

论文阅读:Automated Models of Human Everyday Activity based on Game and Virtual Reality Technology
Automated Models of Human Everyday Activity based on Game and Virtual Reality Technology
基于游戏和虚拟现实技术的人类日常活动自动化模型
作者:Andrei Haidu and Michael Beetz
作者主页
https://ai.uni-bremen.de/team/andrei_haidu
0.摘要
在本文中,我们将描述AMEVA(日常活动的自动模型),这是一种用于人类日常操纵活动的专用知识获取,解释和处理系统,该系统可以自动:(1)创建和模拟虚拟人的生活 具有一定范围,范围,细节水平,物理特性以及接近于真实感的工作环境(例如厨房和公寓),可以促进并促进人类日常操纵活动的自然和现实执行; (2)记录在各个虚拟现实环境中执行的人类操纵活动及其对环境的影响,并检测力动态状态和事件; (3)将记录的活动数据分解并分割为有意义的动作,并根据认知科学中使用的动作模型对动作进行分类; (4)使用一阶时间间隔逻辑表示法,在KNOWROB [1]中象征性地表示所解释的活动。
1.介绍
由于我们现在拥有可以完成移动获取和放置任务的机器人代理程序[2],[3],[4],因此下一个挑战是如何将这些功能扩展到掌握人为操作的任务中,例如放置和清理桌面,加载 并卸下洗碗机,或将物品放回橱柜。 应对这些挑战的最大障碍之一是必须具备机器人代理才能成功完成这些任务的知识。
例如,考虑设置桌面的任务。 如果机器人代理得到的任务不足以“设置桌子”,则它需要大量知识才能以预期的方式完成任务。 它需要知道桌子上需要什么,可以在哪里找到对象,可以使用哪些对象(您不想在桌子上放脏的或破损的盘子),如何布置对象。 所有这一切都取决于要提供的餐食,无论是休闲的还是正式的,是为成人还是为小孩设置的地方,以及其他环境。
不仅需要知识来推断必须完成的工作,还需要知道如何完成工作。 机器人需要知道自己必须放置在什么位置才能成功拾取物体,要使用哪只手,要握住哪种握把类型,要在哪里放置手指,要施加多少抓握力,要施加多少升力, 此外,还介绍了如何有效地执行获取和放置任务,无论是双手使用,堆叠物品,使用托盘还是在摆放桌子的过程中打开橱柜门。 在图1中,我们说明了人类在虚拟环境中执行的任务,并在OPENEASE [5]中以可视化形式显示了查询的结果,该查询的结果显示了世界状态以及右手从抽屉向托盘移动勺子的轨迹。
