论文阅读:Robot Learning from Demonstration in Robotic Assembly: A Survey
Robot Learning from Demonstration in Robotic Assembly: A Survey
Zuyuan Zhu Huosheng Hu
0.摘要
从演示中学习(LfD)已被用来帮助机器人自主地执行操纵任务,特别是通过观察人类演示者执行的动作来学习操纵行为。 本文回顾了LfD领域的最新研究和发展。 主要重点放在如何向机器人演示装配操作中的示例行为,以及如何提取用于机器人学习和生成模仿行为的操纵特征。 分析各种指标以评估机器人模仿学习的性能。 具体而言,LfD在机器人装配中的应用是本文的重点。
关键词:从示范中学习; 模仿学习 ;机器人组装; 机器学习
1.介绍
1.1机器人装配
当前部署在装配线上的工业机器人具有位置控制和编程功能,可以按照所需的轨迹执行装配任务[1,2]。 这些位置控制的机器人可以很好地处理结构良好的装配线中的已知对象,从而实现高度精确的位置和速度控制。 但是,它们无法处理装配操作中的任何意外更改,并且需要繁琐的重新编程以适应新的装配任务。
例如,Knepper等。 研究了用于家具装配的多机器人协调装配系统[3]。 表格中列出了单个零件的几何形状,以便一组机器人可以协作进行零件交付或零件组装。 为了对家具零件进行建模和识别,已在CAD文件中预定义了对象的表示形式,以便可以从几何数据中推导出正确的组装顺序。 Suárez-Ruiz和Pham提出了一种用于双手插销的操作原语的分类法,这只是宜家椅子自主组装的关键步骤之一[4]。
通常,典型的机器人组装操作涉及对两个或多个对象/零件的操作。 每个零件都是装配的子集。 组装的目的是计算将单个零件组合在一起的操作顺序,以便出现新产品。 组装任务的示例可以在下面总结。
钉入孔,即,机械手会抓住钉子并将其插入孔中。 钉入孔是已被广泛研究的最重要和最具代表性的组装任务[5-14]。
在槽中滑动,即机器人将螺栓配件插入凹槽内,然后将螺栓滑动到要固定螺栓的所需位置[15]。
螺栓拧紧,即机器人将自攻螺栓拧入未知特性的材料中,这需要将自攻螺钉拧入非结构化环境中[15-17]。
椅子组件,即机器人将椅子部件与紧固件集成在一起[18,19]。
拾取和放置,即,机器人拾取一个对象作为基础并将其放到固定装置上[17,20,21]。
管道连接,即机器人拾取两个管接头螺母并将其放置在管上[17]。
由于典型的机器人组装操作需要接触待组装的工件,因此除了位置和方向轨迹之外,估算伴随的力-扭矩曲线至关重要。 为了学习装配操作的执行,机器人需要首先估计工件的姿态,然后通过从人类演示中学习来生成装配顺序。 对于出现在装配工作区中的某些特定对象,应设计一些专门的抓取器来抓取具有各种形状的这些零件并获取力-扭矩数据。 特别地,在拧紧任务期间,待拧紧的材料是非结构化的,这使得旋转角度的控制更加复杂。
考虑到这些挑战,机器人组装仍然是机器人研究领域中最具挑战性的问题之一,特别是在非结构化环境中。 相反,人类具有出色的技能来执行需要顺从性和力量控制的装配任务。 这促使我们回顾机器人组装中的示范学习(LfD)的当前研究及其潜在的未来方向。
1.2从示范中学习
传统的机器人要求用户具有编程技能,这使机器人超出了普通大众的承受范围。 如今,机器人技术研究人员已经研究了新一代机器人,这些机器人可以从演示中学习,而无需编程。 换句话说,这些新型机器人可以使用其传感器感知人类的动作,并再现与人类相同的动作。 完全没有编程技能的普通大众都可以使用它们。
