
大数据学习——spark学习
计算圆周率
[root@mini1 bin]# ./run-example SparkPi
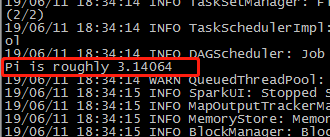
[root@mini1 bin]# ./run-example SparkPi 10

[root@mini1 bin]# ./run-example SparkPi 1000

运行spark-shell的两种方式:
1直接运行spark-shell
单机通过多线程跑任务,只运行一个进程叫submit
2运行spark-shell --master spark://mini1:7077
将任务运行在集群中,运行submit在master上,运行executor在worker上
启动
[root@mini1 bin]# ./spark-shell
hdfs
hadoop/sbin/start-dfs.sh

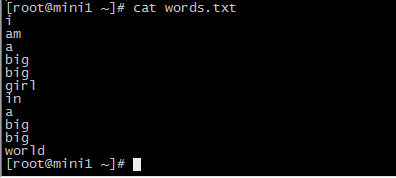
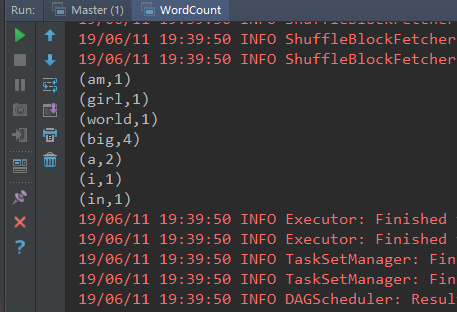
计算wordcount
sc.textFile("/root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

升序,降序排列

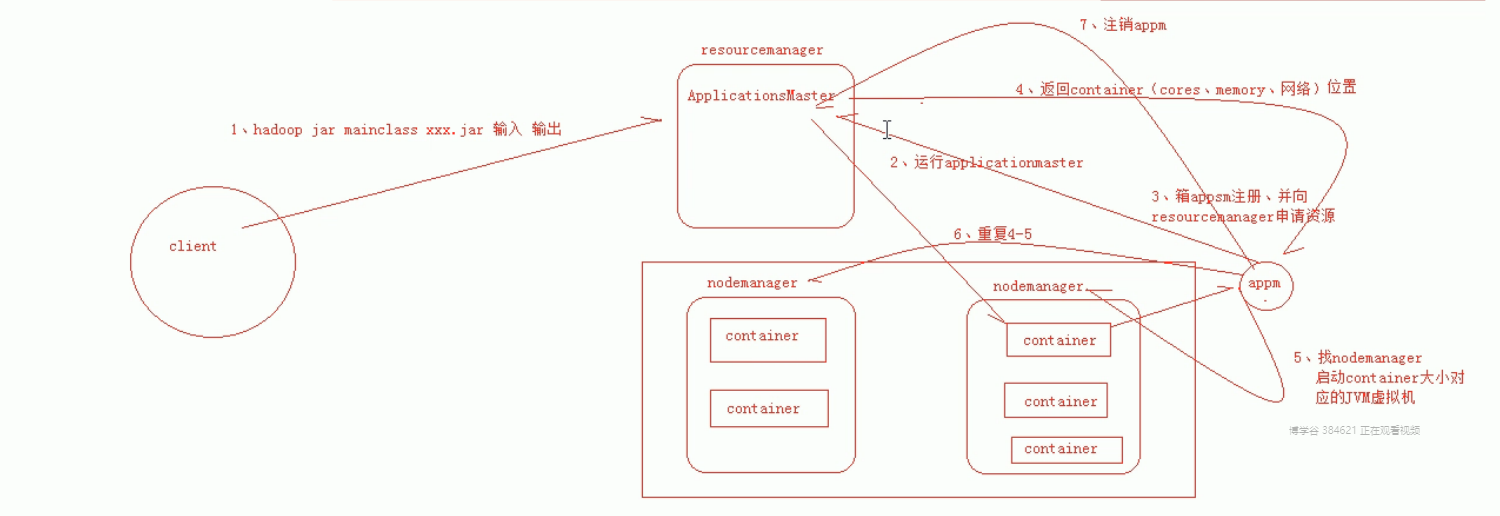
mapReduce执行流程
从hdfs采集数据
上传文件 hdfs dfs -put words.txt /
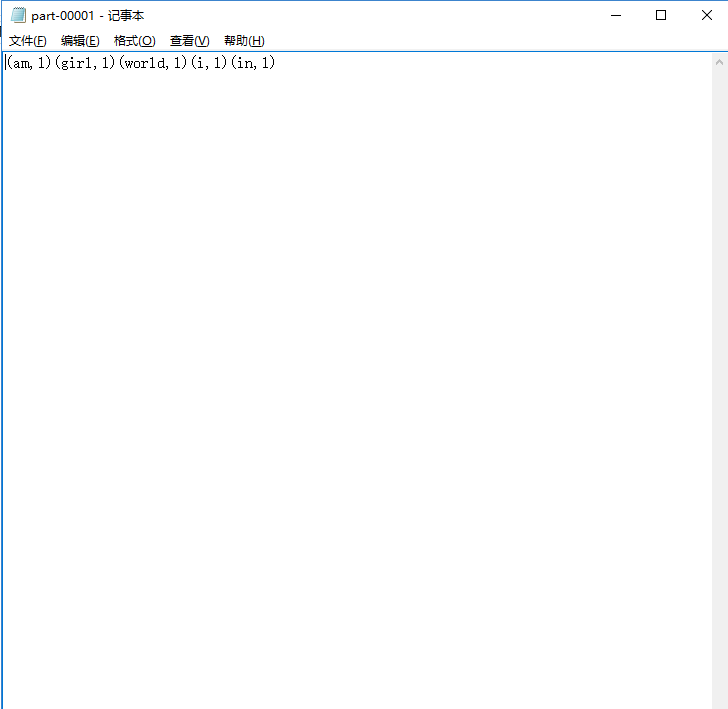
sc.textFile("hdfs://mini1:9000/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
通过spark的api写wordcount
本地运行
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * Created by Administrator