(在模仿中精进数据可视化02) 温室气体排放来源可视化
本文完整代码已上传至我的
Github仓库https://github.com/CNFeffery/FefferyViz
1 简介
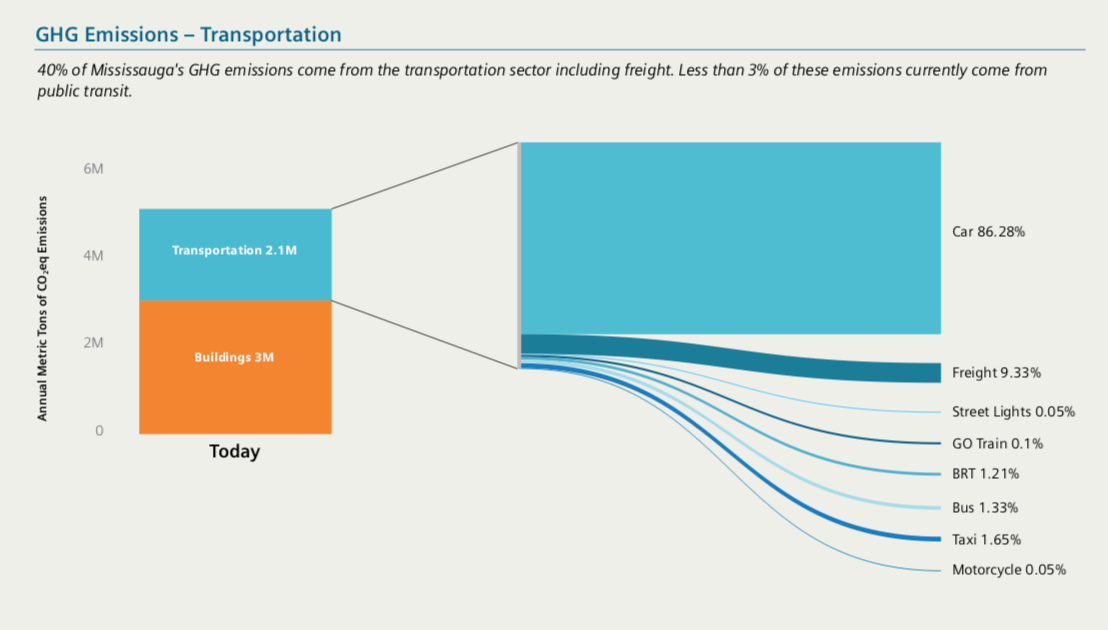
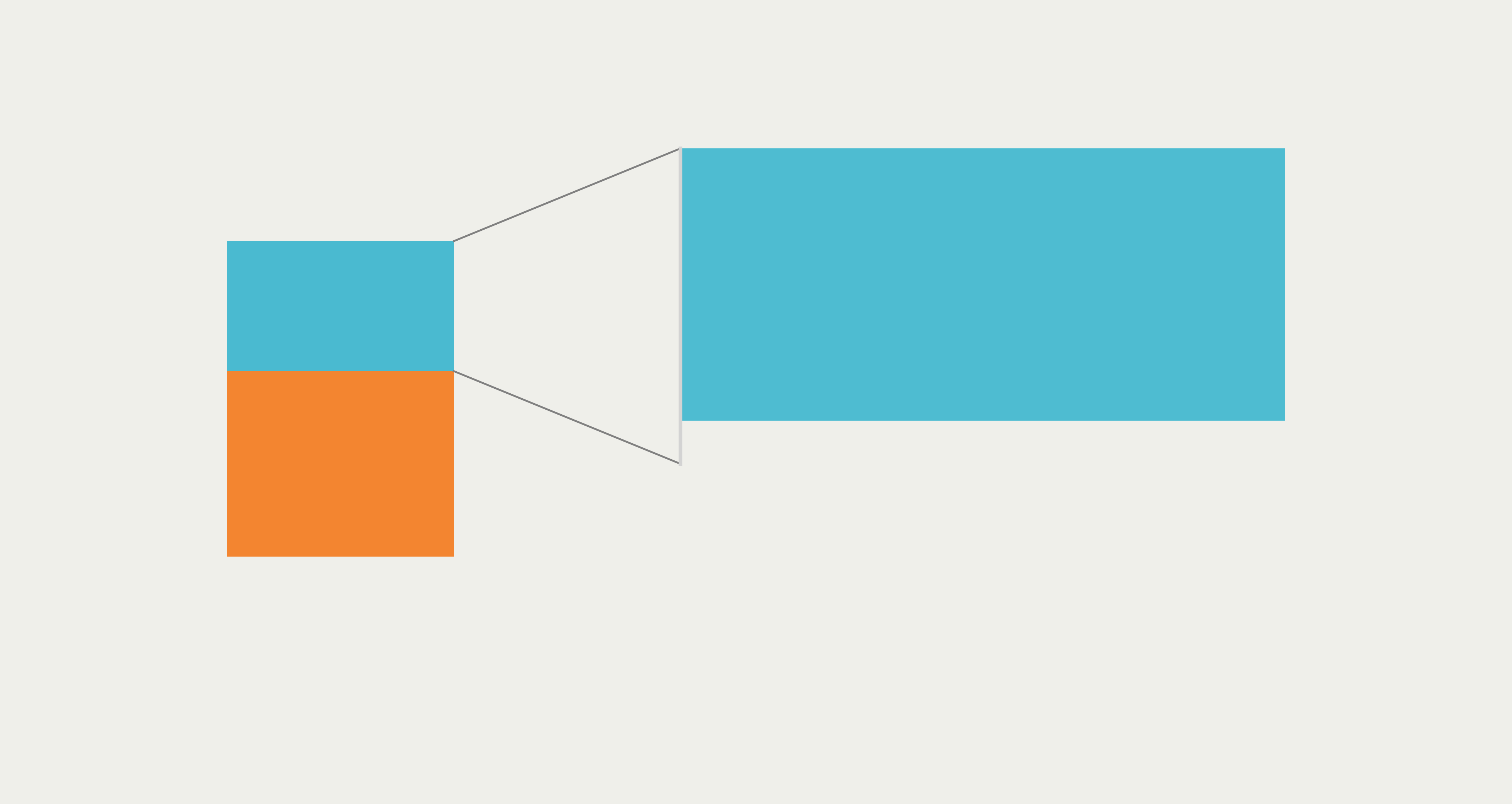
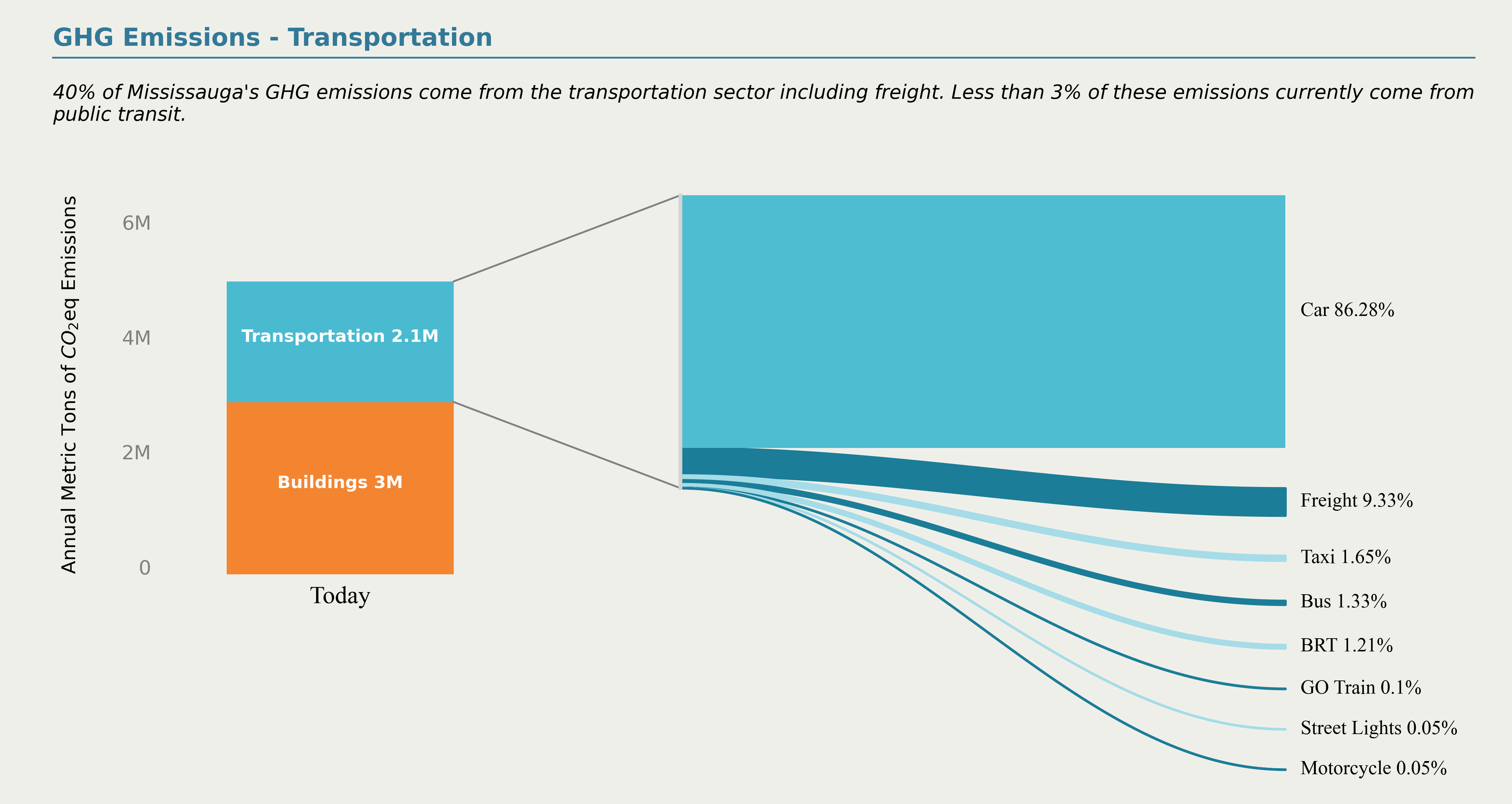
交通是产生温室气体排放的主要来源之一,而本期作为(在模仿中精进数据可视化)系列的第二期,将带大家以纯Python的方式对加拿大米西索加城市温室气体排放研究报告中的如图1所示的可视化作品进行复刻,它对温室气体排放来源中,交通方面的各排放源排放比例进行可视化:
2 模仿过程
2.1 观察原作品
其实原作品整体构图上比较直观,主要由两部分组成:
- 1 左侧柱状图部分
左侧的柱状图无需多言,就是一个简单的堆叠柱状图,利用matplotlib构建起来非常方便。
- 2 右侧类桑基图部分
到了右侧,也是这张图中最有设计感的部分,它用类似桑基图的方式,将左图中交通下属的分类温室气体排放比例构成进行可视化,这也是本文的重点部分,我们可以利用matplotlib加上一点点简单的数学知识来复刻它。
2.2 开始动手!
在洞悉了原作品的主要视觉元素之后,接下来我们开始动手复刻它。
2.2.1 左侧柱状图部分
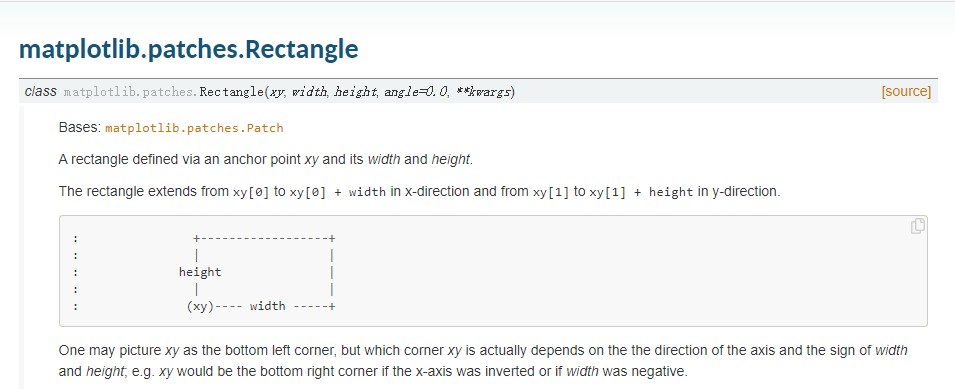
对于左侧的堆叠柱状图,其本质其实是两个堆叠起来的矩形,因此我们可以使用matplotlib.patches下的Rectangle来创建矩形。
