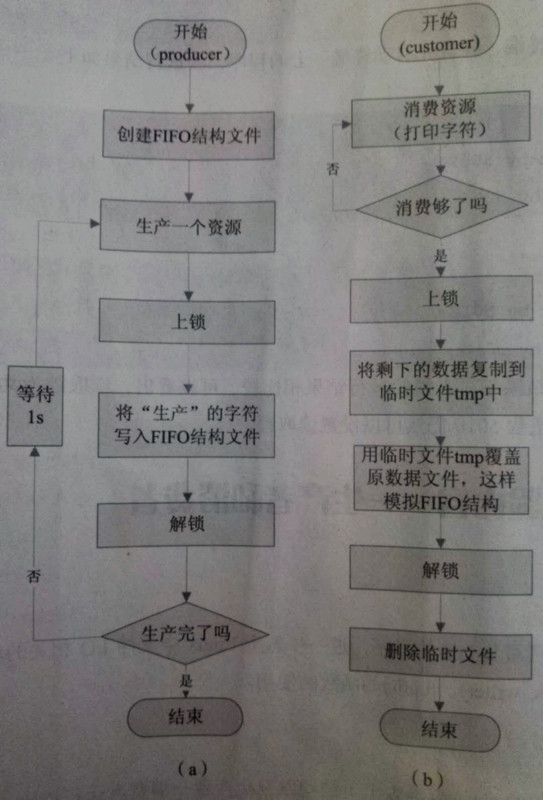
1 /******************************************************************* 2 * > File Name: producer.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Tue 28 Nov 2017 11:20:29 PM CST 6 ******************************************************************/ 7 8 #include <stdio.h> 9 #include <unistd.h> 10 #include <stdlib.h> 11 #include <string.h> 12 #include <fcntl.h> 13 #include "lock_set.h" 14 15 #define MAXLEN 10 /*缓冲区大小最大值*/ 16 #define ALPHABET 1 /*表示使用英文字符*/ 17 #define ALPHABET_START 'a' /*头一个字符,可以用'A'*/ 18 #define COUNT_OF_ALPHABET 26 /*字母字符的个数*/ 19 #define DIGIT 2 /*表示使用数字字符*/ 20 #define DIGIT_START '0' /*头一个字符*/ 21 #define COUNT_OF_DIGIT 10 /*数字字符的个数*/ 22 #define SIGN_TYPE ALPHABET /*本实例选用英文字符*/ 23 const char *fifo_file = "./myfifo"; /*仿真FIFO文件名*/ 24 char buff[MAXLEN]; /*缓冲区*/ 25 26 /*功能:生产一个字符并写入仿真FIFO文件中*/ 27 int product(void){ 28 int fd; 29 unsigned int sign_type, sign_start, sign_count, size; 30 static unsigned int counter = 0; 31 32 /*打开仿真FIFO文件*/ 33 if((fd = open(fifo_file, O_CREAT|O_RDWR|O_APPEND, 0644)) < 0){ 34 perror("Open fifo_file error :");exit(EXIT_FAILURE); 35 } 36 37 sign_type = SIGN_TYPE; 38 switch(sign_type){ 39 case ALPHABET:/*英文字符*/ 40 { 41 sign_start = ALPHABET_START; 42 sign_count = COUNT_OF_ALPHABET; 43 } 44 break; 45 case DIGIT:/*数字字符*/ 46 { 47 sign_start = DIGIT_START; 48 sign_count = COUNT_OF_DIGIT; 49 } 50 break; 51 default: 52 { 53 return -1; 54 } 55 }/*end of switch*/ 56 57 sprintf(buff, "%c", (sign_start + counter)); 58 counter = (counter + 1)%sign_count; 59 60 lock_set(fd, F_WRLCK); /*上写锁*/ 61 if((size = write(fd, buff, strlen(buff))) < 0){ 62 printf("Producer write error\n"); 63 return -1; 64 } 65 66 lock_set(fd, F_UNLCK); /*解锁*/ 67 68 close(fd); 69 return 0; 70 } 71 72 int main(int argc, char* argv[]) 73 { 74 int time_step = 1; /*生产周期*/ 75 int time_life = 10; /*需要生产的资源总数*/ 76 77 if(argc > 1){ 78 /*第一个参数表示生产周期*/ 79 sscanf(argv[1], "%d", &time_step); 80 } 81 82 if(argc > 2){ 83 /*第二个参数表示需要生产的资源数*/ 84 sscanf(argv[2], "%d", &time_life); 85 } 86 87 while(time_life --){ 88 if(product() <0){ 89 break; 90 } 91 sleep(time_step); 92 } 93 94 exit(EXIT_SUCCESS); 95 }