on 2019/6/11. */ object WordCount extends App { //创建conf,设置应用的名字和运行的方式,local[2]运行2线程,产生两个文件结果 val conf = new SparkConf().setAppName("wordcount").setMaster("local[2]") //创建sparkcontext val sc = new SparkContext(conf) val file: RDD[String] = sc.textFile("hdfs://mini1:9000/words.txt") val words: RDD[String] = file.flatMap(_.split(" ")) //压平,分割每一行数据为每个单词 val tuple: RDD[(String, Int)] = words.map((_, 1)) //将单词转换为(单词,1) val result: RDD[(String, Int)] = tuple.reduceByKey(_ + _) //将相同的key进行汇总聚合 val resultSort: RDD[(String, Int)] = result.sortBy(_._2, false) //排序 // result.collect() //在命令行打印 resultSort.foreach(println) }
集群运行
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * Created by Administrator on 2019/6/11. */ object WordCount { def main(args: Array[String]) { //创建conf,设置应用的名字和运行的方式,local[2]运行2线程,产生两个文件结果 //.setMaster("local[1]")采用1个线程,在本地模拟spark运行模式 val conf = new SparkConf().setAppName("wordcount") //创建sparkcontext val sc = new SparkContext(conf) val file: RDD[String] = sc.textFile("hdfs://mini1:9000/words.txt") val words: RDD[String] = file.flatMap(_.split(" ")) //压平,分割每一行数据为每个单词 val tuple: RDD[(String, Int)] = words.map((_, 1)) //将单词转换为(单词,1) val result: RDD[(String, Int)] = tuple.reduceByKey(_ + _) //将相同的key进行汇总聚合 val resultSort: RDD[(String, Int)] = result.sortBy(_._2, false) //排序 resultSort.saveAsTextFile(args(1)) } }
打包
