

大数据学习——spark运营案例
iplocation需求
在互联网中,我们经常会见到城市热点图这样的报表数据,例如在百度统计中,会统计今年的热门旅游城市、热门报考学校等,会将这样的信息显示在热点图中。
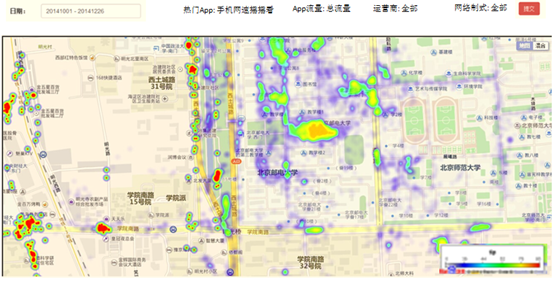
因此,我们需要通过日志信息(运行商或者网站自己生成)和城市ip段信息来判断用户的ip段,统计热点经纬度。
练习数据
链接:https://pan.baidu.com/s/14IA1pzUWEnDK_VCH_LYRLw
提取码:pnwv
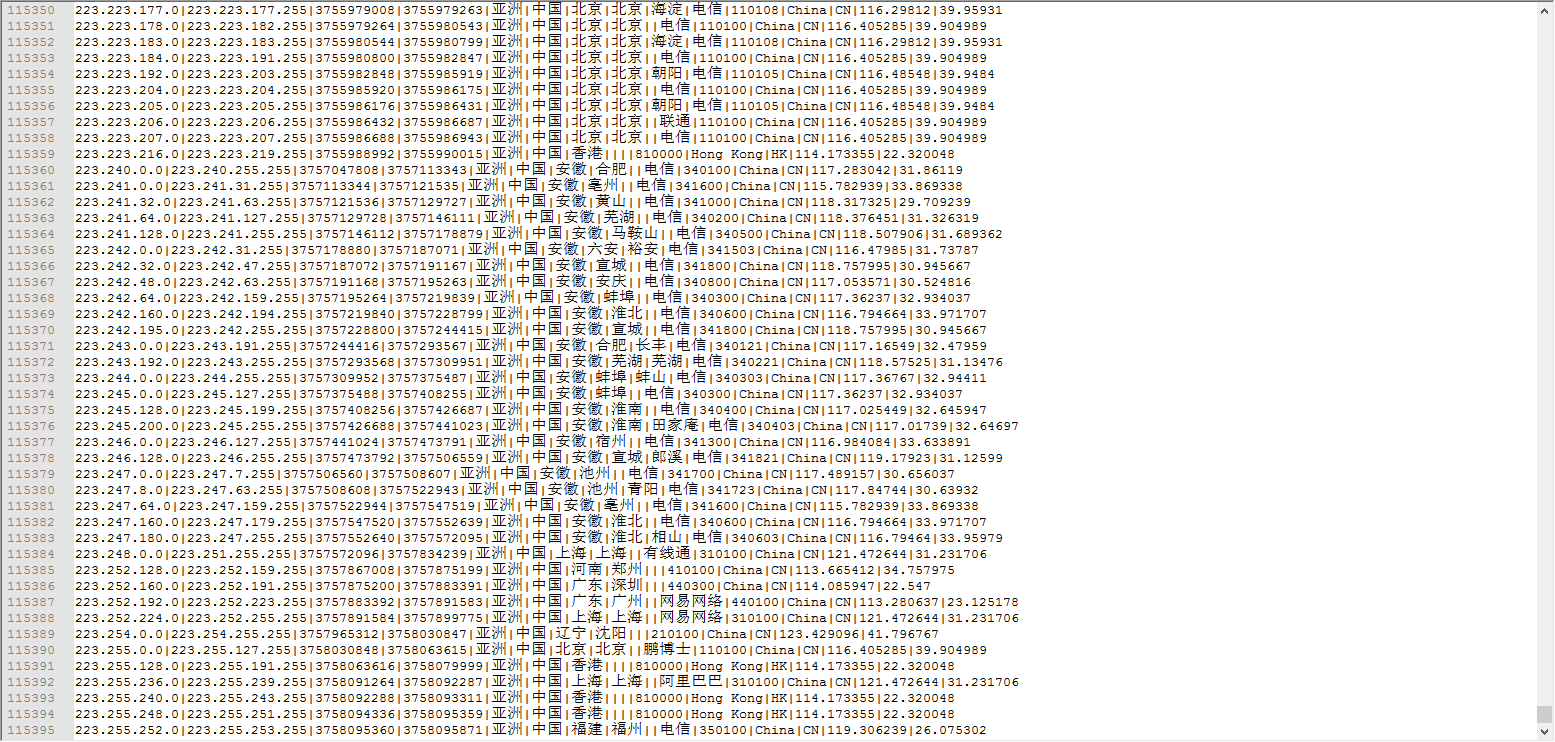
package org.apache.spark import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import java.io.{BufferedReader, FileInputStream, InputStreamReader} import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ArrayBuffer /** * Created by Administrator on 2019/6/12. */ object IPLocation { def ip2Long(ip: String): Long = { //ip转数字口诀 //分金定穴循八卦,toolong插棍左八圈 val split: Array[String] = ip.split("[.]") var ipNum = 0L for (i <- split) { ipNum = i.toLong | ipNum << 8L } ipNum } //二分法查找 def binarySearch(ipNum: Long, value: Array[(String, String, String, String, String)]): Int = { //上下循环循上下,左移右移寻中间 var start = 0 var end = value.length - 1 while (start <= end) { val middle = (start + end) / 2 if (ipNum >= value(middle)._1.toLong && ipNum <= value(middle)._2.toLong) { return middle } if (ipNum > value(middle)._2.toLong) { start = middle } if (ipNum < value(middle)._1.toLong) { end = middle } } -1 } def data2MySQL(iterator: Iterator[(String, Int)]): Unit = { var conn: Connection = null var ps: PreparedStatement = null val sql = "INSERT INTO location_count (location, total_count) VALUES (?, ?)" try { conn = DriverManager.getConnection("jdbc:mysql://192.168.74.100:3306/test", "root", "123456") iterator.foreach(line => { ps = conn.prepareStatement(sql) ps.setString(1, line._1) ps.setInt(2, line._2) ps.executeUpdate() }) } catch { case