

大数据学习——Storm学习单词计数案例
需求:计算单词在文档中出现的次数,每出现一次就累加一次
遇到的问题
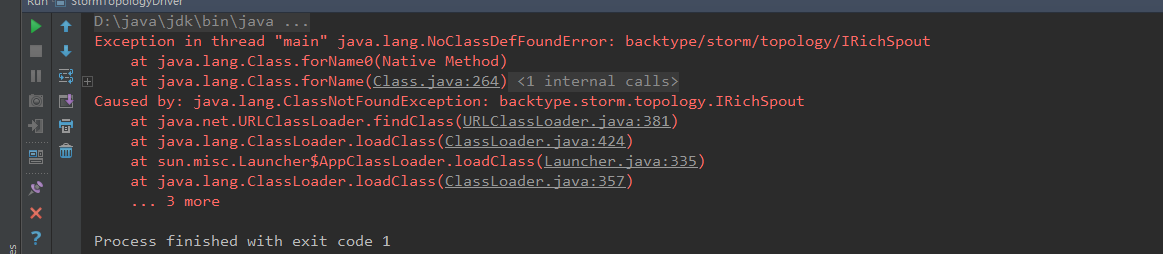
这个问题是<scope>provided</scope>作用域问题
https://www.cnblogs.com/biehongli/p/8316885.html
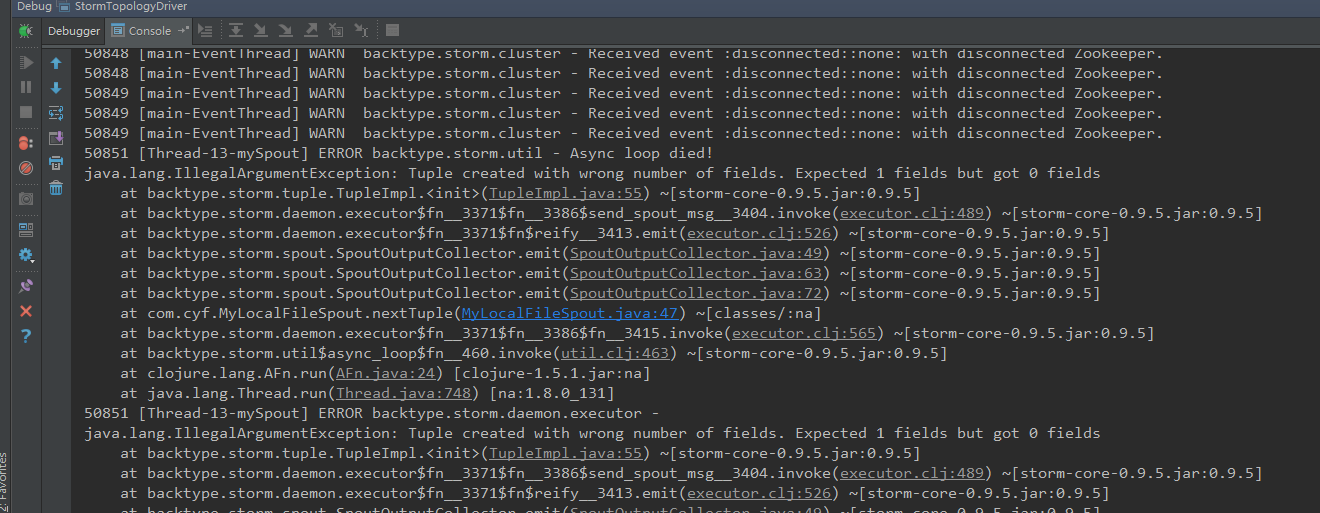
这个问题是需要把从文件中读取的内容放入list
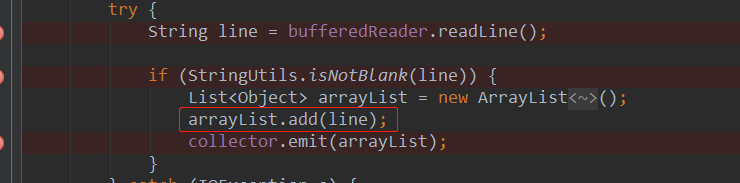
代码如下
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId> <artifactId>TestStorm</artifactId> <version>1.0-SNAPSHOT</version> <repositories> <repository> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>0.9.5</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>2.4</version> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <classpathPrefix>lib/</classpathPrefix> <mainClass>com.cyf.StormTopologyDriver</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build> </project>
MyLocalFileSpout
package com.cyf; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import org.apache.commons.lang.StringUtils; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.Map; /** * Created by Administrator on 2019/2/19. */ public class MyLocalFileSpout extends BaseRichSpout { private SpoutOutputCollector collector; private BufferedReader bufferedReader; //初始化方法 public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this.collector = spoutOutputCollector; try { // this.bufferedReader = new BufferedReader(new FileReader("/root/1.log")); this.bufferedReader = new BufferedReader(new FileReader("D:\\1.log")); } catch (FileNotFoundException e) { e.printStackTrace(); } } //循环调用的方法 //Storm实时计算的特性就是对数据一条一条的处理 public void nextTuple() { //每调用一次就会发送一条数据出去 try { String line = bufferedReader.readLine(); if (StringUtils.isNotBlank(line)) { List<Object> arrayList = new ArrayList<Object>(); arrayList.add(line); collector.emit(arrayList); } } catch (IOException e) { e.printStackTrace(); } } public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("juzi")); } }
MySplitBolt
package com.cyf; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; /** * Created by Administrator on 2019/2/19. */ public class MySplitBolt extends BaseBasicBolt { public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { //1.数据如何获取 String juzi = (String) tuple.getValueByField("juzi"); //2.进行切割 String[] strings = juzi.split(" "); //3.发送数据 for (String word : strings) { basicOutputCollector.emit(new Values(word, 1)); } } public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("word", "num")); } }
