(数据科学学习手札142)dill:Python中增强版的pickle
本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
大家好我是费老师,相信不少读者朋友们都在Python中利用pickle进行过序列化操作,而所谓的序列化,指的是将程序运行时在内存中产生的变量对象,转换为二进制类型的易存储可传输数据的过程,相反地,从序列化结果解析还原为Python变量就叫做反序列化。
通常我们都是用标准库pickle进行这项操作,但其功能单一,且针对很多常见的Python对象如lambda函数无法进行序列化。而今天费老师我要给大家介绍的库dill就可以看作增强版的pickle。

2 使用dill实现更丰富的序列化/反序列化操作
作为第三方库,我们使用pip install dill完成安装后,就可以使用它来代替pickle了:
2.1 基础使用
dill的基础使用与pickle一样,使用dump/dumps进行序列化操作,load/loads进行反序列化操作,下面是一些基本的例子,我们对一些常见的对象进行序列化/反序列化操作:
import dill
import numpy as np
demo_int = 999
demo_float = 0.99
demo_dict = {'a': 999}
demo_array = np.random.rand(2, 2)
# 序列化并写出到pkl文件
with open('./demo.pkl', 'wb') as d:
dill.dump(
[demo_int, demo_float, demo_dict, demo_array],
d
)
从写出的demo.pkl文件中还原对象:
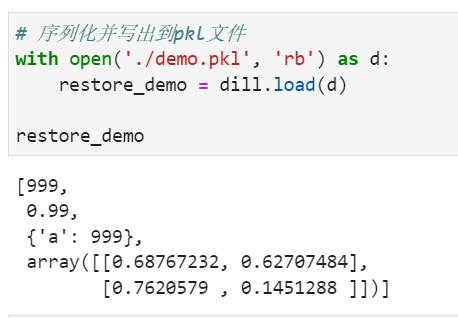
# 序列化并写出到pkl文件
with open('./demo.pkl', 'rb') as d:
restore_demo = dill.load(d)
restore_demo
2.2 增强功能
看完了dill的基础用法,下面我们来介绍其相对于pickle进行增强的特殊功能:
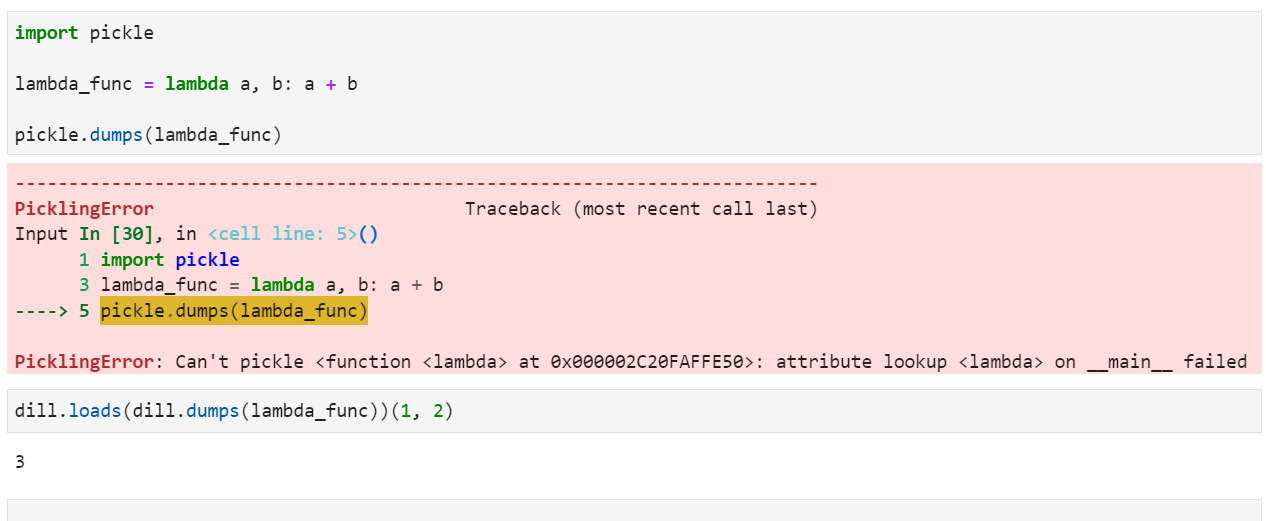
2.2.1 对lambda函数进行序列化
pickle可以对常规的函数进行序列化,但针对lambda函数则会报错,而使用dill就可以正常序列化:
