JVM学习---threadDump导出与案例分析
在故障定位(尤其是out of memory)和性能分析的时候,经常会用到一些文件来帮助我们排除代码问题。这些文件记录了JVM运行期间的内存占用、线程执行等情况,这就是我们常说的dump文件。常用的有heap dump和thread dump(也叫javacore,或java dump)。我们可以这么理解:heap dump记录内存信息的,thread dump是记录CPU信息的。
heap dump:
heap dump文件是一个二进制文件,它保存了某一时刻JVM堆中对象使用情况。HeapDump文件是指定时刻的Java堆栈的快照,是一种镜像文件。Heap Analyzer工具通过分析HeapDump文件,哪些对象占用了太多的堆栈空间,来发现导致内存泄露或者可能引起内存泄露的对象。
thread dump:
thread dump文件主要保存的是java应用中各线程在某一时刻的运行的位置,即执行到哪一个类的哪一个方法哪一个行上。thread dump是一个文本文件,打开后可以看到每一个线程的执行栈,以stacktrace的方式显示。通过对thread dump的分析可以得到应用是否“卡”在某一点上,即在某一点运行的时间太长,如数据库查询,长期得不到响应,最终导致系统崩溃。单个的thread dump文件一般来说是没有什么用处的,因为它只是记录了某一个绝对时间点的情况。比较有用的是,线程在一个时间段内的执行情况。
两个thread dump文件在分析时特别有效,困为它可以看出在先后两个时间点上,线程执行的位置,如果发现先后两组数据中同一线程都执行在同一位置,则说明此处可能有问题,因为程序运行是极快的,如果两次均在某一点上,说明这一点的耗时是很大的。通过对这两个文件进行分析,查出原因,进而解决问题。
threadDump导出几种方式:
1、在类Linux系统,通过kill -3 <pid>导出
2、通过ps -ef或者jps找到pid,再通过jstack -l pid > a.tdump
3、通过jvisualvm或者jprofiler等可视化工具直接生成线程dump
案例一:下面分析一段代码产生死锁,以及如何分析
public class DeadLockDemo { public static void main(String[] args) { Object a = new Object(); Object b = new Object(); new Thread(()->{ synchronized (a){ try { System.out.println(Thread.currentThread().getName() + ",locked a"); Thread.sleep(3000); synchronized (b){ System.out.println(Thread.currentThread().getName() + ",locked b"); } } catch (InterruptedException e) { e.printStackTrace(); } } },"threadA").start(); new Thread(()->{ synchronized (b){ try { System.out.println(Thread.currentThread().getName() + ",locked b"); Thread.sleep(3000); synchronized (a){ System.out.println(Thread.currentThread().getName() + ",locked a"); } } catch (InterruptedException e) { e.printStackTrace(); } } },"threadB").start(); } }
执行结果:
threadA,locked a
threadB,locked b
分析步骤:
1、通过jps -l(只能查看到本机java进程)或者ps -ef | grep ...(可以查看到所有用户的java进程),找到pid
2、jstack -l pid(内容较多的话可以重定向到一个文件,jstack -l pid > result.tdump)可以看到死锁很明显found 1 deadlock。
Java stack information for the threads listed above: =================================================== "threadB": at cn.htd.DeadLockDemo.lambda$main$1(DeadLockDemo.java:27) - waiting to lock <0x000000076c1b6860> (a java.lang.Object) - locked <0x000000076c1b6870> (a java.lang.Object) at cn.htd.DeadLockDemo$$Lambda$2/1452126962.run(Unknown Source) at java.lang.Thread.run(Thread.java:748) "threadA": at cn.htd.DeadLockDemo.lambda$main$0(DeadLockDemo.java:13) - waiting to lock <0x000000076c1b6870> (a java.lang.Object) - locked <0x000000076c1b6860> (a java.lang.Object) at cn.htd.DeadLockDemo$$Lambda$1/81628611.run(Unknown Source) at java.lang.Thread.run(Thread.java:748) Found 1 deadlock.
案例二:定位cpu占用率高的java线程
1、通过top查找到cpu占用率高的java进程。

2、定位最耗CPU的线程,命令:top -Hp 11721
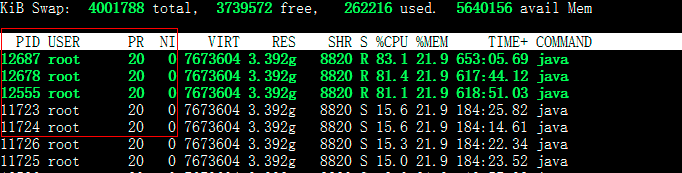
3、把线程id转为16进制,通过jstack打印线程堆栈信息,就可以定位问题代码
命令: jstack -l 11721 | grep $(printf "%x\n" 12687) -50 --定位出找到的nid以及前面后面各50行
命令2:jstack -l 11721 | grep $(printf "%x\n" 12687) -A50 --定位出找到的nid以及后面50行
命令3:jstack -l 11721 | grep $(printf "%x\n" 12687) -B50 --定位出找到的nid以及前面50行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号