2,Python常用库之二:Pandas
Pandas是用于数据操纵和分析,建立在Numpy之上的。Pandas为Python带来了两种新的数据结构:Pandas Series和Pandas DataFrame,借助这两种数据结构,我们能够轻松直观地处理带标签数据和关系数据。
Pandas功能:
- 允许为行和列设定标签
- 可以针对时间序列数据计算滚动统计学指标
- 轻松处理NaN值
- 能够将不同的数据集合并在一起
- 与Numpy和Matplotlib集成
Pandas Series
Pandas series 是像数组一样的一维对象,可以存储很多类型的数据。Pandas series 和 Numpy array之间的主要区别之一是你可以为Pandas series 中的每个元素分配索引标签;另一个区别是Pandas series 可以同时存储不同类型的数据。
创建 Pandas Series
pd.Series(data, index)
1 groceries = pd.Series(data=[30, 6, 'yes', 'No'], index=['eggs', 'apples', 'milk', 'bread']) 2 ser = pd.Series(data=[[0, 1, 2, 3], [1, 3, 5, 7], [2, 4, 6, 8]], index=(['a', 'b', 'c']))
查看 Pandas Series 属性
print(groceries.size) # 数量
print(groceries.shape) # 形状
print(groceries.ndim) # 维度
print(groceries.index) # 索引列表
print(groceries.values) # 元素列表
查看是否存在某个索引标签:in
1 print('book' in groceries)
访问 Pandas Series 中元素切片和索引
Pandas Series 提供了两个属性 .loc 和 .iloc
.loc 表明我们使用的是标签索引访问
.iloc 表明我们使用的是数字索引访问
# 标签索引 print(groceries['eggs']) print(groceries[['eggs', 'milk']]) # 数字索引 print(groceries[1]) print(groceries[[1, 2]]) print(groceries[-1]) # 明确标签索引 print(groceries.loc['milk']) print(groceries.loc[['eggs', 'apples']]) # 明确数字索引 print(groceries.iloc[0]) print(groceries.iloc[[0, 1]])
可以使用groceries.head(),tail()分别查看前n个和后n个值
groceries.unique进行去重操作
修改和删除 Pandas Series 中元素
直接标签访问,值修改就可
1 groceries['eggs'] = 2 2 print(groceries)
删除:drop(参数 1:lable,标签;参数 2:inplace=True/False,是/否修改原 Series)
1 print(ser.drop(['b'])) 2 print(ser.drop(['a', 'b'], inplace=True))
Pandas Series 中元素执行算术运算
Pandas Series执行元素级算术运算:加、减、乘、除
fruits = pd.Series(data=[10, 6, 3], index=['apples', 'oranges', 'bananas']) # 所有数字进行运算 print(fruits + 2) print(fruits - 2) print(fruits * 2) print(fruits / 2) # 所有元素应用Numpy中的数学函数 print(np.exp(fruits)) print(np.sqrt(fruits)) print(np.power(fruits, 2)) # 部分元素进行运算 print(fruits[0] - 2) print(fruits['apples'] + 2) print(fruits.loc['oranges'] * 2) print(np.power(fruits.iloc[0], 2))
Pandas DataFrame
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
创建 Pandas DataFrame
第一步:创建 Pandas Series 字典
第二步:将字典传递给 pd.DataFrame
1 items = {'Bob': pd.Series(data=[245, 25, 55], index=['bike', 'pants', 'watch']),
2 'Alice': pd.Series(data=[40, 110, 500, 45], index=['book', 'glasses', 'bike', 'pants'])}
3 shopping_carts = pd.DataFrame(items)
4 print(shopping_carts)
通过关键字 columns 和 index 选择要将哪些数据放入 DataFrame 中
1 shopping_cart = pd.DataFrame(items, index=['bike', 'pants'], columns=['Bob']) 2 print(shopping_cart)
访问整列:dataframe[['column1', 'column2']]
