Python3程序设计指南:02 数据类型
1、标识符与关键字
创建一个数据项时,我们或者将其赋值给一个变量,或者将其插入到一个组合中。为对象引用赋予的名称叫标识符。
1.1 规则
有效的Python标识符是任意长度的飞空字符序列,其中包括一个“引导字符”,以及0个或多个“后续字符”,Python标识符必须符合两条规则:
- 只要是Unicode编码的字母,都可以充当引导字符,包括ASCII字母、下划线以及大多数非英文语言的字母。
- Python标识符不能与Python关键字同名。
如何查看Python关键字呢?只需两行代码:
# 查看Python关键字
import keyword
print(keyword.kwlist)
输出结果如下:
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
1.2 约定
- 不要使用Python预定义的标识符名对自定义的标识符进行命名。
- 避免使用开头和结尾都是下划线的标识符。因为Python定义了各种特殊方法和变量,使用的就是这样的名称。
2、Integral类型
Python提供了两种内置的Integral类型,即int和bool。在布尔表达式中,0与False都表示False,其他任意整数与True都表示True。在数字表达式中,True表示1,False表示0。
2.1 整数
整数的大小只受限于机器的内存大小。默认情况下,整数采用的是十进制。二进制以0b引导,八进制以0o引导,十六进制以0x引导,大小写都可以。
2.1.1 数值型操作符与函数
| 语法 | 描述 |
|---|---|
| x+y | 将数x与数y相加 |
| x-y | 从x减去y |
| x*y | 将x与y相乘 |
| x/y | 用x除以y,得到一个浮点值(如果x或y是复数就产生一个复数) |
| x//y | 用x除以y,舍弃小数部分,得到一个整数 |
| x%y | 用x除以y,取模(余数) |
| x**y | x的y次幂 |
| -x | 对x取复数,如果x非零,就改变其符号 |
| +x | 不做任何操作,有时候用于澄清代码 |
| abs(x) | 返回x的绝对值 |
| divmod(x,y) | 以二元组的形式返回x除以y所得的商和余数(两个整数) |
| pow(x,y) | 与x**y等同 |
| pow(x,y,z) | (x**y)%z的另一种写法 |
| round(x,n) | 返回浮点数x四舍五入后得到的相应整数(如果给定n,就将浮点数转换为小数点后有n位) |
所有二元数学操作符(+、-、*、/、//、%、与**)都有相应的增强版赋值操作符(+=、-=、*=、/=、//=、%=、与**=)。
2.1.2 使用数据类型创建对象
对象的创建可以通过给变量赋字面意义上的值,比如x=17,或者将相关的数据类型作为函数进行调用,比如x=int(17)。
使用数据类型创建对象时,有3种用例:
- 不使用参数调用数据类型函数。此时,对象会被赋值为一个默认值,比如
x=int()会创建一个值为0的整数。所有内置数据类型都可以作为函数并不带任何参数进行调用。 - 使用一个参数调用数据类型函数。如果给定的参数是同样的数据类型,就会创建一个新对象;否则会尝试进行转换。
- 如果给定参数支持到给定数据类型的转换,但是转换失败,会产生一个ValueError异常,否则返回给定类型的对象。
- 如果给定参数不支持到给定数据类型的转换,就会产生一个TypeError异常。
整数转换函数:
| 语法 | 描述 |
|---|---|
| bin(i) | 返回整数i的二进制表示(字符串),比如bin(100)='0b01100100' |
| hex(i) | 返回整数i的十六进制表示(字符串),比如hex(100)='0x64' |
| int(x) | 将对象x转换为整数,失败时会产生ValueError异常,如果x的数据类型不知道到整数的转换,就会产生TypeError异常;如果x是一个浮点数,就会截取其整数部分 |
| int(s, base) | 将字符串s转换为整数,如果给定了可选的基参数,那么应该为2到36之间的整数 |
| oct(i) | 返回整数i的八进制表示(字符串),比如oct(100)='0o144' |
- 给定两个或多个参数——但不是所有数据类型都支持,而对支持这一情况的数据类型,参数类型以及内涵都是变化的。
2.1.3 整数位逻辑操作符
| 语法 | 描述 |
|---|---|
| i|j | 对整数i和整数j进行为逻辑OR运算 |
| i^j | 对整数i和整数j进行为逻辑XOR运算 |
| i&j | 对整数i和整数j进行为逻辑AND运算 |
| i<<j | 将i左移j位,类似于i*(2**j),但不带溢出检查 |
| i>>j | 将i左移j位,类似于i//(2**j),但不带溢出检查 |
| ~i | 反转i的每一位 |
2.2 布尔型
有两个内置的布尔型对象:True与False。
布尔数据也可以当做函数进行调用——不指定参数时将返回False,给定的是布尔型参数时,会返回该参数的一个拷贝,给定的是其他类型的参数时,则会尝试将其转换为布尔数据类型。
所有内置的数据类型与标准库提供的数据类型都可以转换为一个布尔型值。
3、浮点类型
