C++ 原子操作
内存屏障,也称为内存栅栏、内存栅障或屏障指令,是一类同步屏障指令。它是CPU或编译器在对内存随机访问的操作中的一个同步点,确保此点之前的所有读写操作都执行完毕后,才可以开始执行此点之后的操作。
1)原子性(Atomicity):
原子性是指一个或多个操作作为一个整体来执行,中途不会被其他线程打断。在多线程环境中,原子性确保一个操作要么完全执行,要么完全不执行,不会出现只执行一部分的情况。这有助于避免线程间的数据竞争和不一致状态。
2)可见性(Visibility):
可见性是指当一个线程修改共享变量的值后,其他线程能够立即看到这个修改。由于多线程环境中的缓存和内存模型,一个线程对共享变量的修改可能不会立即对其他线程可见。可见性确保线程之间的共享数据始终保持一致,从而防止数据不一致和线程安全问题。
3)有序性(Ordering):
有序性指的是在多线程环境中,操作执行的顺序。由于不同的线程可能并发执行,因此操作的执行顺序可能不是按照代码书写顺序来发生的。C++内存模型定义了不同的内存序(memory order),这些内存序决定了原子操作的顺序以及非原子操作的顺序
C++内存序:

| 序号 | 值 | 中文说法 | 含义 |
| 1 | memory_order_relaxed | 宽松型内存序 | 不提供任何同步保证,只保证原子操作本身是原子的。 |
| 2 | memory_order_consume | 消费型内存序 | 用于同步依赖关系,保证依赖于原子操作结果的后续操作按顺序执行(在该原子操作之后执行)。 |
| 3 | memory_order_acquire | 获取内存序 | 用于同步对共享数据的访问,保证在该点(获取操作)之后,对共享数据的所有读取操作都将看到最新的数据。保证在该点之后的, 所有共享数据的读操作不会被重排序到该点之前 after is after |
| 4 | memory_order_release | 释放内存序 |
用于同步对共享数据的访问,保证在该点(释放数据)之前,对共享数据的所有写入操作都已完成,并且对其他线程可见(写入一致性缓存:L2Cache)。 保证在该点之前的,所有共享数据的写入不会被重排序到该点之后。 before is before 备注: 对于多个原子变量的store/release, 不能保证其他内核,拿到的都是最新的值(内核一级缓存的旧值)。 原因见第6条。 |
| 5 | memory_order_acq_rel | 获取-释放内存序 |
当前线程中,同时满足memory_order_acquire和memory_order_release。 |
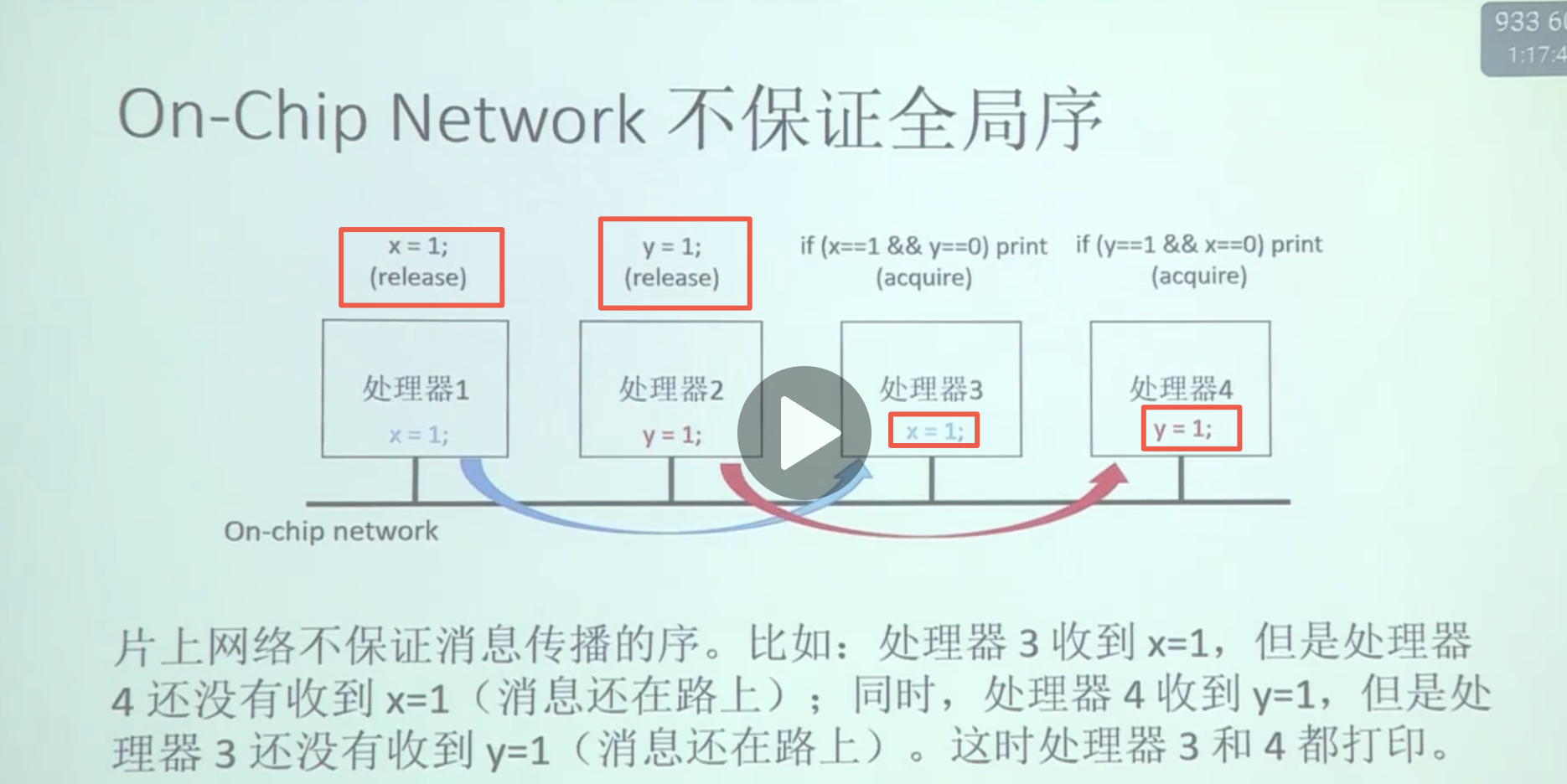
| 6 | memory_order_seq_cst | 顺序一致性内存序 | 最强约束。保证所有线程都有相同的操作顺序,并且保证全局有序。 这里的全局有序,是指多个原子变量(x, y)的写有序。
例子:1)内核1将x写入cpu一致性缓存 2)内核2将y写入cpu一致性缓存 3)内核1广播通知其他核x更新了并且收到应答 4) 内核2广播通知其他核y更新了并且收到应答。 有序:指的是广播通知有序,保证一个原子变量的更新,通知到其他全部内核后,才会开始下一个通知。
|


std::atomic 成员函数的概述:
| 成员函数 | 描述 | 参数 | 返回值 |
|---|---|---|---|
std::atomic<T>() noexcept = default; |
默认构造函数 | 无 | 无 |
constexpr atomic(T val) noexcept; |
初始化构造函数 | T val(初始化值) |
无 |
T load(std::memory_order order = std::memory_order_seq_cst) const noexcept; |