尽管人类似乎甚至没有自觉地思考它们,但我们人类白天完成的大多数操纵任务都是非常密集的知识。 正如普拉特(Pratt)在他的文章中所说:“机器人将要发生寒武纪爆炸吗?” [6]:“机器人能力中尚未解决的关键问题是普遍性知识表示和基于该表示的认知。” 但是,必须先获取知识,然后才能对知识进行表示和推理。 这是一项特别棘手的任务,因为最迫切需要的知识类型是常识和幼稚的物理知识,这是所有人类在没有意识到的情况下拥有和应用的知识,并且他们经常难以制定。
现代技术,特别是游戏和虚拟现实,为我们提供了获取常识和天真物理学知识的新颖方法。 无需设计这些知识[7],[8],[9]或众包[10],[11],我们可以在需要常识性和幼稚物理推理的游戏中设置任务,使人们能够执行任务并为 然后从观察到的行为中挖掘知识。
在本文中,我们提出了AMEVA(日常活动的自动模型),这是一种可以自动进行人类日常操纵活动的专用知识获取,解释和处理系统。
- 创建和模拟虚拟人类的生活和工作环境(例如厨房和公寓),其范围,程度,细节水平和物理特性有助于并促进人类日常操纵活动的自然和现实执行;
- 从虚拟现实环境创建一个符号知识库,该知识库代表环境中的所有对象,它们的零件和关节模型。 这使得系统对环境无所不知。 知识库扩展了天体物理学,常识和有关对象的背景知识;
- 记录在各自的虚拟现实环境中执行的人类操纵活动及其对环境的影响,并检测力的动态状态和事件;
- 将记录的活动数据分解并分割为有意义的动作,并根据认知科学中使用的动作模型对动作进行分类;
- 使用链接到子符号数据流的一阶时间间隔逻辑公式在KNOWROB中象征性地解释所解释的活动;
我们将AMEVA应用于一般的取放任务(包括组织厨房,摆放和清洁桌子,装卸洗碗机)。 挑战包括访问游戏环境的相关数据结构,包括对象,对象的功能结构及其关节模型以及在环境的物理模拟中发生的力动态事件。
我们通过开放和基于网络的机器人知识服务OPENEASE [5]来收集,管理并公开访问活动事件的观察数据,模型和符号表示[5]。
本文的其余部分安排如下。 在以下两节中,我们描述AMEVA的功能视图和系统架构。 在第四节中,我们详细介绍了虚拟环境。 在第五部分中,我们介绍系统如何观察,记录和识别活动。 此后,我们在第六节中展示了我们收集的实验和结果。
2. AMEVA功能图
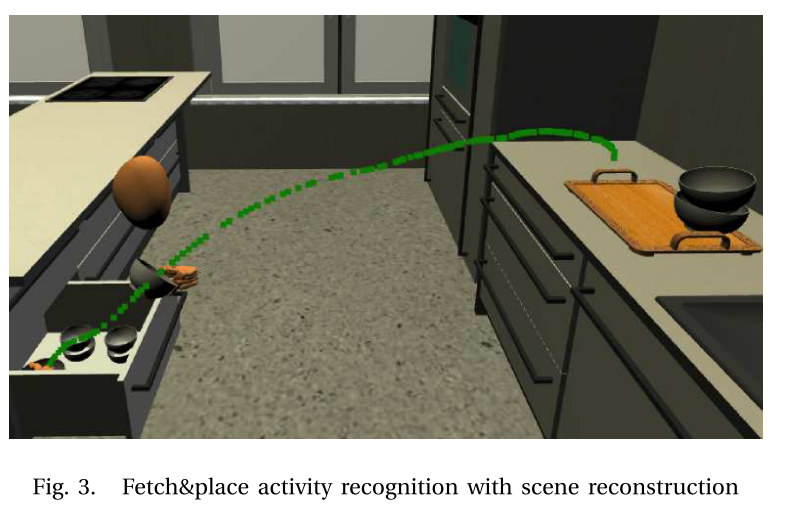