Python提供了3中浮点值:内置的float与complex类型,以及来自标准库的decimal.Decimal类型。
float类型存放双精度的浮点数。
3.1 浮点数
比较两个float数是否相等(按机器所能提供的最大精度):
import sys
def equal_float(a, b):
return abs(a - b) <= sys.float_info.epsilon
Python的floatS通常会提供之多17个数字的精度。
3.2 复数
复数这种数据类型是固定的,其中存放的是一对浮点数,一个表示实数部分,一个表示虚数部分。复数的两个部分都以属性名的形式存在,分别为real与imag,例如:
z = -23.1+8.94j
print(z.real, z.imag)
除//、%、divmod()以及三个参数的pow()之外,所有数值型操作符与函数都可以用于对复数进行操作,赋值操作符的增强版也可以。
复数类型有一个方法conjugate()用于改变虚数部分的符号,例如:
z = -23.1+8.94j
y = z.conjugate()
###
y = -23.1-8,94j
要使用复数,可以先导入cmath模块,该模块提供了math模块中大多数三角函数与对数的复数版,也包括一些复数特定的函数。
3.3 十进制数
decimal模块可以提供固定的十进制数,其精度可以由我们自己指定。涉及Decimals的计算要比浮点数的计算慢。
In [5]: import decimal
In [6]: a = decimal.Decimal(4532)
In [7]: b = decimal.Decimal("543129.98789798")
In [8]: a+b
Out[8]: Decimal('547661.98789798')
十进制数是由decimal.Decimal()函数创建,该函数可以接受一个整数或一个字符串作为参数——但不能以浮点数作为参数,因为浮点数不够精确。
4、字符串
字符串是使用固定不变的str数据类型表示的,其中存放Unicode字符序列。
4.1 str()函数
str()函数的用法:
-
创建字符串对象,参数为空时,返回一个空字符串,参数为非字符串类型时返回改参数的字符串形式,参数为字符串时,返回该字符串的拷贝。
In [9]: string1 = str() In [10]: string2 = str(1234) In [11]: string3 = str('hello') In [12]: string1 Out[12]: '' In [13]: string2 Out[13]: '1234' In [14]: string3 Out[14]: 'hello' -
转换函数,此时要求第一个参数为字符串或可以转换为字符串的其他数据类型,其后跟两个可选的字符串参数,其中一个用于指定要使用的编码格式,另一个用于指定如何处理编码错误。
4.2 字符串的表示
- 单引号:
s = 'hello' - 双引号:
s = "hello" - 三引号:
s = '''hello python'''或s = """hello python"""
在引号包含的字符串中使用引号:
- 使用与引号包含的字符串不同的引号,例如
s = "this is a 'str'." - 如果两者引号相同,那就需要使用转义字符,例如
s = "this is a \"str\"."
如果要写一个长字符串,跨越了多行,如何表示?
-
使用三引号(注意行尾的"",如果不加,则打印出来带有换行符):
In [29]: s = """This is the first way to ...: solve the problem""" In [30]: s Out[30]: 'This is the first way to \nsolve the problem' In [31]: s = """This is the first way to \ ...: solve the problem""" In [32]: s Out[32]: 'This is the first way to solve the problem' -
使用"+"和"":
In [33]: s = "This is not the best way to join two long strings " + \ ...: "together since it relines on ugly newline escaping" In [34]: s Out[34]: 'This is not the best way to join two long strings together since it relines on ugly newline escaping' -
使用圆括号:
In [35]: s = ("This is the nice way to join two long strings " ...: "together;it relines on string literal concatenation.") In [36]: s Out[36]: 'This is the nice way to join two long strings together;it relines on string literal concatenation.'