原子加载值 | |
当前值 |
void store(T val, std::memory_order order = std::memory_order_seq_cst) noexcept; |
原子存储值 | T val(要存储的值) |
无 |
T exchange(T val, std::memory_order order = std::memory_order_seq_cst) noexcept; |
原子交换值 | T val(新值) |
交换前的值 |
bool compare_exchange_strong(T& expected, T val, std::memory_order order1, std::memory_order order2) noexcept; |
原子比较并交换(强版本) | T& expected(预期值),T val(新值) |
是否成功交换 |
bool compare_exchange_weak(T& expected, T val, std::memory_order order1, std::memory_order order2) noexcept; |
原子比较并交换(弱版本) | 同上 | 是否成功交换 |
T fetch_add(T val, std::memory_order order = std::memory_order_seq_cst) noexcept; |
原子加法并返回旧值 | T val(要加的数值) |
操作前的值 |
T fetch_sub(T val, std::memory_order order = std::memory_order_seq_cst) noexcept; |
原子减法并返回旧值 | 同上 | 操作前的值 |
T fetch_and(T val, std::memory_order order = std::memory_order_seq_cst) noexcept; |
原子按位与并返回旧值 | 同上 | 操作前的值 |
T fetch_or(T val, std::memory_order order = std::memory_order_seq_cst) noexcept; |
原子按位或并返回旧值 | 同上 | 操作前的值 |
T fetch_xor(T val, std::memory_order order = std::memory_order_seq_cst) noexcept; |
原子按位异或并返回旧值 | 同上 | 操作前的值 |
bool is_lock_free() const noexcept; |
检查是否是无锁操作 | 无 | 如果是无锁操作,返回 true;否则返回 false |
++ --等 |
#include <atomic>
std::atomic<int> flag = ATOMIC_VAR_INIT(0);
std::atomic<int> data;
void writer_thread() {
data.store(42, std::memory_order_relaxed);
flag.store(1, std::memory_order_release); // 释放内存屏障
}
void reader_thread() {
while (!flag.load(std::memory_order_acquire)) { // 获取内存屏障
// spin-wait
}
int value = data.load(std::memory_order_relaxed);
// 此时可以确保看到writer_thread中data的写操作
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号