
ELK最佳实践
1.ELK最佳实践解析
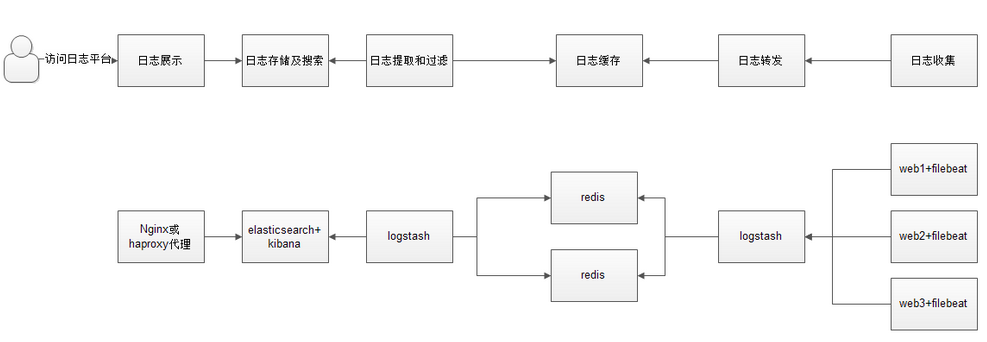
a.用户通过nginx或haproxy访问ELK日志统计平台,IP地址为keepalived的vip地址;
b.nginx将请求转发到kibana;
c.kibana到es获取数据,es是两台做的集群,数据保存在任意一台es服务器;
d.左边的logstash从redis中取出数据并发送到elasticsearch中;
e.redis服务器做数据的临时存放点,避免web服务器日志量过大,造成的数据收集与保存不一致导致日志丢失,其中redis可以做集群,然后再由logstash服务器从redis中持续取出数据;
f.右边的logstash过滤从filebeat取出的日志信息,并放入redis中进行保存;
g.filebeat进行收集web的日志.
为什么要在redis跟filebeat增加一台logstash呢?因为在大量的日志数据写入时,容易导致数据的丢失和混乱,为了解决这一问题,增加一台logstash可以通过类型进行过滤,降低数据传输的臃肿.
以下操作纯属虚构,如有雷同,那不可能,因为我的笔记本是8G内存,开一个logstash就累够呛,开不动六台虚拟机了,手上也没有物理机让我做虚拟化,所以只能有时间了、有需要了再来做这个实验.
2.IP规划
10.0.0.33:filebeat+web,filebeat收集日志发送到logstash
10.0.0.32:logstash,将日志写入reids(input、output)
10.0.0.31:redis,大量缓存数据
10.0.0.30:logstash,从redis取出数据写入es(input、output)
10.0.0.29:es+kibana,es接收传来的数据写入磁盘,等待kibana来取
a.10.0.0.33:filebeat输出到logstash
vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- /var/log/*.log
- /var/log/messages
exclude_lines: ['^DBG',"^$"]
document_type: filebeat-systemlog-0033
output.logstash:
hosts: ["10.0.0.32:5044"]
enabled: true
worker: 2
compression_level: 3
systemctl restart filebeat
b.10.0.0.32:logstash将日志写入reids(向redis写数据不需要给key加日期)
vim beats.conf
input {
beats {
port => "5044"
}
}
output {
if [type] == "filebeat-systemlog-0033" {
redis {
data_type => "list"
host => "10.0.0.31"
db => "3"
port => "6379"
password => "123456"
key => "filebeat-systemlog-0033"
}
}
}
systemctl restart logstash
c.10.0.0.31:redis不用做什么操作
d.10.0.0.30:logstash从redis取出数据写入es
vim redis-es.conf
input {
redis {
data_type => "list"
host => "10.0.0.31"
db => "3"
port => "6379"
key => "filebeat-systemlog-0033"
password => "123456"
}
}
output {
if [type] == "filebeat-systemlog-0033" {
elasticsearch {
hosts => ["10.0.0.29:9200"]
index => "redis31-systemlog-%{+YYYY.MM.dd}"
}
}
}
systemctl restart logstash
e.10.0.0.29:es+kibana
es插件页面出现这个日志索引时redis31-systemlog-xxxx.xx.xx,代表整个流程是通的.
ELK架构实用演示:http://blog.51cto.com/jinlong/2056717

 浙公网安备 33010602011771号
浙公网安备 33010602011771号