OpenStack G版以后的Availability Zone与Aggregate Hosts
关于Availability Zone与Aggregate Hosts的概念解析,可以参考这篇文章:http://blog.chinaunix.net/uid-20940095-id-3875022.html
1. availability zone
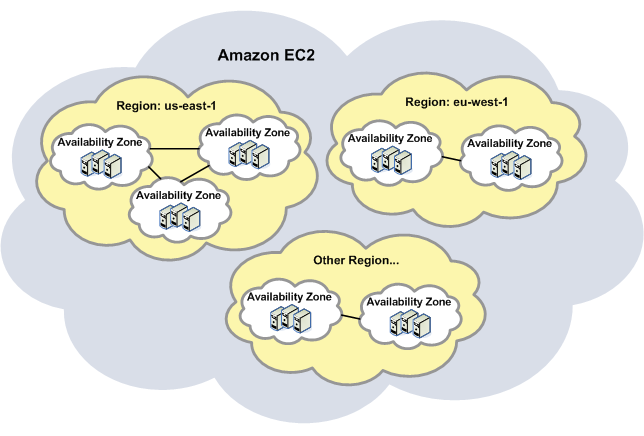
az是在region范围内的再次切分,只是工程上的独立,例如可以把一个机架上的机器划分在一个az中,划分az是为了提高容灾性和提供廉价的隔离服务。选择不同的region主要考虑哪个region靠近你的用户群体,比如用户在美国,自然会选择离美国近的region;选择不同的az是为了防止所有的instance一起挂掉,下图描述了二者之间的关系。
catalog其实是分级的 <catalog>.<region>.<service>.<endpoint>,第二级的region就是上文提到的region。在这里我们可以设置不同的region和不同的service的endpoint。horizon只提取keystone中catalog的regionOne中的endpoint,所以,即使设置了多个region,horizon也体现不出来。
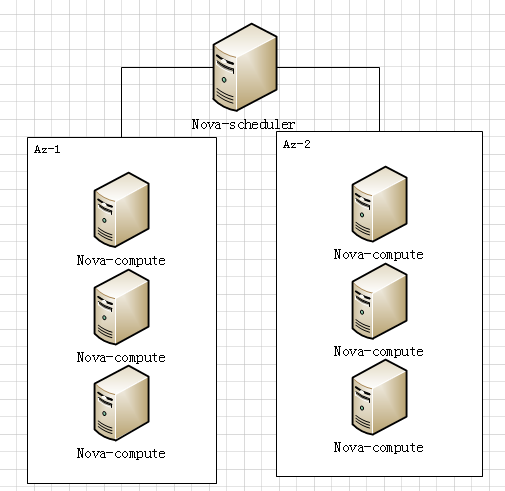
az在openstack中其实是nova-scheduler来实现的,当新建虚拟机,调度器将会根据nova-compute设置的az来调度,例如在新建虚拟机的时候,用户设置了希望将虚拟机放在az-1中,那么调度器将会选择属于这个az的nova-compute来调度,如下图所示。
2. Aggregate Hosts
Availability zones are a customer-facing capability, host aggregates are meant to be used by administrators to separate hardware by particular properties, and are not seen by customers.
az是一个面向终端客户的概念和能力,而host aggregate是管理员用来根据硬件资源的某一属性来对硬件进行划分的功能,只对管理员可见。
其主要功能就是实现根据某一属性来划分物理机,比如按照地理位置,使用固态硬盘的机器,内存超过32G的机器,根据这些指标来构成一个host group。
nova aggregate-create joesservers chicago
Host aggregate可以用来进一步细分availability zone。
通过以上分析,问题就来了:availability zone和host aggregate都能对host machine进行划分,那么二者的区别是啥?
az是用户可见的,用户手动的来指定vm运行在哪些host上,即用户可见;Host aggregate是一种更智能的方式,是调度器可见的,影响调度策略的一个表达式
3.Openstack 中如何指定那些computer节点属于同一availability zone?