AMEVA的关键部分是在任务执行过程中自动识别动作和事件。 为此,我们使用了Flannagan等人提出的模型。 文献[12]指出,如图2所示,动作被构造为运动阶段,其中阶段具有关联的运动目标,该目标通常对应于力动态事件(控制设备中的显着事件)。 这些运动阶段具有知识前提,例如达到运动,预握姿势,目标姿势等。 通过从人的运动中提取规律性,我们可以得出运动约束和目标函数,用于基于约束的机器人控制。 图3显示了使用认知科学家提出的上述模型自动分段动作的示例。 它根据定义的阶段对数据进行分段,并可以自动提取所有知识前提,例如关键帧的掌握和预抓姿势,包括轨迹数据。
AMEVA的目的是增强机器人所具有的常识,以便能够回答诸如“桌面设置对象的布置方式”,“我在哪里可以找到桌面设置对象的问题”等问题。 学习运动约束,例如 装满杯子的杯子在运输过程中必须直立以避免溢出。 它不打算用于提取机器人特定的信息,因此不必配置虚拟世界来模仿机器人在现实世界中面临的不确定性。
3. AMEVA的系统架构
图4描绘了AMEVA的系统架构。创建了机器人工作环境的详细,逼真的虚拟模型。 在我们的案例中,对带有橱柜的厨房,带有铰接装置的电气设备以及物理过程模型(例如冰箱中的模拟冷冻过程)进行了建模。 该环境还配备有日常使用的物体,例如盘子,杯子,牛奶盒,刀,叉等。该环境具有集成的物理模拟,该模拟会导致物体掉落,被推动时移动以及与其他物体碰撞 。
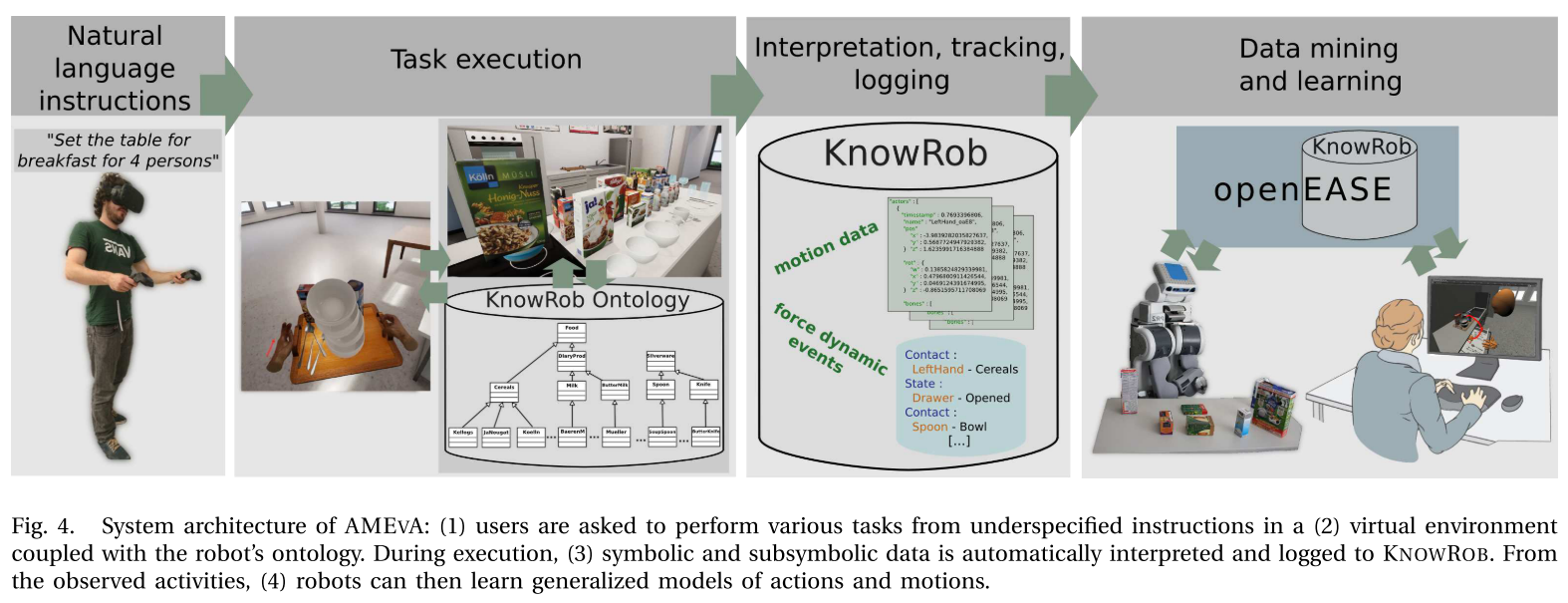
为了与虚拟世界互动,用户使用带有手部跟踪控制器的现成的虚拟现实耳机。然后,将跟踪到的耳机和游戏控制器的姿势映射到用户的虚拟头部和手上。使用基于力的PID控制器可以完成手部动作的映射,与典型的游戏环境相比,交互作用更为逼真。虚拟手已完全装配好(例如,每个手指骨骼都有碰撞,并受到关节的约束),并且与模拟世界中的所有实体发生碰撞,因此,用户对对象推/拉的“力度越大”,其越大。施加到它的力量。双手的闭合和张开是通过将手指施加到被致动的手指关节上来控制的。考虑到没有手指跟踪用户的手,这些力是从游戏控制器的模拟按钮映射的。由于仅在有限的情况下使用经过良好调整的物理引擎才能进行基于力的抓取,因此目前在实验中使用了基于固定的抓取模型。
然后,向用户指示特定任务,例如“为两个将要吃咖啡和谷类早餐的人设置桌子”。 然后,他/她将在虚拟环境中穿行到橱柜,打开橱柜以取出用于谷物的碗,然后从抽屉中取出勺子,从冰箱中获得牛奶盒。 最终,他/她将拿起咖啡杯,将其放在咖啡机下并装满。
虚拟环境中的所有对象都与KNOWROB的机器人本体结合在一起。 它们都属于本体中的相应类,因此,机器人可以通过在查询中包含有关对象的背景知识来提高其知识获取技能。 例如,它将知道虚拟世界中的特定牛奶是类别类型的牛奶,而牛奶又是一种乳制品,其性质是易腐烂的产品。 随后,它会发现冰箱是存放此类产品的合适场所。
