

大数据学习——hive基本操作
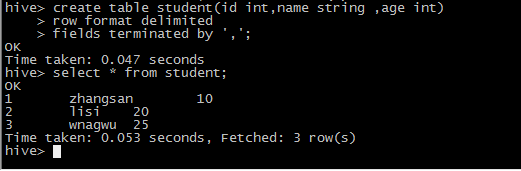
1 建表
create table student(id int,name string ,age int)
row format delimited
fields terminated by ',';
2 创建一个student.txt
添加数据
1,zhangsan,10 2,lisi,20 3,wnagwu,25
3 上传
hdfs dfs -put student.txt /user/hive/warehouse/student
4 select * from student;
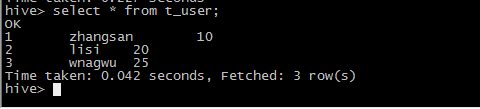
5 通常不会通过put方式加载数据,而是通过load的方式添加数据
create table t_user(id int,name string ,age int) row format delimited fields terminated by ',';
load data local inpath '/root/student.txt' into table t_user;
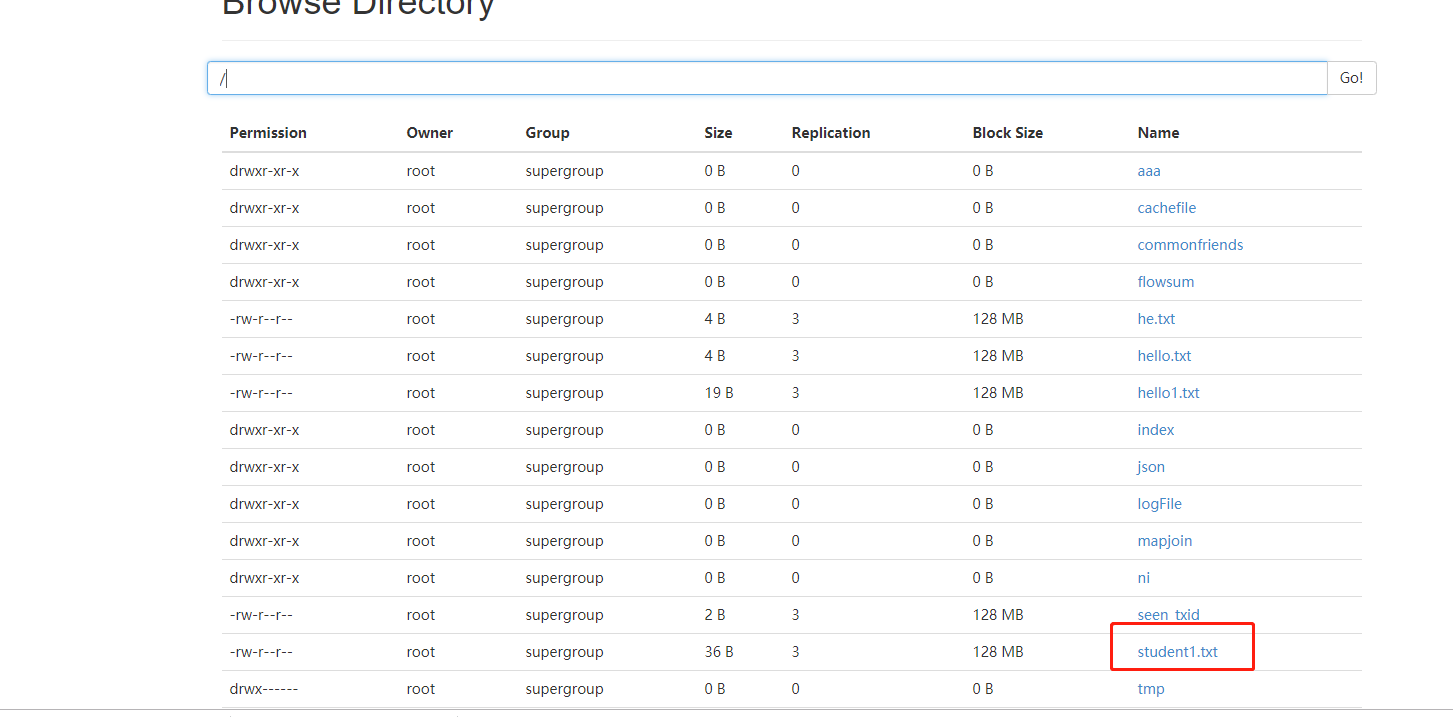
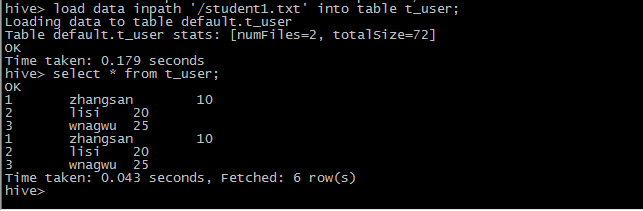
6 添加hdfs上的数据到hive
hdfs dfs -put student1.txt /
7 内部表和外部表的区别
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
企业开发中经常使用的是外部表,删除表后,元数据还在,比较安全
8 创建一个分区表
create table t_partitioned(ip string ,duration int) partitioned by(country string) row format delimited fields terminated by ',';
9 造数据
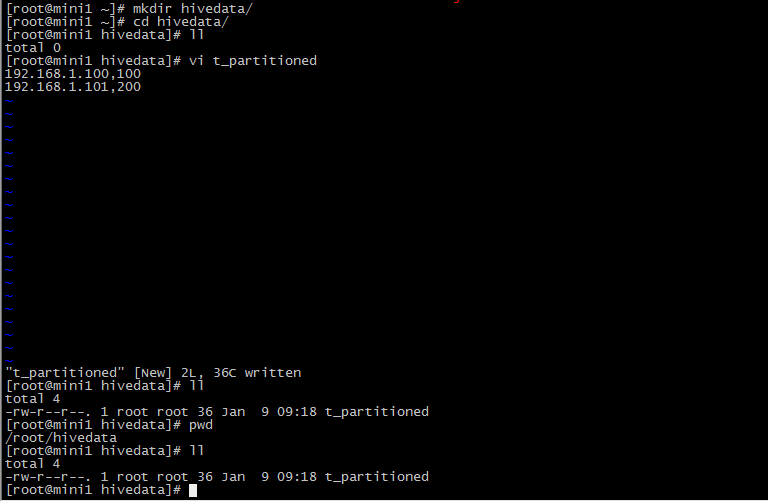



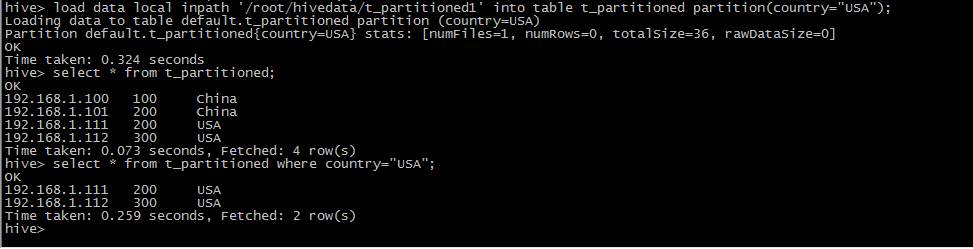
10 数据存储格式
STORED AS
SEQUENCEFILE|TEXTFILE|RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
create table t_3(id int,name string) row format delimited fields terminated by ',' stored as sequencefile;
插入数据(不能用load方式添加数据)
insert overwrite table t_3 select id,name from student;
愿你遍历山河
仍觉人间值得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号