e: Exception => println(e) } finally { if (ps != null) ps.close() if (conn != null) conn.close() } } def main(args: Array[String]) { val conf = new SparkConf().setAppName("iplocation").setMaster("local[5]") val sc = new SparkContext(conf) //读取数据(ipstart,ipend,城市基站名,经度,维度) val jizhanRDD = sc.textFile("E:\\ip.txt").map(_.split("\\|")).map(x => (x(2), x(3), x(4) + "-" + x(5) + "-" + x(6) + "-" + x(7) + "-" + x(8) + "-" + x(9), x(13), x(14))) // jizhanRDD.foreach(println) //把RDD转换成数据 val jizhanPartRDDToArray: Array[(String, String, String, String, String)] = jizhanRDD.collect() //广播变量,一个只读的数据区,是所有的task都能读取的地方,相当于mr的分布式内存 val jizhanRDDToArray: Broadcast[Array[(String, String, String, String, String)]] = sc.broadcast(jizhanPartRDDToArray) // println(jizhanRDDToArray.value) val IPS = sc.textFile("E:\\20090121000132.394251.http.format").map(_.split("\\|")).map(x => x(1)) //把ip地址转换为Long类型,然后通过二分法去ip段数据中查找,对找到的经纬度做wordcount //((经度,纬度),1) val result = IPS.mapPartitions(it => { val value: Array[(String, String, String, String, String)] = jizhanRDDToArray.value it.map(ip => { //将ip转换成数字 val ipNum: Long = ip2Long(ip) //拿这个数字去ip段中通过二分法查找,返回ip在ip的Array中的角标 val index: Int = binarySearch(ipNum, value) //通Array拿出想要的数据 ((value(index)._4, value(index)._5), 1) }) }) //聚合操作 val resultFinnal: RDD[((String, String), Int)] = result.reduceByKey(_ + _) // resultFinnal.foreach(println) //将数据存储到数据库 resultFinnal.map(x => (x._1._1 + "-" + x._1._2, x._2)).foreachPartition(data2MySQL _) sc.stop() } }
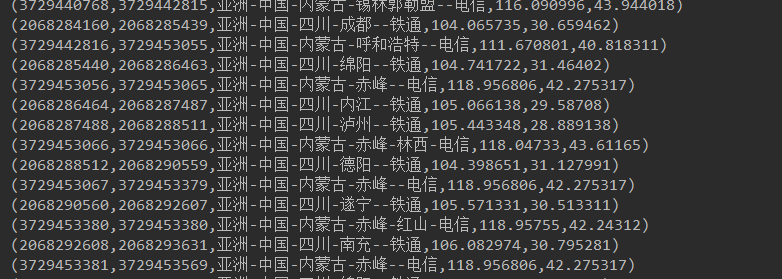
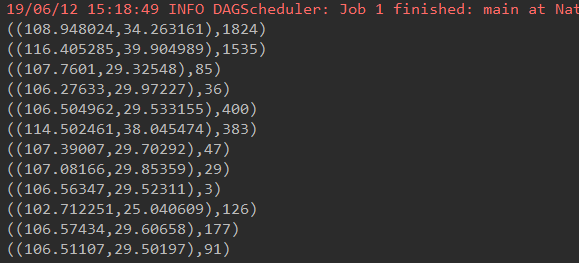
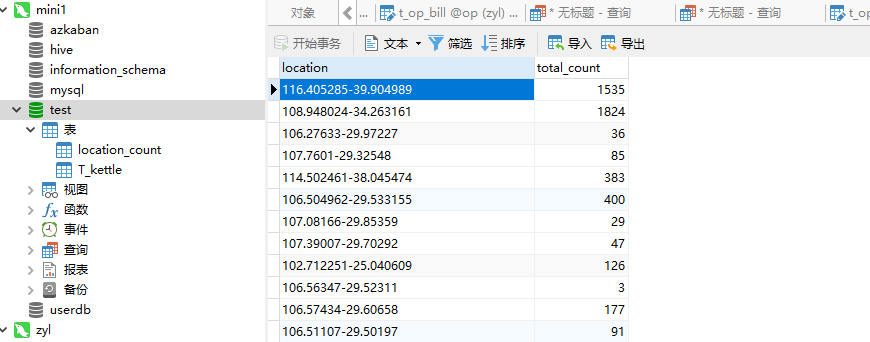
PV案例
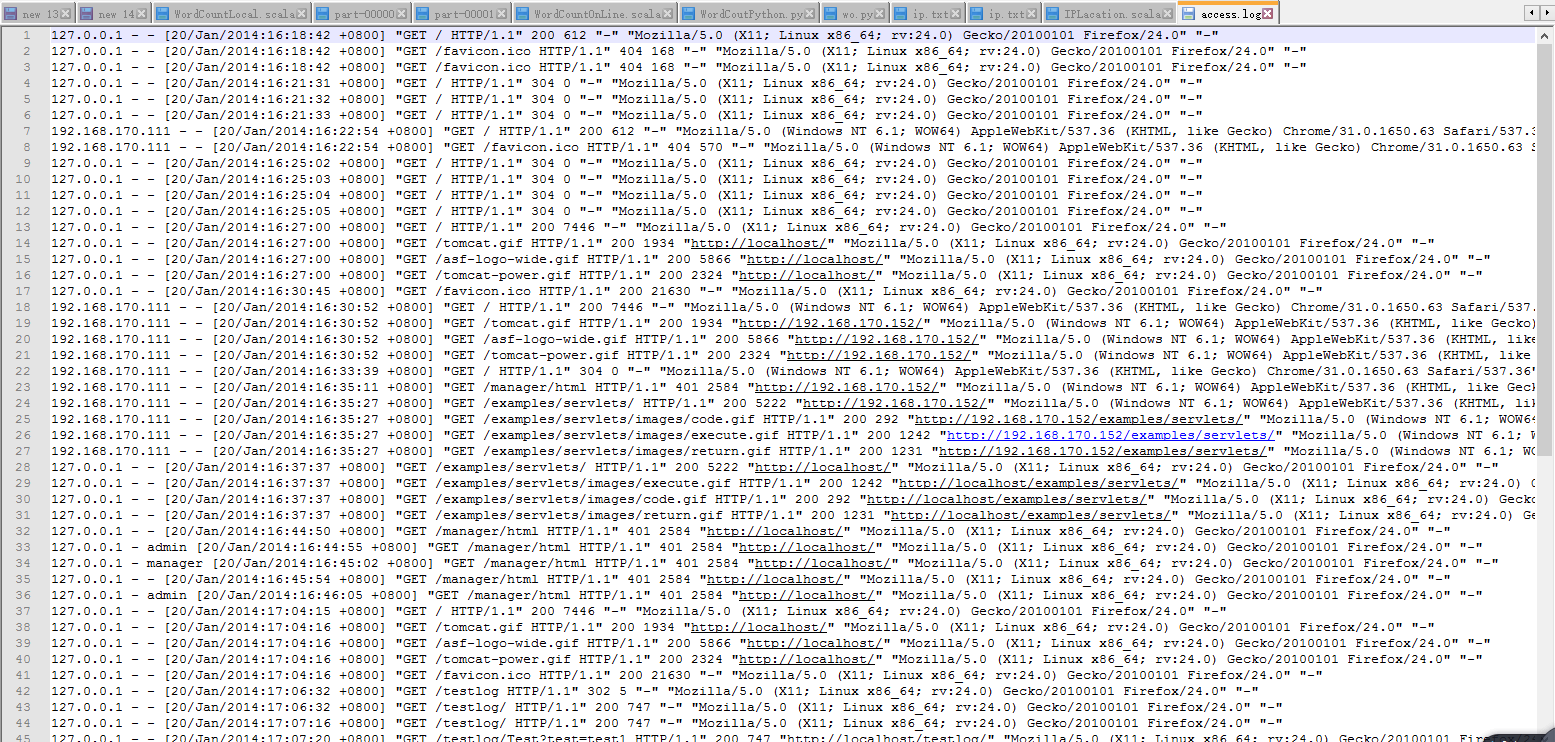
