

大数据学习——sqoop导入数据
把数据从关系型数据库导入到hadoop
启动sqoop

导入表表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
sqoop import \ --connect jdbc:mysql://mini1:3306/userdb \ --username root \ --password 123456 \ --table emp --m 1

在/root/sqoop下执行命令,导入emp表到hdfs
./sqoop import \ --connect jdbc:mysql://mini1:3306/userdb \ --username root \ --password 123456 \ --table emp --m 1
注意执行上边的命令可能会遇到这个问题 https://www.cnblogs.com/feifeicui/p/10311076.html
查看执行结果
hdfs dfs -ls /user/root
![]()


在/root/sqoop下执行命令,导入emp_add表到hdfs
./sqoop import \ --connect jdbc:mysql://mini1:3306/userdb \ --username root \ --password 123456 \ --table emp_add --m 1

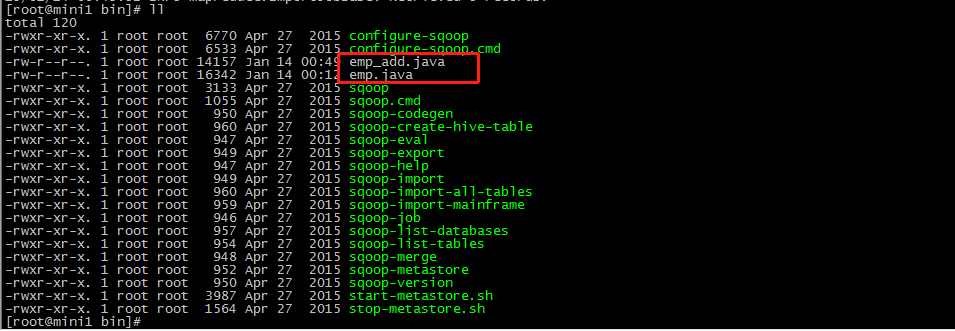
执行完命令会生成 emp_add.java emp.java
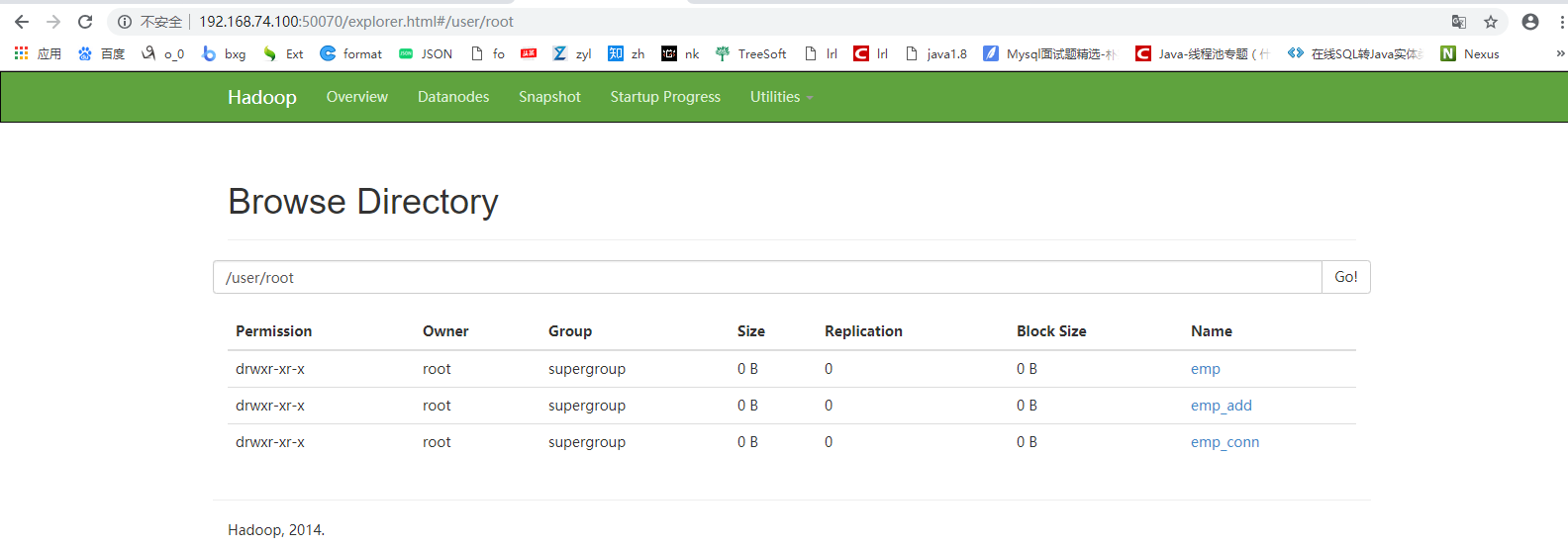
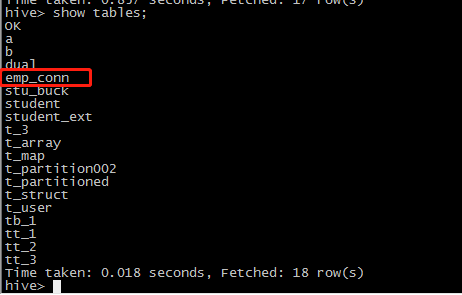
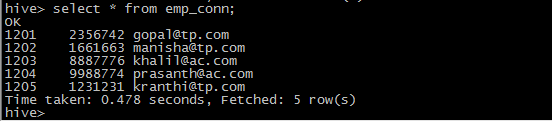
把数据库的emp_conn这个表先导入到hdfs上 /user/root/emp_con这个目录下,然后将这个目录下的数据通过load形式导入到hive表中,这里还没有指明对应的hive上的表名,它会用mysql数据库的表名。
./sqoop import \ --connect jdbc:mysql://mini1:3306/userdb \ --username root \ --password 123456 \ --table emp_conn --hive-import --m 1
导入到HDFS指定目录
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
以下是指定目标目录选项的Sqoop导入命令的语法。
|
--target-dir <new or exist directory in HDFS> |
下面的命令是用来导入emp_add表数据到'/queryresult'目录。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --target-dir /queryresult \ --table emp --m 1 |
下面的命令是用来验证 /queryresult 目录中 emp_add表导入的数据形式。
|
$HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-* |
它会用逗号(,)分隔emp_add表的数据和字段。
|
