Django数据库--事务及事务回滚
数据库的读写操作中,事务在保证数据的安全性和一致性方面起着关键的作用,而回滚正是这里面的核心操作。Django的ORM在事务方面也提供了不少的API。有事务出错的整体回滚操作,也有基于保存点的部分回滚。本文将讨论Django中的这两种机制的运行原理。
Django利用django.db.transaction模块中的API对数据库进行事务的管理
Django provides a straightforward API in the django.db.transaction module to manage the autocommit state of each database connection.
主要函数:
1. get_autocommit(using=None)
判断事务是否自动提交
2. set_autocommit(autocommit, using=None)
设置自动提交事务
这些函数使接受一个 using 参数表示所要操作的数据库。如果未提供,则 Django 使用 "default" 数据库。
3. on_commit(do something)
事务提交后马上执行任务,例如celery任务
例如:
with transation.atomic:
#do something and commit the transaction
transaction.on_commit(lambda: some_celery_task.delay('arg1'))
怎么使用?在哪里使用?
事务是一系列的数据库操作,在数据的安全性和减少网络请求方面都有很大的优势。关于数据库事务的文章有很多,我这里就不展开讨论了。
那么ORM中有哪些相关的API呢?
trasation模块中最重要的是一个Atomic类,Atomic是一个上下文管理器。可以使用@transaction.atomic 或者with transaction.atomic 的方式来调用。
为了设置保存点,即断点进行事务的执行和回滚,可以嵌套使用with transaction.atomic,例如官网的例子(伪代码):
with transaction.atomic(): # Outer atomic, start a new transaction transaction.on_commit(foo) #事务提交后马上执行foo函数 try: with transaction.atomic(): # Inner atomic block, create a savepoint transaction.on_commit(bar) #事务提交后马上执行foo函数 raise SomeError() # Raising an exception - abort the savepoint except SomeError: pass
第一个with transaction.atomic()创建事务,第二个with transaction.atomic()创建保存点。
虽然错误raiseSomeError是从‘内部’的保存点发出来的,但只会影响到‘外部’的保存点,即只会回滚前面的数据库操作。
下面还会讨论另一种创建保存点的方法。
在使用transaction.atomic前需要注意的问题:
1. 数据库的自动提交默认为开启,如果要将它关闭,必须很小心。一旦使用了transaction,即关闭了自动提交。
2. 如果数据库之前的使用的是自动提交,那么在切换为非自动提交之前,必须确保当前没有活动的事务,通常可以手动执行commit() 或者 rollback() 函数来把未提交的事务提交或者回滚。
一、整体回滚
所有的数据库更新操作都会在一个事务中执行,如果事务中任何一个环节出现错误,都会回滚整个事务。
案例(伪代码1):
from django.db import transaction # open a transaction @transaction.atomic #装饰器格式 def func_views(request): do_something() a = A() #实例化数据库模型 try: a.save() except DatabaseError: pass
此方案整个view都会在事务之中,所有对数据库的操作都是原子性的。
案例(伪代码2):
from django.db import transaction def func_views(request): try: with transaction.atomic(): #上下文格式,可以在python代码的任何位置使用 a = A() a.save() #raise DatabaseError #测试用,检测是否能捕捉错误 except DatabaseError: # 自动回滚,不需要任何操作 pass
此方案比较灵活,事务可以在代码中的任意地方开启,对于事务开启前的数据库操作是必定会执行的,事务开启后的数据库操作一旦出现错误就会回滚。
需要注意的是:
1. python代码中对Models的修改和对数据库的修改的区别,数据库层面的修改不会影响Models实例变量。
如果在代码中修改一个变量,例如:
try: with transaction.atomic(): a = A() a.attribute = True #A表的某一个属性(即数据库的某一列) a.save() raise DatabaseError except DatabaseError: pass print(a.attribute)
#输出结果:True
即使数据库回滚了,但是a实例的变量a.attribute还是会保存在Models实例中,如果需要修改,就需要在except DatabaseError后面进行。
2. transaction不需要在代码中手动commit和rollback的。因为只有当一个transaction正常退出的时候,才会对数据库层面进行操作。除非我们手动调用transaction.commit和transaction.rollback
实际案例(此实例用伪代码2的格式):
models.py
数据表