其使用方法非常简单,只需要指定矩形左下角坐标,再填写矩形对应的宽与高即可自由创建矩形:
我们参考原作品的背景色,以及左侧矩形对应y轴的真实数值,先把左侧的堆叠柱状图和图床背景色做好:
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# 创建图床
fig, ax = plt.subplots(figsize=(11, 6))
# 创建buildings对应矩形
ax.add_patch(Rectangle((0, 0), 3e6, 3e6, facecolor='#f38530'))
# 创建transportation对应矩形
ax.add_patch(Rectangle((0, 3e6), 3e6, 2.1e6, facecolor='#4abad0'))
# 设置x轴范围
ax.set_xlim(-3e6, 1.7e7)
# 设置y轴范围
ax.set_ylim(-4e6, 9e6)
# 设置背景色
fig.patch.set_facecolor('#efefea')
ax.set_facecolor('#efefea')
# 关闭坐标轴
ax.axis('off');

接着我们在上面代码的基础上添加下列代码,顺便把原作品中连接左右侧的3条灰色线条添加上去:
# 添加连接线
ax.plot([3e6, 6e6], [3e6, 3e6-1.5e6], color='grey', linewidth=0.75)
ax.plot([3e6, 6e6], [5.1e6, 5.1e6+1.5e6], color='grey', linewidth=0.75)
ax.plot([6e6, 6e6], [3e6-1.5e6, 5.1e6+1.5e6], color='lightgrey', linewidth=1.5)
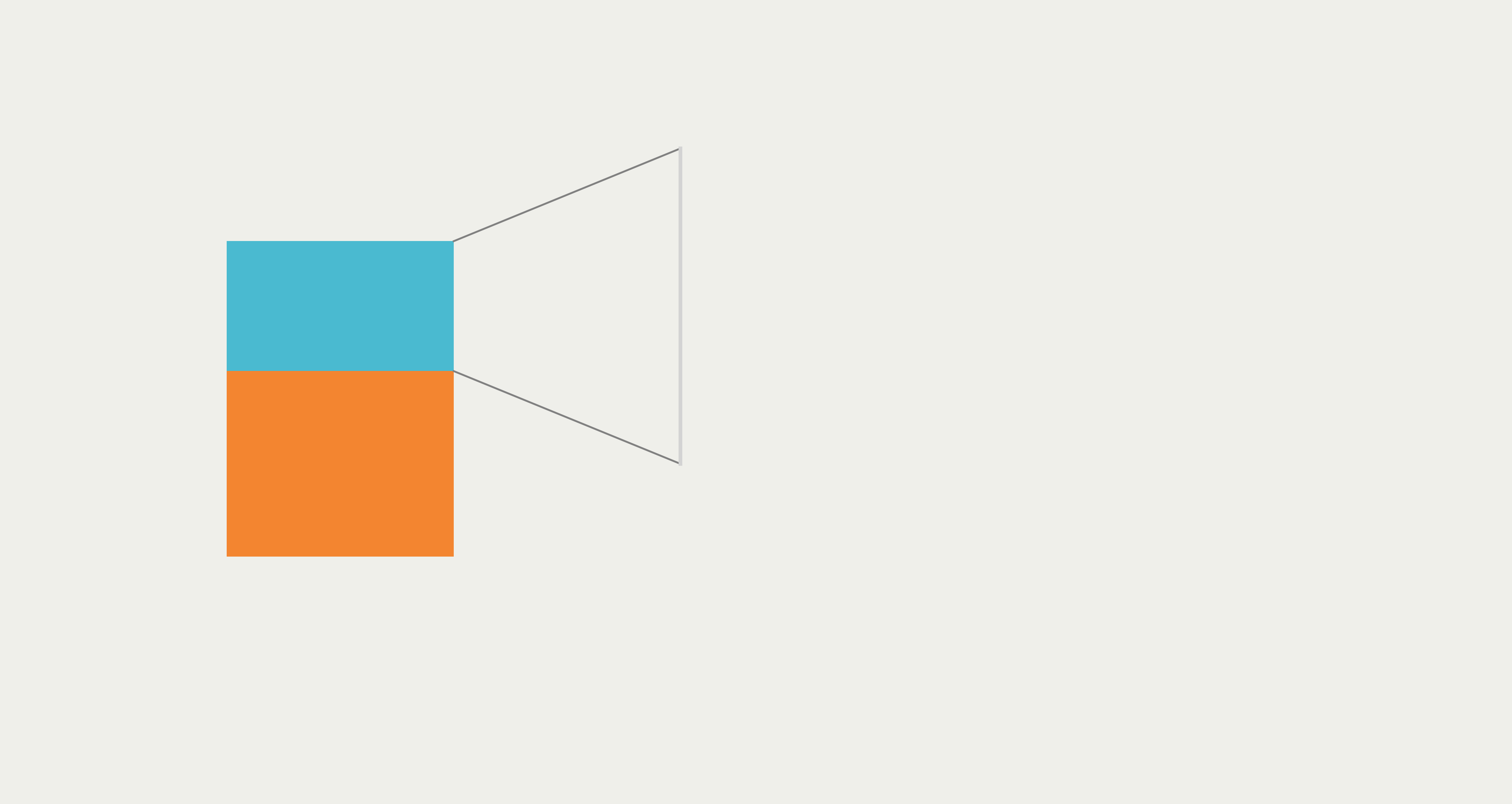
这样,我们就把最简单的左半边主要视觉元素组织好了。
2.2.2 右侧类桑基图部分
到了本文的核心内容——构造右侧类桑基图部分,为了便于之后的几何元素制作,我们先把原作品中右侧涉及的数据构造到数据框中:
import pandas as pd
data = pd.DataFrame({
'类型': ['Car', 'Freight', 'Street Lights', 'GO Train', 'BRT', 'Bus', 'Taxi', 'Motorcycle'],
'份额': [0.8628, 0.0933, 0.0005, 0.001, 0.0121, 0.0133, 0.0165, 0.0005]
})
data['份额累加'] = data['份额'].cumsum()
data.head()
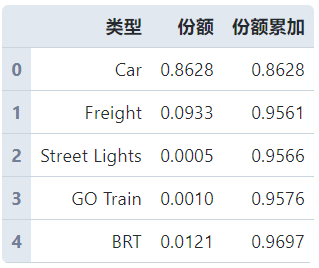
其中份额累加列的添加是为了方便之后组合几何元素。
首先我们来绘制右侧最上方的Car对应的矩形,因为这部分只是简单的矩形,在上一步的绘图代码中添加下列代码来更新图像:
height = 5.1e6 + 1.5e6 - (3e6 - 1.5e6)
