

大数据学习——sparkSql
官网http://spark.apache.org/docs/1.6.2/sql-programming-guide.html
val sc: SparkContext // An existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc) val df = sqlContext.read.json("hdfs://mini1:9000/person.json")
1.在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上 hdfs dfs -put person.json / 2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割 val lineRDD = sc.textFile("hdfs://mini1:9000/person.json").map(_.split(" "))
3.定义case class(相当于表的schema) case class Person(id:Int, name:String, age:Int)
4.将RDD和case class关联 val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
5.将RDD转换成DataFrame val personDF = personRDD.toDF
6.对DataFrame进行处理 personDF.show
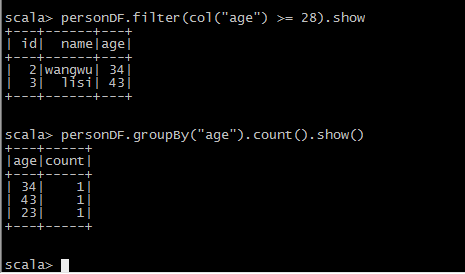
DSL风格语法



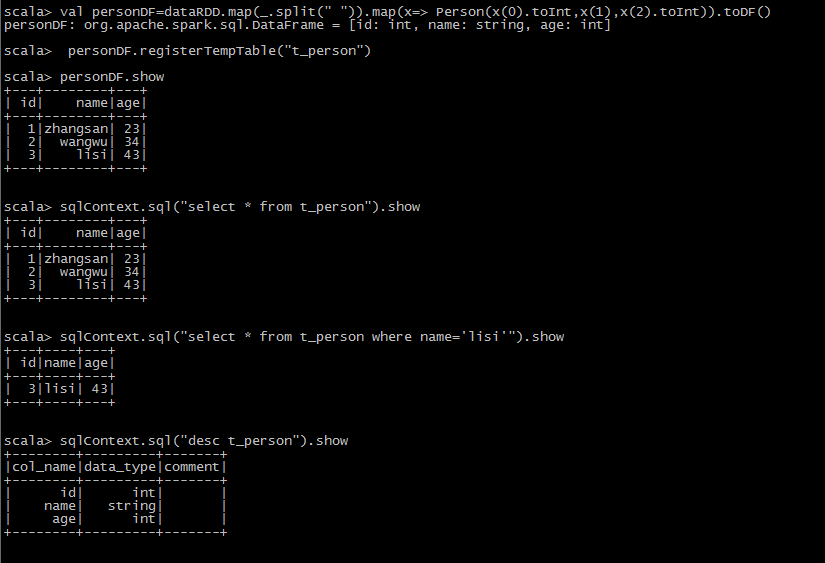
SQL风格语法
scala> val dataRDD=sc.textFile("hdfs://mini1:9000/person.json") dataRDD: org.apache.spark.rdd.RDD[String] = hdfs://mini1:9000/person.json MapPartitionsRDD[120] at textFile at <console>:27 scala> case class Person(id:Int ,name: String, age: Int) defined class Person scala> val personDF=dataRDD.map(_.split(" ")).map(x=> Person(x(0).toInt,x(1),x(2).toInt)).toDF()
scala> personDF.registerTempTable("t_person")

SparkSqlTest
package org.apache.spark import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SQLContext} /** * Created by Administrator on 2019/6/12. */ object SparkSqlTest { def main(args: Array[String]) { val conf = new SparkConf().setAppName("sparksql").setMaster("local[1]") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) val file: RDD[String] = sc.textFile("hdfs://mini1:9000/person.json") val personRDD = file.map(_.split(" ")).map(x => Person(x(0).toInt, x(1), x(2).toInt)) import sqlContext.implicits._ val personDF: DataFrame = personRDD.toDF() personDF.registerTempTable("t_person") sqlContext.sql("select * from t_person").show } } case class Person(id: Int, name: String, age: Int)
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
| 2| wangwu| 34|
| 3| lisi| 43|
+---+--------+---+
愿你遍历山河
仍觉人间值得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号