

希尔排序的简单理解
详细描述
希尔排序又称为缩小增量排序,主要是对序列按下标的一定增量进行分组,对每组使用直接插入排序算法排序;随着增量逐渐减小,每组包含的关键字越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。
希尔排序详细的执行步骤如下:
- 选择一个增量序列 t1, t2, ..., tk,其中 ti > tj,tk = 1;
- 按增量序列个数 k 对序列进行 k 趟排序;
- 每趟排序,根据对应的增量 ti 将待排序序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序;
- 仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
算法图解
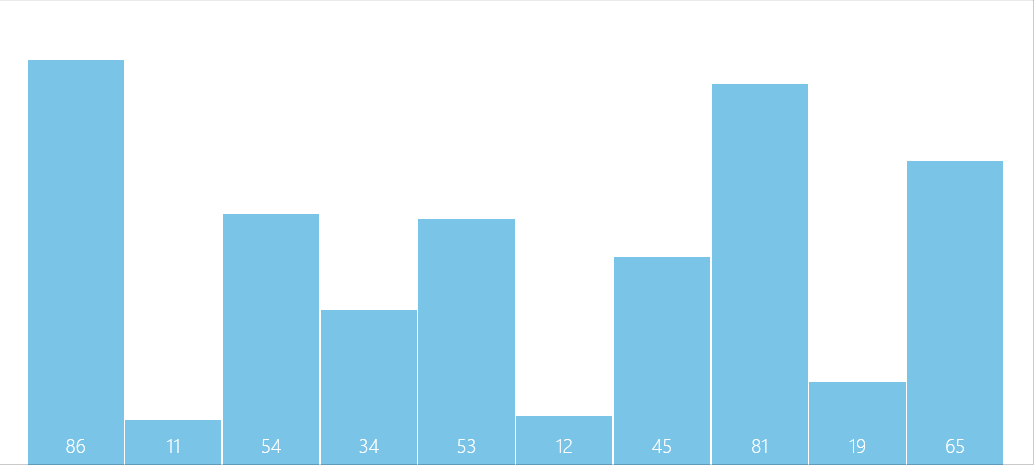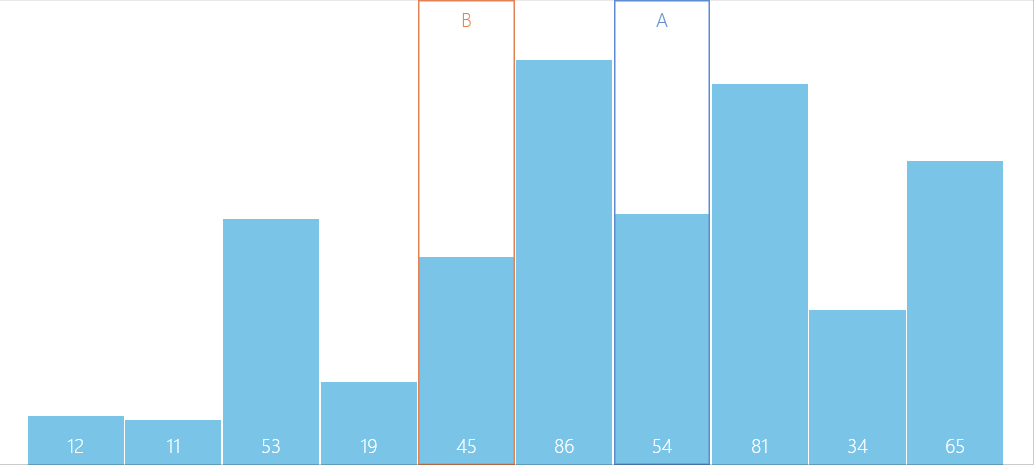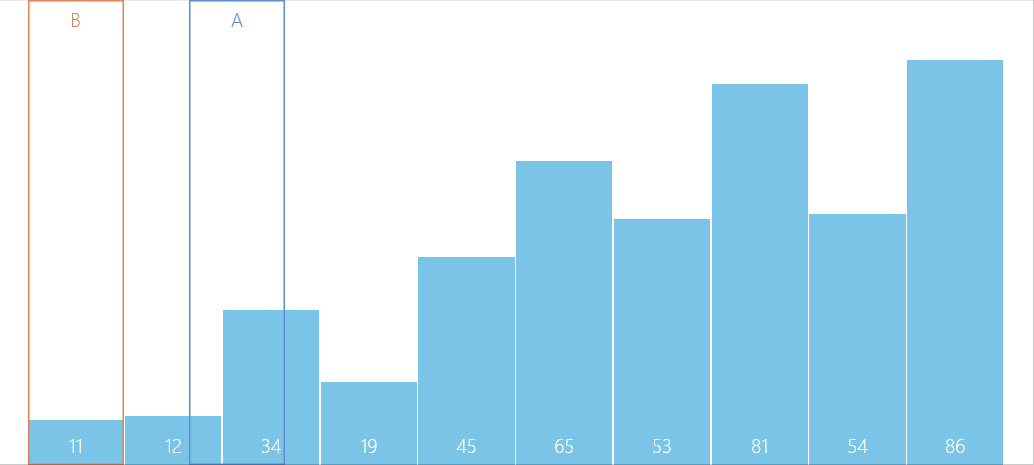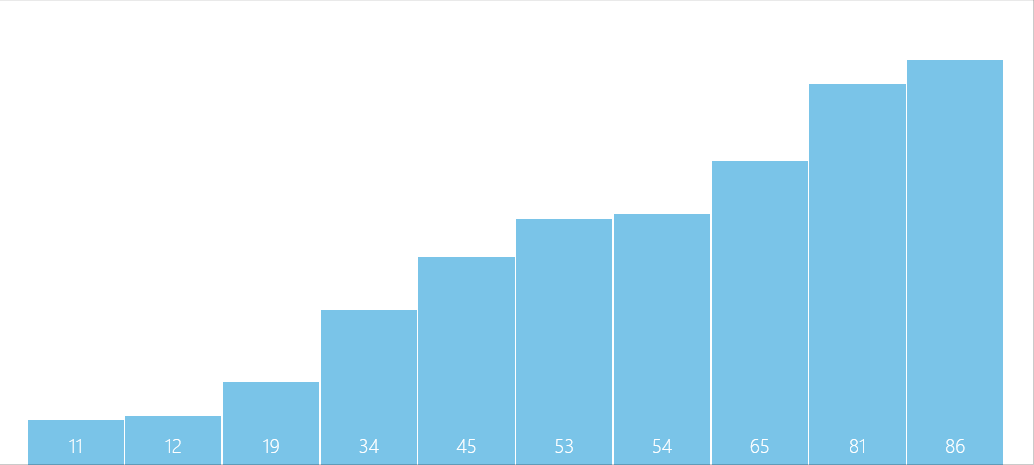
问题解疑
希尔排序是原地排序算法吗?
希尔排序是插入排序的一个优化版本,利用优化的策略使用插入排序,提高效率,没有使用到额外的内存空间,因此希尔排序是原地排序算法。
希尔排序是稳定的排序算法吗?
插入排序是稳定的排序算法,但是,由于希尔排序使用了增量间隔进行插入排序,希尔排序并不能像插入排序保持稳定,排序过程中会出现相等的两数前后顺序不一致。
希尔排序的时间复杂度是多少?
最好情况时间复杂度为
代码实现
排序接口
package cn.fatedeity.algorithm.sort; /** * 排序接口 */ public interface Sort { int[] sort(int[] numbers); }
排序抽象类
package cn.fatedeity.algorithm.sort; /** * 排序抽象类 */ public abstract class AbstractSort implements Sort { protected void swap(int[] numbers, int src, int target) { int temp = numbers[src]; numbers[src] = numbers[target]; numbers[target] = temp; } }
希尔排序类
package cn.fatedeity.algorithm.sort; /** * 希尔排序类 */ public class ShellSort extends AbstractSort { @Override public int[] sort(int[] numbers) { if (numbers.length <= 1) { return numbers; } int length = numbers.length; // 通常增量序列进行二分对原序列拆分 for (int gap = length >> 1; gap > 0; gap = gap >> 1) { for (int i = gap; i < length; i++) { int j = i, current = numbers[i]; while (j >= gap && numbers[j - gap] > current) { numbers[j] = numbers[j - gap]; j = j - gap; } numbers[j] = current; } } return numbers; } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具