# 右侧图形
# 最上方矩形
ax.add_patch(Rectangle((6e6, 3e6-1.5e6+0.1372*height),
0.8e7,
0.8628*height,
facecolor='#4ebcd1'))
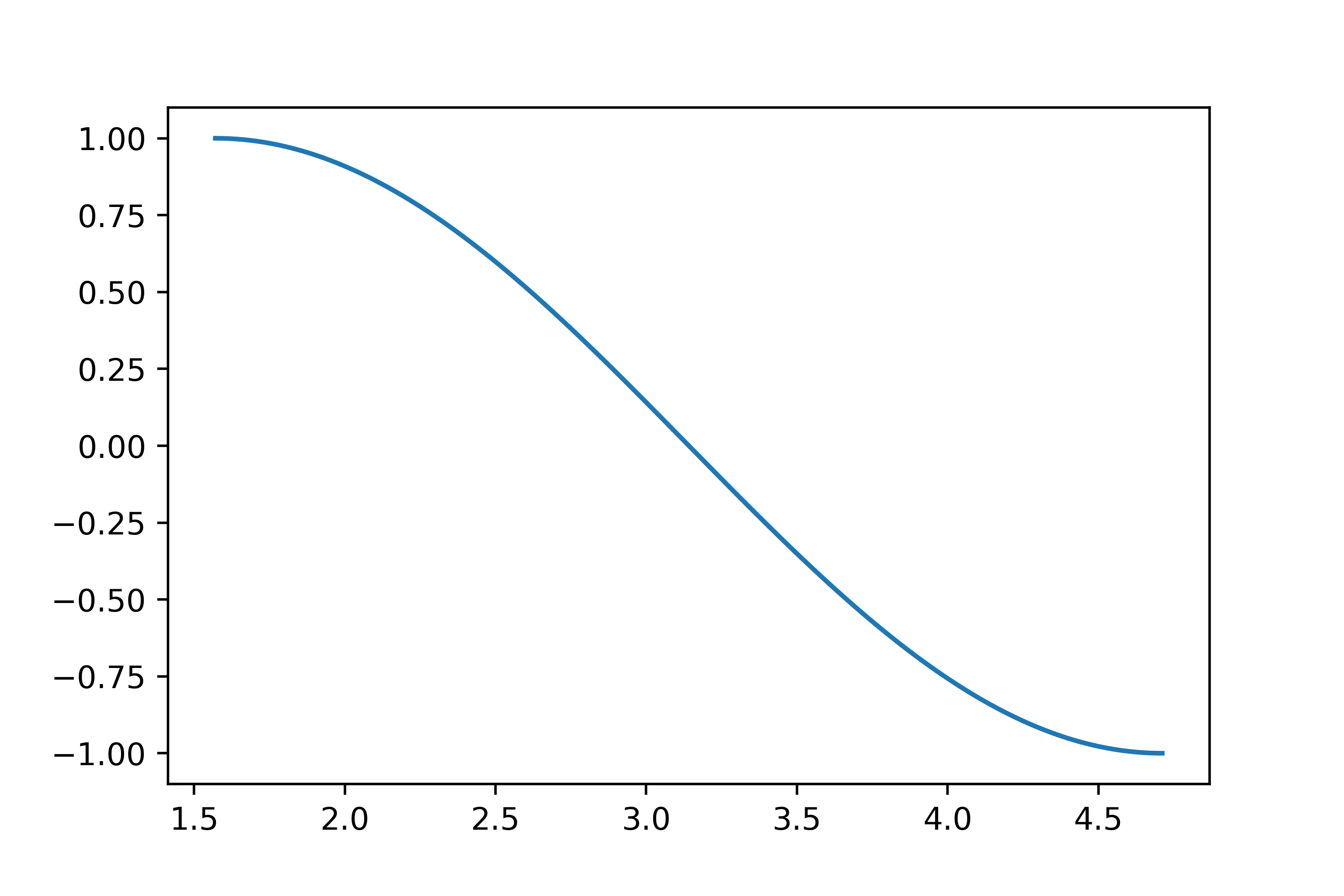
接下来我们来创建类桑基图部分,思路其实很简单,因为这部分内容与Sigmoid型函数对应的曲线是很接近的,譬如正弦函数在\(0.5\pi\)到\(1.5\pi\)之间的曲线:
根据这个特点,我们可以结合第1期中玩过的老把戏——线性变换,来辅助生成桑基条带。
我们从最上方矩形的下端开始,利用data中的份额与份额累加,以及\(0.5\pi\)到\(1.5\pi\)之间的标准正弦函数曲线,配合线性变换,来构造每个类别对应条带的上下边界,再配合matplotlib中的fill_between来完成条带的绘制。
首先我们来生成基础正弦函数采样点数据,以及线性变换函数:
x, y = np.arange(0.5*np.pi, 1.5*np.pi, 0.001), np.sin(np.arange(0.5*np.pi, 1.5*np.pi, 0.001))
def scale(xlim, ylim):
return (xlim[0] + (xlim[1] - xlim[0]) * (x - x.min()) / (x.max() - x.min()),
ylim[0] + (ylim[1] - ylim[0]) * (y - y.min()) / (y.max() - y.min()))