class Author(models.Model): name = models.CharField(max_length=30,null=False) age = models.IntegerField() email = models.URLField(null=True) class Count(models.Model): name = models.CharField(max_length=30) article_amount = models.IntegerField()
views.py
from django.shortcuts import render from django.http import HttpResponse from index.models import Author,Count from django.db import transaction,IntegrityError def add_author_views(request): author_name = u'renyingying' author = Author(name=author_name, age=24, email='renyingying@qqq.com') # author.save() count = Count(name=author_name, article_amount=1) count.save() try: with transaction.atomic(): author.save() raise DatabaseError #报出错误,检测事务是否能捕捉错误 except DatabaseError: # 自动回滚,不需要任何操作 pass
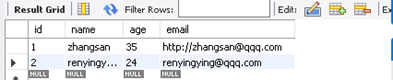
事务外的数据库操作正常执行,而事务内的数据库操作则会回滚。
author表

count表

将raise DatabaseError这一行代码注释掉,author才会有数据
二、保存点Savepoint(断点回滚)
保存点是事务中的标记,从原理实现上来说是一个类似存储结构的类。可以回滚部分事务,而不是完整事务,同时会保存部分事务。python后端程序可以使用保存点。
一旦打开事务atomic(),就会构建一系列等待提交或回滚的数据库操作。通常,如果发出回滚命令,则会回滚整个事务。保存点则提供了执行细粒度回滚的功能,而不是将执行的完全回滚transaction.rollback()。
工作原理:savepoint通过对返回sid后面的将要执行的数据库操作进行计数,并保存在内置的列表中,当对数据库数据库进行操作时遇到错误而中断,根据sid寻找之前的保存点并回滚数据,并将这个操作从列表中删除。
相关API:
1. savepoint(using = None)
创建一个新的保存点。这表示处于正常状态的事务的一个点。返回保存点ID(sid)。在一个事务中可以创建多个保存点。
2. savepoint_commit(sid,using = None)
发布保存点sid,从创建保存点开始执行的数据库操作将成为可能回滚事务的一部分
3. savepoint_rollback(sid,using = None)
将事务回滚到保存点sid
4. clean_savepoints(using = None)
重置用于生成唯一保存点ID的计数器
值得注意的是:
这些函数中的每一个都接受一个using参数,该参数是数据库的名称。如果using未提供参数,则使用"default"默认数据库。
案例:
models.py上文的案例一样
views.py
from django.db import transaction # open a transaction @transaction.atomic def add_author_views(request): # 自动提交方式 # Author.objects.create(name=u'wangbaoqiang',age=33,email='wangbaoqiang@qqq.com') author_name = u'linghuchong' author = Author(name=author_name,age=26,email='linghuchong@qqq.com') author.save() # transaction now contains author.save() sid = transaction.savepoint() try: count = Count(name=author_name, article_amount=1) count.save() # transaction now contains author.save() and count.save() transaction.savepoint_commit(sid) # open transaction still contains author.save() and count.save() except IntegrityError: transaction.savepoint_rollback(sid) # open transaction now contains only count.save() # 保存author操作回滚后,事务只剩下一个操作 transaction.clean_savepoints() #清除保存点
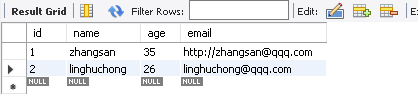
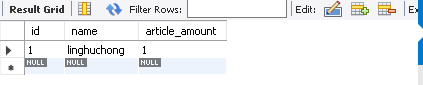
注意:希望当遇到错误得到回滚的事务一定要放在try里面(如果放在try外面,虽然不会报错,但是是不会执行的)。如上面的例子,如果在给Count表执行插入数据发生错误,就会‘断点’回滚到Count表插入数据前,Author表插入的数据不变。
结果显示:
Author表
Count表
参考文章:
https://blog.csdn.net/m0_37422289/article/details/82221489