Bakker和Kuniyoshi对“从演示中学习(LfD)”或“模仿学习”这一术语进行了深入分析,他们定义了什么是模仿以及应该是什么机器人模仿。 从心理学的角度来看,桑代克将模仿定义为学会做被见证的行为[22]。 基于此,Bakker指出,当代理人通过观察老师对行为的执行来学习行为时,就会进行模仿[23]。 这是建立机器人模仿特征的起点:(i)适应; (ii)老师与学习者之间的有效沟通; (iii)与其他学习算法的兼容性; (iv)在代理商社会中有效学习[24]。
此外,还确定了模仿机器人的三个过程,即感知,理解和执行。 换句话说,可以将它们重新定义为:观察动作,表示动作并重现该动作。 图1显示了这三个主要问题以及机器人模仿中的所有相关当前挑战。
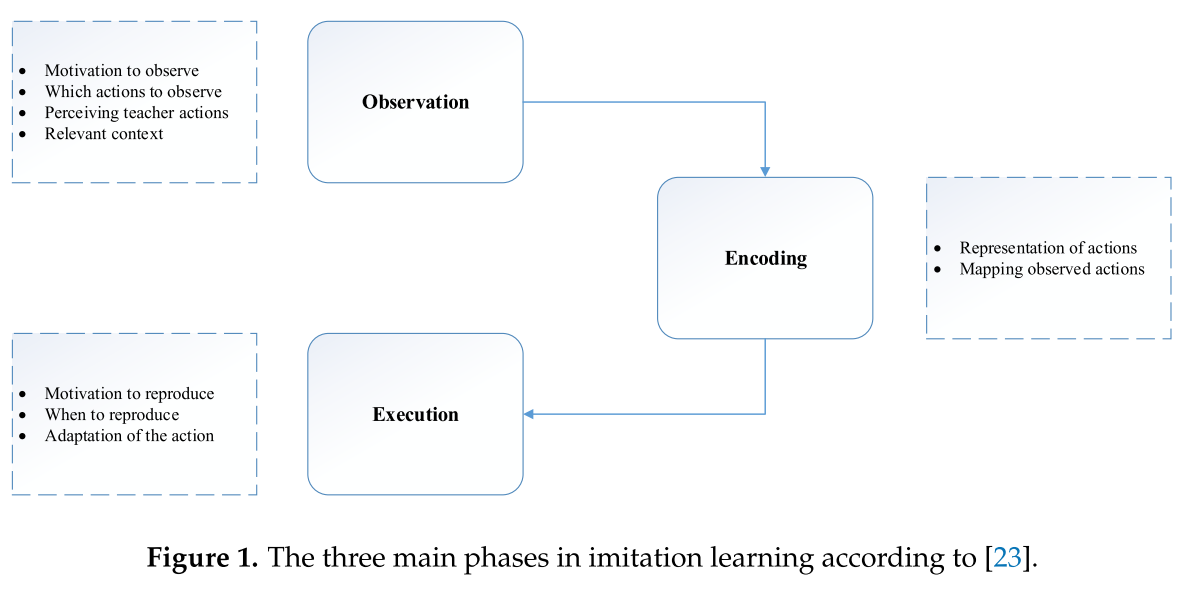
Mataric等。 从生物学的角度定义模仿学习,即基于行为的控制[25]。 他们指出,关键的挑战是如何解释和理解观察到的行为,以及如何整合感知和运动控制系统以重建观察到的内容。 换句话说,模仿学习有两个基本任务:(i)从视觉输入中识别人类行为; (ii)寻找构造运动控制系统以实现一般动作和模仿学习能力的方法。
当前代表技能的方法可以大致分为两个趋势:(i)轨迹编码-技能的低级表示,采用感觉和运动信息之间的非线性映射的形式; (ii)符号编码-一种技能的高级表示,以一系列动作-感知单位分解该技能[26]。 总的来说,要从演示中学习机器人,我们需要解决三个挑战:对应性问题,泛化性和抗干扰的鲁棒性[27]。 首先,对应问题意味着如何将人与人之间的链接和关节映射到机器人。 其次,只有在可以概括所演示的动作(例如不同的目标位置)的情况下,通过演示进行学习才是可行的。 最后,我们需要强大的抗干扰能力:在动态环境中准确重播观察到的运动是不现实的,在动态环境中障碍物可能会突然出现。
大多数装配任务可以表示为具有特定目标的单个运动序列,可以将其建模为动态运动原语(DMP,在4.2节中进行了说明),其中DMP是LfD体系结构的基本模块。 另外,最近已经提出LfD作为一种有效的方法,可以加快从低级控制到高级装配计划的学习过程编程[28]。 因此,LfD是机器人组装的首选方法。
最近,LfD已经应用于机器人组装[29-31]。 高松等。 在机器人装配中引入了LfD,并提出了一种通过人工演示识别装配任务的方法[32]。 他们定义了足够的子技能和关键的过渡组装任务,并在具有实时立体视觉系统的双臂机器人上实现了钉钉任务。 组装任务是通过两个常规的6自由度(自由度)对象跟踪系统识别的刚性多面体对象完成的。 组装任务被封装为两个对象关系的链,例如维护,分离和约束。 为了使组装任务的过程顺利进行,还定义了关键的过渡。
组装任务中的人机协作降低了阻抗控制的复杂性。 朝着多模态LfD框架迈进了一步,在该框架中,机器人提取了教师的基于阻抗的行为,在协作表组装任务中同时记录了力模式和视觉信息[33]。 应该注意的是,实验并未考虑到机器人的独立性和自主性。 对于装配任务的建模,Dantam等人。 将人类的示威活动转化为一系列语义相关的对象连接运动[34]。 然后,将运动序列进一步抽象为运动语法,它代表了演示的任务。 应当注意,组装任务是在仿真中实现的。
1.3