用于在虚拟环境中观察人类规模的操纵任务的自然设置可用于获取人类为成功完成其任务而应用的各种常识和幼稚的物理知识。 例如,我们可以了解人类认为早餐吃咖啡和谷物所需的哪些物品,通常在哪里找到这些物品,如何在桌子上摆放这些物品,以及人类如何拿到,抓住或握住它们。 从这种自然的日常活动中提取常识和天真物理学知识的机会是多种多样的。
在任务执行期间:将虚拟世界中所有实体的位置和方向流式传输到数据库; 检测,解释和存储对象的状态及其物理相互作用。 在这种解释中,力动态事件的检测和分类特别重要[13],[14]。 例如,获取和放置对象会生成一系列力动态状态,其中手触摸要获取的对象,该对象失去与支撑表面的接触,然后在放置位置与支撑表面接触,接着是手 释放对象。 这些事件对于理解观察到的活动是必不可少的,因为它们可以表征和定义动作类别,从而可以将连续运动分割成有意义的运动阶段。
然后,AMEVA将运动数据流与时间同步的力动态事件一起使用,以生成分层的符号-亚符号活动表示。该表示的符号部分在一阶时间间隔逻辑[15]中陈述。在这种形式上,运动阶段(和动作)被表示为出现(mp,[t1,t2]),断言运动阶段mp发生在从时间点t1开始到时间点t2结束的时间间隔中。如果运动阶段是获取和放置动作的对象传递阶段,则将在t1发生失去与支撑表面接触的力动态事件,并在目的地将物体与支撑表面接触。通过从子符号数据流中检索相应的姿态数据,AMEVA可以在时间间隔[t1,t2]中检索对象和手的运动轨迹。因此,活动解释阶段的结果是一个知识库,它象征性地表示观察到的活动,并使用该符号部分来检索子符号数据,例如对象和身体部位的运动和姿势,如图1所示。
AMEVA活动观察和解释系统的最后一个组成部分是动作挖掘和机器学习。 该组件的目的是学习动作和运动的通用模型,机器人可以使用这些模型来填补由指令不足导致的知识空白。 例如,机器人可以学习搬运装有物质的敞开容器的运动约束。
在本文的其余部分,我们将更详细地描述和讨论AMEVA系统的组件。
4. 环境
从虚拟现实演示中获取高质量动作和运动数据的重要因素是,执行活动的人给人的印象是虚拟现实环境看起来像逼真的照片,关节模型表现得逼真,并且手操作直观且轻松 。
图5显示了环境模型的详细程度。 所描绘的冰箱是通过详细的CAD模型建模的,该模型包括分层的对象部件模型以及冰箱门的实际铰接模型。 此外,以冰箱灯泡的形式存在的动态灯可确保冰箱内的照明条件真实。