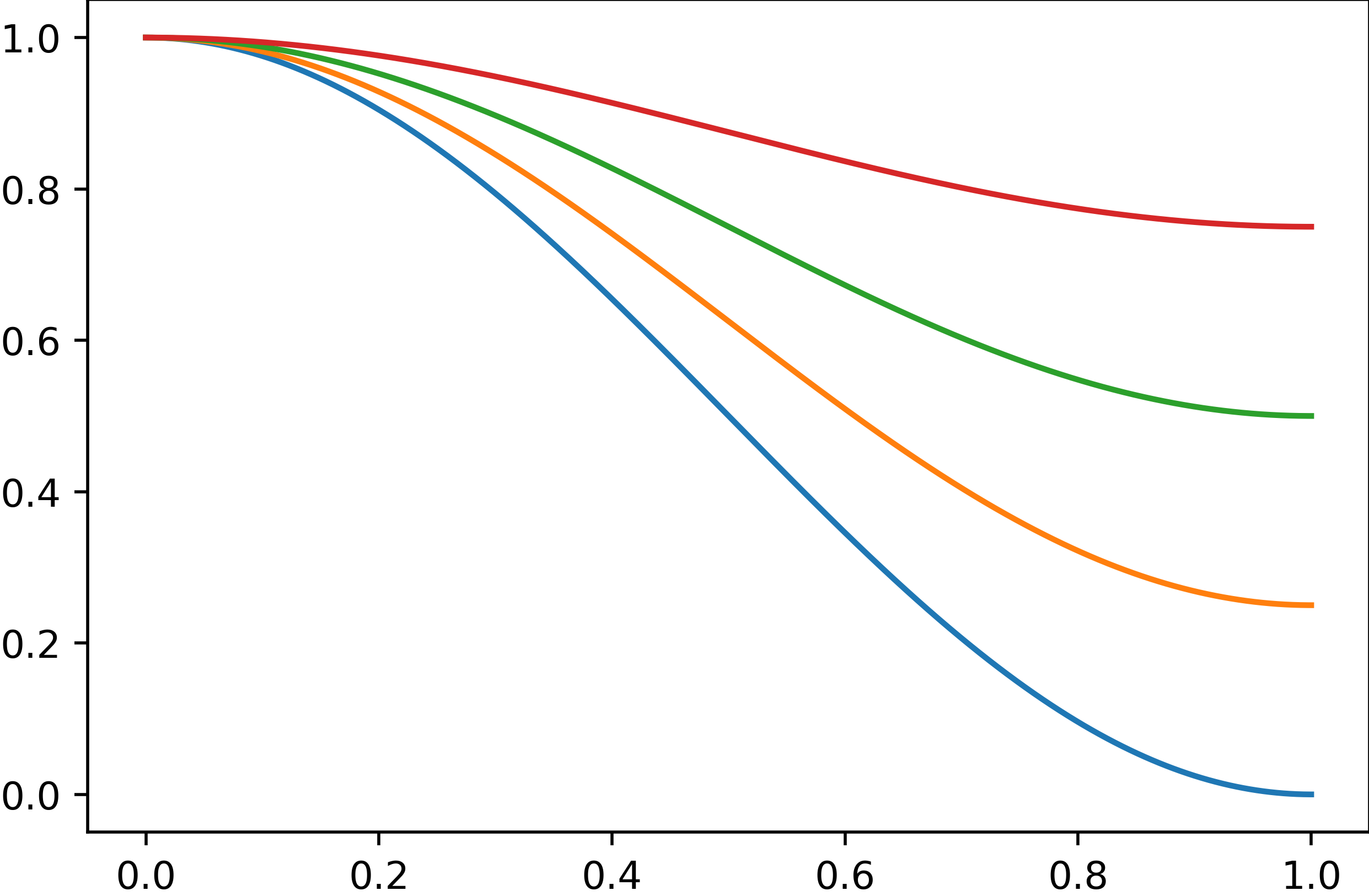
这样我们就可以在给定x范围,以及给定y范围的基础上,将标准的正弦函数曲线不同程度的“压扁”,就像下面的例子一样:
import numpy as np
x, y = np.arange(0.5*np.pi, 1.5*np.pi, 0.001), np.sin(np.arange(0.5*np.pi, 1.5*np.pi, 0.001))
def scale(xlim, ylim):
return (xlim[0] + (xlim[1] - xlim[0]) * (x - x.min()) / (x.max() - x.min()),
ylim[0] + (ylim[1] - ylim[0]) * (y - y.min()) / (y.max() - y.min()))
plt.plot(*scale((0, 1), (0, 1)))
plt.plot(*scale((0, 1), (0.25, 1)))
plt.plot(*scale((0, 1), (0.5, 1)))
plt.plot(*scale((0, 1), (0.75, 1)));
按照这个思想,我们结合份额与份额累加值,以两种色彩交错的方式构造条带:
# 生成每个条带的上下底
bands = [(scale(xlim=(6e6, 6e6+0.8e7),
ylim=(5.1e6+1.5e6-data.at[i, '份额累加']*height-(i+1)*7e8,
5.1e6+1.5e6-data.at[i, '份额累加']*height)),