与先前的演示学习调查不同[35],本文主要关注LfD技术在机器人装配中的应用。 本文的其余部分安排如下。 第2节概述了机器人组装中的主要研究问题,将其分为四类。 在第3节中说明了如何向机器人演示装配任务的关键问题,在第4节中说明了如何抽象装配任务的特征。然后,我们研究了如何评估模仿器性能的问题。 在第5节中。最后,在第6节中对LfD和机器人组装中的开放研究领域进行了简短的总结和讨论。
2.机器人装配中的研究问题
机器人装配需要高度的可重复性,灵活性和可靠性,以提高装配线的自动化性能。 因此,必须解决许多特定的研究问题,以便在非结构化环境中实现自动化的机器人组装。 机器人软件应该能够将组装任务的顺序转换为单独的动作,估计组装零件的姿态并计算所需的力和扭矩。 由于机器人组装面临许多挑战,因此本节将重点介绍与LfD密切相关的四个类别:姿态估计,力估计,组装顺序和带螺丝的组装。
2.1姿态估计
在装配线中,经常必须以高精度预先确定定工件的位置和方向。 基于视觉的姿势估计是一种基于点云数据[5]来确定装配零件的位置和方向的低成本解决方案。 纹理投影仪还可用于获取高密度点云并帮助进行立体匹配过程。 Abu-Dakka等。 使用3D相机Kinect捕获3D场景数据,并且可以基于点云数据估算已知对象的姿态[11]。
在姿势估计之前,应该通过使用局部特征来识别对象,因为这是匹配的有效方法[36]。 崔等。 开发了一系列姿势估计算法,该算法使用具有方向的边界点和边界线段以及定向的表面点来为各种工业零件提供高精度[37]。 但是,在杂乱无章的环境中,目标物体会被自身遮挡和传感器发出噪音,装配机器人需要强大的视觉才能可靠地识别和定位物体。 Zeng等。 使用全卷积神经网络对场景的多个视图进行分割和标记,然后将预定义的3D对象模型拟合到分割中以获得6D对象姿势而不是3D位置[38]。
然而,由于视觉系统的分辨率有限,因此基于视觉的姿态估计具有局限性。 另外,在孔中钉作业中,当机器人接近孔时,钉通常会堵塞孔。 因此,基于视觉的姿势估计不适用于两个零件相互遮挡的高精度装配任务。 如果将摄像机安装在机械臂上,则可以消除遮挡问题,但是需要额外的感官数据才能估计摄像机的姿势[39]。
为了纠正装配零件的姿势,Xiao等人。 设计了一个名义上的组装运动序列来从探索性投诉运动中收集数据[40]。 然后,该数据将用于更新后续的装配顺序,以纠正名义装配操作中的错误。 然而,在将来的研究中应该进一步解决被操纵物体的姿态的不确定性。
2.2 力估计
在组装任务中,力控制可以在机械手和工件之间提供稳定的接触[5-7,30,41-45]。 当人类操作员在组装过程中执行顺应性运动时,机器人应获得在组装过程中出现的接触力。 在任务执行过程中,机器人将学习复制学习到的力和扭矩,而不是从轨迹复制位置和方向。 力信息还可用于加快装配任务的后续操作[8,9,12–15,46]。
通常使用机器人末端执行器上的力传感器或机器人手臂各关节上的力传感器(例如DLR(德国航空航天中心)的轻型手臂)来检测施加到工件上的力。 使用内部力传感器的问题是,在使用之前必须补偿测得的力以消除干扰力(例如重力和摩擦力)。 然后将反馈力引入到控制系统,该控制系统在机器人操纵器上生成相应的平移/旋转速度命令,以推动被操纵的工件。
为了使机器人能够以不同的刚度进行交互,Peternel等人。 使用阻抗控制界面来教它一些组装任务[47]。 老师通过触觉和阻抗控制界面控制了机器人。 机器人被教导学习如何执行“槽中滑动”组装任务,在该任务中,机器人将装有螺栓的零件插入到另一零件中。 但是,在某些装配任务(例如,槽中滑动任务)中,低运动变异性不一定与高阻抗力相对应。