1 /******************************************************************* 2 * > File Name: customer.c 3 * > Author: fly 4 * > Mail: XXXXXXXX@icode.com 5 * > Create Time: Wed 29 Nov 2017 08:32:23 PM CST 6 ******************************************************************/ 7 8 #include <stdio.h> 9 #include <unistd.h> 10 #include <stdlib.h> 11 #include <fcntl.h> 12 #include "lock_set.h" 13 14 #define MAX_FILE_SIZE 100*1024*1024 /*100MB*/ 15 16 const char *fifo_file = "./myfifo"; /*仿真FIFO文件名*/ 17 const char *tmp_file = "./tmp"; /*临时文件名*/ 18 19 /*资源消费函数*/ 20 int customing(const char *myfifo, int need){ 21 int fd; 22 char buff; 23 int counter = 0; 24 25 /*以可读方式打开文件*/ 26 if((fd = open(myfifo, O_RDONLY)) < 0){ 27 printf("Function customing error\n"); 28 return -1; 29 } 30 31 printf("Enjoy :"); 32 /*找到文件的开头*/ 33 lseek(fd, SEEK_SET, 0); 34 35 while(counter < need){ 36 while((read(fd, &buff, 1) == 1) && (counter < need)){ 37 fputc(buff, stdout); /*消费者就是在屏幕上简单的显示*/ 38 counter ++; 39 } 40 } 41 42 fputs("\n", stdout); 43 close(fd); 44 return 0; 45 } 46 47 /*功能:从sour_file文件的offset偏移处开始将count个字节数据复制到dest_file文件*/ 48 int myfilecopy(const char *sour_file, const char *dest_file, int offset, int count, int copy_mode){ 49 int in_file, out_file; 50 int counter = 0; 51 char buf_unit; 52 53 if((in_file = open(sour_file, O_RDONLY|O_NONBLOCK)) < 0){ 54 printf("Function myfilecopy error in source file\n");return (-1); 55 } 56 57 if((out_file = open(dest_file, O_CREAT|O_RDWR|O_TRUNC|O_NONBLOCK, 0644)) < 0){ 58 printf("Function myfilecopy error in destination file :");return (-1); 59 } 60 61 lseek(in_file, offset, SEEK_SET); 62 while((read(in_file, &buf_unit, 1)) && (counter < count)){ 63 write(out_file, &buf_unit, 1); 64 counter ++; 65 } 66 67 close(in_file);close(out_file); 68 return 0; 69 } 70 71 /*功能:实现FIFO消费者*/ 72 int custom(int need){ 73 int fd; 74 75 /*对资源进行消费,need表示该消费的资源数目*/ 76 customing(fifo_file, need); 77 78 if((fd = open(fifo_file, O_RDWR)) < 0){ 79 perror("Function myfilecopy error in source_file :");return (-1); 80 } 81 82 /*为了模拟FIFO结构,对整个文件内容进行平行移动*/ 83 lock_set(fd, F_WRLCK); 84 myfilecopy(fifo_file, tmp_file, need, MAX_FILE_SIZE, 0); 85 myfilecopy(tmp_file, fifo_file, 0, MAX_FILE_SIZE, 0); 86 lock_set(fd, F_UNLCK); 87 unlink(tmp_file); 88 close(fd); 89 return 0; 90 } 91 92 int main(int argc, char* argv[]) 93 { 94 int customer_capacity = 10; 95 96 if(argc > 1){ 97 /*第一个参数指定需要消费的资源数目,默认值为10*/ 98 sscanf(argv[1], "%d", &customer_capacity); 99 } 100 101 if(customer_capacity > 0){ 102 custom(customer_capacity); 103 } 104 105 exit(EXIT_SUCCESS); 106 }

