
软工实践第二次作业
GitHub地址 :
https://github.com/fblogy/PersonProject-C2
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 50 |
| • Estimate | • 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 660 | 600 |
| • Analysis | • 需求分析 (包括学习新技术) | 100 | 70 |
| • Design Spec | • 生成设计文档 | 30 | 20 |
| • Design Review | • 设计复审 | 20 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 270 | 250 |
| • Code Review | • 代码复审 | 60 | 50 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | 90 | 80 |
| • Test Repor | • 测试报告 | 40 | 40 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 40 | 30 |
| 合计 | 800 | 730 |
计算模块接口的设计与实现过程
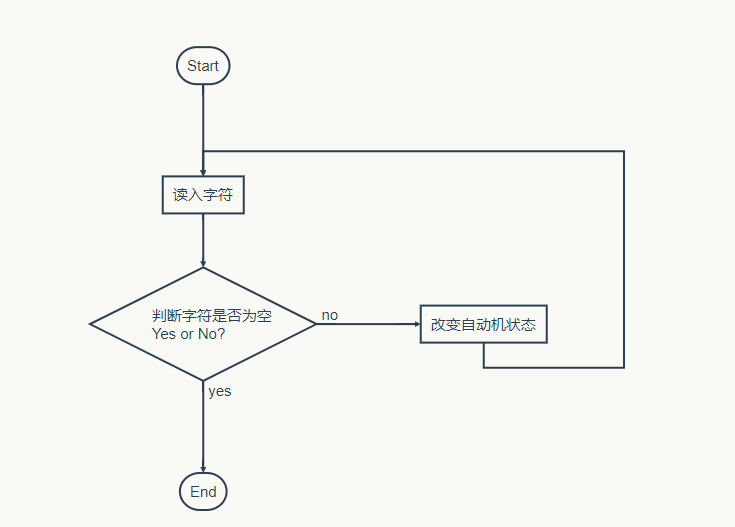
我的计算模块设计是打算使用有穷自动机来实现,对读入的每一个字符做一次判断,然后转移状态。
我设计的自动机有7个状态
-2 :非单词
-1 :遇到换行
0 : 遇到分割符
1, 2, 3, 4 : 开头的字母长度
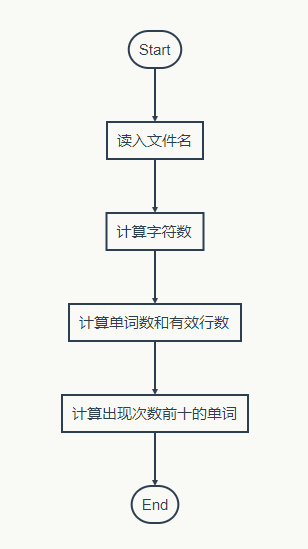
我所需要的设计的函数有三个,对应需求的三种功能。
我这种做法的独特之处是对所有要实现的功能其实逻辑是基本一样的,而且复杂度也比较低,是O(n)的,感觉应该属于比较好的做法了。
以下是自动机转移的代码
int now = -1, ch;
while (ch = getchar()) {
if (ch == -1) { if (now >= 4) add(s, Map); break; }
if (ch > 128) continue;
if (ch == '\n') { if (now >= 4) add(s, Map); s = ""; now = -1; continue; }
if (ch >= 'A' && ch <= 'Z') ch -= 'A' - 'a';
if (now == -2) { if (!checkword(ch) && !checknumber(ch)) now = 0; continue; }
if (checkword(ch)) { if (now == -1) now = 1; else now++; s += ch; continue; }
if (checknumber(ch)) {
if (now == -1) now = -2;
else if (now >= 4) now++, s += ch;
else now = -2, s = "";
continue;
}
if (now >= 4) add(s, Map); s = ""; now = 0;
}
计算模块接口部分的性能改进
一开始测试有1e7个字符的随机文本时要花很多时间,后来考虑到只要求前10频繁出现的单词就可以了,所以不用对所有的单词排序,只要对前10大排序即可。
以及可以把统计单词的map改为unordered_map,减少时间花费。
性能分析


可以看出,程序时间消耗主要是在统计前十频率的单词上,且主要是统计的过程中把单词这个字符串和出现次数用unordered_map映射关联起来这个部分,但是这是我想到的比较快而且好写的数据存储结构了,而且这部分会成为性能瓶颈在写之前我就已经想到了,性能改进部分我主要在代码实现前完成了。
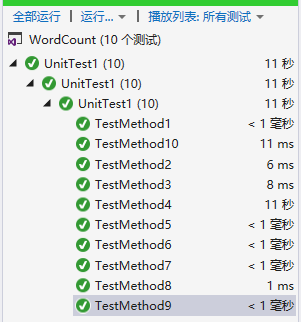
计算模块部分单元测试展示
#include "stdafx.h"
#include "CppUnitTest.h"
#include "../WordCount/core.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace UnitTest1
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test1.txt"); //获取文件名
int count_chars = CountChar(name);
Assert::AreEqual(count_chars, 3);
}
TEST_METHOD(TestMethod2)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test2.txt");
pii count_words = CountWord(name);
Assert::AreEqual(count_words.fi, 94);
}
TEST_METHOD(TestMethod3)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test3.txt");
vector<pair<string, int> > word_rank = CountFrequentWord(name);
Assert::AreEqual(word_rank[0].fi, string("image"));
Assert::AreEqual(word_rank[0].se, 4);
Assert::AreEqual(word_rank[1].fi, string("systems"));
Assert::AreEqual(word_rank[1].se, 4);
Assert::AreEqual(word_rank[2].fi, string("detection"));
Assert::AreEqual(word_rank[2].se, 3);
Assert::AreEqual(word_rank[3].fi, string("object"));
Assert::AreEqual(word_rank[3].se, 3);
Assert::AreEqual(word_rank[4].fi, string("accurate"));
Assert::AreEqual(word_rank[4].se, 2);
Assert::AreEqual(word_rank[5].fi, string("classifier"));
Assert::AreEqual(word_rank[5].se, 2);
Assert::AreEqual(word_rank[6].fi, string("fast"));