MyWordCountAndPrintBolt
package com.cyf; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Tuple; import java.util.HashMap; import java.util.Map; /** * Created by Administrator on 2019/2/19. */ public class MyWordCountAndPrintBolt extends BaseBasicBolt { private Map<String, Integer> wordCountMap = new HashMap<String, Integer>(); public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { String word = (String) tuple.getValueByField("word"); Integer num = (Integer) tuple.getValueByField("num"); //1查看单词对应的value是否存在 Integer integer = wordCountMap.get(word); if (integer == null || integer.intValue() == 0) { wordCountMap.put(word, num); } else { wordCountMap.put(word, integer.intValue() + num); } //2.打印数据 System.out.println(wordCountMap); } public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } }
StormTopologyDriver
package com.cyf; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.generated.AlreadyAliveException; import backtype.storm.generated.InvalidTopologyException; import backtype.storm.generated.StormTopology; import backtype.storm.topology.TopologyBuilder; /** * Created by Administrator on 2019/2/21. */ public class StormTopologyDriver { public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException { //1准备任务信息 TopologyBuilder topologyBuilder = new TopologyBuilder(); topologyBuilder.setSpout("mySpout", new MyLocalFileSpout()); topologyBuilder.setBolt("bolt1", new MySplitBolt()).shuffleGrouping("mySpout"); topologyBuilder.setBolt("bolt2", new MyWordCountAndPrintBolt()).shuffleGrouping("bolt1"); //2任务提交 //提交给谁,提交什么内容 Config config=new Config(); StormTopology stormTopology=topologyBuilder.createTopology(); //本地模式 LocalCluster localCluster=new LocalCluster(); localCluster.submitTopology("wordcount",config,stormTopology); //集群模式 // StormSubmitter.submitTopology("wordcount",config,stormTopology); } }
本地运行结果:
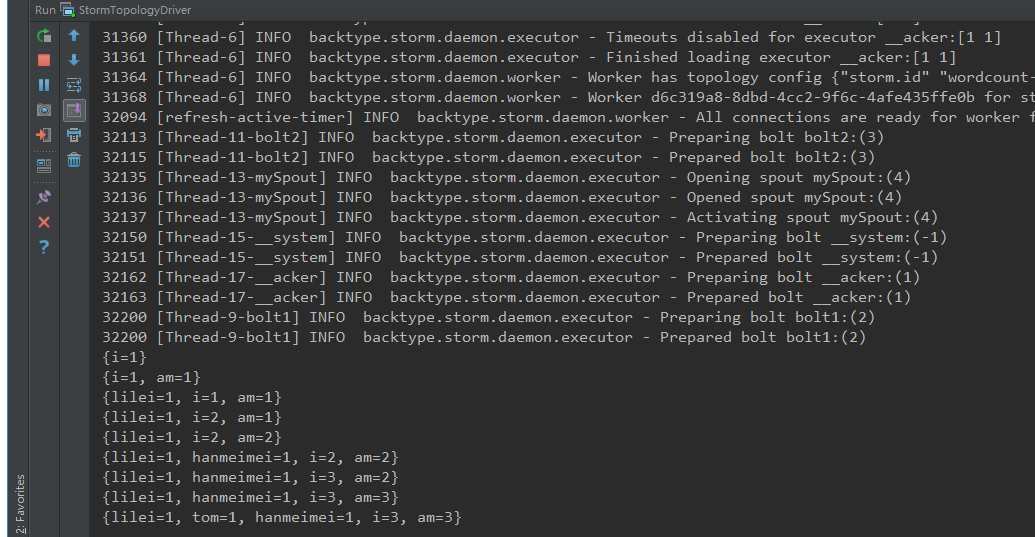
在集群上运行

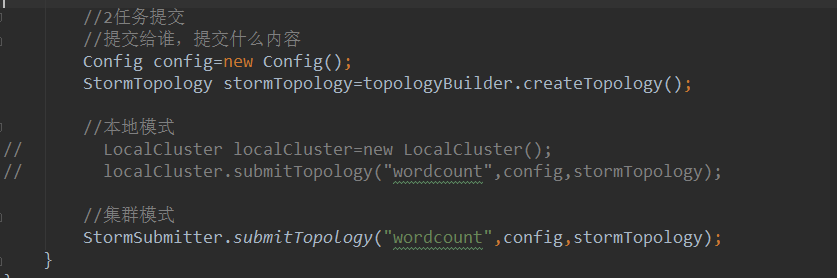
运行命令:
storm jar TestStorm.jar com.cyf.StormTopologyDriver
愿你遍历山河
仍觉人间值得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号