
MongoDB - 分片简介
简介
什么是分片
高数据量和高吞吐量的数据库应用会对单机的性能造成较大压力,大的查询会将单机的 CPU 耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存压力转移到磁盘 IO 上。
为了解决这些问题,有两个基本的方法:
- 垂直扩展:增加更多的 CPU 和存储资源来扩展容量
- 水平扩展:将数据集分布在多个服务器上
MongoDB 的分片就是水平扩展的体现,使用分片减少了每个分片需要处理的请求数。通过水平扩展,集群可以提高自己的存储容量和吞吐量。
何时分片
通常来说,不宜过早对数据进行分片,这会增加部署的复杂性;也不应该过晚进行分片,因为很难在不停止运行的情况下对超载的系统进行分片。
通常情况下,分片用于以下情况:
- 增加可用 RAM
- 增加可用磁盘空间
- 减少服务器的负载
- 处理单个 mongod 无法承受的吞吐量
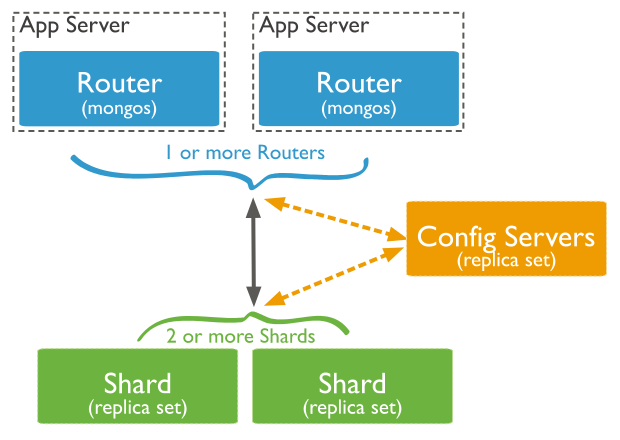
集群结构
一个 MongoDB 的分片集群包含以下组件:
- Shard: 即分片,数据的真正存储位置,以 chunk 为单位存数据;分片也可以部署为一个副本集
- Router: 查询的路由,提供客户端和分片之间的接口;MongoDB 提供了 mongos 进程实现
- Config Servers: 存储元数据和配置数据
数据存储
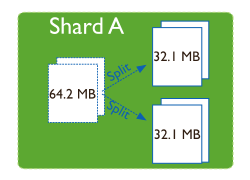
分片的块
在一个分片服务内部,MongoDB 会把数据分为块,每个 chunk 代表这个分片内部的一部分数据。其作用有两个:
- splitting: 当一个 chunk 的大小超过配置的 chunk size 时,MongoDB 的后台进程会将这个 chunk 继续切分
- balancing: 在 MongoDB 中,会有一个 balancer 线程负责 chunk 的迁移,从而均衡各个分片的负载
块的大小
在 MongoDB 中,chunk 的分裂和迁移是非常耗费 IO 资源的,并且 chunk 的分裂只会发生在插入和更新时。
对于大块和小块的选择,其实各有优缺点:
- 小块:迁移速度快,数据分布更均匀;数据分裂频繁,路由节点消耗更多资源
- 大块:数据分裂少,数据块移动集中消耗 IO 资源
分裂和迁移
随着数据的增长,其中的数据大小超过了配置的 chunk size(默认 64M),则这个 chunk 就会分裂成两个。
数据增长的速度快慢会影响 chunk 分裂的速度,数据增长越快则 chunk 分裂的速度越快。
需要注意的是,如果分片试图分裂的时候,其中一个配置服务器停止运行了,那么将无法更新元数据,则会出现分片一直尝试拆分块并一直失败,这种一直无法成功的过程最终会导致 拆分风暴。
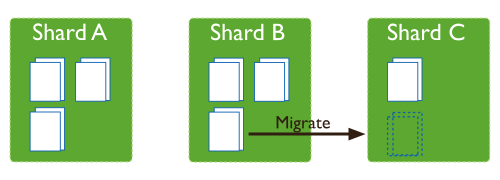
一旦发生了分裂,比如说 Shard A 分裂成 3 个块,Shard B 分裂成 3 个块,而 Shard C 仍然只有 1 个块,则各个分片上的 chunk 数量会不平衡,。
这时候,mongos 中的 balancer 线程就会执行自动平衡,把 chunk 从 chunk 数量最多的分片挪动到 chunk 数量最少的节点。
如何分片
分片键
在对集合进行分片的时,需要选择一个或多个组合字段来对数据进行拆分,这个键(这些键)被称为分片键。
选择分片键非常重要,分片键的有以下注意事项:
- 分片键是不可变的
- 分片键必须是索引
- 分片键不能是数组
- 分片键大小限制 512bytes
- 分片键用于路由查询
- 分片键的组合最好具有很高的基数
哈希分片
分片过程中可以使用哈希索引作为分片键,其最大的好处是能保证数据在各个节点分布基本均匀。
对于基于哈希的分片,MongoDB 计算一个字段的哈希值,并用这个哈希值来创建数据块。
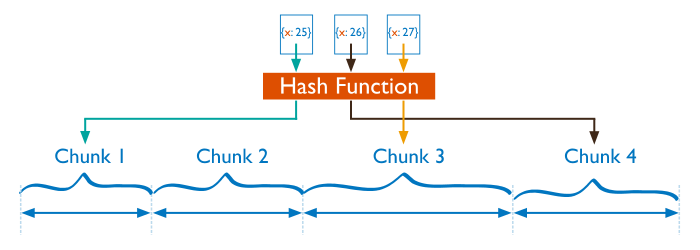
在使用基于哈希分片的系统中,拥有相近分片键的文档很可能不会存储在同一个数据块中,数据的分离性更好一些。
基于哈希分片可以很好地在集群中分配负载,但是,如果随机访问超出了 RAM 大小的数据时,效率会比较低。
范围分片
对于基于范围的分片,MongoDB 按照分片键的范围把数据分成不同部分。
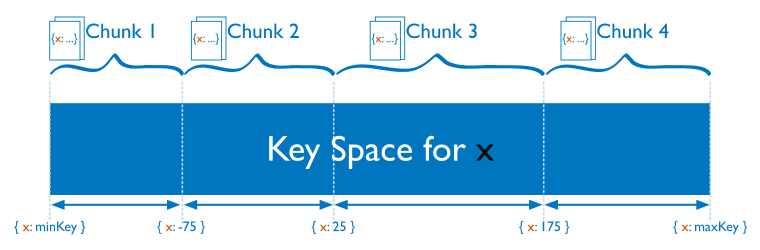
在使用分片键做范围划分的系统中,拥有相近分片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
如果这个分片键是一个自增的值时,将会使 MongoDB 难以保持块的均衡,因为 MongoDB 需要不断将最后一个分片的数据块移动到其他分片上。
哈希和范围的结合
哈希分片更适合随机访问,不适合范围查询;范围分片则是适合范围查询,不适合平衡负载。
一个自定义的方案是,对自增字段构建哈希索引(尽可能是仍然保持有序的哈希算法)即可解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号