(数据科学学习手札97)掌握pandas中的transform
本文示例文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
开门见山,在pandas中,transform是一类非常实用的方法,通过它我们可以很方便地将某个或某些函数处理过程(非聚合)作用在传入数据的每一列上,从而返回与输入数据形状一致的运算结果。
本文就将带大家掌握pandas中关于transform的一些常用使用方式。

2 pandas中的transform
在pandas中transform根据作用对象和场景的不同,主要可分为以下几种:
2.1 transform作用于Series
当transform作用于单列Series时较为简单,以前段时间非常流行的企鹅数据集为例:
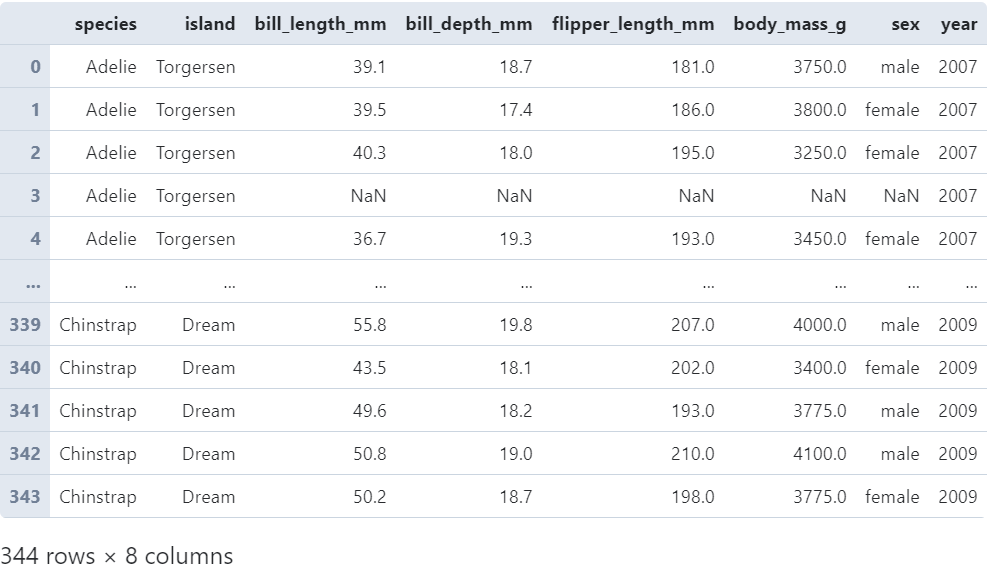
我们在读入数据后,对bill_length_mm列进行transform变换:
- 单个变换函数
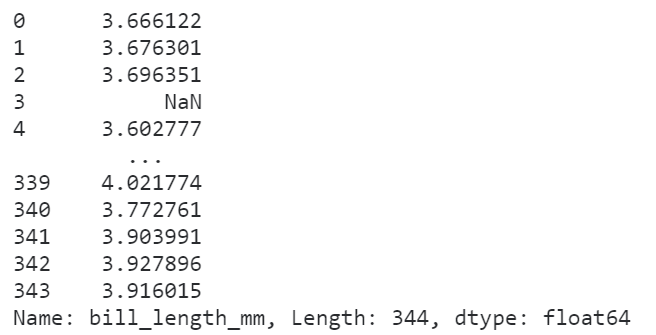
我们可以传入任意的非聚合类函数,譬如对数化:
# 对数化
penguins['bill_length_mm'].transform(np.log)
或者传入lambda函数:
# lambda函数
penguins['bill_length_mm'].transform(lambda s: s+1)

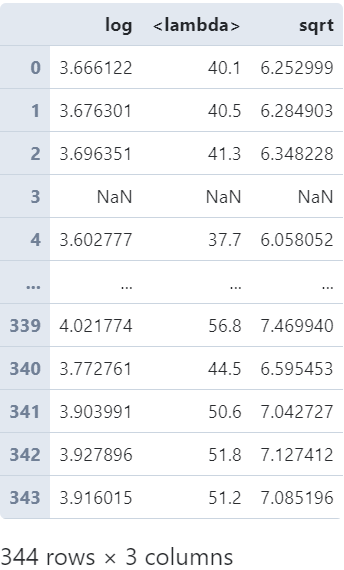
- 多个变换函数
也可以传入包含多个变换函数的列表来一口气计算出多列结果:
penguins['bill_length_mm'].transform([np.log,
lambda s: s+1,