专用的扭矩传感器可以轻松获取力,但可能无法轻松地将其安装到机器人手上。 另外,Wahrburg等。 部署电机信号和关节角度以重建外力[42]。 应当注意,力/扭矩估计不是问题,并且在结构化环境中的传统机器人组装中已经成功。 然而,对于非结构化环境中的机器人组装而言,这是一个问题。 力/扭矩估计不仅涉及获取力/扭矩数据,而且还涉及将这些数据用于机器人以适应其与不同刚度的相互作用。
2.3 组装顺序
由于适当的组装顺序有助于最大程度地降低组装成本,因此在传统的机器人组装系统中手动定义了组装顺序。 然而,[44]中定义的详细组装顺序极大地阻碍了下一代组装线的自动化。 为了实现任务的有效组装顺序,需要使用优化算法来找到最佳计划。 Bahubalendruni等。 发现汇编谓词(即某些约束集)对最佳汇编序列生成有重要影响[48]。
Wan和Harada提出了一个集成的装配和运动计划系统,以水平表面作为支撑夹具[20]来搜索装配顺序。 Kramberger等。 提出了两种新颖的算法,它们学习了优先约束和相对零件尺寸约束[8]。 第一种算法使用优先约束来生成以前看不见的装配序列,并通过向人类示范学习来保证装配序列的可行性。 第二种算法学习了如何通过探索性执行来配合零件,即通过探索学习。
从演示中学习组装顺序可以针对一般组装任务进行定制[5,8,21,30,31,49]。 Mollard等。 提出了一种从演示中学习的方法,以自动检测对象对之间的约束,分解演示的子任务,并学习分层组装任务[19]。 此外,通过交替的校正和执行进一步完善了学习序列。 应该注意的是,定义装配顺序的挑战是如何根据操纵的工件自动提取运动原语并生成可行的装配顺序。
2.4 用螺丝组装
拧紧是装配中最具挑战性的子任务之一,它需要强大的力控制,以便机器人可以将自攻螺栓拧入未知特性的材料中。 自攻螺钉驱动任务包括两个主要步骤。 第一步是将螺丝刀插入螺栓的头部。 接触刚度保持在恒定值,这样螺丝起子就可以持续接触螺栓的头部。 第二步是将螺丝刀安装到螺丝头中,并旋转一定角度以将螺栓驱动到非结构化材料中。
为了测量驱动螺丝刀所需的比力和角度,Peternel等人。 首先使用人类示威者旋转螺丝刀,然后使用Haptic Master万向接头装置捕获对应角度。 然后将信息映射到机器人的末端执行器旋转[15]。 应当注意的是,用于补偿旋转刚度的扭矩是未知的,因此演示者可通过刚度控制手动命令高旋转刚度,以使机器人准确跟随所演示的旋转。
拧紧任务中存在很大的不确定性,例如螺丝刀可能无法正确抓住螺栓的头部。 实际上,随着任务复杂性的提高,执行错误的任务变得越来越普遍。 除了防止错误发生外,Laursen等人。 提出了一种通过自动反向执行到安全状态来自动处理某些类别的错误的系统,从该位置可以恢复向前执行[16]。 如图1所示,在LfD的执行阶段,装配动作的适应性至关重要。此外,机器人装配中不确定性的适应性仍需要进一步研究。
总之,姿势估计,力估计,组装顺序和带螺钉的组装在有限的条件下已得到部分解决,但仍与工业应用相距甚远。 当前大多数装配系统都在相对简单的任务中进行了测试,例如孔内钉。 另外,需要一种更鲁棒和有效的控制策略来处理非构造环境中的复杂装配任务。
3.演示方法