在G版以前,当我们用nova-manage service list 查看nova服务启动的状态的时候,即看status是笑脸还是XX,其实是通过一个循环任务report_state,循环地向数据库service表中写入信息,比如一个计数report_count以及更新该记录的时间。而判断该服务状态时,就会读取Service表,看当前时刻与该服务上次更新的时间的差值是否在允许的范围内(配置项service_down_time),如果超出了service_down_time,就认为该服务状态异常。所以,总结一下,一个服务状态是XXX的原因,要么是该服务出现了异常,要么是时间不同步导致。
需要注意的是,在report_state中,除了report_count,还有一个更新的字段:availability_zone。该字段来源于配置项node_availability_zone。举个例子,一个nova-compute服务,它的Availability Zone就依赖于配置文件中的node_availability_zone配置项。同时,一个nova-compute仅属于一个AZ。还有一点要注意,我们创建aggregate时也可以指定Availability Zone,然后向aggregate中添加主机时,要求主机的zone与aggregate的zone一致。
因此,总结如下:每一个computer node的属于哪一个AZ,是通过nova.conf中的node_availability_zone配置项来指定,一个nova-compute仅属于一个AZ,并且创建Aggregate指定的AZ,在向其添加host的时候,应与host原属的AZ与其一致。
但是从G版开始以后的版本,比如我现在所用的H版里头,nova.conf里面就没有node_availability_zone的配置字段,虽然还留有一个default_availability_zone的配置项,但仅在nova-api节点起作用。因此在这个时候,如果想用户起虚拟机的时候能指定AZ,或将某一个compute node指定成一个AZ,该如何操作了?
G版中对服务的管理增加了很多方式,可以是老的更新数据的方式(如果节点不多,可以使用这种,不会对数据库造成大的压力),但如果节点较多,使用数据库的方式就不太明智了,此时可以选择效率较高的memcached或者zookeeper。于是,Service表中也不再保存availability_zone字段,配置项node_availability_zone也不再使用。
G版中,默认情况下,对Nova服务分为两类,一类是controller节点的服务进程,如nova-api, nova-scheduler, nova-conductor等;另一类是计算节点进程,nova-compute。对于第一类服务,默认的zone是配置项internal_service_availability_zone,而nova-compute所属的zone由配置项default_availability_zone决定。(这两个配置项仅在nova-api的节点起作用,horizon界面才会刷新)
可能是社区的开发人员意识到,让管理员通过配置的方式管理zone不太合适,不够灵活,所以在G版中将这一方式修改。就改用nova aggregate-create 命令,在创建一个aggregate的同时,指定一个AZ。
root@controller:~# nova help aggregate-create usage: nova aggregate-create <name> [<availability-zone>] Create a new aggregate with the specified details. Positional arguments: <name> Name of aggregate. <availability-zone> The availability zone of the aggregate (optional).
因此创建一个aggregate后,同时把它作为一个zone,此时aggregate=zone。因为大家知道,aggregate是管理员可见,普通用户不可见的对象,那么这个改变,就可以使普通用户能够通过使用zone的方式来使用aggregate。
创建完aggregate之后,向aggregate里加主机时,该主机就自动属于aggregate表示的zone。
在G版之后,可以认为aggregate在操作层面与AZ融合在一起了,但同时又不影响aggregate与flavor的配合使用,因为这是两个调度层面。同时又要注意,一个主机可以加入多个aggregate中,所以G版中一个主机可以同时属于多个Availability Zone,这一点也与之前的版本不同。
4.实际测试使用
1. 创建aggregate,指定zone
#nova aggregate-create Aggregate1 az1
#nova aggregate-list
2.添加主机
#nova aggregate-add-host Aggregate1 computer1
3. 查询主机与服务所属的zone
#nova host-list
#nova service-list
4. 再将主机加入另一个aggregate,再次查询
#nova aggregate-create Aggregate2 az2
#nova aggregate-add-host Aggregate2 computer1
#nova host-list
#nova service-list
本文后部分内容参考来源:【OpenStack】F版和G版中的Availability Zone:http://blog.csdn.net/lynn_kong/article/details/9012451
更多精彩内容,敬请访问上一条链接!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号