np.sqrt])
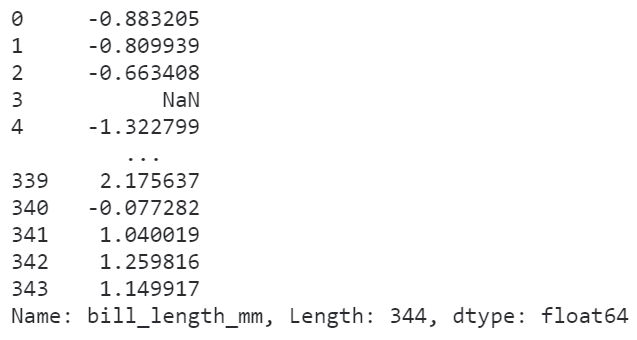
而又因为transform传入的函数,在执行运算时接收的输入参数是对应的整列数据,所以我们可以利用这个特点实现诸如数据标准化、归一化等需要依赖样本整体统计特征的变换过程:
# 利用transform进行数据标准化
penguins['bill_length_mm'].transform(lambda s: (s - s.mean()) / s.std())
2.2 transform作用于DataFrame
当transform作用于整个DataFrame时,实际上就是将传入的所有变换函数作用到每一列中:
# 分别对每列进行标准化
(
penguins
.loc[:, 'bill_length_mm': 'body_mass_g']
.transform(lambda s: (s - s.mean()) / s.std())
)
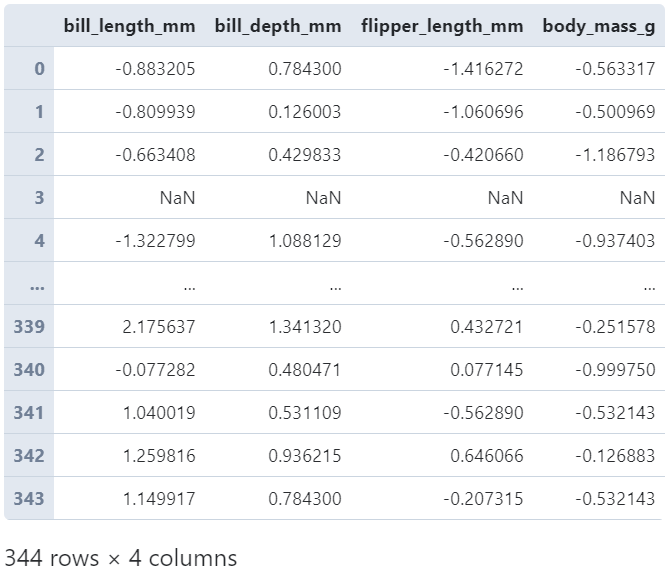
而当传入多个变换函数时,对应的返回结果格式类似agg中的机制,会生成MultiIndex格式的字段名:
(
penguins
.loc[:, 'bill_length_mm': 'body_mass_g']
.transform([np.log, lambda s: s+1])
)
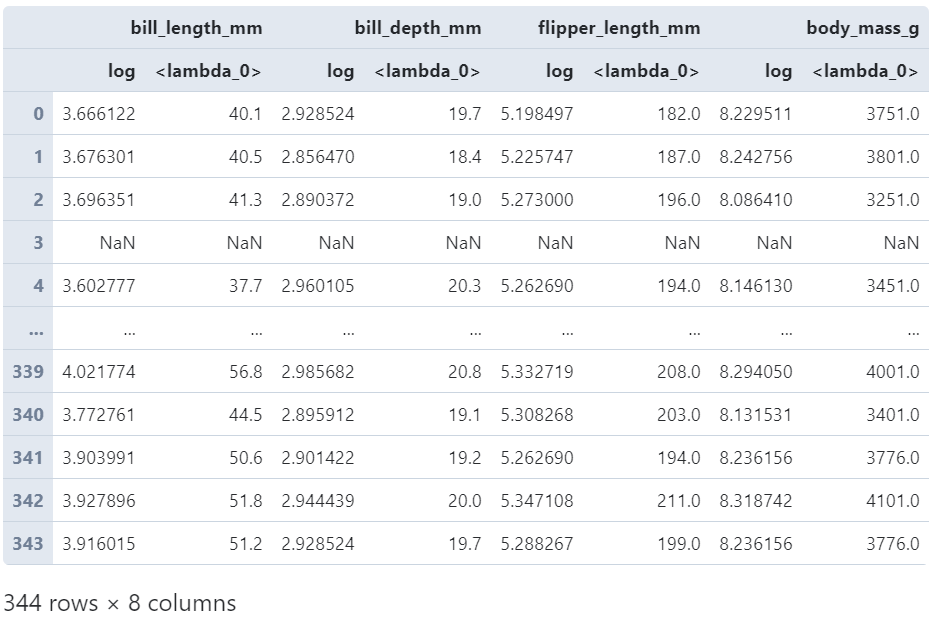
而且由于作用的是DataFrame,还可以利用字典以键值对的形式,一口气为每一列配置单个或多个变换函数:
# 根据字典为不同的列配置不同的变换函数
(
penguins
.loc[:, 'bill_length_mm': 'body_mass_g']