1 # 读取列 2 print(shopping_carts[['Bob', 'Alice']])
访问整行:dataframe.loc[['row1', 'row2']]
# 读取行 print(shopping_carts.loc[['bike']])
访问某行某列:dataframe['column']['row'],先提供行标签,将出错。
# 读取某一列某一行 print(shopping_carts['Bob']['bike'])
【注意】 直接用中括号时:
- 索引表示的是列索引
- 切片表示的是行切片
shopping_carts[0:2] #读取第一二行的数据
添加整列(末尾添加列),空值用 None
# 添加列 shopping_carts['Mike'] = [10, 30, 10, 90, None]
添加整行(末尾添加行),把新添加行创建为 dataframe,通过 append() 添加
# 添加行
new_items = [{'Alice': 30, 'Bob': 20, 'Mark': 35, 'Mike': 50}]
new_store = pd.DataFrame(new_items, index=['store3'])
shopping_carts = shopping_carts.append(new_store)
只能删除整列:pop('lable')
# 删除整列
shopping_carts.pop('Jey')
删除行或者列:drop(['lable1', 'lable2'], axis=0/1) 0表示行,1表示列
# 删除行 shopping_carts = shopping_carts.drop(['store3', 'watch'], axis=0)
更改行和列标签
rename()
# 更改列标签
shopping_carts = shopping_carts.rename(columns={'Bob': 'Jey'})
# 更改行标签
shopping_carts = shopping_carts.rename(index={'bike': 'hats'})
处理 NaN
统计 NaN 数量:isnull().sum().sum
# 数值转化为 True 或者 False print(store_items.isnull()) # 每一列的 NaN 的数量 print(store_items.isnull().sum()) # NaN 总数 print(store_items.isnull().sum().sum())
统计非 NaN 数量:count(axis=0/1)
# 每一行非 NaN 的数量,通过列统计 print(store_items.count(axis=1)) # 每一列非 NaN 的数量,通过行统计 print(store_items.count(axis=0))
删除具有NaN值的行和列:dropna(axis=0/1, inplace=True/False) inplace默认False,原始DataFrame不会改变;inplace为True,在原始DataFrame删除行或者列
# 删除包含NaN值的任何行 store_items.dropna(axis=0)
# 删除包含NaN值的任何列 store_items.dropna(axis=1, inplace=True)
将 NaN 替换合适的值:fillna()
# 将所有 NaN 替换为 0 store_items.fillna(value=0) # 前向填充:将 NaN 值替换为 DataFrame 中的上个值,axis决定列或行中的上个值 store_items.fillna(method='ffill', axis=1) # 后向填充:将 NaN 值替换为 DataFrame 中的下个值,axis决定列或行中的下个值 store_items.fillna(method='backfill', axis=0)
pandas的拼接操作
- 级联:pd.concat, pd.append
- 合并:pd.merge, pd.join
级联
1,匹配级联:
import numpy as np import pandas as pd from pandas import Series,DataFrame df1 = DataFrame(data=np.random.randint(0,100,size=(3,3)),index=['a','b','c'],columns=['A','B','C']) df2 = DataFrame(data=np.random.randint(0,100,size=(3,3)),index=['a','d','c'],columns=['A','d','C']) pd.concat((df1,df1),axis=0,join='inner')
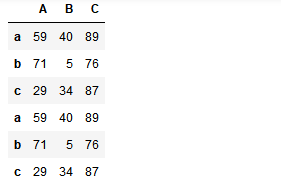
2, 不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
pd.concat((df1,df2),axis=1,join='outer')
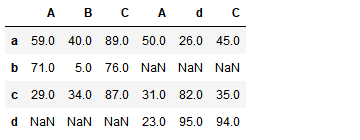
pd.merge()合并
merge与concat的区别在于,merge需要依据某一共同的列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
参数:
- how:out取并集 inner取交集
- on:当有多列相同的时候,可以使用on来指定使用那一列进行合并,on的值为一个列表
1) 一对一合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df1