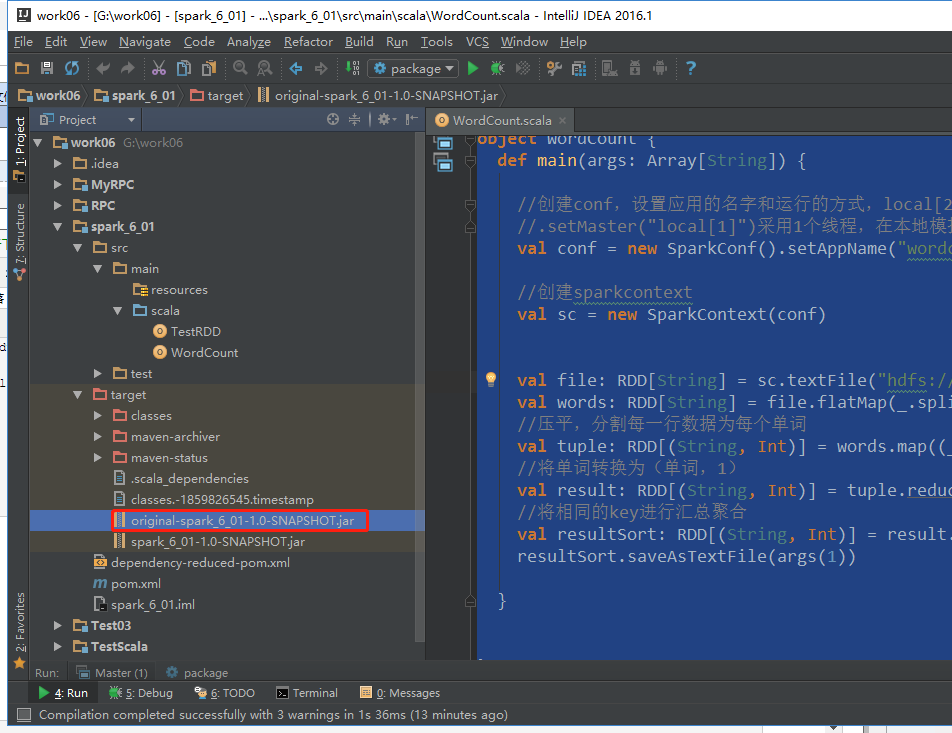

把该代码包传到任意一台装有spark的机器上

我上传到了bin下

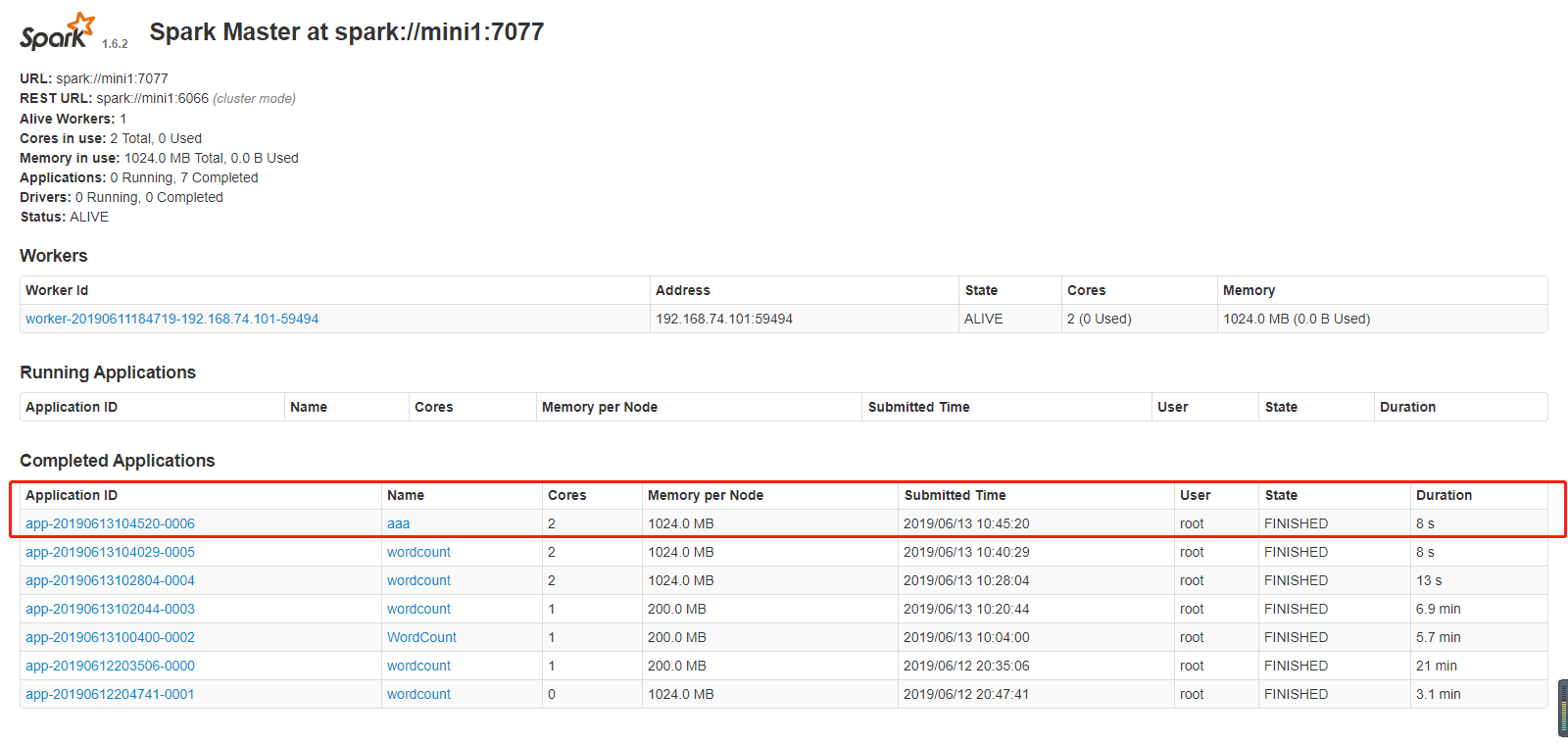
提交
[root@mini1 bin]# ./spark-submit --help
#开始加了这两个参数 导致一直运行失败,链接超时,还去问了初夏老师
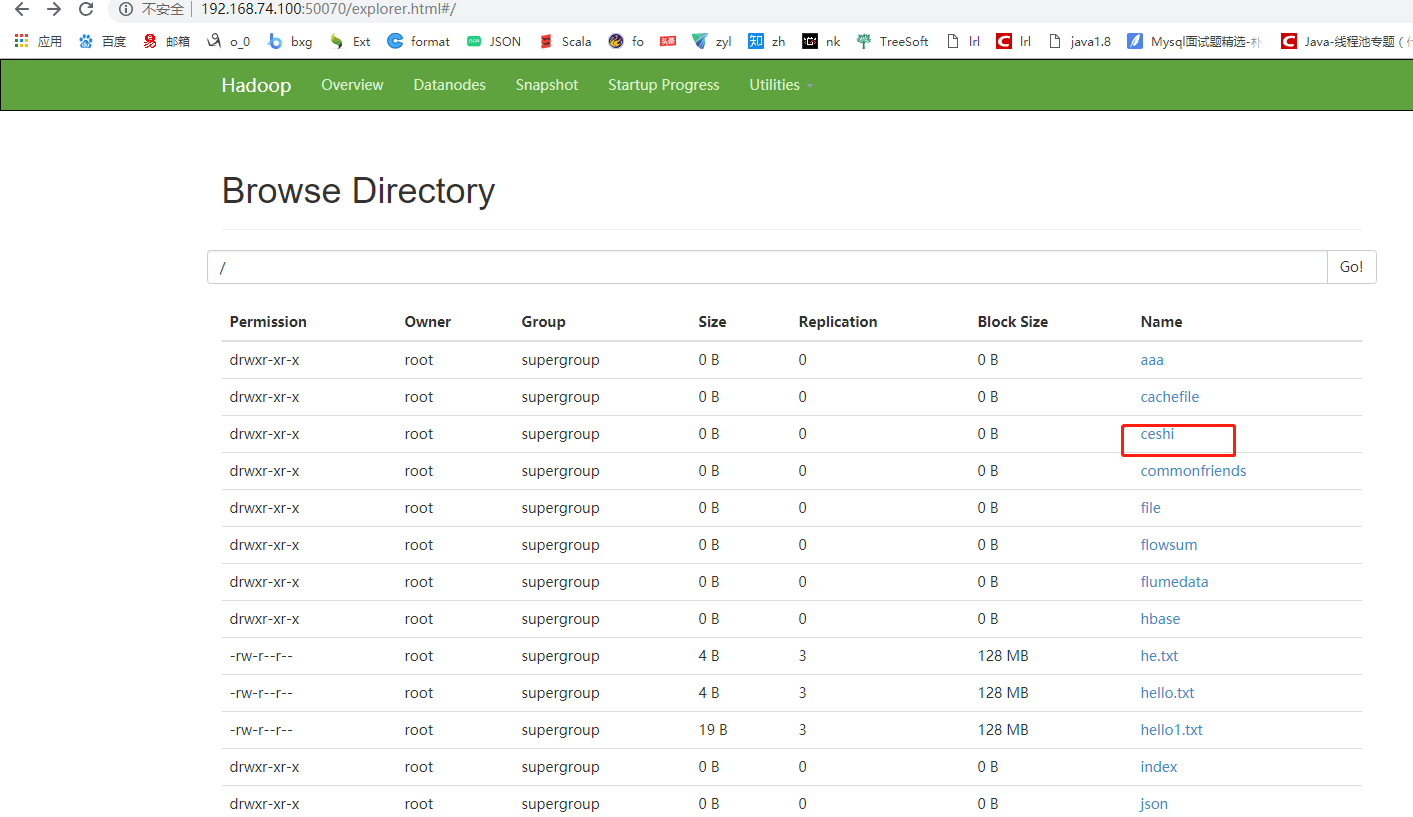
[root@mini1 bin]# ./spark-submit --master spark://mini1:7077--class com.cyf.WordCount --executor-memory 200M --total-executor-cores 1 original-spark_6_01-1.0-SNAPSHOT.jar hdfs://mini1:9000/words.txt hdfs://mini1:9000/ceshi/wordcountcluster