从演示中学习机器人需要获取示例轨迹,这些轨迹可以通过各种方式捕获。 替代地,机器人可以由其操作员物理地引导通过期望的轨迹,并且所学习的轨迹被本体地记录以用于演示。 这种方法要求机器人可以向后驱动[50,51]或可以补偿外力的影响[52-54]。 在以下小节中,我们将讨论利用这些演示技术的各种工作。
3.1 动觉示范
动觉引导的优点是,运动直接记录在学习机器人上,不需要先从具有不同运动学和动力学的系统中转移。 在演示运动中,机器人的手由一名示威者引导[55-57]。 应该注意的是,运动学教学可能会影响获得的力和扭矩,尤其是在使用联合力传感器估算力和扭矩以控制实际机器人上的组装任务时。 另外,如果被操纵的物体很大,相距很远或有危险要处理,则运动引导可能会出现问题。
图2显示,机器人在重力补偿模式下通过动觉教学,即示威者在完成任务的每个步骤中移动了其手臂。 为此,将机器人电机设置为被动模式,以便演示人员可以移动每个肢体。 在演示过程中,每个关节运动的运动学都通过本体感受被记录下来。 机器人为每个自由度都提供了电机编码器。 通过移动肢体,机器人通过记录由电机编码器提供的关节角度数据来“感知”其自身的运动。 与使用图形仿真相比,与机器人的交互更加有趣,这使用户可以隐式感受到机器人在其实际环境中的局限性。
在[58]中,通过运动学演示向机器人提供了示例任务,其中老师以零重力模式物理移动了机器人的手臂来执行任务,并使用袖带上的按钮设置抓手的闭合。通过按下手臂上的按钮,录音开始了,老师开始移动同一只手臂进行操作。操作完成后,老师再次按下按钮以暂停录制。老师简单地重复了步骤,用另一只手和录音继续进行操作。演示过程中记录了手臂激活信号和机械手的状态,将工具的使用过程分为顺序的操作原语。通过使用起始姿势,被致动的末端执行器的结束姿势以及姿势序列来表征每个图元。通过DMP框架学习原语。这些原语和原语的排序构成了工具使用的模型。
3.2运动传感器演示
示威者的肢体动作非常复杂且难以捕获。计算机视觉可能会以较低的准确度捕获示威者的运动[59]。 相比之下,基于光学或磁性标记的跟踪系统可以实现高精度,并避免计算机视觉的视觉重叠[60-63]。 因此,部署了基于标记的跟踪设备来跟踪人类示威者用于组装任务的操纵运动。
Skoglund等。 提出了一种基于学习模型的基于模糊建模和下一个状态规划器的模仿学习方法[64]。 脉冲运动捕获系统使用了一个手套,该手套的背面有LED,每个指尖上都有一些触觉传感器。 LED用于计算手腕的方向,而触觉传感器则用于检测与物体的接触。 或者,可以使用运动传感器代替LED进行跟踪。
彩色标记是一种用于运动传感器演示的简单有效的运动跟踪技术。 Acosta-Calderon和Hu提出了一种机器人模仿系统,在该系统中,机器人模仿者观察到了一个演示者进行手臂运动[65]。 通过颜色跟踪系统提取并跟踪人类演示器上的颜色标记。 然后,将获得的信息用于解决上一节中所述的对应问题。 用于实现此对应关系的参考点是演示者的肩膀,该肩膀对应于机械臂的底部。
为了利用全身运动数据捕获人类运动,在运动捕获设置中总共使用了34个标记[66]。 在数据收集过程中,获得了一系列连续的运动数据,例如各种人类的步行运动,下蹲运动,踢腿运动和抬高手臂的运动。 一些运动是离散的,另一些是连续的。 因此,学习系统应自动分割运动。 在[67]中研究了人体运动模式的分割。 人们还观察了运动序列,对其进行了手动分割,然后标记了这些运动。 请注意,将由人类分割的运动设置为地面真值,并且未使用其他标准。