df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
df2
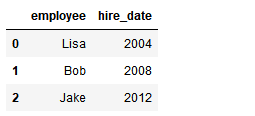
pd.merge(df1,df2,how='outer')

2) 多对一合并
df3 = DataFrame({ 'employee':['Lisa','Jake'], 'group':['Accounting','Engineering'], 'hire_date':[2004,2016]}) df3
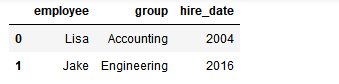
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
df4

pd.merge(df3,df4)
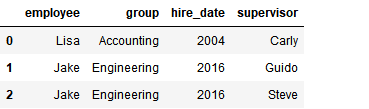
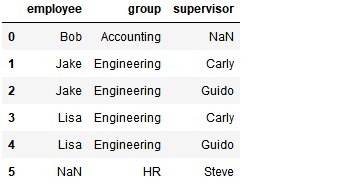
3) 多对多合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df1

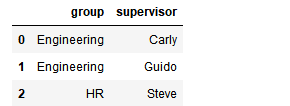
df5 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
df5
pd.merge(df1,df5,how='outer')
4) key的规范化
- 当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
df1 = DataFrame({'employee':['Jack',"Summer","Steve"],
'group':['Accounting','Finance','Marketing']})
df2 = DataFrame({'employee':['Jack','Bob',"Jake"],
'hire_date':[2003,2009,2012],
'group':['Accounting','sell','ceo']})
display(df1,df2)

- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
加载数据
csv 格式文件,每一行都是用逗号隔开:read_csv()
1 # 读取 csv 文件,第一行作为列标签
2 data = pd.read_csv('data.csv')
3 print(data)
4 print(data.shape)
5 print(type(data))
读取前 N 行数据:head(N)
# 读取头 3 行数据 print(data.head(3))
读取最后 N 行数据:tail(N)
# 读取后 5 行数据 print(data.tail(5))
检查是否有任何列包含 NaN 值:isnull().any() / notnull().all() 类型 bool
# 检查任何列是否有 NaN 值,返回值:bool print(data.isnull().any())
# 检查任何行是否不存在 NaN 值,返回值:bool
data.notnull().all(axis=1)
数据集的统计信息:describe()
1 # 获取 DataFrame 每列的统计信息:count,mean,std,min,25%,50%,75%,max 2 # 25%:四分之一位数;50%:中位数;75%:四分之三位数 3 print(data.describe()) 4 # 通过统计学函数查看某个统计信息 5 print(data.max()) 6 print(data.median())
数据相关性:不同列的数据是否有关联,1 表明关联性很高,0 表明数据不相关。corr()
1 # 数据相关性 2 print(data.corr())
数据分组:groupby(['lable1', 'lable2'])
1 # 按年份分组,统计总薪资 2 data.groupby(['Year'])['Salary'].sum() 3 # 按年份分组,统计平均薪资 4 data.groupby(['Year'])['Salary'].mean() 5 # 按年份,部门分组,统计总薪资 6 data.groupby(['Year', 'Department'])['Salary'].sum()
简单练习
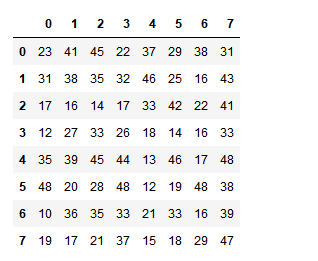
df = DataFrame(data=np.random.randint(10,50,size=(8,8))) df
df.iloc[1,2] = None df.iloc[2,2] = None df.iloc[6,2] = None df.iloc[6,7] = None df
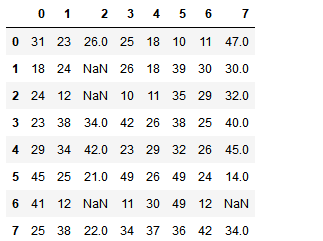
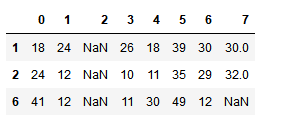
df.loc[df.isnull().any(axis=1)] # 获取所有存在空值的行
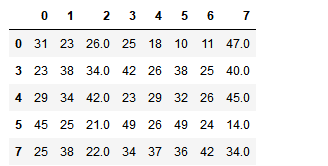
df.loc[df.notnull().all(axis=1)] # 检测所有都不为空的行

df.dropna(axis=0) # 删除存在所有存在空值的行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号