
DSO论文解读
dso
1.1. Motivation
本文提出的单目视觉测距法的直接和稀疏公式是出于以下考虑因素;
(1)直接:
关键点的主要优点之一是它们能够为使用现成的商品相机拍摄的图像中存在的光度和几何失真提供稳健性。例如自动曝光变化,非线性响应功能(伽马校正/白平衡),镜头衰减(渐晕),去连接伪像,或甚至由滚动快门引起的强烈几何失真。
同时,对于介绍中提到的所有用例,数百万台设备(并且已经)配备了专门用于为计算机视觉算法提供数据的摄像机,而不是为人类消费捕获图像。这些摄像机应该并且将被设计为提供完整的传感器模型,并以最能为处理算法提供服务的方式捕获数据:例如,自动曝光和伽马校正不是未知的噪声源,而是提供更好图像数据的功能 - 可以合并到模型中,使获得的数据更具信息性。由于直接方法将完整的图像形成过程建模为像素强度,因此它可以从更精确的传感器模型中获益。直接公式的主要好处之一是它不需要一个点本身可以识别,从而允许更精细的几何表示(像素反向深度)。此外,我们可以从所有可用数据中进行采样 - 包括边缘和弱强度变化 - 生成更完整的模型,并在稀疏纹理环境中提供更强大的稳健性。
(2)稀疏:
添加几何体之前的主要缺点是引入几何参数之间的相关性,这使得实时统计上一致的联合优化不可行(参见图2)。
2.2模型公式
我们将在目标帧I j中观察到的参考帧I i中的点p∈Ωi的光度误差定义为在小的像素邻域上的加权SSD。我们的实验表明,以略微扩展的模式排列的8个像素(见图4)在评估所需的计算,运动模糊的稳健性和提供足够的信息之间进行了良好的权衡。请注意,就所包含的信息而言,在如此小的像素邻域上评估SSD类似于为中心像素添加一级和二级辐照度导数条件(除了辐照度恒定性)。 让



为了使我们的方法能够在没有已知曝光时间的情况下操作序列,我们包括由e -a i(I i -b i)给出的附加仿射亮度传递函数。注意,与大多数先前的配方[13,6]相反,标量因子e -a i是对数参数化的。这既防止了它变为负面,又避免了由乘法(即指数增加)漂移引起的数值问题。除了使用强大的Huber惩罚之外,我们还应用了渐变相关的加权w p
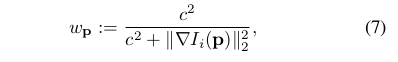
对具有高梯度的像素进行缩减。 该加权函数可以概率地解释为在投影点位置p 0上添加小的,独立的几何噪声,并且立即使其边缘化 - 近似小的几何误差。总而言之,误差E pj取决于以下变量:(1)点的逆深度dp,(2)相机本征c,(3)所涉及的帧的姿势T i,T j和(4)它们的 亮度传递函数参数ai,bi,aj,bj。
所有帧和点的全光度误差由下式给出
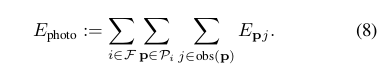
其中i遍历所有帧F,p遍在帧i中的所有点P i,并且j遍及所有帧obs(p),其中点p是可见的。图5显示了结果因子图:与经典重投影误差的唯一区别是每个残差对主机帧姿态的附加依赖性,即每个项依赖于两个帧而不是一个帧。虽然这会将非对角线条目添加到Hessian的姿势 - 姿势块中,但是在应用Schur补码来边缘化点参数后,它不会影响稀疏模式。因此,可以将所得系统解析为间接配方。 注意,关于两个帧的姿势的雅可比行列式通过它们的相对姿势的伴随线性相关。实际上,在计算Hessian或其Schur补码时,可以从总和中拉出该因子,从而大大减少由更多变量依赖性引起的附加计算。
如果曝光时间已知,我们进一步添加先前将仿射亮度传递函数拉到零:
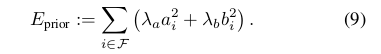
如果没有可用的光度校准,我们设置t i = 1并且λa=λb= 0,因为在这种情况下,他们需要对相机的(未知的)改变曝光时间进行建模。作为旁注,应该提到的是,如果x i和y i都包含噪声测量,则多个因子a * = argmax a i(ax i-y i)2的ML估计量是有偏差的(参见[7]); 导致a在无约束情况下漂移λa= 0。