[root@mini1 bin]#./spark-submit --master spark://mini1:7077 --class com.cyf.WordCount original-spark_6_01-1.0-SNAPSHOT.jar hdfs://mini1:9000/words.txt hdfs://mini1:9000/ceshi/wordcountcluster
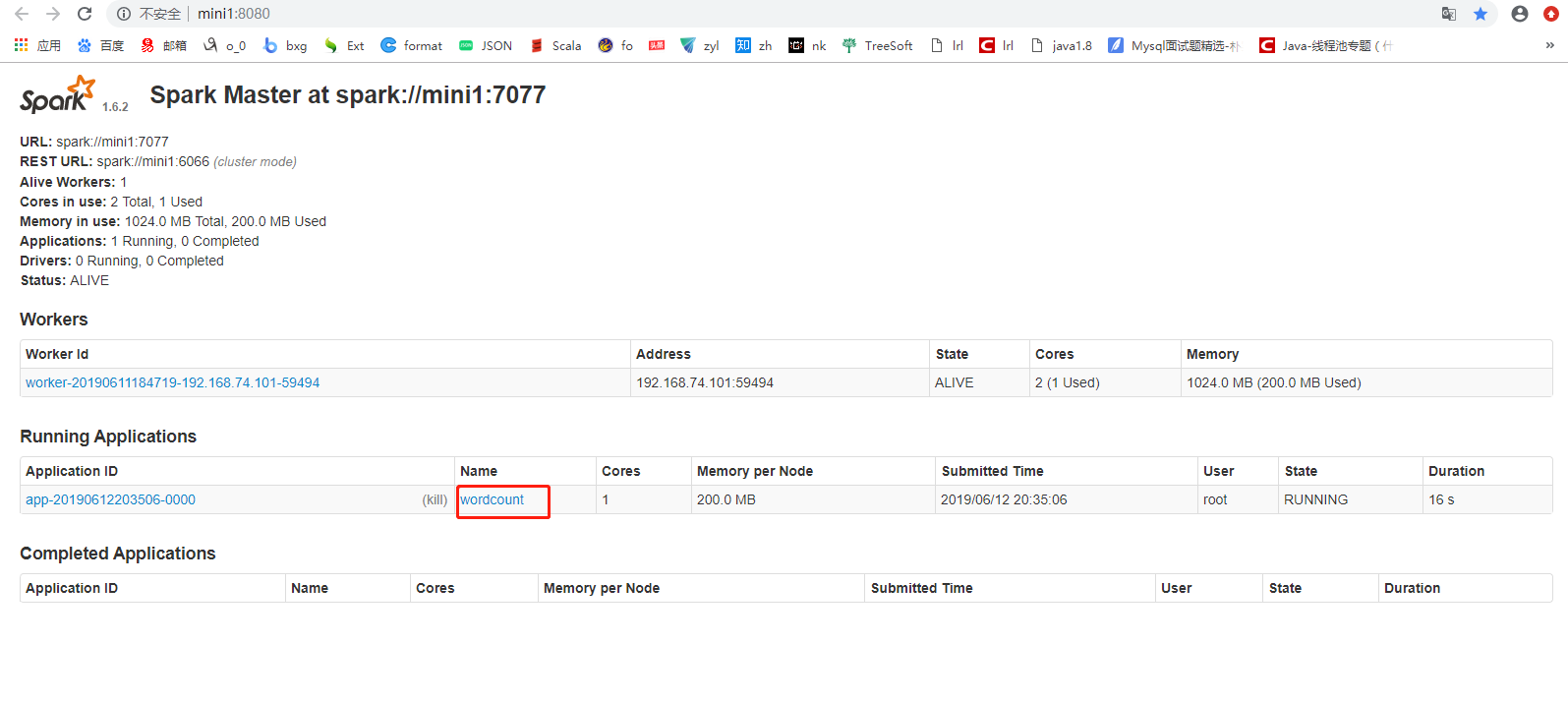
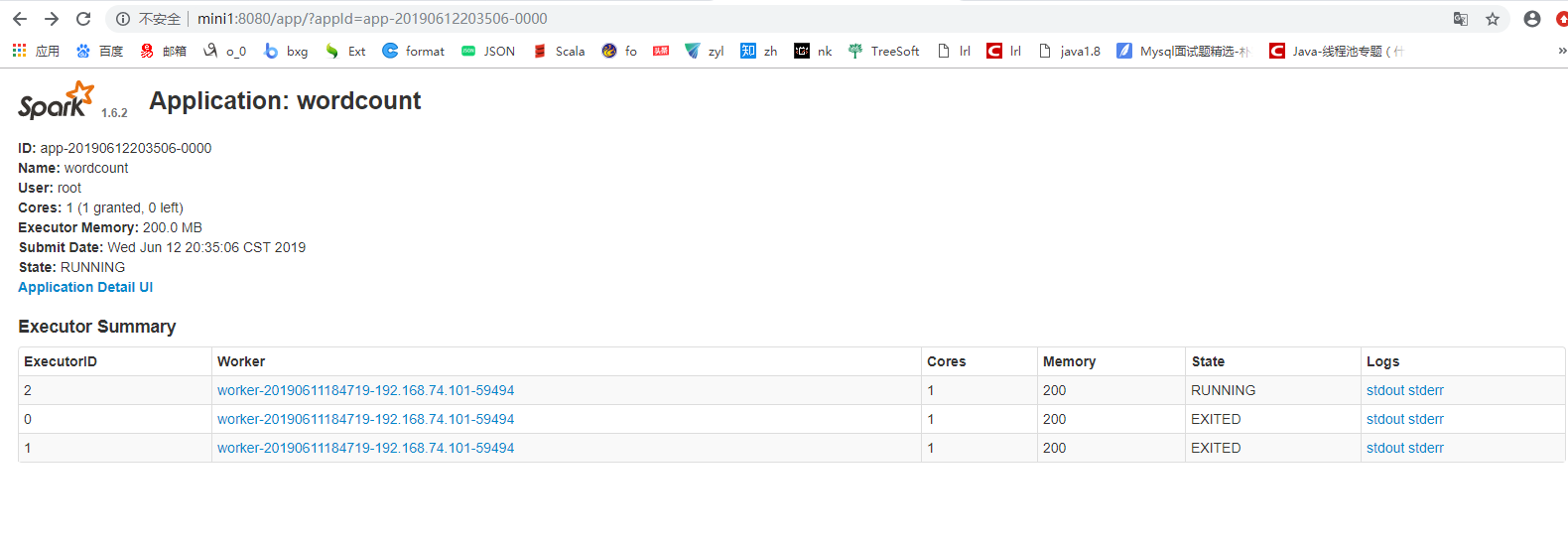
开始加上边两个参数运行,一直报连接超时的错误
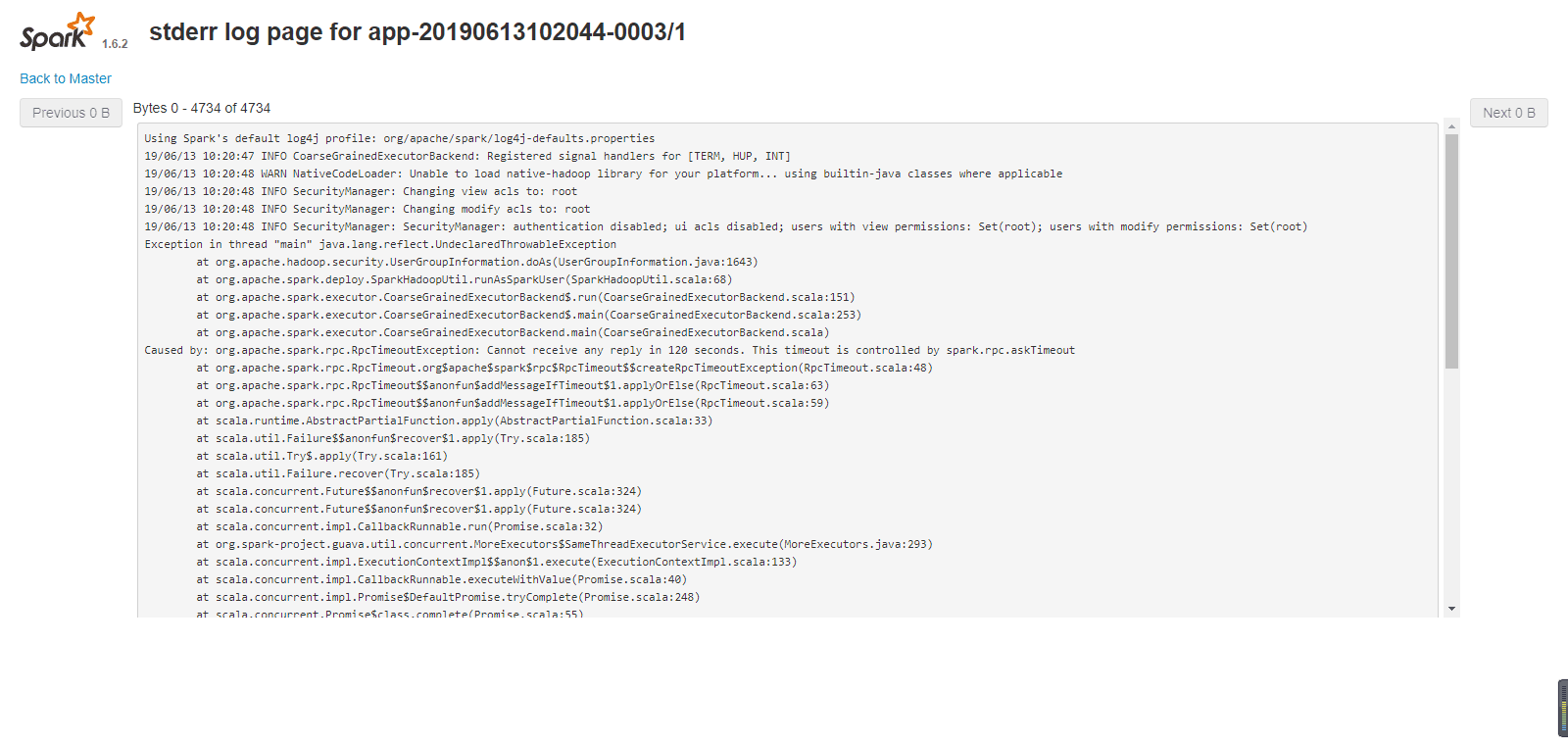
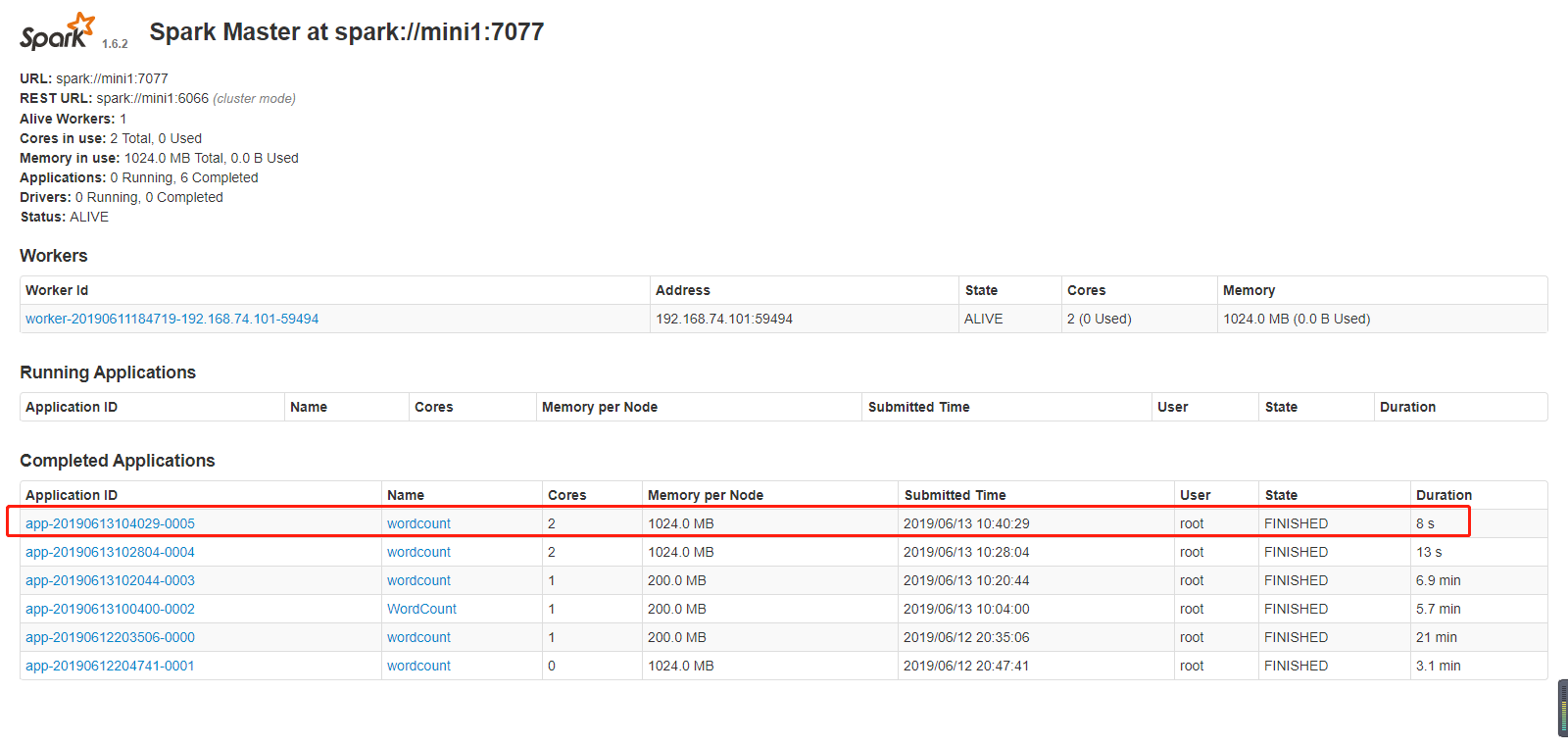
后来把参数去掉,运行成功了


python
wo.py
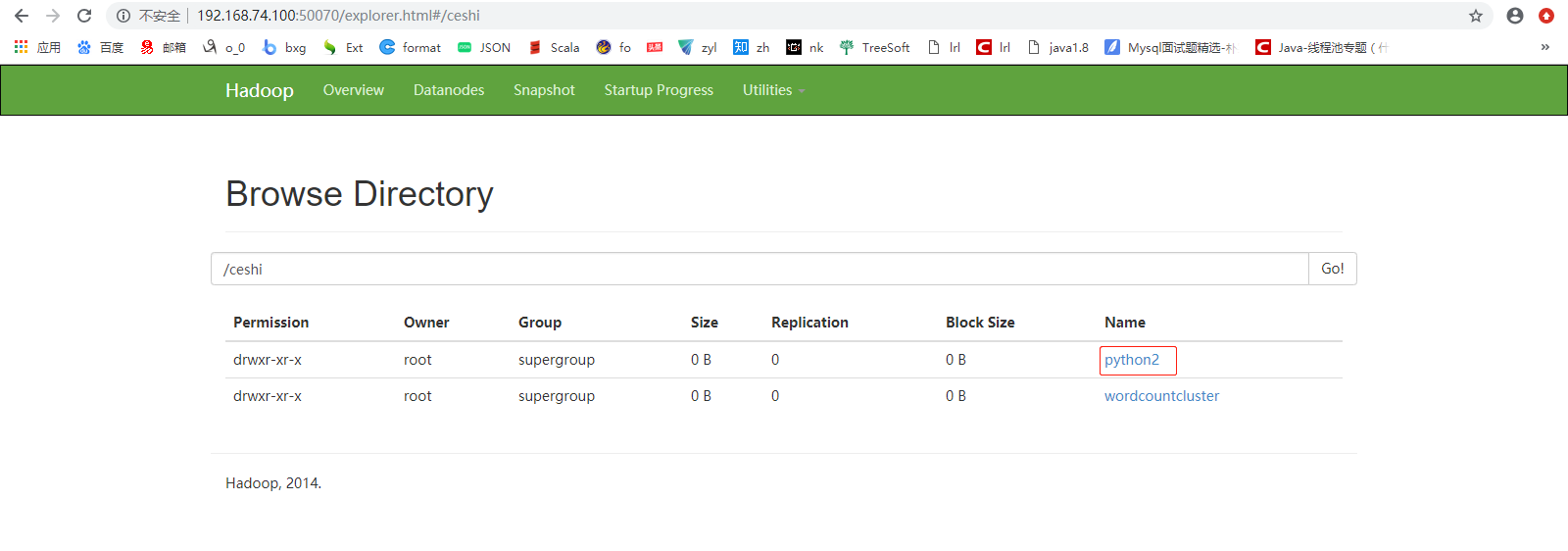
#!/usr/bin/python from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName("aaa").setMaster("spark://mini1:7077") sc = SparkContext(conf=conf) data = ["tom", "lilei", "tom", "lilei", "wangsf"] rdd = sc.parallelize(data).map(lambda x: (x, 1 )).reduceByKey(lambda a, b: a + b).saveAsTextFile("hdfs://mini1:9000/ceshi/python2")
上传,运行
[root@mini1 bin]# ./spark-submit wo.py


愿你遍历山河
仍觉人间值得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号