1201, 288A, vgiri, jublee 1202, 108I, aoc, sec-bad 1203, 144Z, pgutta, hyd 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
导入表数据子集
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
|
--where <condition> |
下面的命令用来导入emp_add表数据的子集。子集查询检索员工ID和地址,居住城市为:Secunderabad
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --where "city ='sec-bad'" \ --target-dir /wherequery \ --table emp_add --m 1 |
按需导入
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --target-dir /wherequery2 \ --query 'select id,name,deg from emp WHERE id>1207 and $CONDITIONS' \ --split-by id \ --fields-terminated-by '\t' \ --m 1 |
下面的命令用来验证数据从emp_add表导入/wherequery目录
|
$HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-* |
它用逗号(,)分隔 emp_add表数据和字段。
|
1202, 108I, aoc, sec-bad 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
增量导入
增量导入是仅导入新添加的表中的行的技术。
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。
|
--incremental <mode> --check-column <column name> --last value <last check column value>
|
假设新添加的数据转换成emp表如下:
1206, satish p, grp des, 20000, GR
下面的命令用于在EMP表执行增量导入。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp --m 1 \ --incremental append \ --check-column id \ --last-value 1205 |
以下命令用于从emp表导入HDFS emp/ 目录的数据验证。
|
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-* 它用逗号(,)分隔 emp_add表数据和字段。 1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
下面的命令是从表emp 用来查看修改或新添加的行
|
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1 这表示新添加的行用逗号(,)分隔emp表的字段。 1206, satish p, grp des, 20000, GR |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号