

大数据学习——Hadoop第一天
1.1 什么是HADOOP
- HADOOP是apache旗下的一套开源软件平台
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
国内外HADOOP应用案例介绍
1、HADOOP应用于数据服务基础平台建设
2、/HADOOP用于用户画像
3、HADOOP用于网站点击流日志数据挖掘
金融行业: 个人征信分析
证券行业: 投资模型分析
交通行业: 车辆、路况监控分析
电信行业:用户上网行为分析
...
总之:hadoop并不会跟某种具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具
HADOOP生态圈以及各组成部分的简介
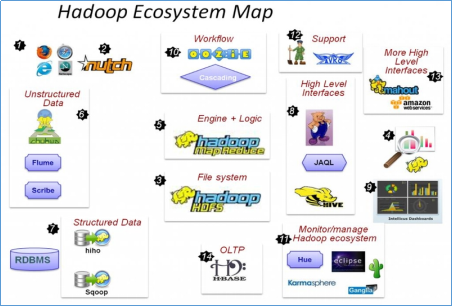
重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
愿你遍历山河
仍觉人间值得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号