
ThreaLocal三部曲之——ThreadLocal相关
ThreaLocal大法广泛应用于各大开源框架,大家最熟悉的spring中就有大量运用。相比synchonzied机制的时间换空间,ThreaLocal则倾向于用空间换时间。阅读jdk源码可知,threadLocal实现各线程副本变量的方式,是jdk在每个Thread类中,都引入了一个threadLocalMap参数,实际上我们调用threadLocal的set方法时,就是把需要存储的值放到了当前线程的threadLocalMap中。
一、ThreaLocal
ThreadLocal类接口很简单,主要使用的只有4个方法,我们先来了解一下:
- void set(Object value)设置当前线程的线程局部变量的值。内部实际调用了内部类threadLocalMap的set方法
- public Object get()该方法返回当前线程所对应的线程局部变量。内部实际调用threadLocalMap的getEntry方法
- public void remove()将当前线程局部变量的值删除,内部是及调用threadLocalMap的remove方法
- protected Object initialValue()返回该线程局部变量的初始值,该方法是一个protected的方法,显然是为了让子类覆盖而设计的。这个方法是一个延迟调用方法,在线程第1次调用get()或set(Object)时才执行,并且仅执行1次。ThreadLocal中的缺省实现直接返回一个null。
二、关于内存泄漏
聊到threadLocal可能引发的内存泄漏,习惯性甩锅给threadLocalMap中Entry的key值的弱引用,但我们讲道理,这个锅和弱引用没有一毛钱关系,一个ThradeLocal的内存模型图如下:
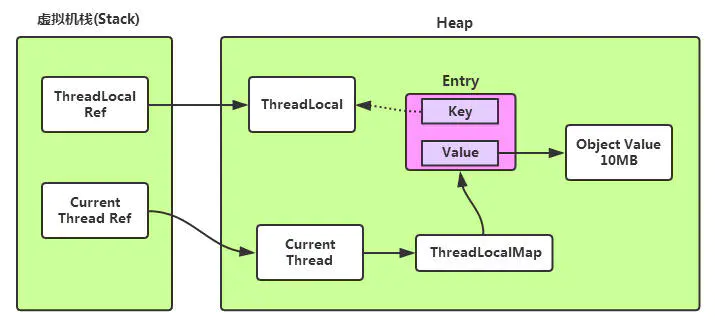
上图中,threadLocal自身引用清空的时候,由于当前线程还持有一个threadLocals的threadLocalMap对象,而此对象中实际存储一个Entry数组,同时Entry的的key值指向ThradLocal对象,此时就算key是强引用,只要当前线程不被回收,那么threadLocalMap在可达性分析中永远可达,此时永远不会被回收。
引起内存泄漏的不是弱引用,而是引入threadLocal的线程很多时候不会被回收(举个例子,tomcat处理请求时其实是开了个线程池反复使用,此处还会引入分布式缓存本地存储使用ThreadLocal,不及时romove引发同一个thread重入缓存错误的坑)
那么我们再聊聊弱引用的好处,threadlocal本身不可达被回收时,key值会在下一次gc被回收,然后针对当前线程的threadLocals任意操作,都可能会清空这个key值为null的value,下面我们看下jdk如何做到这一点。
三、ThreaLocalMap
根据上文分析,我们可以知道实际threadlocal的get,set,remove方法,真正调用执行的还是threadLocalMap中的对应方法,我们接下来看一下threadLocalMap中对应的三种方法:
3.1 get方法
private Entry getEntry(ThreadLocal<?> key) { // 获取数组中的位置 int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) // 不为空则返回 return e; else // 为空时重新遍历 return getEntryAfterMiss(key, i, e); }
我们再看下getEntryAfterMiss的源码
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length // 遍历 while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) // 寻址成功,返回 return e; if (k == null) // 处理key被回收的value expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null; }
expungeStaleEntry方法也很巧妙,我们先看源码
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; //清除当前脏entry tab[staleSlot].value = null; tab[staleSlot] = null; size--; // Rehash until we encounter null Entry e; int i; //2.往后环形继续查找,直到遇到table[i]==null时结束 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); //3. 如果在向后搜索过程中再次遇到脏entry,同样将其清理掉 if (k == null) { e.value = null; tab[i] = null; size--; } else { //处理rehash的情况 int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; // Unlike Knuth 6.4 Algorithm R, we must scan until // null because multiple entries could have been stale. while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; }
这里主要是清楚当前脏数据,然后向后以log2(n')的长度继续查找脏数据(key弱引用被回收),找到脏数据,则再次清楚,并扩大长度,继续向后log2(n')清理脏数据。
3.2 set方法
private void set(ThreadLocal<?> key, Object value) Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1) // 遍历 for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get() if (k == key) { e.value = value; return; if (k == null) { // 替换 replaceStaleEntry(key, value, i); return; } tab[i] = new Entry(key, value); int sz = ++size; // 清理key为空的value if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }
我们先看下cleanSomeSlots方法的源码
private boolean cleanSomeSlots(int i, int n) { // 是否成功清理脏数据 boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; // 同get方法中的清理指定位置脏数据 i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed; }
接下来我们看下replaceStaleEntry方法
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e; // 向前找到第一个正常entry,作者认为一个脏数据前很可能有其他脏数据 int slotToExpunge = staleSlot; for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i; for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); if (k == key) { //如果在向后环形查找过程中发现key相同的entry就覆盖并且和脏entry进行交换 e.value = value; tab[i] = tab[staleSlot]; tab[staleSlot] = e; //如果在查找过程中还未发现脏entry,那么就以当前位置作为cleanSomeSlots的起点 if (slotToExpunge == staleSlot) slotToExpunge = i; //搜索脏entry并进行清理 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } //如果向前未搜索到脏entry,则在查找过程遇到脏entry的话,后面就以此时这个位置作为起点执行celanSomeSlots if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } //如果在查找过程中没有找到可以覆盖的entry,则将新的entry插入在脏entry tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value); if (slotToExpunge != staleSlot) //执行cleanSomeSlots cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); }
更多set相关,可以参考下文,讲解很详细,本文不赘述:https://www.jianshu.com/p/dde92ec37bd1
3.3 romove方法
分析完get与set方法后,我们会发现remove方法是送分题,上源码:
private void remove(ThreadLocal<?> key) { Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { if (e.get() == key) { // 清空引用的key e.clear(); // 清理指定位置的value,get方法中已描述 expungeStaleEntry(i); return; } } }