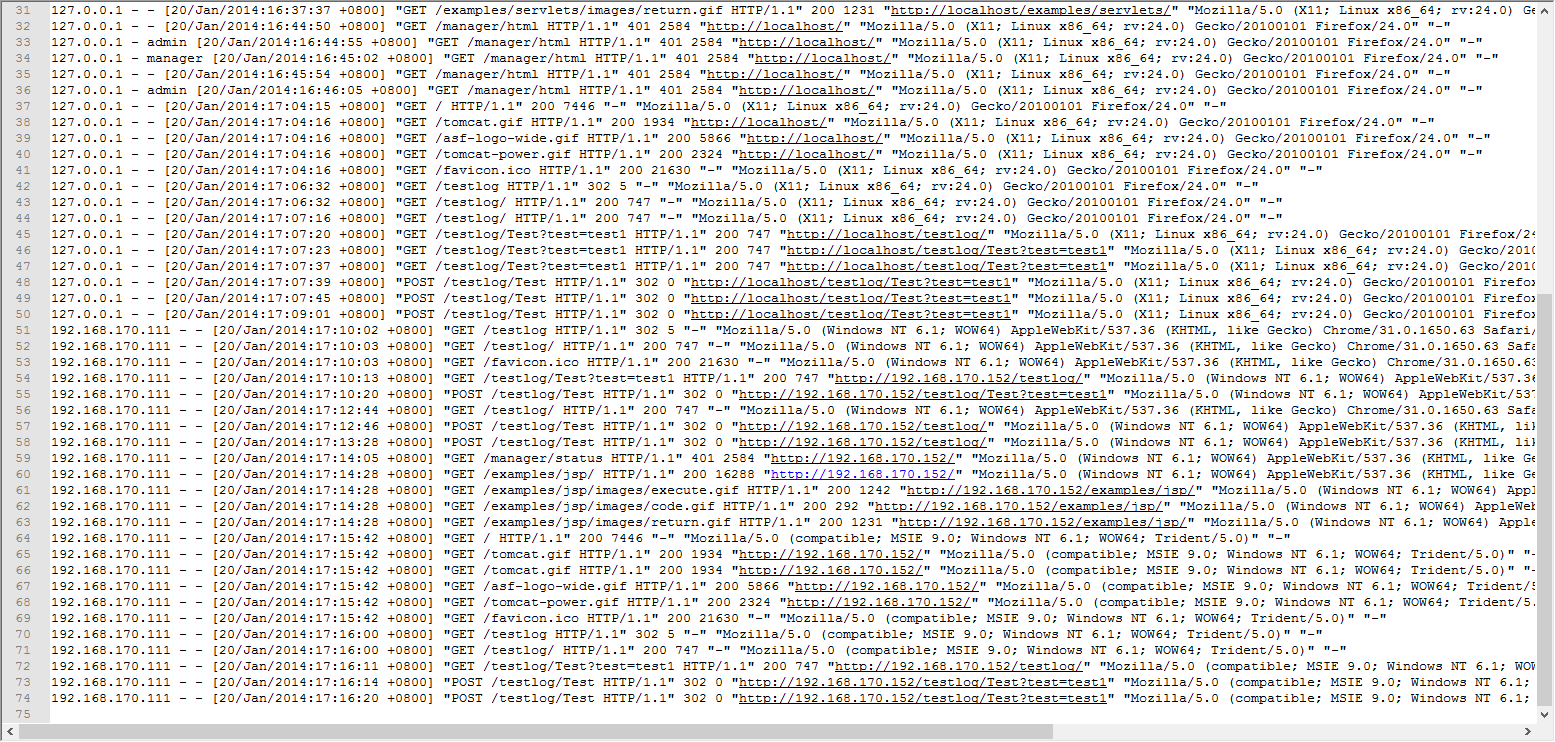
package org.apache.spark import org.apache.spark.rdd.RDD /** * Created by Administrator on 2019/6/12. */
//PV(Page View)访问量, 即页面浏览量或点击量
object PV { def main(args: Array[String]) { val conf = new SparkConf().setAppName("pv").setMaster("local[2]") val sc = new SparkContext(conf) //读取数据access.log val file: RDD[String] = sc.textFile("e:\\access.log") //将一行数据作为输入,将() val pvAndOne: RDD[(String, Int)] = file.map(x => ("pv", 1)) //聚合计算 val result = pvAndOne.reduceByKey(_ + _) result.foreach(println) } }

UV
package org.apache.spark import org.apache.spark.rdd.RDD /** * Created by Administrator on 2019/6/12. */ //UV(Unique Visitor)独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客 object UV { def main(args: Array[String]) { val conf = new SparkConf().setAppName("pv").setMaster("local[2]") val sc = new SparkContext(conf) //读取数据access.log val file: RDD[String] = sc.textFile("e:\\access.log") //要分割file,拿到ip,然后去重 val uvAndOne = file.map(_.split(" ")).map(x => x(0)).distinct().map(x => ("uv", 1)) //聚合 val result = uvAndOne.reduceByKey(_ + _) result.foreach(println) } }
pv uv环比分析
package org.apache.spark import scala.collection.mutable.ArrayBuffer /** * Created by Administrator on 2019/6/12. */ object Pvbi { // LoggerLevels.setStreamingLogLevels() val conf = new SparkConf().setAppName("pv").setMaster("local[7]") val sc = new SparkContext(conf) val PVArr = ArrayBuffer[(String, Int)]() val UVArr = ArrayBuffer[(String, Int)]() def main(args: Array[String]) { computePVOneDay("e:\\access/tts7access20140824.log") computePVOneDay("e:\\access/tts7access20140825.log") computePVOneDay("e:\\access/tts7access20140826.log") computePVOneDay("e:\\access/tts7access20140827.log") computePVOneDay("e:\\access/tts7access20140828.log") computePVOneDay("e:\\access/tts7access20140829.log") computePVOneDay("e:\\access/tts7access20140830.log") println(PVArr) computeUVOneDay("e:\\access/tts7access20140824.log") computeUVOneDay("e:\\access/tts7access20140825.log") computeUVOneDay("e:\\access/tts7access20140826.log") computeUVOneDay("e:\\access/tts7access20140827.log") computeUVOneDay("e:\\access/tts7access20140828.log") computeUVOneDay("e:\\access/tts7access20140829.log") computeUVOneDay("e:\\access/tts7access20140830.log") println(UVArr) } def computePVOneDay(filePath: String): Unit = { val file = sc.textFile(filePath) val pvTupleOne = file.map(x => ("pv", 1)).reduceByKey(_ + _) val collect: Array[(String, Int)] = pvTupleOne.collect() PVArr.+=(collect(0)) } def computeUVOneDay(filePath: String): Unit = { val rdd1 = sc.textFile(filePath) val rdd3 = rdd1.map(x => x.split(" ")(0)).distinct val rdd4 = rdd3.map(x => ("uv", 1)) val rdd5 = rdd4.reduceByKey(_ + _) val collect: Array[(String, Int)] = rdd5.collect() UVArr.+=(collect(0)) } }


TopK
package org.apache.spark import org.apache.spark.rdd.RDD /** * Created by Administrator on 2019/6/12. */ object TopK { def main(args: Array[String]) { //创建配置,设置app的name val conf = new SparkConf().setAppName("topk").setMaster("local[2]") //创建sparkcontext,将conf传进来 val sc = new SparkContext(conf) //读取数据access.log val file: RDD[String] = sc.textFile("e:\\access.log") //将一行数据作为输入,将() val refUrlAndOne: RDD[(String, Int)] = file.map(_.split(" ")).map(x => x(10)).map((_, 1)) //聚合 val result: Array[(String, Int)] = refUrlAndOne.reduceByKey(_ + _).sortBy(_._2, false).take(3) println(result.toList) } }