Assert::AreEqual(word_rank[6].se, 2);
Assert::AreEqual(word_rank[7].fi, string("human"));
Assert::AreEqual(word_rank[7].se, 2);
Assert::AreEqual(word_rank[8].fi, string("like"));
Assert::AreEqual(word_rank[8].se, 2);
Assert::AreEqual(word_rank[9].fi, string("locations"));
Assert::AreEqual(word_rank[9].se, 2);
}
TEST_METHOD(TestMethod4)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test4.txt");
int count_chars = CountChar(name);
pii tmp = CountWord(name);
int count_words = tmp.fi;
int count_lines = tmp.se;
vector<pair<string, int> > word_rank = CountFrequentWord(name);
Assert::AreEqual(count_chars, 10000000);
}
TEST_METHOD(TestMethod5)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test5.txt");
int count_lines = CountWord(name).se;
Assert::AreEqual(count_lines, 3);
}
TEST_METHOD(TestMethod6)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test6.txt");
vector<pair<string, int> > word_rank = CountFrequentWord(name);
Assert::AreEqual(word_rank[0].fi, string("ubuntu14"));
Assert::AreEqual(word_rank[0].se, 1);
Assert::AreEqual(word_rank[1].fi, string("ubuntu16"));
Assert::AreEqual(word_rank[1].se, 1);
Assert::AreEqual(word_rank[2].fi, string("windows"));
Assert::AreEqual(word_rank[2].se, 1);
Assert::AreEqual(word_rank[3].fi, string("windows2000"));
Assert::AreEqual(word_rank[3].se, 1);
Assert::AreEqual(word_rank[4].fi, string("windows97"));
Assert::AreEqual(word_rank[4].se, 1);
Assert::AreEqual(word_rank[5].fi, string("windows98"));
Assert::AreEqual(word_rank[5].se, 1);
}
TEST_METHOD(TestMethod7)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test7.txt");
int count_chars = CountChar(name);
Assert::AreEqual(count_chars, 0);
}
TEST_METHOD(TestMethod8)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test8.txt");
int count_chars = CountChar(name);
pii tmp = CountWord(name);
int count_words = tmp.fi;
int count_lines = tmp.se;
vector<pair<string, int> > word_rank = CountFrequentWord(name);
Assert::AreEqual(word_rank[0].fi, string("file123"));
Assert::AreEqual(word_rank[0].se, 1);
Assert::AreEqual(count_words, 1);
Assert::AreEqual(count_chars, 15);
Assert::AreEqual(count_lines, 1);
}
TEST_METHOD(TestMethod9)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test9.txt");
int count_words = CountWord(name).fi;
Assert::AreEqual(count_words, 0);
}
TEST_METHOD(TestMethod10)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test10.txt");
int count_chars = CountChar(name);
pii tmp = CountWord(name);
int count_words = tmp.fi;
int count_lines = tmp.se;
Assert::AreEqual(count_chars, 1703);
Assert::AreEqual(count_lines, 25);
Assert::AreEqual(count_words, 119);
}
};
}
输入的测试数据可以在github中查看
我装的vs好像没有代码覆盖率查看的模块
计算模块部分异常处理说明
if (characters == 0) {
cout << "File not found!";
exit(1);
}
如果访问的文件不存在,会返回错误

总结
这次软工作业我用了很长的时间来做,在这过程中遇到了很多困难也学到了很多。这是我第一次用vs2017来开发,一开始有很多不熟悉的地方,比如可以把头文件放到预编译的文件中,知道了把模块进行封装,然后可以通过单元测试来检验,之前都是把代码写一起,然后多个测试数据都是用批处理文件来对拍的。这次作业带给我的价值不是在于实现了这么一个功能,而是了解了许多软件开发的步骤和经验,让我感受到了软件开发大概是一个什么样的过程,感觉花的时间还是很有意义的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号