在图3中,安装在手套中的运动传感器用于跟踪相对于发射器的6D姿势(位置和方向); 然后,机器人将以1:1的运动比例接收变换后的姿势。 钉孔实验表明,与远程操作过程中使用外部设备相比,数据手套的效率较低。 在图4中,手势和接触力都是通过触觉手套来测量的。 在机器人组装中,力传感器是必不可少的,因为该任务需要精确控制力。 因此,通常将运动传感器和力传感器组合在一起。
3.3 遥控演示
在遥控演示过程中,操作员使用控制箱或提示以控制机器人执行组装任务,并且机器人不断记录来自其自己的传感器的数据,请参见图5。 机械手直接记录在机械手上,即映射是直接的,不存在相应的问题。 从遥控演示中学习是控制复杂机器人的一种有吸引力的方法。
远程操作的优势在于可以在人与机器人之间建立有效的通信和操作策略。 它已被应用到各种应用中,包括远程控制移动机器人助手[70-72],执行组装任务[68,73,74],执行空间定位任务[75],向机器人展示预握形状 [76],传送有关协作任务的动态和交流信息[77],以及挑选和移动任务[78]。
在组装任务中,当演示者执行组装动作时,姿势信息将被馈入实时跟踪系统,以便机器人可以复制演示者的动作[13]。 Robonaut是NASA的太空人形机器人,由人类通过全浸入式遥控操作来控制[79]。 它的立体声摄像头和声音传感器通过戴在他或她头上的头盔将影像和听觉信息传输到遥控操作员。 尽管全浸入式遥控操作对于Robonaut是一个不错的策略,但其灵巧的控制却非常繁琐和累人。
在远程操作过程中,操作员通常会通过远离机器人站立的控制器来操纵机器人。 在图6中,人类教机器人执行凹槽中的滑动任务,如第二列所示,然后机器人自主重复学习的技能,如第三列所示。 对于螺栓拧紧任务,如右图所示,在演示后,DMP用于编码轨迹。 有时,控制器可以是机器人本身的一部分。 Tanwani等。 在机器人学习过程中应用远程操作,要求机器人执行打开/关闭阀并拾取对象的任务[80]。 操作员握住机器人的左臂并控制其右臂,以从安装在右臂末端的摄像机接收视觉反馈。 在远程演示中,机器人的左臂扮演控制器的角色,右臂充当效应器。
向机器人传递提示是远程操作的另一种方式。 人工操作人员通过多次重复所需的任务或指出技能的重要要素,可以向机器人提供提示。 提示可以通过整个学习过程以各种方式解决。 提示之一是语音指法,即操作员的指令。
Pardowitz等。 在演示任务以加速机器人学习的过程中,使用了演示者的语音注释[81]。 语音说明已集成到权重函数中,权重函数确定了操纵段中包含的特征的相关性。
一般而言,语音声学包括三个主要的位信息:说话人的身份,语音的语言内容和讲话方式。 Breazeal等人没有专注于语音信息的语言内容。 提出了一种方法来教机器人如何理解说话者的情感交流意图[82]。 在LfD范式中,通过HRI(人机交互)了解人类演示者的意图是机器人学习的关键点。 演示是针对目标的,希望机器人能够理解人类的意图并提取所演示示例的目标[83]。
声音或视觉模式可用于拟人化机器人[84]。 从运动匹配[85,86]和关节运动复制[27,56,87-92]的角度转移了对人类意图的理解。 最近的研究工作认为,即使示例没有得到很好的证明,机器人也需要理解人类作为社会认知学习者的意图[93-95]。 但是,为了跟踪完成预期目标的意图,模仿机器人需要一种学习方法。 解决方案可能是建立人类教师的认知模型[96,97],或使用视角模拟[98]。