scale(xlim=(6e6, 6e6+0.8e7),
ylim=(5.1e6+1.5e6-data.at[i, '份额累加']*height-data.at[i+1, '份额']*height-(i+1)*7e8,
5.1e6+1.5e6-data.at[i, '份额累加']*height-data.at[i+1, '份额']*height)))
for i in range(data.shape[0]-1)]
colors = ['#1b7d98', '#a5dce7']
for i, band in enumerate(bands):
if i % 2 == 0:
ax.fill_between(band[0][0], band[0][1], band[1][1], color='#1b7d98')
else:
ax.fill_between(band[0][0], band[0][1], band[1][1], color='#a5dce7')

这样子,我们就完成了原作品的主要视觉元素的复刻。
2.2.3 其他元素的补充
接下来的内容就比较简单,我们只需要把各种文字标注、分割线、刻度等小细节补上即可:
# 其它元素的补充
# y轴数值标签
for y_, text in zip([0, 2e6, 4e6, 6e6], ['0', '2M', '4M', '6M']):
ax.text(-1e6, y_, text, ha='right', color='grey', fontsize=8)
# 添加左侧矩形内部标注
ax.text(1.5e6, 1.5e6, 'Buildings 3M', color='white',
ha='center', fontsize=7, fontweight='bold')
ax.text(1.5e6, 3e6+1.05e6, 'Transportation 2.1M',
color='white', ha='center', fontsize=7, fontweight='heavy')
# 添加黑色Today标注
ax.text(1.5e6, -5e5, 'Today',
color='black', ha='center',
fontsize=10, family='Times New Roman')
# 添加右侧文字标注
ax.text(1.42e7, 4.5e6, 'Car 86.28%', fontsize=8, family='Times New Roman')
for i in range(data.shape[0]-1):
ax.text(1.42e7, 5.1e6+1.5e6-data.at[i, '份额累加']*height-data.at[i+1, '份额']*0.5*height-(i+1)*7e5,
'{} {}%'.format(data.at[i+1, '类型'], round(data.at[i+1, '份额']*100, 2)),
va='center', fontsize=8, family='Times New Roman')
# 添加y轴标题
ax.text(-2.2e6, 3.3e6, 'Annual Metric Tons of $CO_{2}$eq Emissions',