除了设备和家具的模型之外,虚拟厨房环境还包括日常对象的真实模型,包括杯子,碗,勺子,叉子,刀,谷物盒等。 这些对象模型使我们可以创建非常现实的场景。 例如,我们可以将所有日常使用的物品放在厨房的柜台上,并要求人们将它们放在其所属的物品上,以了解人们如何组织厨房的原理。
A. 虚拟现实环境作为知识库
除了通过照相机或其他观察手段观察真实人类动作以外,在虚拟现实环境中设定观察和解释人类活动的方法是两个关键优势。 首先是在虚拟环境中,活动解释算法可以访问模拟过程和数据结构。 因此,该算法具有关于物体状态和姿态以及力动态状态和事件的地面真相数据,从而使活动解释更加容易,更加准确和完全自动化。 其次,我们可以使用虚拟环境的数据结构来自动创建一个符号知识库,其中包含有关环境中对象的所有相关背景知识。 了解对象的目的和功能,可以支持对观察到的活动的解释和概括,以及对广义动作和运动模型的学习。
创建新的AMEVA环境时,所有现有实体类型(家具,器皿等)都需要使用KNOWROB本体中的相应类类型进行标记。 如果是这种情况,还将添加发音属性或部分关系。 在执行此手动步骤之后,系统会自动为每个实体分配持久性唯一标识符,并创建环境的语义表示。 这将确保即使将来远程执行或在多台PC上执行,所有将来的情节也将共同链接到相同的表示形式。 这使得生成的知识库可以随着新数据而不断增加。
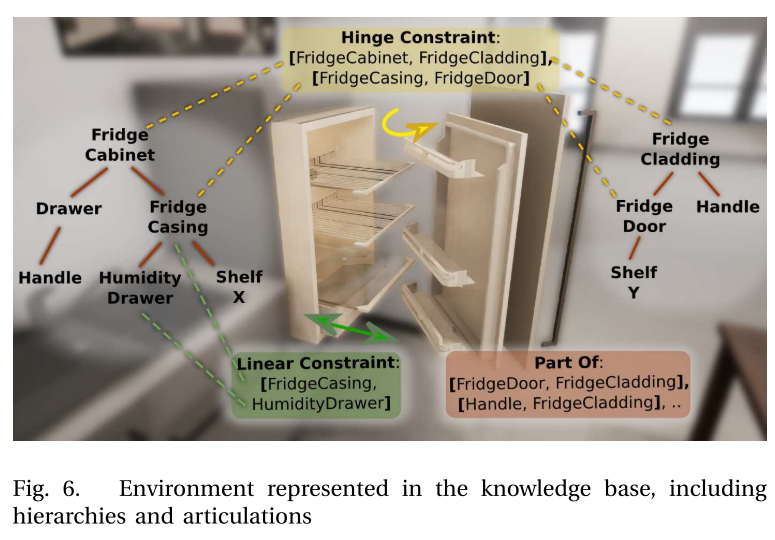
图6显示了环境知识基础中的表示细节,包括父子层次结构和关节。 我们以类似于语义机器人描述语言的方式表示层次结构[16]。 对于图中示例性的冰箱壁板,我们具有:门板和底座之间的铰链连接; 底部抽屉和底座之间的线性连接; 手柄和面板之间的固定装置,以及抽屉之间的固定装置。 执行期间,流利的语言(例如,对象(或关节)的张开角度和姿势)将自动更新并记录为它们当前对应的状态(“打开”,“关闭”,“半打开”等)。
5. 活动观察
A. 情节表示
在任务执行期间,AMEVA会跟踪虚拟世界中每个对象及其相关部分的姿势以及门,抽屉,旋钮等的状态。所有跟踪结果都将自动优化(过滤出冗余数据)并登录 NoSQL数据库。
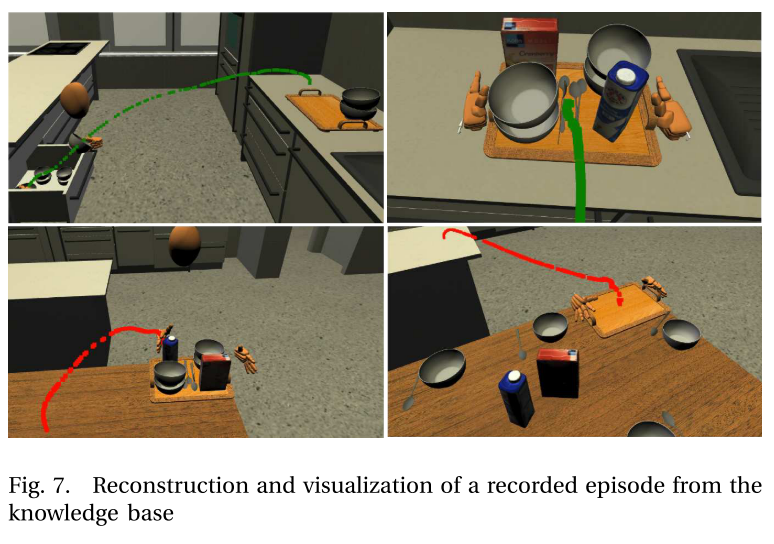
在虚拟环境中的每次执行之后,可以在OPENEASE中加载和可视化生成的符号下符号活动表示数据以及知识库。 图7描绘了来自已记录情节的各种关键事件下虚拟世界的重建。 在这种情况下,为用户提供了任务,因此将桌面设置为4人早餐。 还指示他使用托盘以优化其操作。 生成的图像说明了提取和放置动作的开始,并突出了动作期间抓取的对象的轨迹:从抽屉抓取碗并将其放在托盘上; 抓住托盘并将其放在桌子上; 将托盘上的牛奶放在桌子上,然后将托盘带回厨房岛。