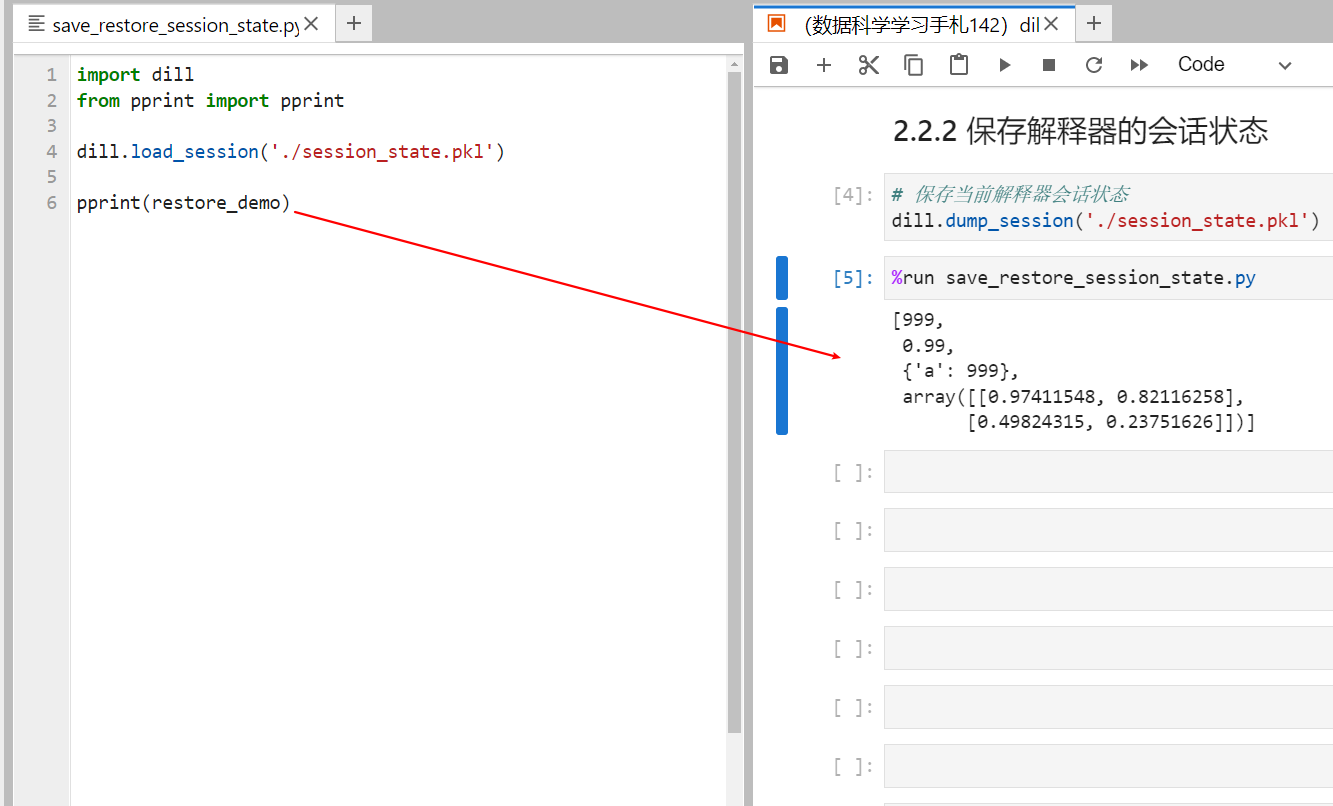
2.2.2 保存解释器的会话状态
dill中另一项很实用的功能则是其支持将当前解释器的会话状态整个打包保存和还原,譬如下面的例子,利用dill.dump_session()保存当前解释器会话状态,在另一个独立的py脚本中再利用dill.load_session()就可以一步到位全部还原:
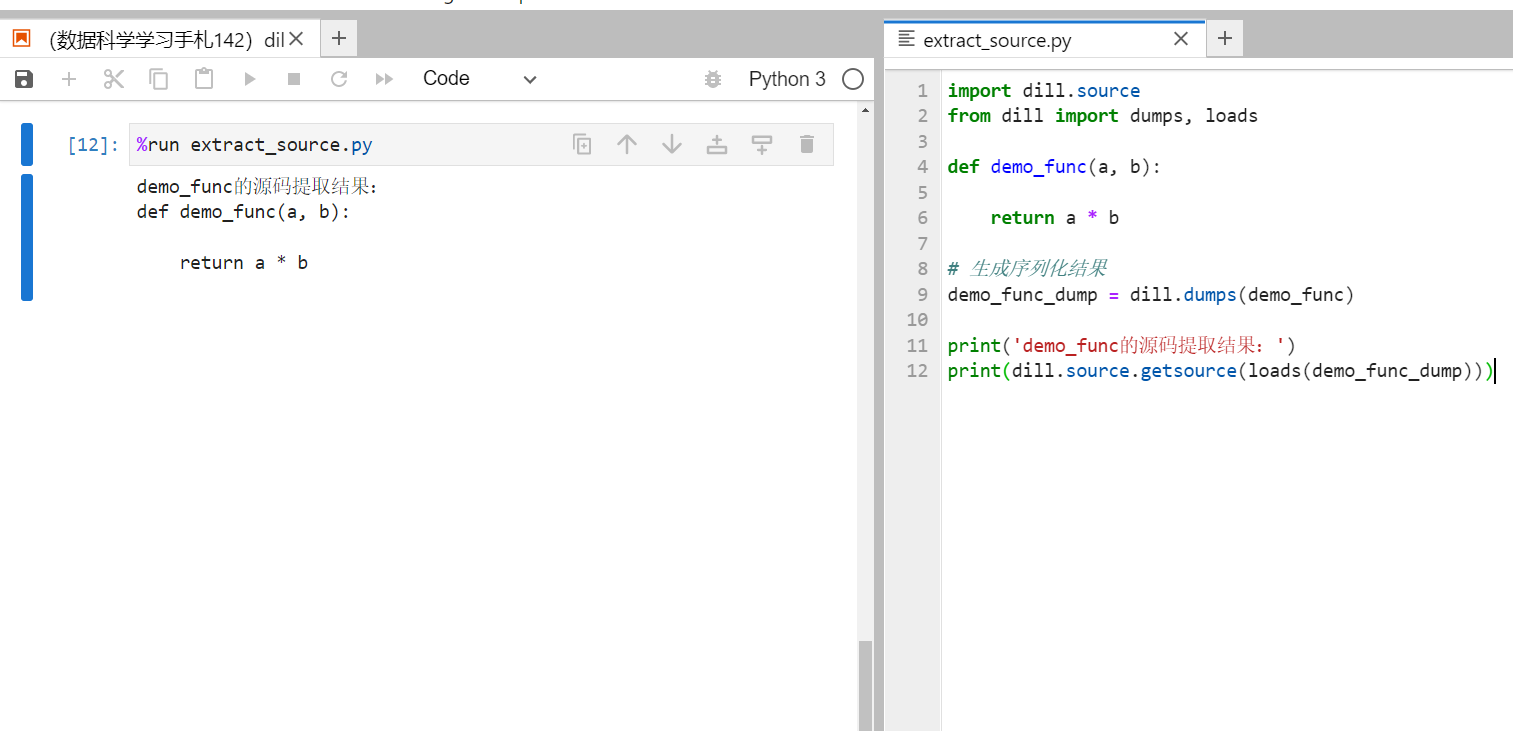
2.2.3 从序列化结果中还原源码
dill中另一个很强大的功能是其source模块可以从序列化结果中还原对象的源码,这在序列化的对象为函数时非常实用(注意目前此功能不可以在ipykernel中执行,因此下面的例子使用魔术命令直接执行外部py脚本):
除此之外,dill还有很多其他丰富的功能,感兴趣的读者朋友可以前往其官方文档(https://dill.readthedocs.io/en/latest/dill.html)了解更多。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号