Python的“Idioms and Anti-Idioms”HOWTO文档建议总是使用圆括号将跨越多行的任何语句进行封装,而不使用专一的换行符。
4.3 字符串的分片与步长
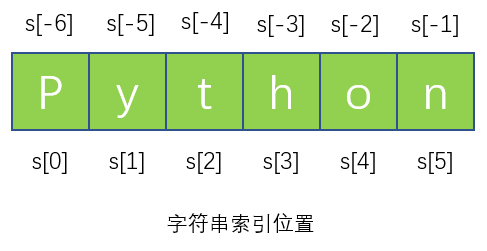
字符串的索引位置从0开始,直至字符串长度值减去1。使用负索引位置也可以,此时的计数方式是从最后一个字符到第一个字符。
假如我们设置s='Python',下图展示了字符串所有有效索引位置:
分片操作有三种语法:
- seq[start] :从序列中提取start位置的数据项。
- seq[start:end] :从start开始到end结束的数据项(不包含)。
- seq[start: end:step] :从start开始到end结束的数据项(不包含)每隔step个字符进行提取。
其中seq可以是任意序列,比如列表、字符或元组。start、end与step必须是整数。
第二和第三种语法,我们可以忽略任意的整数索引值:忽略起点索引值,就默认为0;如果忽略终点索引值,就默认为len(seq)。
step可以为负值,如果为负值就从end开始往start方向提取,我们可以利用这一特性进行序列的倒序排列操作:
In [40]: s = 'python'
In [41]: s[::-1]
Out[41]: 'nohtyp'
4.4 字符串操作符与方法
由于字符串是固定序列,所有可用于固定序列的功能都可以用于字符串,包括使用in进行成员测试,使用+=进行追加操作,使用*进行复制操作等。
令 s = 'i like Python':
| 语法 | 描述 | 示例 |
|---|---|---|
| s.capitalize() | 返回字符串s的副本,并将首字母变为大写 | 'I like python' |
| s.center(width, char) | 返回s中间的一个子字符串,长度为width,并使用空格或可选的char(长度为1的字符串)进行填充 | |
| s.count(t, start, end) | 返回s中(或在start : end分片中)子字符串t出现的次数 | s.count('i') 2 |
| s.encode(encoding, err) | 返回bytes对象,该对象使用默认的编码格式或指定的编码格式来表示该字符串并根据可选的err参数处理错误 | s.encode('gbk') b'i like Python' |
| s.endswith(x, start,end) | 如果s(或在s的start : end分片)以字符串x(或元组x中的任意字符串)结尾,就返回True | s.endswith('n') True |
| s.expandtabs(size) | 返回s的副本,其中的制表符使用8个或指定数量的空格替换 | |
| s.find(t, start, end) | 返回t在s中(或s的start : end分片中)的最左位置,如果没找到返回-1。使用s.rfind()则可以发现相应的最右边位置。 | s.find('like') 2 |
| s.format(...) | 返回按给定参数进行格式化后的字符串副本,后面会讲 | |
| s.index(t,start,end) | 返回t在s中(或s的start : end分片中)的最左位置,如果没有找到会产生ValueError异常。如果使用rindex()可以从右边开始搜索。 | s.index('y') 8 |
| s.isalnum() | 如果s非空,并且其中的每个字符都是字母数字,返回True | False |
| s.isalpha() | 如果s非空,并且其中的每个字符都是字母,返回True | False |
| s.isdecimal() | 如果s非空,并且其中的每个字符都是Unicode的基数为10的数字,返回True | False |
| s.isidentifier() | 如果s非空,并且是一个有效的标识符,返回True | False |
| s.islower() | 如果s至少有一个可以小写的字符,并且其所有的可小写的字符都是小写的,返回True | False |
| s.isnumeric() | 如果s非空,并且其中的每个字符都是数值的Unicode字符,比如数字或小数,返回True | False |
| s.isprintable() | 如果s非空,并且其中的每个字符都是可打印的,包括空格但不包括换行,返回True | True |
| s.isspace() | 如果s非空,并且其中的每个字符都是空白字符,返回True | False |
| s.istitle() | 如果s非空,并且首字母大写,返回True | False |
| s.isupper() | 如果s至少有一个可以大写的字符,并且其所有的可大写的字符都是大写的,返回True | False |
| s.join(seq) | 返回序列seq中每个项连接起来后的结果,并以s(可以为空)在每两项之间分隔 | s.join(['first', 'second']) 'firsti like Pythonsecond' |
| s.ljust(width, char) | 返回长度为width的字符串(使用空格或可选的char(长度为1的字符串)进行填充)中左对齐的字符串s的一个副本。使用s.rjust()可以右对齐,s.center()可以中间对齐 | |
| s.lower() | 将s中的字符变为小写 | 'i like python' |