B. 识别力的动态状态和事件
我们建议将动作识别基于实体之间的力相互作用模式。 例如,我们可以通过一系列力动态状态和事件来表征取放动作。 对于获取和放置,此顺序是(1)要获取的物体由支撑表面支撑,(2)接触物体的手,(3)附着在手上的物体,(4)不再接触物体的手, 物体被目的地的支撑面所保持。 在图2中从第二部分可以看到这种模式。
我们的假设是,不同的动作可以通过它们在物体和身体部位(尤其是手)上的动力相互作用的各自不同的模式来表征。 Talmy在语言学中提出了这种观点,他认为单词的含义可以根据力的动力学进行有效的语义分类,后来被人工智能的动作识别和建模所采用[13]。
动作的力动态表征对于虚拟环境中的动作识别过程非常重要的原因是,通过监视虚拟现实环境下的物理模拟,可以轻松,可靠且准确地检测到力动态状态和事件。 通过计算活动情节期间所有相关力动态状态和事件的顺序,解释算法可以轻松识别动作并将其分割为相关运动阶段。
在图8中,我们通过比较执行的动作中的各个关键帧,可以识别出牛奶从冰箱中取出的事件。 图像上的彩色时间线表示情节中自动记录的事件。 我们可以看到,当手与门把手接触时,冰箱门的状态发生了变化。 抓住牛奶容器后,它不再与冰箱的底部搁板接触,并且最终在桌子上。 但是,在下桌子之前,我们可以观察到徒手再次与门把手接触,并且门的状态变为关闭状态。
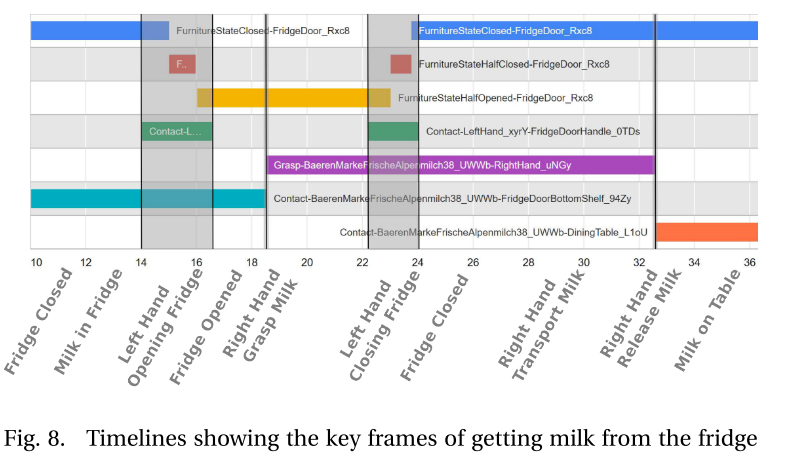
6. 实验
为了展示AMEVA的功能,我们收集了27集,其中给用户的任务是为各种不同的早餐场景设置桌子:
- 吃饭的人数(1,2,4)
- 并用一只手,两只手,两只手和一个托盘
被赋予与机器人相同或相似的任务,这可以用来优化他在任务执行过程中的步骤。
在表I中,我们描述了在正确执行的情节中检查持续时间和行进距离的查询结果。 查询的创建方式与我们先前的工作[17]中描述的方式类似。 从结果中我们可以注意到:在时间上,只有要服务的人数至少为4(或者,要操纵/搬运的物品数量大于托盘的数量)时,才开始使用托盘来搬运物品才有用。 一种用于该特定场景); 按距离行进,使用托盘是最有利的; 在这两种情况下,仅用一只手执行任务都是明显的缺点;
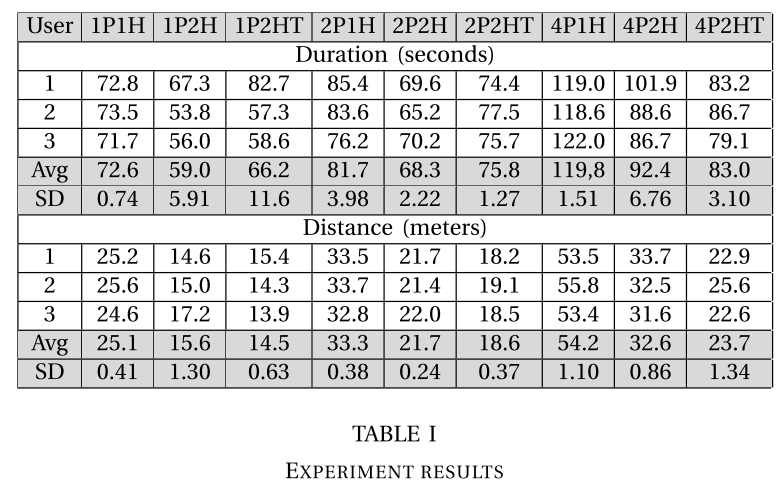
现在假设机器人已经具备执行此任务所需的技能和能力(抓握物体,打开抽屉,搬运物品等)的先验知识,现在可以使用此信息为自己的情况重新映射结果。 例如,如果机器人抓取物体的速度很慢,但是导航/移动没有任何问题,那么使用托盘最有可能没有优势,因为它总是包含额外的操作动作。