.transform({'bill_length_mm': np.log,
'bill_depth_mm': lambda s: (s - s.mean()) / s.std(),
'flipper_length_mm': np.log,
'body_mass_g': [np.log, np.sqrt]})
)
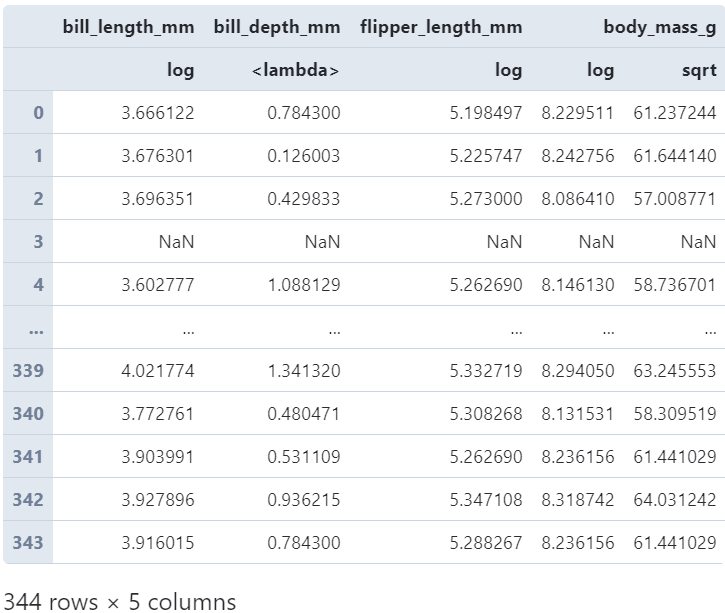
2.3 transform作用于DataFrame的分组过程
在对DataFrame进行分组操作时,配合transform可以完成很多有用的任务,譬如对缺失值进行填充时,根据分组内部的均值进行填充:
# 分组进行缺失值均值填充
(
penguins
.groupby('species')[['bill_length_mm', 'bill_depth_mm',
'flipper_length_mm', 'body_mass_g']]
.transform(lambda s: s.fillna(s.mean().round(2)))
)
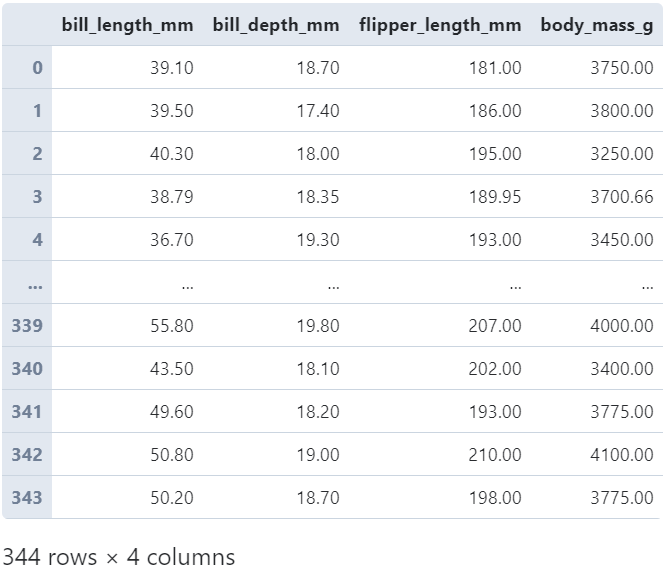
并且在pandas1.1.0版本之后为transform引入了新特性,可以配合Cython或Numba来实现更高性能的数据变换操作,详细的可以阅读( https://github.com/pandas-dev/pandas/pull/32854 )了解更多。
除了以上介绍的内容外,transform还可以配合时间序列类的操作譬如resample等,功能都大差不差,感兴趣的朋友可以自行了解。
以上就是本文的全部内容,欢迎在评论区与我进行讨论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号