梯度下降法和随机梯度下降法
1. 梯度
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T,简称grad f(x,y)或者▽f(x,y)。对于在点(x0,y0)的具体梯度向量就是(∂f/∂x0, ∂f/∂y0)T.或者▽f(x0,y0),如果是3个参数的向量梯度,就是(∂f/∂x, ∂f/∂y,∂f/∂z)T,以此类推。
那么这个梯度向量求出来有什么意义呢?他的意义从几何意义上讲,就是函数变化增加最快的地方。具体来说,对于函数f(x,y),在点(x0,y0),沿着梯度向量的方向就是(∂f/∂x0, ∂f/∂y0)T的方向是f(x,y)增加最快的地方。或者说,沿着梯度向量的方向,更加容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是 -(∂f/∂x0, ∂f/∂y0)T的方向,梯度减少最快,也就是更加容易找到函数的最小值。
2.梯度下降法
什么是梯度下降法呢/
举个例子,我们在下山的时候,如果山中浓雾太大,而且我们有不清楚路线,那我们可以以当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
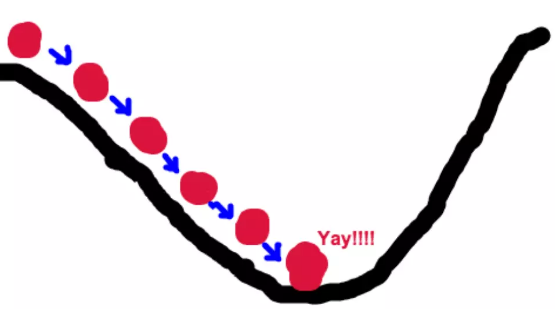
梯度下降法的过程与这个例子很相似,一个函数可微分。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向,所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。
什么是梯度:
一个多元函数的梯度方向是该函数值增大最陡的方向。具体化到1元函数中时,梯度方向首先是沿着曲线的切线的,然后取切线向上增长的方向为梯度方向,2元或者多元函数中,梯度向量为函数值f对每个变量的导数,该向量的方向就是梯度的方向,当然向量的大小也就是梯度的大小。
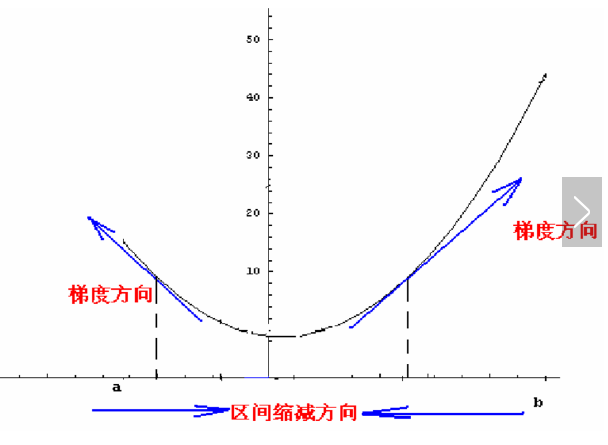
梯度下降法详解:
对于一个多元函数j(x),在x点处做线性逼近(求一阶导数)
j(x+x0)=j(x)+Δ'(x)*øj(x0)+o(无穷小),其中øj(x0)为j(x0)的倒数;
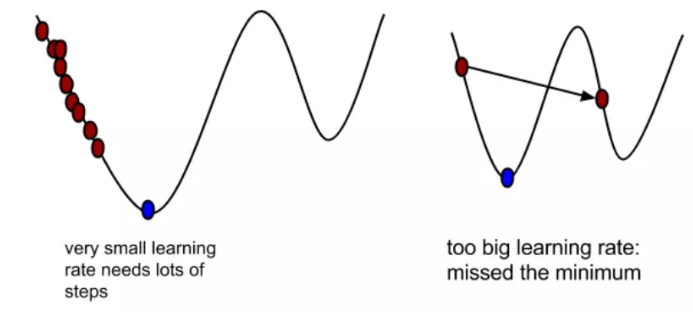
对于一个函数做了线性逼近,可以判断在x这个点的增加方向和减小方向;虽然做线线逼近不能告诉我们这个函数的极值点在什么地方,但能告诉我们极值点在什么方向,因此我们可以根据这个方向(即下山的方向)选取一个较小的步长(学习率)来沿着这个方向走下去,找到极值点。
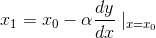
J是关于x的一个函数,我们当前所处的位置为x0点,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是α,走完这个段步长,就到达了x1这个点!

几种梯度下降法介绍
批量梯度下降法(Batch Gradient Descent)
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新,这个方法对应于前面3.3.1的线性回归的梯度下降算法,也就是说3.3.1的梯度下降算法就是批量梯度下降法。
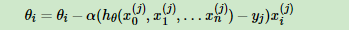
由于我们有m个样本,这里求梯度的时候就用了所有m个样本的梯度数据。
随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。对应的更新公式是:
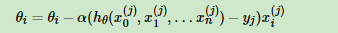
随机梯度下降法,和4.1的批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
那么,有没有一个中庸的办法能够结合两种方法的优点呢?有!这就是4.3的小批量梯度下降法。
小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个样子来迭代,1<x<m。一般可以取x=10,当然根据样本的数据,可以调整这个x的值。对应的更新公式是:
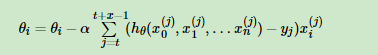
下面谈谈随机梯度下降法;
这种方法主要是解决梯度计算的问题,上面谈到梯度计算很困难就是因为样本大那随机梯度下降法只计算一个样本;


简要谈一谈鞍点,如图
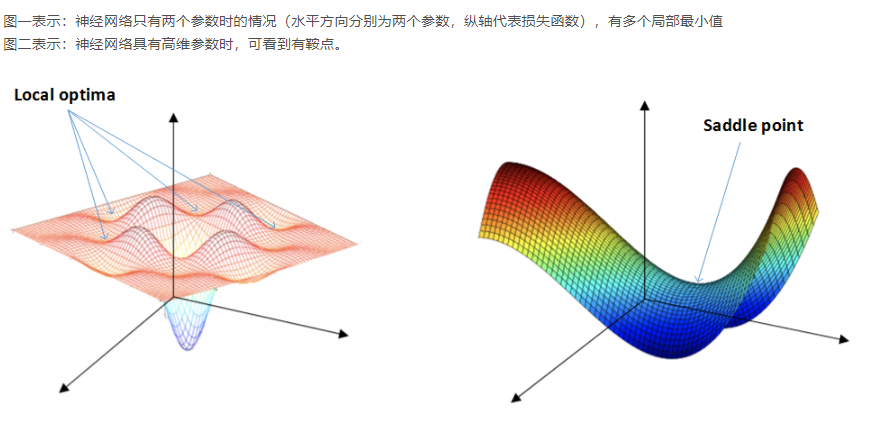
鞍点(saddle point)这个词来自 z=x^2-y^2的图形,在x轴方向向上曲,在y轴方向向下曲,像马鞍,鞍点为(0,0)。
拥有两个以上参数的函数。它的曲面在鞍点好像一个马鞍,在某些方向往上曲,在其他方向往下曲。在一幅等高线图里,一般来说,当两个等高线圈圈相交叉的地点,就是鞍点。
由于只是初学,简要了解一下什么是梯度下降法;以后在有机会再深入探讨;
本文参考:
1. 鞍点参考原文:https://blog.csdn.net/baidu_27643275/article/details/79250537
2.梯度下降参考原文:https://www.cnblogs.com/pinard/p/5970503.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号