4.特征提取
当使用上述演示方法收集了演示轨迹的数据集(即状态动作示例)时,我们需要考虑如何将这些数据映射到数学模型中。 沿演示轨迹分布的位置数据点数以千计,无需记录每个点,因为运动轨迹很难重复。 此外,由于视觉系统的精确度有限以及抓握姿势的不确定性,直接复制所显示的轨迹可能会导致性能不佳。 因此,学习提取和概括装配运动关键特征的策略是LfD的基本部分。
隐马尔可夫模型(HMM)是一种流行的方法,可以对示例进行编码和泛化[99-114]。 HMM是一种通过大量演示来封装人类运动的鲁棒概率方法,该运动包含时空变量[115]。 最初,HMM的训练是脱机学习的,并且在学习之前将样本数据手动分类为组。 为了使HMM联机,Kulic等人。 开发了自适应隐马尔可夫链,用于增量和自主学习运动模式,并将其提取到动态随机模型中。
概率方法也可以与其他方法集成,以通过模仿来学习健壮的人体运动模型。 Calinon等。 将HMM与高斯混合回归(GMR)和动力学系统结合起来,从一组示例中提取冗余[112]。 原始HMM依赖于固定数量的隐藏状态,并且在分割连续运动时将观察模型建模为独立状态。 为了解决HMM的两个主要缺陷,Niekum等人。 提出了β过程自回归隐马尔可夫模型,在该模型中所有模型都易于共享[114]。
Chernova和Veloso基于高斯混合模型(GMM),提出了一种交互式策略学习策略,该策略通过允许代理主动请求并有效表示最相关的训练数据来减小训练集的大小[116]。 Calinon等。 通过估计最佳GMM对运动示例进行编码,然后通过GMR概括轨迹[56]。 Tanwani和Calinon通过在共享相似协调模式的任务的各个部分重用协同作用,扩展了半绑定的GMM,以实现可靠的学习和对机器人操纵任务的适应性[80]。
动态运动原语(DMP)代表了一种基于非线性动力学系统的根本不同的运动表示方法。 DMP对空间扰动具有鲁棒性,适合遵循特定的运动路径。 Calinon等。 [112]使用DMP再现最平稳的运动,并且学习过程比HMM,TGMR(时间相关的高斯混合回归),LWR(局部加权回归)和LWPR(局部加权投影回归)更快。 Li和Fritz [58]通过添加定义运动形状的功能扩展了原始DMP公式,它可以通过调整相应的目标参数使运动更好地适应新的目标位置。 乌德等。 [92]利用可用的训练动作和任务目标使DMPs推广到新的情况,并能够产生经证实的周期性轨迹。
5.模仿性能得评价
确定模仿性能的指标是评估LfD的关键因素。在执行阶段(参见图1),度量标准是机器人进行复制的动机。一旦设置了度量,就可以通过最小化该度量来找到最佳控制器(例如,通过评估几次繁殖尝试或通过推导度量以找到最佳值)。模仿量度发挥成本函数或奖励函数的作用,以重现技能[118]。换句话说,模仿的度量在演示过程中定量地转换了人类的意图,并评估了重复机器人性能的相似性。在机器人装配中,对机器人性能的评估是直观的,完成了所示的装配顺序,并将各个零件装配在一起。但是,如果我们要推动和优化学习过程,则特定的内置指标必不可少。图9显示了一个使用模仿度量的示例,以及如何使用该度量来驱动机器人的复制。
LfD是一个相对年轻但发展迅速的研究领域,已经解决了各种各样的挑战。 最直观的评估标准是最小化机器人重复观察到的动作与人类老师演示的教学动作之间的差异[120-122]。 但是,由于评估仅限于特定的学习任务和机器人平台,因此目前在LfD的不同特征提取模型之间几乎没有直接比较。 LfD需要一套统一的评估指标来比较不同的模仿系统。 现有方法主要考虑关节角的变化和相关信息,轨迹路径以及物手关系。