mobile_location案例
需要的数据
链接:https://pan.baidu.com/s/1JbGxnrgxcy05LFUmVo8AUQ
提取码:h7io
package org.apache.spark import org.apache.spark.rdd.RDD import scala.collection.mutable.Map object MobileLocation { def main(args: Array[String]) { //本地运行 val conf = new SparkConf().setAppName("UserLocation").setMaster("local[5]") val sc = new SparkContext(conf) //todo:过滤出工作时间(读取基站用户信息:18688888888,20160327081200,CC0710CC94ECC657A8561DE549D940E0,1) val officetime = sc.textFile("e:\\ce\\*.log") .map(_.split(",")).filter(x => (x(1).substring(8, 14) >= "080000" && (x(1).substring(8, 14) <= "180000"))) //todo:过滤出家庭时间(读取基站用户信息:18688888888,20160327081200,CC0710CC94ECC657A8561DE549D940E0,1) val hometime = sc.textFile("e:\\ce\\*.log") .map(_.split(",")).filter(x => (x(1).substring(8, 14) > "180000" && (x(1).substring(8, 14) <= "240000"))) //todo:读取基站信息:9F36407EAD0629FC166F14DDE7970F68,116.304864,40.050645,6 val rdd20 = sc.textFile("e:\\ce\\loc_info.txt") .map(_.split(",")).map(x => (x(0), (x(1), x(2)))) //todo:计算多余的时间次数 val map1Result = computeCount(officetime) val map2Result = computeCount(hometime) val mapBro1 = sc.broadcast(map1Result) val mapBro2 = sc.broadcast(map2Result) //todo:计算工作时间 computeOfficeTime(officetime, rdd20, "c://out/officetime", mapBro1.value) //todo:计算家庭时间 computeHomeTime(hometime, rdd20, "c://out/hometime", mapBro2.value) sc.stop() } /** * 计算多余的时间次数 * * 1、将“电话_基站ID_年月日"按key进行分组,如果value的大小为2,那么证明在同一天同一时间段(8-18或者20-24)同时出现两次,那么这样的数据需要记录,减去多余的时间 * 2、以“电话_基站ID”作为key,将共同出现的次数为2的累加,作为value,存到map中, * 例如: * 13888888888_8_20160808100923_1和13888888888_8_20160808170923_0表示在13888888888在同一天20160808的8-18点的时间段,在基站8出现入站和出站 * 那么,这样的数据对于用户13888888888在8基站就出现了重复数据,需要针对key为13888888888_8的value加1 * 因为我们计算的是几个月的数据,那么,其他天数也会出现这种情况,累加到13888888888_8这个key中 */ def computeCount(rdd1: RDD[Array[String]]): Map[String, Int] = { var map = Map(("init", 0)) //todo:groupBy:按照"电话_基站ID_年月日"分组,将符合同一组的数据聚在一起 for ((k, v) <- rdd1.groupBy(x => x(0) + "_" + x(2) + "_" + x(1).substring(0, 8)).collect()) { val tmp = map.getOrElse(k.substring(0, k.length() - 9), 0) if (v.size % 2 == 0) { //todo:以“电话_基站ID”作为key,将共同出现的次数作为value,存到map中 map += (k.substring(0, k.length() - 9) -> (tmp + v.size / 2)) } } map } /** * 计算在家的时间 */ def computeHomeTime(rdd1: RDD[Array[String]], rdd2: RDD[(String, (String, String))], outDir: String, map: Map[String, Int]) { //todo:(手机号_基站ID,时间)算法:24-x 或者 x-20 val rdd3 = rdd1.map(x => ((x(0) + "_" + x(2), if (x(3).toInt == 1) 24 - Integer.parseInt(x(1).substring(8, 14)) / 10000 else Integer.parseInt(x(1).substring(8, 14)) / 10000 - 20))) //todo:手机号_基站ID,总时间 val rdd4 = rdd3.reduceByKey(_ + _).map { case (telPhone_zhanId, totalTime) => { (telPhone_zhanId, totalTime - (Math.abs(map.getOrElse(telPhone_zhanId, 0)) * 4)) } } //todo:按照总时间排序(手机号_基站ID,总时间<倒叙>) val rdd5 = rdd4.sortBy(_._2, false) //todo:分割成:手机号,(基站ID,总时间) val rdd6 = rdd5.map { case (telphone_zhanId, totalTime) => (telphone_zhanId.split("_")(0), (telphone_zhanId.split("_")(1), totalTime)) } //todo:找到时间的最大值:(手机号,compactBuffer((基站ID,总时间1),(基站ID,总时间2))) val rdd7 = rdd6.groupByKey.map { case (telphone, buffer) => (telphone, buffer.head) }.map { case (telphone, (zhanId, totalTime)) => (telphone, zhanId, totalTime) } //todo:join都获取基站的经纬度 val rdd8 = rdd7.map { case (telphon, zhanId, time) => (zhanId, (telphon, time)) }.join(rdd2).map { //todo:(a,(1,2)) case (zhanId, ((telphon, time), (jingdu, weidu))) => (telphon, zhanId, jingdu, weidu) } rdd8.foreach(println) //rdd8.saveAsTextFile(outDir) } /** * 计算工作的时间 */ def computeOfficeTime(rdd1: RDD[Array[String]], rdd2: RDD[(String, (String, String))], outDir: String, map: Map[String, Int]) { //todo:(手机号_基站ID,时间) 算法:18-x 或者 x-8 val rdd3 = rdd1.map(x => ((x(0) + "_" + x(2), if (x(3).toInt == 1) 18 - Integer.parseInt(x(1).substring(8, 14)) / 10000 else Integer.parseInt(x(1).substring(8, 14)) / 10000 - 8))) //todo:手机号_基站ID,总时间 val rdd4 = rdd3.reduceByKey(_ + _).map { case (telPhone_zhanId, totalTime) => { (telPhone_zhanId, totalTime - (Math.abs(map.getOrElse(telPhone_zhanId, 0)) * 10)) } } //todo:按照总时间排序(手机号_基站ID,总时间<倒叙>) val rdd5 = rdd4.sortBy(_._2, false) //todo:分割成:手机号,(基站ID,总时间) val rdd6 = rdd5.map { case (telphone_zhanId, totalTime) => (telphone_zhanId.split("_")(0), (telphone_zhanId.split("_")(1), totalTime)) } //todo:找到时间的最大值:(手机号,compactBuffer((基站ID,总时间1),(基站ID,总时间2))) val rdd7 = rdd6.groupByKey.map { case (telphone, buffer) => (telphone, buffer.head) }.map { case (telphone, (zhanId, totalTime)) => (telphone, zhanId, totalTime) } //todo:join都获取基站的经纬度 val rdd8 = rdd7.map { case (telphon, zhanId, time) => (zhanId, (telphon, time)) }.join(rdd2).map { case (zhanId, ((telphon, time), (jingdu, weidu))) => (telphon, zhanId, jingdu, weidu) } rdd8.foreach(println) //rdd8.saveAsTextFile(outDir) } }
愿你遍历山河
仍觉人间值得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号