| s. maketrans(x[,y[,z]]) | 该静态函数返回可用于str.translate()方法的转换表。 如果只有一个参数,它必须是dict类型,键key为长度为1的字符(unicode字符码或者字符),值value为任意长度字符串或者None。键key对应的字符将被转换为值value对应的字符(串)。 如果有两个参数,他们长度必须相等,每一个x字符将被转换为对应的y字符。如果有第三个参数,其对应的字符将被转换为None。 |
m = {'e':'f', 'o':'p'} s.maketrans(m) |
| s.partition(t) | 返回包含3个字符串的元组--字符串s在t的最左边部分、t、字符串s在t最右边部分。如果t不在s内,则返回s与两个空字符串。使用s.rpartition()可以在t最右边部分进行分区 | s.partition('like') ('i ', 'like', ' Python') |
| s.replace(t,u,n) | 返回s的副本,其中每个(或最多n个,如果给定)字符串t使用u替换 | s.replace('like','love') 'i love Python' |
| s.split(t,n) | 返回一个字符串列表,要求在字符串t处至多分割n次。如果没有给定n,就分隔尽可能多次,如果t没有给定,就在空白处分割。使用s.rsplit()可以从右边进行分割 | s.split('i') ['', ' l', 'ke Python'] |
| s.splitlines(f) | 返回在行终结符处进行分割产生的行列表,并剥离行终结符(除非f为True) | s.splitlines() ['i like Python'] |
| s.startswith(s,start,end) | 如果s(或在s的start : end分片)以字符串x(或元组x中的任意字符串)开始,就返回True | s.startswith('i') True |
| s.stripe(chars) | 返回s的一个副本,并将开始处与结尾处的空白字符(或字符串chars中的字符)移除,s.lstripe()仅剥离起始处的相应字符,s.rstripe()仅剥离结尾出的相应字符 | s.strip('n') 'i like Pytho' |
| s.swapcase() | 返回s的副本,并将其中大写字符变为小写,小写字符变为大写 | 'I LIKE pYTHON' |
| s.title() | 返回s的副本,并将每个单词的首字母变为大写,其它字母变为小写 | 'I Like Python' |
| s.translate() | 返回一个使用参数map转换后的字符串,map必须是一个unicode字符码(整形)到unicode字符,字符串或None的映射表,未被映射的字符保持不表,被映射为None的字符将被删除。 | m = {'e':'f', 'o':'p'} s.maketrans(m) s.translate(trans) 'i likf Pythpn' |
| s.upper() | 返回s的大写化版本 | 'I LIKE PYTHON' |
| s.zfill(w) | 返回s的副本,如果比w短,就在开始处添加0,使其长度为w | s.zfill(15) '00i like Python' |
Python还有一些其他库模块提供字符串相关的功能:
- difflib,用于展示文件或字符串之间的差别
- io模块的io.StringIO类,用于读写字符串,就像对文件的读写操作一样
- textwrap,该模块提供了用于包裹于填充字符串的函数和方法
- string,其中定义了一些有用的常量,比如ascii_letters与ascii_lowercase
4.5 str.format()对字符串格式化
str.format()方法会返回一个新字符串,在新字符串中,原字符串中的替换字段被适当格式化后的参数所替代,格式化后的参数可以是字符串或数字类型:
In [103]: '{0}{1}'.format('The price of this apple is $',10)
Out[103]: 'The price of this apple is $10'
如果需要在格式化字符串中包含花括号,就需要将其复写:
In [104]: '{0}{{{1}}}'.format('The price of this apple is $',10)
Out[104]: 'The price of this apple is ${10}'
str.format()替换字段可以使用下面的任意一种语法格式:
字段名是一个与某个str.format()方法参数对应的整数,或者是方法的某个关键字参数的名称
In [105]: '{who} turned {age} this year.'.format(who='she', age=19)
Out[105]: 'she turned 19 this year.'
In [106]: 'The {who} was {0} last week'.format(12, who='boy')
Out[106]: 'The boy was 12 last week'
字段名可以引用集合数据类型,例如:列表
In [108]: 'Both of {0[0]} and {0[1]} are my friends.'.format(['Jenny','Danny'])
Out[108]: 'Both of Jenny and Danny are my friends.'
从Python3.1开始,我们可以忽略字段名:
In [109]: 'The {} was {} last week'.format('boy',12)
Out[109]: 'The boy was 12 last week'
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号