(数据科学学习手札31)基于Python的网络数据采集(初级篇)
一、简介
在实际的业务中,我们手头的数据往往难以满足需求,这时我们就需要利用互联网上的资源来获取更多的补充数据,但是很多情况下,有价值的数据往往是没有提供源文件的直接下载渠道的(即所谓的API),这时我们该如何批量获取这些嵌入网页中的信息呢?
这时网络数据采集就派上用处了,你通过浏览器可以观看到的绝大多数数据,都可以利用爬虫来获取,而所谓的爬虫,就是我们利用编程语言编写的脚本,根据其规模大小又分为很多种,本篇便要介绍基本的Python编写的爬虫脚本来进行单机形式的网络数据采集,这也是一个进阶的数据挖掘工程师或数据分析师的基本技能之一,大量的应用场景都会需要这种几乎可以毫无阻碍地获取数据的手段,譬如市场预测、机器语言翻译亦或是医疗诊断领域,通过对新闻网站、文章中的文本数据进行采集以进行进一步的数据挖掘工作,也是爬虫很常见的应用场景之一;
本篇博客将通过介绍基础的爬虫知识,并附上两个实战项目的例子(爬取网易财经海南板块历史股票数据、爬取网易新闻多个分类板块的新闻文本数据),对基础的爬虫做一个小小的总结。
*本篇以jupyter notebook作为开发工具
二、建立连接
为了抓取互联网上的数据资源,第一步显然是要建立起网络连接(即登入你的目标网址),在Python中,我们使用urllib.request中的urlopen()来建立起与目标网址的连接,这个函数可以用来打开并读取一个从网络获取的远程对象,可以轻松读取HTML文件、图像文件或其他寄存在网络端的文件,下面是一个简单的例子:
from urllib.request import urlopen '''赋值我们需要登入的网址''' html = urlopen('http://news.163.com/') '''打印采集回的目标网页的源代码''' print(html.read())
运行结果:

可以看出,通过上面非常简单的几行语句,我们就采集回http://news.163.com/的网页源代码,与浏览器中查看源代码的方式进行比较:
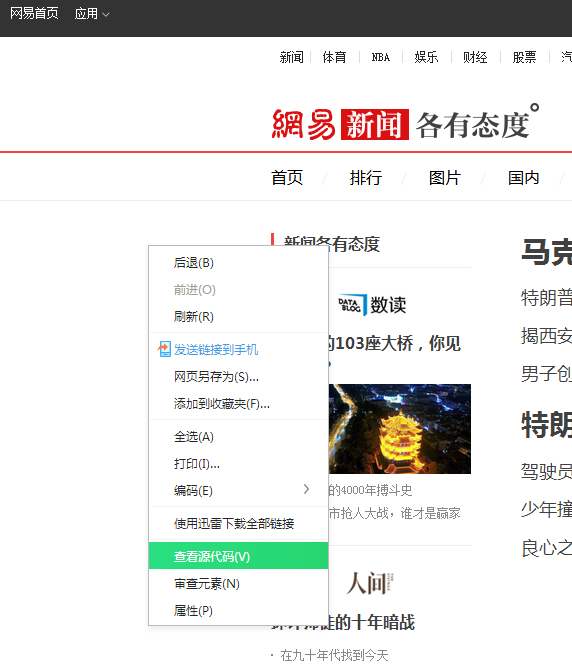

可以看出,只通过这几行语句采集回的网页内容,和浏览器中展示的网页源码信息有很大的出入,这是因为我们通过urlopen只是传回来朴素的源代码,没有经过任何解析操作,下面介绍如何对返回的朴素的网页源码进行解析;
三、BeautifulSoup库
通过上一节我们举的例子可以看出,我们需要对返回的网页源码进行结构化的解析,而BeautifulSoup就是这样一个神奇的第三方库,它通过对HTML标签进行定位,以达到格式化和组织复杂网络信息的目的,我们基于BeautifulSoup对上一节中的简单代码进行扩充:
from urllib.request import urlopen from bs4 import BeautifulSoup '''赋值我们需要登入的网址''' html = urlopen('http://news.163.com/') '''利用BeautifulSoup对朴素的网页源代码进行结构化解析(包括对utf编码的内容进行转码)''' obj1 = BeautifulSoup(html.read()) '''打印采集回的目标网页的源代码''' print(obj1)
运行结果:

可以看出这时我们得到的内容与我们之前在浏览器中查看的网页源代码一致(中文内容也被展示出来),更重要的是,我们已经对目标网页的结构进行了解析,意味着我们可以通过调用不同结构标签来查看相应内容:
print(obj1.html.h1) print(obj1.html.title)
运行结果:

这对之后我们对所需内容的定位提取很有帮助,事实上,任何HTML、XML文件的任意节点信息都可以被提取出来,只要目标信息的附近有标记即可;
四、错误的处理策略
相比大家都有经验,当我们登入某些网址时,因为网络不稳定或其它原因,会导致网页连接失败,而在我们的网络爬虫持续采集数据的过程中,因为网页数据格式不友好、网络服务器宕机、目标数据的标签寻找失败等原因,会导致你的爬虫中途因发生错误而中断,这在需要长时间工作的爬虫项目来说尤为关键;
爬虫工作过程中常见的错误如下:
对于urlopen的过程,服务器上不存在目标网页(或是获取页面的时候出现错误),这种异常发生时,程序会返回HTTP错误,这包含很多种详细的错误类型,但urlopen统一反馈“HTTPError”,于是乎利用Python中处理错误的try...except机制,就可以在爬虫遇到这种错误时,进行相应的处理方法(通常是选择跳过),下面是一个简单的例子:
from urllib.request import urlopen '''创造一系列网址,其中第四个为伪造的不存在网站''' html = ['http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=1', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=2', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=3', 'http://www.pythonscraping.com/pages/page10000.html', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=4'] '''循环反馈对应网址的源代码信息''' for i in range(5): token = urlopen(html[i]) print(token.read()[:10])
这时我们没有进行错误处理,因此在程序运行到第四个网址时,会出现打不开网页的错误,如下:

HTTPError出现了,这时由于这个网址的打开失败,导致后续的任务都被迫中断,下面我们使用错误处理机制对这种遍历任务中的潜在错误风险进行处理:
from urllib.request import urlopen from urllib.error import HTTPError#注意,这里需要import urllib中具体的错误类型 '''创造一系列网址,其中第四个为伪造的不存在网站''' html = ['http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=1', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=2', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=3', 'http://www.pythonscraping.com/pages/page10000.html', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=4'] '''循环反馈对应网址的源代码信息''' for i in range(5): try: token = urlopen(html[i]) print(token.read()[:10]) except HTTPError as e: print('错误出现!跳过')
运行结果:

这样就可以对各种潜在的错误进行处理,而不打断整个程序的进行,但运行大的爬虫项目时,潜在的错误类型是多种多样的,一旦没有在程序开头import全对应的错误类型,依旧会因为未预料到的错误类型打断程序,这时我们可以利用try...except中的泛型错误Exception来识别所有错误类型,并打印具体的错误类型以作后期分析:
from urllib.request import urlopen '''创造一系列网址,其中第四个为伪造的不存在网站''' html = ['http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=1', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=2', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=3', 'http://www.pythonscraping.com/pages/page10000.html', 'http://quotes.money.163.com/trade/lsjysj_600221.html?year=2012&season=4'] '''循环反馈对应网址的源代码信息''' for i in range(5): try: token = urlopen(html[i]) print(token.read()[:10]) except Exception as e:#泛型错误处理机制 print('错误','< ',e,' >','出现!跳过')
运行结果:

可以看到,在利用Exception时,会处理所有可能的错误,非常方便;
五、目标内容的粗略提取(基于CSS)
前面说了这么多,实际上还是在对我们的目的做铺垫,即介绍了 获取信息--抽取目标信息 这个过程中的获取信息部分,在获得了结构化的全量信息之后,我们就要开始着手如何提取其中想要的信息了;
先普及一个知识:几乎每一个网站都会存在层叠样式报(cascading style sheet,CSS),这种机制使得浏览器和人类得以理解网页的层次内容,CSS可以让HTML元素呈现出差异化,使得不同的数据归属于其对应的标签下,我们再通过BeautifulSoup解析后的网页内容(带有各层次标签),利用对应内容的标签属性,即可有选择的获取我们想要的数据内容;
我们用findAll()方法来对BeautifulSoup对象进行指定标签内容的提取,下面是一个简单的例子:

我们对http://sports.163.com/18/0504/10/DGV2STDA00058782.html这个新闻网页,先是提取它的新闻标题内容,通过观察网页源代码,发现其文章标题内容隐藏在<title>标签下,于是利用findAll()对title标签内内容进行提取:
from urllib.request import urlopen from bs4 import BeautifulSoup '''连接目标网址''' html = urlopen('http://sports.163.com/18/0504/10/DGV2STDA00058782.html') '''将反馈回的网页源代码解析为BeautifulSoup对象''' obj = BeautifulSoup(html) '''提取obj对象下title标签内的内容''' text = obj.findAll('title') '''打印结果''' print(text)
运行结果:

从上面的小例子中可以看出findAll()的强大功能,下面对其进行详细的介绍:
BeautifulSoup中的find()与findAll()是网页内容提取中最常用的两个函数,我们可以利用它们通过标签的不同属性轻松地过滤HTML页面,查找需要的单个或多个标签下的内容。
find()与findAll()用法几乎一样,先介绍findAll()的主要参数:
tag:这个参数传递字符串形式的单个标题标签或由多个标题标签组成的列表,如'title',['h1','h2','h3']
attributes:属性参数,接受用字典封装的一个标签的若干属性和对应的属性值,例如{'property':'og:description'}
recursive:bool型变量,默认为True,代表findAll会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签;如果设置为False,则findAll只查找文档的一级标签;
text:字符型输入,设置该参数以后,提取信息就不是用标签的属性,而是用标签的文本内容,即content中的内容来匹配
limit:范围限制参数,只用于findAll,换句话说,find等价于findAll的limit参数为1时的特殊情况,因为根据其他参数设定的条件返回的,是满足条件的所有标签下内容按顺序排列的一个序列,limit设置的值即控制了最终留下前多少个结果
keyword:这个参数的用法不是对keyword赋值,而是将你感兴趣的标签内属性声明项,如name="keywords"这样的,在findAll中附加上
下面还是基于之前举例子的那篇新闻网页,对findAll进行演示:
单个标题标签内容的粗略提取:
from urllib.request import urlopen from bs4 import BeautifulSoup html =urlopen( 'http://sports.163.com/18/0504/10/DGV2STDA00058782.html') obj = BeautifulSoup(html,'lxml') '''获取标签为<p>的内容''' text = obj.findAll('p') print(text)
运行结果:

多个标签内容的捆绑提取:
from urllib.request import urlopen from bs4 import BeautifulSoup html =urlopen( 'http://sports.163.com/18/0504/10/DGV2STDA00058782.html') obj = BeautifulSoup(html,'lxml') '''保存多个标题标签的列表''' tag = ['title','meta'] '''获取tag中标签的内容''' text = obj.findAll(tag) print(text)
运行结果:

对指定标签下指定属性值对应内容的提取:
from urllib.request import urlopen from bs4 import BeautifulSoup html =urlopen( 'http://sports.163.com/18/0504/10/DGV2STDA00058782.html') obj = BeautifulSoup(html,'lxml') '''获取meta标签下属性name为author的对应内容''' text = obj.findAll('meta',{'name':'author'}) print(text)
运行结果:

六、正则表达式
即使你之前完全没有接触过网络爬虫,也可能接触过正则表达式(regular expression,简称regex),之所以叫正则表达式,是因为它们可以识别正则字符串(regular string),通俗的理解就是,我只识别我编写的正则表达式所匹配的内容,而忽视不符合我的表达式所构造的规则的字符串,这在很多方面都十分的方便;
正则字符串是任意可以用一系列线性规则构成的字符串,例如:
1、字母“a”至少出现一次;
2、后面接上重复5次的“b”;
3、后面再接上重复任意偶数次的字母“c”;
4、最后一位字母是“d”或没有。
满足上述组合条件的字符串有无数个,如“aaabbbbbccccd”,“abbbbbcc”等,相信你应该理解了,正则表达式就是用一个对于目标语句的格式普适的规则,来识别目标内容。
你可以将正则表达式理解为SQL中的LIKE运算符后跟着的通配符,还是以上面介绍过的组合条件为例,用正则表达式来表示:
aa*bbbbb(cc)*(d|)
首先,开头的a表示a出现一次,a*表示a出现任意次,因此aa*的组合代表a至少出现一次;bbbbb表示连续出现5次b;(cc)*表示cc出现任意次,对应重复任意次(包括0次)的c;(d|)表示出现d或无任何字符,对应“最后一位是字母d或没有”,这样一个由若干规则按顺序组合起来的字符串,就是正则字符串;
*有很多网站可以在线测试你的正则表达式,我喜欢用的是http://regexpal.com.s3-website-us-east-1.amazonaws.com/?_ga=2.164205119.1679442026.1514793856-2027450969.1514793856
再举一个更常见的正则表达式使用场景——识别邮箱,以我个人的邮箱为例:pengzyill@foxmail.com,这是个常见的邮箱格式,若要编写正则表达式来识别它,就会按顺序用到以下识别规则:
1、邮箱的第一部分至少包括一种内容:大写字母、小写字母、数字0-9、点号.、加号+或下划线_,因此为了识别这一部分,我们构造的正则字符串如下:
[A-Za-z0-9\.+_]+
[]中放入的内容是所有可能出现的内容的最简形式,A-Z表示所有大写字母,a-z表示所有小写字母,0-9表示所有数字,\.表示点号.(这里用\转义),+表示加号,_表示下划线,[]后紧跟的+表示前面[]内的所有部件可以出现多次,且至少有一种部件至少出现1次,可以看出,非常简洁;
2、紧跟着,会出现一个@符号,很简单,对应的正则字符串为:
@
3、在@之后,是指明邮箱所属域名的部分,由大小写字母组成,如我的邮箱中的foxmail,于是对应的正则字符串为:
[A-Za-z]+
4、紧跟着是一个点号,即:
\.
5、最后一部分,是邮箱地址的顶级域名,如com,org,edu或net等,这是四种最常见的,因此以这四种作为全部(虽然有些以偏概全),对应的正则字符串如下:
(com|org|edu|net)
将上述的子正则字符串按照顺序连接起来,便得到了我们的用于识别邮箱地址的正则字符串:
[A-Za-z0-9\.+_]+@[A-Za-z]+\.(com|org|edu|net)
我们在前面提到的在线测试网站中测试一下~
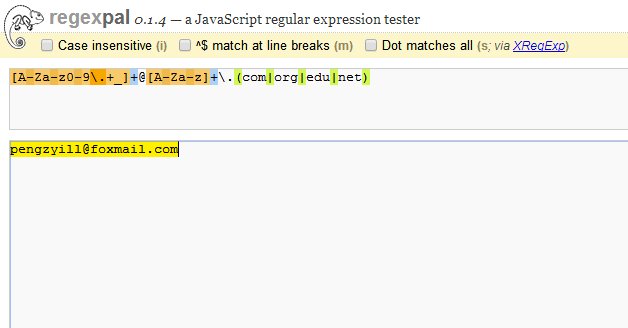
可以看出,我的邮箱地址被准确的识别出来(完全被黄色底纹包裹),你也可以试试你自己的邮箱地址;所以,在使用正则表达式之前,最好分块的理清楚各个部分需要对应的正则字符串,这对提高效率很有帮助。
下面用一些简单的说明和例子来总结一下正则表达式中的常用符号:
| 符号 | 含义 | 例子 | 匹配结果 |
| * | 匹配前面的单个字符、子表达式或括号里的所有字符0次或多次 | a*(bb)* | aaaa aabbbb |
| + | 匹配前面的字符、子表达式或括号里的所有字符至少1次 | a+b+ | ab aabbb |
| [] | 匹配括号中任意一个字符(配合*实现多次出现的匹配) | [A-Z]* | LOVE PEACE |
| () | 表达式编组(类似数学运算,()里的规则会优先运行) | (a*b)* | aabab abababab |
| {m,n} | 匹配前面的字符、子表达式或括号里的字符m到n次(包含m或n) | a{2,3}b{2,3} | aabbb aaabb |
| [^] | 匹配任意一个不在中括号里的字符 | [^A-Z]* | apple love%++ |
| | | 匹配任意一个由竖线|分割的字符、子表达式 | b(a|i|e)d | bad bid bed |
| . | 匹配任意单个字符(包括符号、数字和空格等) | b.d | bed b?d bod |
| ^ | 表示以某个字符或子表达式开头的字符串 | ^a | adshdjsh a?di |
| \ | 转义字符(把有特殊含义的字符转换成字面形式,譬如本表中的一些常用符号) | \.\|\\ | .|\ |
| $ | 常用于正则表达式的末尾,表示“从字符串的末端匹配”,如果不使用它,每个正则表达式实际上都相当于外套一个.*,默认从字符串开头进行匹配。可以将这个符号视为^的反义词 | [A-Z]*[a-z]*$ | ABCabc |
| ?! | 表示“不包含”,这个符号通常放在字符或正则表达式前面,表示指定字符不可以出现在目标字符串中,若字符在字符串的不规则部位出现,则需要在整个字符串中排除某个字符,就需要加上^与$符号 | ^((?![A-Z]).)*$ | nojoasdn-\ |
七、正则表达式与BeautifulSoup
基于前面介绍的正则表达式,下面我们来介绍如何将正则表达式与BeautifulSoup结合起来:
这里要使用到一个新的模块——re,这时Python中专门进行正则表达式相关操作的模块,为了与BeautifulSoup结合起来,我们需要进行的操作是将re.compile('正则表达式内容')作为findAll内适配参数的输入值,即可将以前确切赋参的方法,转换为利用正则表达式进行模式赋参,这大大提高了findAll对网页内容提取的自由度和效率,下面是几个简单的例子:
from urllib.request import urlopen from bs4 import BeautifulSoup import re html =urlopen( 'http://sports.163.com/18/0504/10/DGV2STDA00058782.html') obj = BeautifulSoup(html,'lxml') '''匹配meta标签下,name属性值为k开头,紧跟着任意数目小写字母''' text = obj.findAll('meta',{'name':re.compile('k[a-z]*')}) print(text)
运行结果:

接下来我们来实现更复杂一些的数据爬取,我在本篇博客中反复举例的网页是一篇关于台球的新闻报道,那么我们最关注的信息就应该是新闻的正文内容,下面我们就将针对此目的进行数据的爬取:
通过对网页源代码的观察后,确定了新闻内容属于标签p下,因此利用正则表达式配合findAll爬取这部分内容,这里.*?表示匹配所有类型任意出现次数的字符:
from urllib.request import urlopen from bs4 import BeautifulSoup import re html =urlopen( 'http://sports.163.com/18/0504/10/DGV2STDA00058782.html') obj = BeautifulSoup(html,'lxml') '''匹配p标签下的内容''' text = obj.findAll('p',text=re.compile('.*?')) '''打印未经处理的内容''' print(text)
运行结果:

虽然将全部新闻内容爬取了下来,但其中参杂着许多<>包裹的标签内容,下面我们利用re.sub来对这些无关内容进行处理:
'''将爬下来的粗略内容转为字符串形式''' text = str(text) '''利用re.sub将所有的<>及内部信息替换为空字符,等价于将这些干扰部分删去''' print(re.sub('<.*?>','',text))
运行结果:

相信你此时一定在惊叹re这个模块的功能之强大,接下来的一篇博客,我就将详细介绍re模块的常见功能和特性;
以上就是关于Python网络爬虫的初级知识,今后会继续更进阶的介绍,敬请期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号