加权相似性度量
仅考虑轨迹的位置,欧几里得距离度量可以定义为:
通用相似性度量
通用相似性度量H是评估任务再现的一般形式,在[123]中提出。 与等式(1)中定义的欧式距离的加权相似性度量相比,相似性度量H考虑到更多变量,例如约束的变化和变量间的依存关系。 应当注意,矩阵是连续的,正的,并且在沿着轨迹的任何点都是可估计的。
6.总结与讨论
本文介绍了从演示学习(LfD)方法的全面概述,重点介绍了它们在机器人装配中的应用。 演示方法分为三类,分析了每种方法的特点,并回顾了特征提取背后的理论。 然后,根据演示程序在机器人程序中的建模方式,将提取内容分为三类。 在这些模型中,动态运动原语(DMP)因其在机器人装配中形式化非线性动态运动的有利功能而得到突出显示。 接下来,模仿性能的量度被用作再现学习技能的成本函数。 清楚地分析了LfD在机器人装配中的应用,尤其是LfD如何促进装配任务的完成。
LfD具有使公众无需学习编程技能即可使用机器人的独特优势。 另外,LfD的运动学演示解决了人类演示者与机器人之间的对应问题。 因此,LfD是一种有效的机器人学习算法,并已在许多机器人学习系统中使用。 从数据不足到增量学习和有效的演示,LfD有几个有希望的领域,有待进一步研究。 进一步来说:
从数据不足中学习。 LfD旨在向非专家提供一种简单的方法来教授机器人实用技能,尽管通常情况下,演示的数量并不多。 但是,机器人组装中的演示可能包含噪音。 由于缺乏某些运动功能以及与人类示威者互动的直观特性,因此非专业用户很难使用LfD。 要求非专家以重复的方式演示一个动作并不是一个好的解决方案。 需要对如何通过有限的特征样本进行概括的未来研究工作。
增量学习。 机器人可以从演示者那里学习技能,也可以从不同的演示中学到一些技能。 在过去的研究中,增量学习的研究仍然非常有限。 机器人学到的技能是并行的,不是渐进的或增量的。 DMP是可以用来学习更多高级技能的基本学习模块,而这些技能不能用来学习更复杂的技能。 在未来的研究中,增量学习功能应被更多的关注用于机器人组装。
有效的示范。 当演示者执行任何组装动作时,机器人将尝试从演示中提取特征。 在大多数情况下,学习过程是单向的,缺乏及时的修订,导致学习效率降低。 LfD系统中采用的最流行的方法是奖励功能。 但是,奖励函数仅给出对给定状态的评估,而没有关于可以选择演示的理想信息作为最佳示例。 一种有前途的解决方案是,示威者可以及时(例如通过GUI [19])反馈有关机器人动作的信息。 有关如何提供这种有效反馈信息的更多研究是未来工作的另一方面。
精细组装。 机器人组装的目的是极大地提高行业生产率,并帮助工人完成重复性很高的任务,尤其是在“轻”行业,例如小零件的组装。 机器人必须足够复杂,以处理更复杂,更高级的任务,而不仅限于组装的各个子技能,例如插入,旋转,拧紧等。 需要有关如何将子技能结合到流畅的装配技能中的未来研究工作。
改进的评估。 一套标准化的评估指标是未来工作的根本重要研究领域。 此外,改进的评估指标通过在LfD中提供更准确和有效的目标来帮助模仿学习过程。 评估标准的形式化也将促进机器人组装中扩展的通用学习系统的研究和开发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号