7.相关工作
与我们的方法类似,在[18]中,Bates等人将虚拟现实环境用作收集有关人类行为的语义信息的可行方法。 他们建立了一个框架,能够实时提取和推理语义数据。 系统会对用户的已知动作进行连续的细分和语义分类,同时能够按需学习新颖的动作。 从对用户的持续观察中,系统以所有相关活动的图表的形式提取用户使用的任务空间。 他们还使用KNOWROB本体存储有关虚拟世界中对象的分类和初始知识。 以类似的方式,将虚拟对象标记为它们在本体中的对应类。 本文的重点是无需事先培训即可识别和学习复杂虚拟环境中的新活动。
在[19]中,Fang等人使用虚拟环境来学习各种执行方式下浇注的物理效果。 他们提出的框架可以在变化的条件下,在交互式仿真环境中从幼稚的用户演示中获取并应用动作知识。 作者认为,通过从人类用户那里收集数据,而不是从大量自动生成的模拟中收集数据,他们可以忽略很大一部分可能的运动空间。 事先使用这些数据,可以大大减少学习控制器参数的计算时间。 他们认为,使用人类示范将有助于构建一个能够学习日常操纵技能的通用框架。
8. 总结和未来的工作
在本文中,我们介绍了AMEVA(日常活动的自动模型),这是一种专用的知识获取,解释和处理框架。 该框架使用基于物理的,接近光影的虚拟环境来促进人类日常活动的自然和现实执行。 在执行期间,将执行的操纵活动及其对环境的影响与检测到的力动态状态和事件一起记录下来。 然后将记录的活动分解并细分为有意义的动作。
为了展示该框架的功能,我们收集了27集,其中给用户的任务是为早餐场景设置桌子,服务对象的人数各不相同,并且使用的手和工具的数量受到限制。 所有收集的知识都在KNOWROB中以符号表示,并在基于Web的知识服务OPENEASE中可用。
在未来的研究中,我们计划将动作观察基础结构扩展到准备饭菜的任务:我们考虑特定的动作动词,包括擦,剪,倒,并学习如何针对不同的对象,使用不同的工具以及针对不同的目的执行相应的动作。 在当前的实施状态下,日常使用的对象尚未完全建模。 我们的议程是进一步详细说明模型,以便牛奶纸箱具有带打开机构的盖子,并且容器中装有虚拟牛奶。 通过这些日常使用对象的深入模型,我们打算实现日常操作任务的高性能学习。
我们正在努力引入基于物理(力)的抓取模型,使用户可以在运行时在各种定义的样式之间进行更改,从而最终将抓取样式映射到特定的对象和场景。
我们正在推进使用物理动作的全身跟踪系统(图9)的集成。 这将导致更自然的运动,因为从物理上避免了运动上不可能的情况,例如,双臂交叉,换手,漂浮在物体上方等。 计划将这些动作语义上映射到知识库中表示的完全表达的人类模型。