rotation=90, va='center', fontsize=7.8)
# 上部分隔线
ax.plot([-2.3e6, 1.65e7], [9e6, 9e6], color='#327997', linewidth=0.7)
# 上部黑色说明文字
ax.text(-2.3e6,
7.9e6,
"40% of Mississauga's GHG emissions come from the transportation sector including freight. Less than 3% of these emissions currently come from \npublic transit.",
fontsize=7.9,
style='italic')
# 上部标题
ax.text(-2.3e6, 9.2e6, 'GHG Emissions - Transportation',
color='#327997', fontweight='heavy')
经过这一番操作,最终的结果如图10所示:
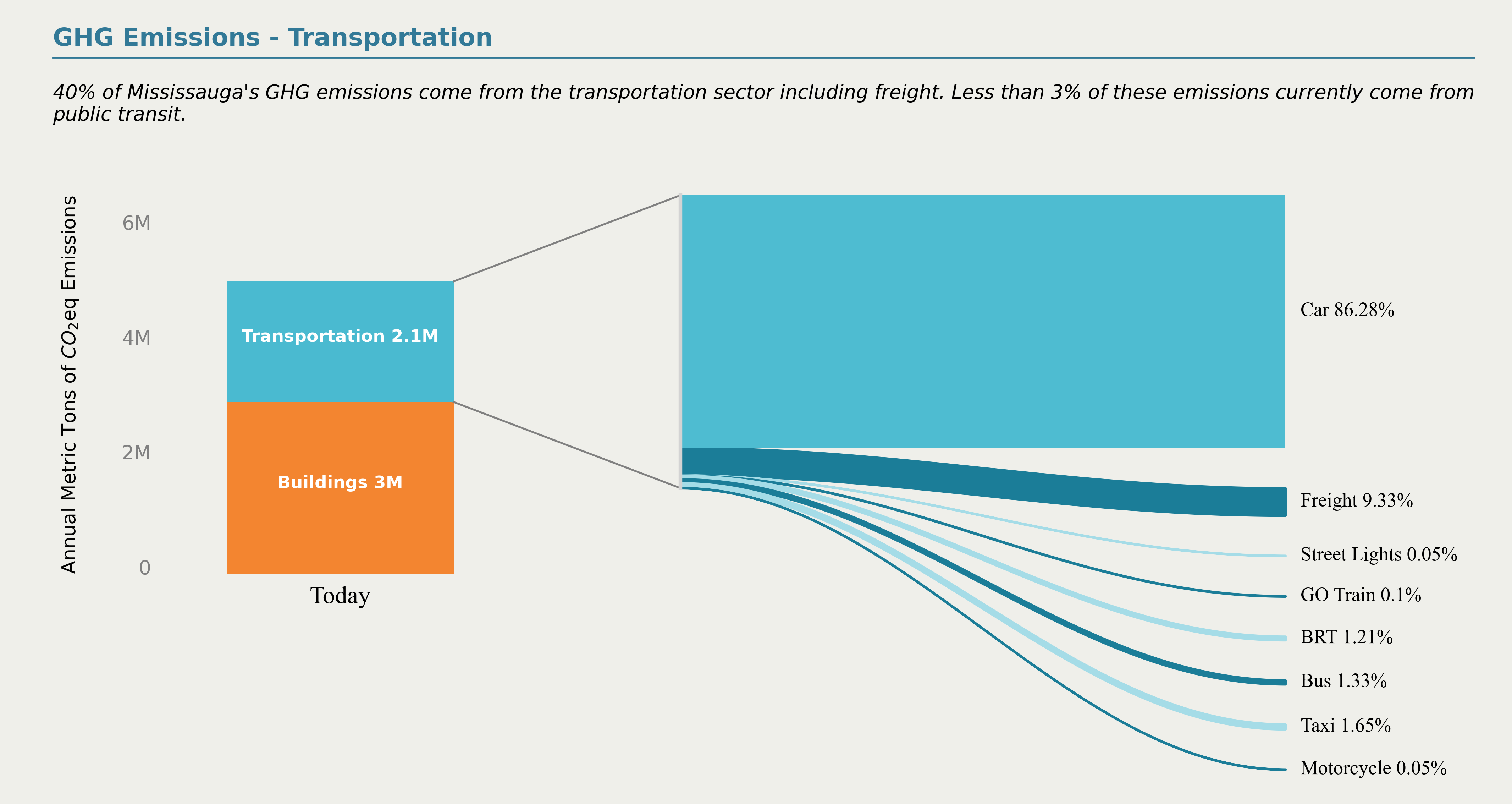
而原作品中右侧并没有按照比例的降序排列,如果你想降序排列,只需要在创建data之后对数据框按照份额降序并重置index即可~,降序排列后再绘制的效果如图11所示:
是不是舒服自然了很多了呢~
以上就是本文的全部内容,欢迎在评论区与我进行讨论~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号